【CSAPP笔记】8. 汇编语言——数据存储
下面介绍一些C语言中常见的特殊的数据存储方式,以及它们在汇编语言中是如何表示的。
数组
数组是一种将标量数据聚集成更大数据类型的方式。实现数组的方式其实十分简单,也非常容易翻译成机器代码。C语言的一个特点是可以产生指向数组元素的指针,然后可以对这些指针进行运算。
数组的基本原则如下:
对于数组的声明:T A[N];,这句语句有两个效果。首先,它在存储器中分配一个 L * N 个字节的连续区域,L 是数据类型 T 单位为字节的大小,用 $ X_A $ 来表示起始位置。其次,它引入标识符 A ,可以用 A 作为指向数组开头的指针,指针的值就是$ X_A $。

汇编代码:假设 E 是一个 int 型数组,我们想计算 E[i],数组的地址存储在寄存器 %edx 中, 下标 i 存放在寄存器 %ecx 中。下列指令会计算地址 $ X_E + 4i $,读取这个存储器的值,然后将结果放到寄存器 %eax 中。
movl (%edx, %ecx, 4), %eax
指针运算
C语言允许对指针进行运算,计算的过程中,值会根据该指针引用的类型的大小进行伸缩(指针类型的作用)。下面这些例子给出一些关于数组 E 的表达式,以及每个表达式的汇编代码实现。
| 表达式 | 结果类型 | 值 | 汇编代码 |
|---|---|---|---|
| E | int * | $ X_E $ | movl %edx, %eax |
| E[0] | int | $ M[X_E] $ | movl (%edx), %eax |
| E[i] | int | $ M[X_E + 4i] $ | movl (%edx, %ecx, 4), %eax |
| &E[2] | int * | $ X_E + 8 $ | leal 8(%edx), %eax |
| E+i-1 | int * | $ X_E + 4i - 4 $ | leal -4(%edx, %ecx, 4), %eax |
| *(E+i-3) | int | $ M[X_E + 4i - 12] $ | movl -12(%edx, %ecx, 4), %eax |
| &E[i]-E | int | i | movl %ecx, %eax |
嵌套数组
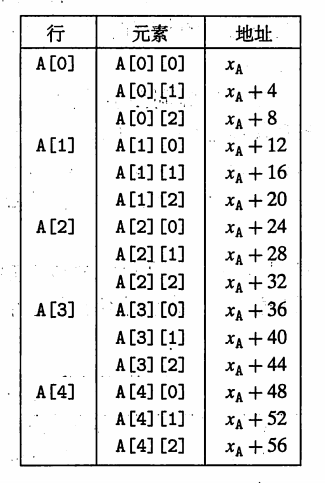
当我们创建数组的数组时,数组的分配和引用的一般原则也是成立的。例如有声明:
int A[5][3];
则相当于下面的声明:
typedef int row3_t[3];
row3_5 A[5];
A 数组是一个包含 5 个元素的数组,每一个元素是一个含有 3 个整数的数组。也可以看成是一个 5 行 3 列的二维数组。用 A[0][0] 到 A[4][2] 来引用。二维数组是以行优先的顺序来排列的。第 0 行的所有元素,可以写作 A[0]。
对于数组 T[R][C]; 来说,他的元素 T[i][j] 的存储器地址为:$ X_D + L(C * i + j) $
异质的数据结构
C语言提供了两种结合不同的对象来创建数据类型的机制:结构(struct),将多个对象集合到一个单位中;联合(union),允许用几种不同的类型引用一个对象。
结构体
C语言的 struct 创建一种数据类型,将可能不同的数据类型的对象聚合到一个对象中。结构体中各个组成部分由名字来引用。类似于数组的实现,结构体的所有组成部分都存放在存储器中的一段连续的区域内,指向结构体的指针就是结构体第一个字节的地址。编译器维护每个结构类型的信息,指示每个字段(field)的字节偏移。以这些偏移作为存储器引用中指令的位移,从而产生对结构体元素的引用。
假设有下面的结构体声明:
struct rec{
int i;
int j;
int a[3];
int *p;
};
那么在内存中的排列是:

为了访问字段,编译器产生的代码要将结构体的地址加上适当的偏移。例如指向结构体 rec 的指针变量 r 存放在寄存器 %edx 中,下面的代码将元素 r->i 复制到 r->j
movl (%edx), %eax # 将 r->i 放到寄存器中
movl %eax, 4(%edx) # 将寄存器的值复制到 r->j 中
可以看到,为了访问字段 j,代码将 r 的地址加上偏移量 4。
联合体
联合体提供了一种方式,能够规避C语言的类型系统,允许以多种类型来引用同一个对象。联合体的语法和结构体一样,但语义差别很大——联合体用不同的字段来引用相同的内存。
考虑下面的声明:
struct S{
char c;
int i[2];
double v;
}
union U{
char c;
int i[2];
double v;
}
在一台 IA32 Linux 机器上编译时,字段的偏移量、数据类型的完整大小如下:
| 类型 | 偏移量:c | i | v | 大小 |
|---|---|---|---|---|
| S | 0 | 4 | 12 | 20 |
| U | 0 | 0 | 0 | 8 |
一个联合体的总的大小总是等于它的最大字段的大小。对于类型结构体 U 的指针 p,p->c、p->i[0]、p->v 都是引用数据结构的起始位置。
在一些上下文中,联合体十分有用,但是它也引起一些讨厌的错误,因为它绕过了C语言类型系统提供的安全措施。
举一个联合体应用的具体例子:现在我们要设计一个特殊的二叉树的数据结构,它有一个特点:每个叶子节点有一个 double 类型的值。每个内部节点有左右儿子的指针,但是没有数据。如果声明如下:
struct Node{
struct Node * left;
struct Node * right;
double data;
};
如果用上述结构体,那么每个节点都需要 16 个字节。然而,叶子结点是没有左右儿子的,内部节点是用不着 double data 的,所以每个类型的节点都要浪费一半的内存。如果我们这样声明:
union Node{
struct
{
union Node *left;
union Node *right;
}internal;
double data;
};
那么每个节点就只需要 8 个字节。如果 n 是一个指向 union Node 的指针,那么可以用 n->data 来表示叶子结点的数据,n->internal.left 和 n->internal.right来表示内部节点的左右儿子。
然而这样表示,我们是没办法确定一个给定的节点到底是叶子节点,还是内部节点。有一个方法,是引入一个枚举类型,定义这个联合中可能的不同选择,再用一个结构体将两者包含起来:
typedef enum {LEAF, INTERNAL} nodetype;
struct Node_T{
nodetype type;
union Node{
struct
{
union Node *left;
union Node *right;
}internal;
double data;
}info;
};
可以发现,这样的联合体只需要12个字节。
相对于编码带来的麻烦问题,其实使用联合体带来的节省是很小的。除非说对于有较多字段的数据结构,结构体带来的节省就会更加吸引人。
数据对齐
struct S{
char c;
int i[2];
double v;
};
| 类型 | 偏移量:c | i | v | 大小 |
|---|---|---|---|---|
| S | 0 | 4 | 12 | 20 |
为什么 i 的偏移量不是 1 呢?char 类型的大小不是只有 1 个字节吗?
要解答这个问题,我们必须对数据对齐有一定的了解。计算机系统对于基本的数据类型的合法地址做出了一定的限制,要求地址必须是某个值的倍数(例如4、8、16)。这种对齐限制简化了处理器系统和存储器系统之间的接口硬件设计。
对于上面那个结构体,画出来的图是这样的:

它不可能满足对齐要求。假设我们的对齐要求是 4 字节对齐的话,编译器会在字段 c 之后插入一个 3 字节的间隙(用灰色表示),对齐后的结构体如下:

可以看到后面的字段的偏移量发生了改变,整个结构体的大小变成了 20 字节。
另外,编译器结构的末尾可能为了满足对齐要求而需要一些填充。这样,结构体数组的每个元素都能满足对齐要求。例如将上述结构体稍作修改:
struct S{
int i[2];
double v;
char c;
};
那么编译器为了使结构体数组的每个元素都满足对齐要求,不得不在末尾插入多余的 3 个字节。

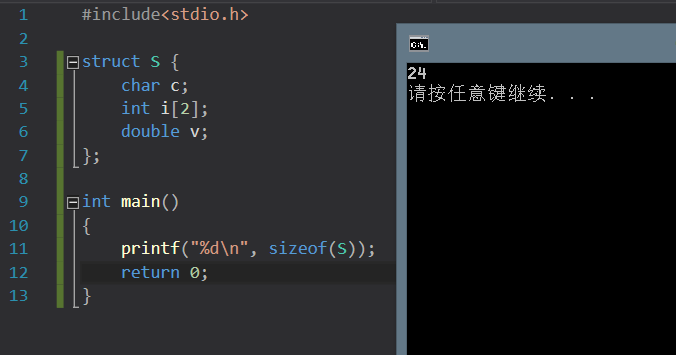
编译这段代码,可以发现,这个编译器的对齐要求应该是为 8 的倍数。了解到对齐方式之后,我们在写结构体的时候,注意一下元素的排列顺序,可以更有效地利用内存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号