
正则模块
一、正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
正则表达式与re模块的关系
1.正则表达式是一门独立的技术,任何语言均可使用
2.python中要想使用正则表达式需要通过re模块
网站注册校验手机号码的功能展示:
1.纯pyhton代码(无正则表达式)
while True: phone_number = input('please input your phone number : ') if len(phone_number) == 11 \ and phone_number.isdigit()\ and (phone_number.startswith('13') \ or phone_number.startswith('14') \ or phone_number.startswith('15') \ or phone_number.startswith('18')): print('是合法的手机号码') else: print('不是合法的手机号码')
2.正则表达式校验
import re phone_number = input('please input your phone number : ') if re.match('^(13|14|15|18)[0-9]{9}$',phone_number): print('是合法的手机号码') else: print('不是合法的手机号码') # 正则在所有语言中都可以使用 不是python独有的
正则表达式也是用字符串表示的,所以,我们要首先了解如何用字符来描述字符。
在正则表达式中,如果
●直接给出字符,就是精确匹配。
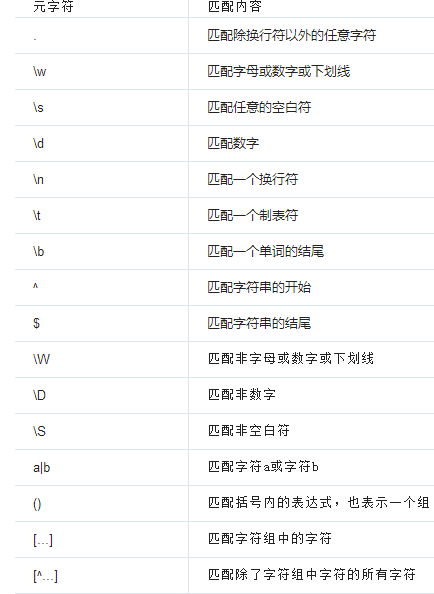
●用\d可以匹配一个数字,
●\w可以匹配一个字母或数字,所以:
-
'00\d'可以匹配'007',但无法匹配'00A'; -
'\d\d\d'可以匹配'010'; -
'\w\w\d'可以匹配'py3';
'.'可以匹配任意字符,所以:
'py.'可以匹配'pyc'、'pyo'、'py!'等等。
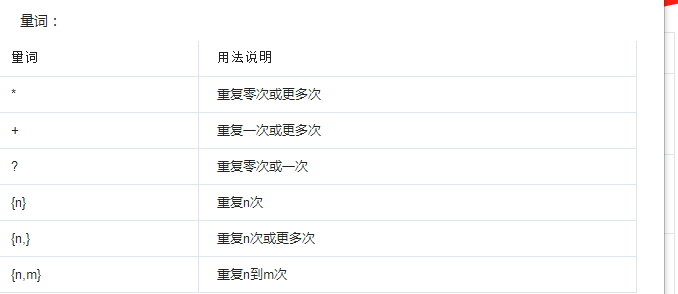
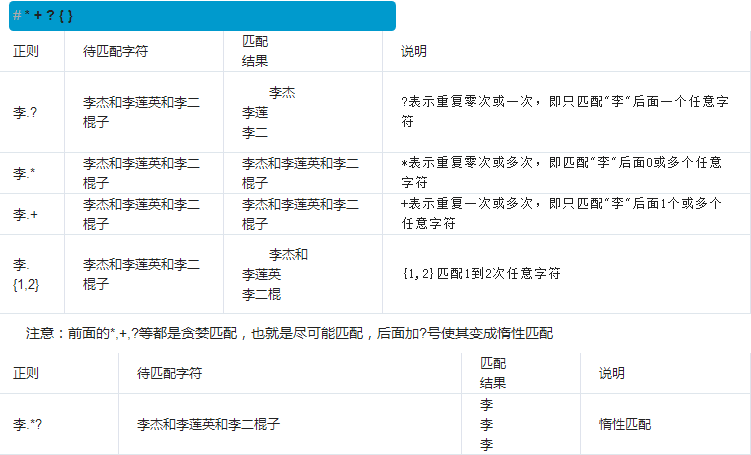
●要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),
●用+表示至少一个字符,
●用?表示0个或1个字符,
●用{n}表示n个字符,
●用{n,m}表示n-m个字符:
来看一个复杂的例子:
\d{3}\s+\d{3,8}
我们来从左到右解读一下:
\d{3}表示匹配3个数字,例如'010';
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格,例如匹配' ',' '等;
\d{3,8}表示3-8个数字,例如'1234567'。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。
如果要匹配'010-12345'这样的号码呢?由于'-'是特殊字符,在正则表达式中,要用'\'转义,所以,上面的正则是\d{3}\-\d{3,8}。
但是,仍然无法匹配'010 - 12345',因为带有空格。所以我们需要更复杂的匹配方式。
进阶
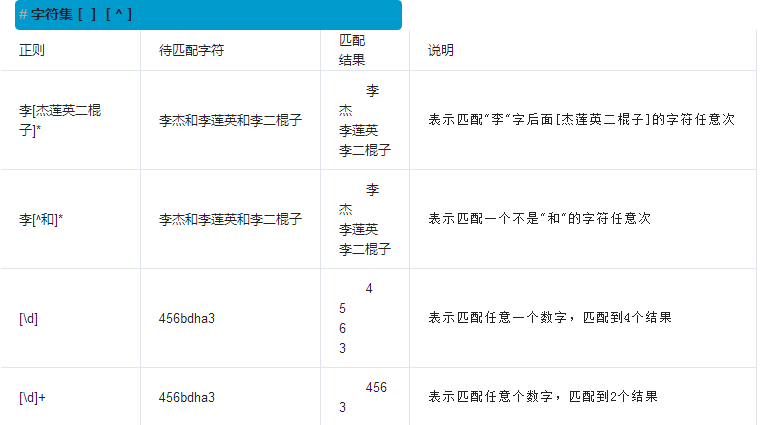
要做更精确地匹配,可以用[]表示范围,比如:
-
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线; -
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等; -
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量; -
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
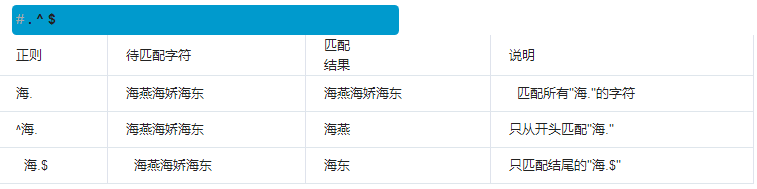
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。
你可能注意到了,py也可以匹配'python',但是加上^py$就变成了整行匹配,就只能匹配'py'了。
字符:

re模块
Python提供re模块,包含所有正则表达式的功能。由于Python的字符串本身也用\转义,所以要特别注意:
s = 'ABC\\-001' # Python的字符串 # 对应的正则表达式字符串变成: # 'ABC\-001'
因此我们强烈建议使用Python的r前缀,就不用考虑转义的问题了:
s = r'ABC\-001' # Python的字符串 # 对应的正则表达式字符串不变: # 'ABC\-001'
1.match('正则表达式','带匹配的字符串')方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。常见的判断方法就是:
ret = re.match('a', 'abc').group() # 同search,不过仅在字符串开始处进行匹配
print(ret) # ‘a'
# match是从头开始匹配,如果正则规则从头开始可以匹配上,就返回一个对象,需要用group才能显示,如果没匹配上就返回None,调用group()就会报错
match只会匹配字符串的第一个。找不到就报错
插入一个可以使得不报错的小技巧:
由于没匹配上则返回None,可以利用if条件判断:
import re res='abc' if re.match(r'a',res): print('ok')
2.findall('正则表达式','带匹配的字符串')
import re res=re.findall('a','sdff s fsfsd ss') print(res)
答案错误回复空[]
找出字符串中符合正则表达式全部内容 并且返回的是一个列表,列表中的元素就是正则匹配到的结果
3.search('正则表达式','带匹配的字符串')只查一次
import re res=re.search('a','sdf fsasdf sf ') print(res.group())
其他模块的补充
1.re.split()
ret = re.split('[ab]', 'abcd') # 先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 print(ret) # ['', '', 'cd'] 返回的还是列表
2.re.sub()
ret = re.sub('\d', 'H', 'eva3egon4yuan4',1) # 将数字替换成'H',参数1表示只替换1个 # sub('正则表达式','新的内容','待替换的字符串',n) """ 先按照正则表达式查找所有符合该表达式的内容 统一替换成'新的内容' 还可以通过n来控制替换的个数 """ print(ret) # evaHegon4yuan4
3.re.subn()
ret = re.subn('\d', 'H', 'eva3egon4yuan4') # 将数字替换成'H',返回元组(替换的结果,替换了多少次) ret1 = re.subn('\d', 'H', 'eva3egon4yuan4',1) # 将数字替换成'H',返回元组(替换的结果,替换了多少次) print(ret) # 返回的是一个元组 元组的第二个元素代表的是替换的个数
4.re.compile()
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字 ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串 res1 = obj.findall('347982734729349827384') print(ret.group()) #结果 : 123 print(res1) #结果 : ['347', '982', '734', '729', '349', '827', '384']
5.re.finditer()
import re ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器 print(ret) # <callable_iterator object at 0x10195f940> print(next(ret).group()) # 等价于ret.__next__() print(next(ret).group()) # 等价于ret.__next__() print(next(ret).group()) # 等价于ret.__next__() print(next(ret).group()) # 等价于ret.__next__() print(next(ret).group()) # 等价于ret.__next__() print(next(ret).group()) # 等价于ret.__next__() 查出迭代取值的范围 直接报错 print(next(ret).group()) #查看第一个结果 print(next(ret).group()) #查看第二个结果 print([i.group() for i in ret]) #查看剩余的左右结果
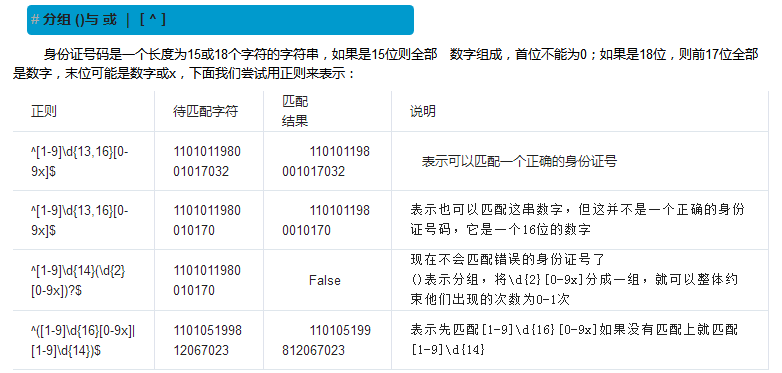
6.re.search()
import re res = re.search('^[1-9](\d{14})(\d{2}[0-9x])?$','110105199812067023') 还可以给某一个正则表达式起别名 res = re.search('^[1-9](?P<password>\d{14})(?P<username>\d{2}[0-9x])?$','110105199812067023') print(res.group()) print(res.group('password')) print(res.group(1)) print(res.group('username')) print(res.group(2)) print(res.group(2)) print(res.group(1))
7.re.findall()
ret1 = re.findall('www.(baidu|oldboy).com', 'www.oldboy.com') ret2 = re.findall('www.(?:baidu|oldboy).com', 'www.oldboy.com') # 忽略分组优先的机制 print(ret1,ret2) # ['oldboy'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可
8.re.split()
ret=re.split("\d+","eva3egon4yuan") print(ret) #结果 : ['eva', 'egon', 'yuan']
9.re.split()
ret1=re.split("(\d+)","eva3egon4yuan") print(ret1) #结果 : ['eva', '3', 'egon', '4', 'yuan']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号