【CSAPP笔记】7. 汇编语言——过程调用
一个过程调用包括将数据(以参数和返回值的形式)与控制从代码的一部分传递到另一部分。除此之外,在进入时为过程的局部变量分配空间,在退出的时候释放这些空间。数据传递、局部变量的分配和释放通过操纵程序栈来实现。栈作为一种能够实现先进后出、后进先出的数据结构,非常适合用于实现函数调用以及返回的机制。
在过程调用中主要涉及三个重要的方面:
- 传递控制:包括如何开始执行过程代码,以及如何返回到开始的地方
- 传递数据:包括过程需要的参数以及过程的返回值
- 内存管理:如何在过程执行的时候分配内存,以及在返回之后释放内存
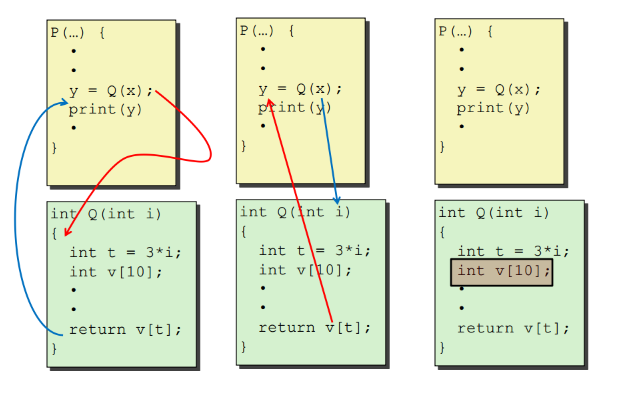
栈结构
程序栈其实就是一块内存区域,这个区域内的数据满足先进后出的原则。从栈底到栈顶,地址由高变低。所以新加入栈的以及新开辟的空间的地址都是较小的。有两个特殊寄存器是与栈有关的。寄存器 %ebp 叫做帧指针,保存当前栈帧开始的位置。寄存器 %esp 叫做栈指针,始终指向栈顶。栈帧(stack frame)是指为单个过程分配的那一小部分栈。大多数信息访问都是相对于帧指针访问的。以前经常看到这类代码:movl 8(%ebp), %eax 意思就是将存放在比帧指针地址大8的变量移动到寄存器里。
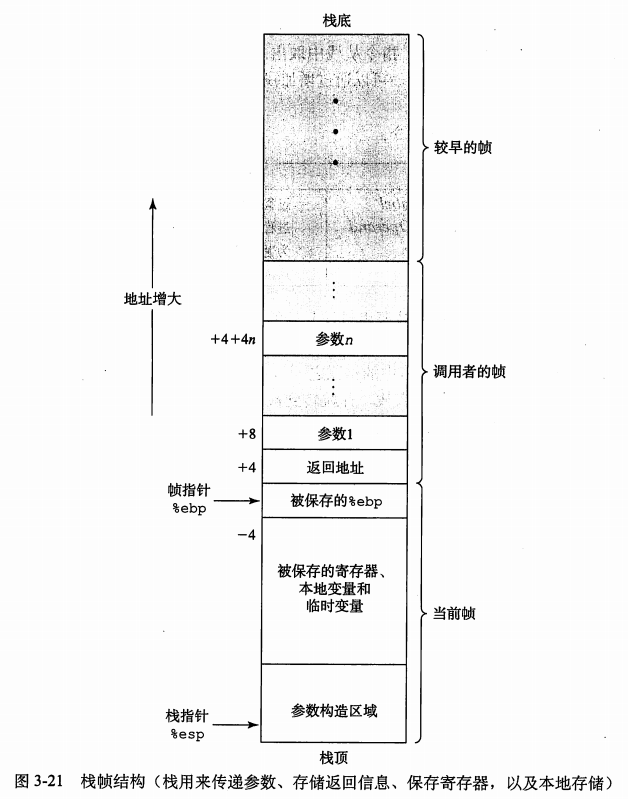
假设过程 P(调用者)调用了过程 Q(被调用者),则 Q 的参数存放在 P 的栈帧中。调用 Q 时,P 的返回地址被压入栈中,形成 P 的栈帧的末尾。返回地址就是当过程 Q 返回时应该继续执行的地方。Q 的栈帧紧跟着被保存的帧指针副本开始,后面是其他寄存器的值。
栈中会存放局部变量。有下面三个原因:
- 不是所有的变量都能放到寄存器中的,没有那么多寄存器。
- 有些局部变量是数组,或者结构体。
- 有些时候需要对某些变量使用
&运算符,获得其地址,因此要将其放在栈中。寄存器变量是没有地址的。
栈向低地址方向增长。可以利用指令pushl将数据存入栈,利用popl将指令从栈中取出。由于栈指针%esp 始终指向栈顶,所以可以通过减小栈指针的值来分配空间,增加栈指针来释放空间。
调用方式
下面是有关过程调用和返回的指令:
| 指令 | 描述 |
|---|---|
| call Label | 过程调用 |
| call Operand | 过程调用 |
| leave | 为返回准备栈 |
| ret | 返回 |
call 指令的效果是将返回地址压入栈中(也就是保存返回地址),然后跳转到被调用过程的起始处。返回地址是在程序中紧跟在 call 后面的那条指令的地址。这样当被调用过程返回时,执行从此(call 指令的下一条指令)继续。
ret 指令从栈中弹出返回地址,然后跳转到返回地址的位置。
寄存器共享
寄存器是在过程调用中唯一能被所有过程共享的资源。因此我们必须保证被调用者不会覆盖某个调用者稍后会使用的寄存器的值。根据惯例,寄存器%eax、%edx、%ecx被划分为调用者保存寄存器。当过程 P 调用过程 Q 时,Q 可以覆盖这些寄存器的数据,而不会破坏 P 所需的数据。寄存器%ebx、%esi、%edi被划分为被调用者保存寄存器,Q 在覆盖这些寄存器的值之前,必须将其压入栈中,然后在返回前恢复他们。看下面的例子:
int P(int x)
{
int y = x * x; //变量 y 是在调用前计算的
int z = Q(y);
return y + z; //要保证变量 y 在 Q 返回后还能使用。
}
-
基于调用者保存:过程 P 在调用 Q 之前,将 y 的值保存在自己的栈帧中;当 Q 返回时,过程 P 由于自己保存了这个值,就可以从自己的栈中取出来。
-
基于被调用者保存:过程 Q 将值 y 保存在被调用者保存寄存器。如果过程 Q 和其他任何 Q 调用的过程,想使用保存 y 值的被调用者保护寄存器,它必须将这个寄存器的值存放到栈帧中,然后在返回前恢复 y 的值。
这两种方案都是可行的。
过程实例
考虑下面给出的C语言代码。函数 caller 中包括一个对函数 swap_add 的调用。
int swap_add(int *xp, int *yp)
{
int x = *xp;
int y = *yp;
*xp = y;
*yp = x;
return x + y;
}
int caller()
{
int arg1 = 534;
int arg2 = 1057;//局部变量,以及作为参数
int sum = swap_add(&arg1, &arg2);
int diff = arg1 - arg2;
return sum * diff;
}
下面给出 caller 和 swap_add 的栈帧。左图是还未执行到 int sum = swap_add(&arg1, &arg2);语句之前。可以看到因为要对局部变量取地址,所以要把局部变量放到栈中。栈指针一直指在栈顶。帧指针目前指在最上面,代表过程 caller 的栈帧开始的位置。
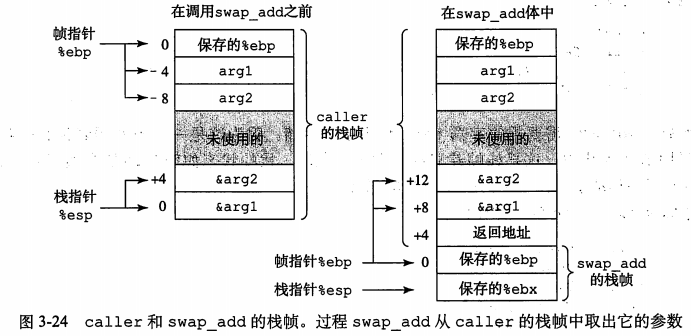
调用了 swap_add 之后,栈成了左边的样子。因为调用函数会使用一个 call 指令。这个指令会压入一个返回地址。紧接着开始了 swap_add 的栈帧。此时 %ebp被更新。在被调用者函数内,使用12(%ebp) 和 8(%ebp)就可以取到两个参数。
下面看一下汇编代码:
caller:
pushl %ebp # 保存旧的 %ebp 的一个副本
movl %esp, %ebp # 设置新的栈顶指针,到栈顶
subl $24, %esp # 栈指针减去24,即分配24个字节的空间
movl $534, -4(%ebp) # int arg1 = 534;
movl $1057, -8(%ebp) # int arg2 = 1057; 这两个局部变量都保存在栈上
leal -8(%ebp), %eax # 取地址 &arg2,放到寄存器中
movl %eax, 4(%esp) # 保存到栈上
leal -4(%ebp), %eax #
movl %eax, (%esp) # 同上
call swap_add # 参数都齐全了,可以调用函数了
swap_add:
push %ebp # %ebp移动了,栈发生了改变
movl %esp, %ebp # 这两步同 caller,是过程调用的“建立部分”
push %ebx # 这是一个被调用者保存寄存器,将旧值压入栈中,作为栈帧的一部分
# 从这里开始才是真正的C语言代码体现的 swap_add 内容
movl 8(%ebp), %edx # 获得参数1,放到寄存器中
movl 12(%ebp), %ecx # 获得参数2,放到寄存器中
movl (%edx), %ebx # int x = *xp;
movl (%ecx), %eax # int y = *yp;
movl %eax, (%edx) # *xp = y;
movl %ebx, (%ecx) # *yp = x;
addl %ebx, %eax # 计算 x + y,结果放在%eax中,所以会返回%eax中的值
popl %ebx # 这是被调用过程的“结束过程”
pop %ebp # 恢复保护寄存器,弹出栈帧指针
ret # 此时栈顶是返回地址,ret指令就弹出这个地址,然后跳转到这个地址
# caller 剩余的代码会紧跟在后面
movl -4(%ebp), %edx # 此时 %ebp 指的是 caller 自己的 %ebp
subl -8(%ebp), %edx # int diff = arg1 - arg2;
imull %edx, %eax # 计算 sum * diff,%eax是存放 swap_add 返回值的
leave
ret
说句题外话,看到这个 swap 函数之后,也能解答一个初学者的问题:为什么下面这个 swap 函数不能交换参数的值?
void swap(int a, int b)
{
int temp;
temp = a;
a = b;
b = temp;
}
swap 函数被调用时,用寄存器存参数 a 与 b,作为临时存储,然后对寄存器内的两个值做了一通操作,并没有影响到存储器中 a 与 b 的值。
用 leave 指令可以使栈做好返回的准备。其作用就是将帧指针移到栈顶然后抛出。
分配给 caller 的栈帧有24个字节,8个用于局部变量,8个用于传参,还有8个字节未使用。这主要是满足 x86 的一个编程指导方针——对齐(alignment)的要求:一个函数使用的栈空间必须是 16 字节的整数倍,包括一开始保存的 %ebp 的 4 字节和返回值的 4 字节,所以共分配了 24 个字节。
从这个例子我们可以看到,编译器根据简单的惯例来产生管理栈结构的代码。栈帧中需要包含:
- 帧指针副本,标识自己的栈帧从哪里开始
- 局部变量(如果需要)
- 临时空间(如果需要)
- 调用其他函数之后,压入返回信息
可以用相对于 %ebp 的偏移量来访问变量和参数。可以用通过加减栈顶指针来释放或分配空间。在返回时,必须将栈恢复到调用前的状态,恢复所有的被调用者保护寄存器和 %ebp,重置 %esp。为了让程序能正确执行,让所有过程遵循一个统一一致的惯例是很重要的。
一个调用过程(call 指令之后)的汇编代码包括三个部分:
- 建立部分:压入帧指针,移动栈指针,压入需要保存的寄存器的值。
- 主体部分:函数的功能部分
- 结束部分:恢复需要保存的值,弹出帧指针,返回。
递归
有了前面的的基础,要理解递归就简单很多了。为什么过程能调用自己本身呢?因为每个调用在栈中都有自己的私有空间。多个未完成的调用,他们局部变量,之间不会相互影响。栈的原则很自然地提供了一个策略:过程被调用时分配局部存储,返回时释放。
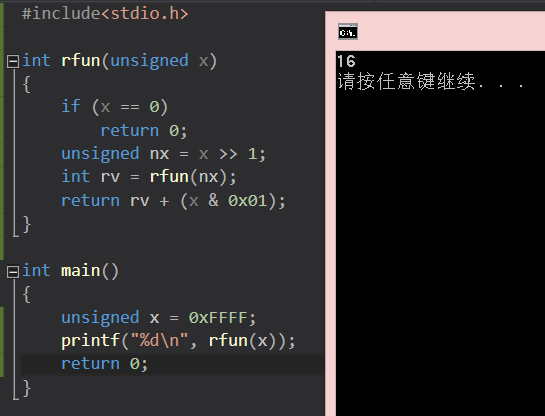
上一个课后题的例子:
一个具有通用结构的C函数如下:
int rfun(unsigned x)
{
if(???)
return ??? ;
unsigned nx = ??? ;
int rv = rfun(nx);
return ???;
}
给出对应的汇编代码,其中省略了建立和完成代码,请通过汇编代码分析:
- 被调用者保护寄存器 %ebx 存的是什么?
- C语言代码中的问号应该填什么?
- 描述C语言代码的作用。
汇编代码如下:
movl 8(%ebp), %ebx # 开头第一句一般是取参数。
movl $0, %eax # int y = 0; (变量名随便取的)
testl %ebx, %ebx # 测试 x
je .L3 # if(x==0) return;
movl %ebx, %eax # else { y = x;
shrl %eax # y >>= 1;}
movl %eax, (%esp) # 压入栈中,很明显,是为了下一次调用使用
call rfun # 递归调用
# 别忘了 call 会压入返回地址,然后跳转
movl %ebx, %edx
andl $1, %edx # %edx 中存的值是 (x & 1)
leal (%edx, %eax), %eax # 寄存器是公用的资源。
# y = (x >> 1) + ( x & 1)
.L3:
经过上面的分析可以得出解答:
%ebx存放的是参数 x 的值。- 我们在汇编中分析出来的一个新变量
y应该就是C语言代码中的nx。 - C语言代码如下:
int rfun(unsigned x)
{
if(x == 0)
return 0;
unsigned nx = x >> 1;
int rv = rfun(nx);
return rv + (x & 0x01);
}
这段代码的作用是:递归地计算一个无符号数的每一位上的数字之和。
对于递归,目前我觉得有一个很恰当的比喻:
我们使用词典查词,本身就是递归,为了解释一个词,需要用到更多词。当你查一个词,发现要解释这个词的一句话里有一个词你不懂,于是你开始查这第二个词。可惜的是,查第二个词的时候仍然有不懂的词,于是查第三个词……这样一直查下去,知道有一个词的解释你完全能看懂,那么递归走到了尽头,开始返回,然后你按照查词顺序的倒序逐个看明白了之前你所查的每个词的意思。你最开始查的那个词,是最后才知道其意思的。
所以对于理解递归,很重要的一点是要理解递归什么时候触及到边界,开始返回了。
古之欲明明德于天下者,先治其国;欲治其国者,先齐其家;欲齐其家者,先修其身;欲修其身者,先正其心;欲正其心者,先诚其意;欲诚其意者,先致其知,致知在格物。物格而后知至,知至而后意诚,意诚而后心正,心正而后身修,身修而后家齐,家齐而后国治,国治而后天下平。(注:这不是递归,只是函数调用嵌套比较深)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号