【CSAPP笔记】6. 汇编语言——控制
到目前为止我们只考虑了直线代码的执行行为,也就是指令一条接着一条执行。C语言中的某些语句,比如条件语句、循环、分支语句,要求有条件地执行,或根据某些表达式的结果决定操作的顺序。机器代码提供基本的低级机制来实现有条件的行为:测试数据值,然后根据测试结果来改变控制流或数据流。
先介绍通过控制流来实现有条件的行为。用jump指令可以改变一组机器代码的执行顺序。jump指令指定控制应该传递到程序的哪个其他部分,这可能依赖于某个测试的结果。
条件码
除了整数寄存器,CPU 还负责维护一组单个位的条件码(condition code)寄存器。最常用的条件码有:
| 条件码 | 作用 | 描述 |
|---|---|---|
| CF | 进位标志,carry | 最近的操作使得最高位产生了进位。可以用来检查无符号操作数的溢出。 |
| ZF | 零标志,zero | 最近的操作得出的结果为零 |
| SF | 符号标志,sign | 最近的操作得出的结果为负 |
| OF | 溢出标志,overflow | 最近的操作导致了一个补码溢出(正溢或负溢) |
假设我们用一条 ADD 指令完成一个 C语言表达式 t=a+b的功能,这里变量都是整型。然后,条件码就是根据下面的表达式设置的:
| 条件码 | 通过下面的表达式来设置 | 描述 |
|---|---|---|
| CF | (unsigned) t < (unsigned) a | 和比加数小,说明出现无符号溢出 |
| ZF | (t == 0) | 结果为零 |
| SF | (t < 0) | 结果为负数 |
| OF | (a < 0 == b < 0) && (t < 0 != a < 0) | a、b同时为负,而和为正;或a、b同时为正,而和为负。说明出现了有符号溢出 |
基础的整数算术操作
下面列出汇编中基础的整数算术操作:
| 指令 | 效果 | 描述 |
|---|---|---|
| leal S, D | &S → D | 加载地址 |
| INC D | D + 1 → D | 自增1 |
| DEC D | D - 1 → D | 自减1 |
| NEG D | -D → D | 取负 |
| NOT D | ~D → D | 取补 |
| ADD S, D | S + D → D | 加 |
| SUB S, D | S - D → D | 减 |
| IMUL S, D | S * D → D | 乘 |
| XOR S, D | S ^ D → D | 异或 |
| OR S, D | S ` | ` D → D |
| AND S, D | S & D → D | 或 |
| SAL k, D | D << k → D | 左移 |
| SAR k, D | D >> k → D | 算术右移 |
| SHL k, D | D >> k → D | 逻辑右移 |
leal 指令不改变任何条件码,因为它是用来做地址计算的。除此之外,其他指令都会会涉及改变条件码。
设置条件码的特殊指令
有两类指令,它们只设置条件码而不改变其他任何寄存器。它们是比较和测试指令,CMP S2, S1 和 TEST S2, S1,比较指令是基于两个操作数的差来设置条件码。测试指令是给予两个数的按位与来设置条件码。常见的用法有:两个操作数是相同的(例如用指令 testl %eax, %eax来测试寄存器中存的是零、正数还是负数);或者有一个操作数是一个掩码,指定哪些位应该被测试。
| 指令 | 基于 | 描述 |
|---|---|---|
| CMP S2, S1 | S1 - S2 | 比较 |
| TEST S2, S1 | S1 & S2 | 测试 |
访问条件码:SET指令
条件码通常不直接读取。有三种方法可以使用,下面依次介绍他们
- 可以根据条件码的组某个组合将一个字节设置为 0 或 1 。
- 可以跳转到程序的其他部分。
- 可以有条件地传送数据。
SET指令根据条件码的组合,将某一个字节设置为 0 或者 1 。指令名字后面的后缀指明了他们的功效和需要考虑的条件码组合的不同。
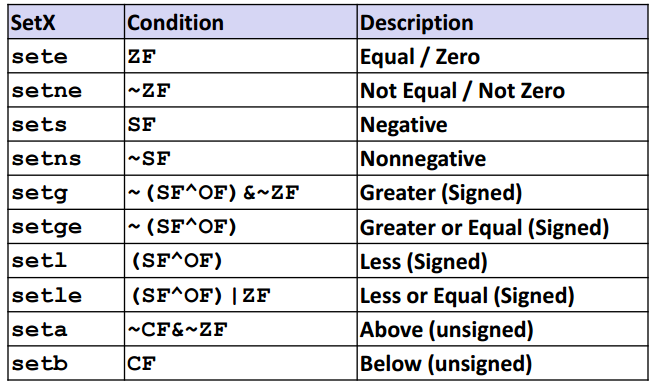
指令|参考英文|效果|注释
---|---|---|---|---
sete D| equal | 相等/零|
setne D| not equal | 不等/非零|
sets D| sign / negetive | 负数|
setns D| nonnegtive | 非负数|
setg D| greater | 大于(有符号>) | a与b的差不为零,差值为正时不能溢出,差值为负时必须溢出,则可以认定a大于b
setge D| greater or equal | 大于等于(有符号≥)|与上面条件相似,只是去掉a与b差值不能为零的限制
setl D| less | 小于(有符号<)| a与b的差值为正的时候必须溢出,或a与b的差值为负但没有发生溢出,则可以认定a小于b
setle D| less or eqaul | 小于等于(有符号≤)| 与上面条件相似,只是多加了一条当a与b的差值为0时也可以认定a小于等于b
seta D| above | 超过(无符号>)| 计算无符号数a和b的差值时最高位没有进位,且结果也不等于零,认为无符号数a大于b
setae D| above or equal | 超过或相等(无符号≥) | 与上面条件相似,但去掉不等于零的限制
setb D| below |低于(无符号<)| 计算无符号数a和b的差值时最高位没有进位
setbe D| below or equal | 低于或等于(无符号≤)| 与上面条件相似,但多加了一条当a与b的差值为0时也可以认定a小于等于b
SET指令的操作数是8个单字节寄存器之一,或是存储一个字节的存储器位置,然后将这个字节设置为 0 或 1。下面看一个典型的计算C语言表达式 x > y 的指令序列。
int gt(int x, int y)
{
return x > y;
}
对应的汇编指令序列:
cmpl %eax, %edx # Compare x : y
setl %al # Set low byte of %eax to 0 or 1
movzbl %al, %eax # Set remaining bytes of %eax to 0
%al 是一个单字节的寄存器元素,变量x和y分别存放在%eax和%edx中,然后使用setl指令,如果 a > b,则把%al设置为 1,反之则设置为 0。movzbl是将做了零扩展的字节传送到字,这么做是因为我们为了得到一个32位结果,就要把高24位进行扩展,这里是全部清 0。
注意机器代码如何区别有符号和无符号值是很重要的。同C语言不同,机器代码不会将一个内存中的值和一个具体的数据类型联系起来。有些情况下,对于无符号数和有符号数使用的操作是相同的,根本原因是因为许多算术运算对于两者都有一样的位级行为。另外的一些情况下,对于无符号数和有符号数就要采取不同的操作,比方说不同版本的移位运算,乘除法,不同的条件码组合。
条件分支
正常执行情况下,指令会按照它们的顺序一条条执行。跳转(jump)指令会导致程序执行切换到一个全新的位置。
jump 指令的字节编码
在汇编代码中,跳转的目的地通常是用一个标号(label)来标识。考虑下列的汇编代码序列(完全人为编造):
movl $0, %eax
jmp .L1
movl (%eax), %edx
.L1:
popl %edx
指令jmp会导致跳过movl指令,从pop处开始执行。jmp是无条件跳转,而下表列出来的跳转指令都是有条件跳转,它们根据条件码组合进行跳转,或选择不跳转,继续执行下一条指令。条件码的组合与其意义和SET指令类似。
前面提到,PC(program counter)——程序计数器的作用是指示要执行的下一条指令的地址。跳转指令有几种不同的编码方法,最常用的是PC相关寻址。它们会将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差值作为编码。当执行PC相关寻址时,PC的值是跳转指令后面那条指令的地址,而不是跳转指令本身的地址。下面看一个例子:
# 一段汇编代码:
jle .L2
.L5:
....
....
jg .L5
.L2:
....
下面是汇编器产生的 .o 文件的反汇编版本:
8: 7e 0d jle 17<main+0x17>
a: 89 d0 ..........
....
....
15: 7f f3 jg a<main+0xa>
17: 89 d0 ..........
在反汇编中,第一行是跳转指令jle,它指定了跳转目标为0x17,也就是汇编代码中标签L2。第二行是跳转指令jg,它指定了跳转目标为0xa,也就是汇编代码中的标签L5。观察指令的字节编码,可以看到第一条跳转指令的目标编码(在第二个字节中)是0xd,将其加上PC的值,(PC值是跳转指令后面那条指令的地址:0xa)得到结果是0x17,就是正确的地址。
翻译条件分支
将条件表达式和语句从C语言翻译成机器代码,一个方法就是使用C语言中的 goto 语句。使用 goto 语句常常被认为是一种不好的语言风格,因为它破坏了程序的结构性,并使代码非常难以阅读和调试。这里我们使用它是为了描述汇编代码在完成代码程序控制转移的流程。
C语言中的if-else的通用形式模板是这样的:
if(text-expr)
then-statement
else
else-statement
对应汇编实现的通用形式模板是这样的:
t = text-expr
if(!t)
goto false;
then-statement
goto done;
false:
else-statement;
done:
下面举一个具体的例子:
//一份返回绝对值差值的C语言代码
int absdiff(int x, int y)
{
int result;
if (x < y)
result = y - x;
else
result = x - y;
return result;
}
//与之等价的goto版本
int absdiff_goto(int x, int y)
{
int result;
if (x >= y) goto Else;
result = y - x;
goto Done;
Else:
result = x - y;
Done:
return result;
}
# 汇编代码
# 变量x存放在 %ebp+8,变量y存放在 %ebp+12
movl 8(%ebp), %edx # 将变量x存放在寄存器%edx中
movl 12(%ebp), %eax # 将变量y存放在寄存器%eax中
cmpl %eax, %edx # 比较 x:y
jge .L2 # 如果满足大于或等于,跳转到标签L2
subl %edx, %eax # y - x 结果放到 %eax
jmp .L3
.L2:
subl %eax, %edx # x - y 结果放到 %edx
movl %edx, %eax # 将 %edx 里的结果放到 %eax
.L3: # return 的是 %eax 里面的值
逆向工程(reverse engineer),通过分析汇编代码,来推出C语言代码,做这样的练习对理解汇编知识和原理有很大的帮助。只看上面这段汇编代码,你能不能推出C语言的代码来呢?
条件传送
条件分支的操作方法是实现控制的转移——当条件满足时,沿着一条路径进行,不满足时,沿另一条路径进行。这种机制简单明了,但在现代处理器上,会非常的低效率。为什么呢?可以想象,如果一定要彻底执行完一条指令之后才开始新的一条指令,那机器的性能没有被最大程度地发挥。因此 CPU 都是依靠流水线(pipeline)进行操作的。例如一条指令需要ABCDE五个操作,在执行完这一条指令的A操作之后,下一条指令的A操作同时被加载进来开始执行,这样子效率会很高。
当机器遇到条件跳转的时候,机器不能确定是否会进行跳转。处理器采用非常精密的分支预测逻辑来预测每一条条件跳转指令到底会不会执行。只要猜测还算可靠(现代处理器要求对条件跳转的预测准确度在百分之九十以上),那么流水线模型会运行得很好。一旦错误预测了一个条件跳转指令,那么意味着处理器要丢掉它为该跳转指令后所有指令已经做的工作,去一个新的,正确的跳转位置开始填充流水线。这意味着一个错误的预测会带来严重的惩罚——大约20~40个时钟周期的浪费。
处理器支持条件传送(condition move),这与条件跳转不同。后者改变的是控制流,而前者传递的是数据流。其实条件传送就是我们熟悉的三目运算符:?:。例如上面的返回差值绝对值的代码的条件传送版本就是:
int absdiff(int x, int y)
{
int result;
result = x < y ? y - x : x - y;
return result;
}
与之等价的,能体现对应的汇编代码的原理的goto版本:
int cmovdiff(int x, int y)
{
int t1 = y - x;
int t2 = x - y;
int test = x < y;
if(test) t2 = t1;
return t2;
}
C语言中的条件传送通用形式模板是这样的:
vt = then-statement
v = else-statement
t = text-expr
if(t) v = vt;
可以看到:执行条件传送时,无需预测测试结果,而是把两个分支的运算都完成。处理器只是读取值,然后检查条件码,然后要么更新目标寄存器,要么保持不变。这会使得工作效率变高,因为它规避了预测错误带来的惩罚。
也不是所有的条件表达式都适合用条件传送的。如果两个表达式中有任意一个可能产生错误或者副作用,就会导致非法的行为,例如:
int readpointer(int *xp)
{
return (xp ? *xp : 0);
}
乍一看似乎没什么问题:如果指针为空,则返回0,否则返回指针指向的整数。但其实这个实现是错误的。因为条件传送对指针 xp 的引用是一定会发生的,如果 xp 是一个空指针,会导致一个间接引用空指针的错误。
条件传送也不会总是改进效率。如果两个表达式需要做大量的计算,那么当对应的条件不满足时,所做的工作就白费了。编译器必须权衡条件传送多做的计算,和条件分支预测错误惩罚之间的相对性能。
循环
C语言提供多种循环结构,for、while 和 do while。但看到这里大家也明白,汇编里没有相应的高级抽象指令,而是通过用测试、条件码、跳转组合起来,形成循环的效果。
do while
// do while 的 C 语言代码:计算阶乘
int fact_dowhile(int n)
{
int result = 1;
do{
result *= n;
n--;
}while(n > 1);
return result;
}
//等价的goto版本:
int fact_dowhile_goto(int n)
{
int result = 1;
loop:
result *= n;
n--;
if(n>1)goto loop;
return result;
}
上述代码的汇编代码是:
movl 8(%ebp), %edx # 获得变量n
movl $1, %eax # int result = 1;
.L2:
imull %edx, %eax # result *= n;
subl $1, %edx # n--;
cmpl $1, %edx
jg .L2 # if(n>1) loop
# return
| 寄存器 | 变量 | 初始值 |
|---|---|---|
| %eax | result | 1 |
| %edx | n | n |
有的时候,确定哪些寄存器放的是什么值,会很有挑战性,特别是在循环代码中。看汇编代码时,理解他们的关系,关键是找到程序值和寄存器的映射关系。编译器常常试图将多个程序值映射到同一个寄存器上,最小化寄存器的使用率。
do-while循环的通用结构是:
//C语言代码
do
Body
while (Test);
//goto版本
loop:
Body
if (Test)
goto loop
while
while循环的通用结构是:
// C 语言 While
while (Test)
Body
// goto 版本
t = test-expr
if(!t)
goto done;
loop:
Body
t = test-expr
if(t) goto loop;
done:
while 与 do-while 最大的区别是它先对 test-expr 求值,所以在第一次执行循环主体 Body 之前,循环就有可能终止。而 do-while 是一定会执行至少一次循环主体的。
for
// C语言的for
for (Init; Test; Update)
Body
// 先转换到while
Init;
while (Test) {
Body
Update;
}
// 转换成do-while
Init;
if(Test)
goto done;
do{
Body
Update
}while(Test);
done:
//再转换到goto代码
Init;
t = Test;
if(!t)
goto done;
loop:
Body;
Update;
t = Test;
if(t)
goto loop;
done:
switch 语句
switch 语句可以根据一个整数索引值进行多重分支(multi-way branching)。处理具有多种预测可能的分支时,这种语句特别有用,而且提高了C语言代码的可读性。
通过使用一种数据结构,叫做跳转表(jump table),使得实现 switch 十分的高效。跳转表是一个数组,表项 i 是一个代码段地址,代码段是当索引值等于 i 时程序应采取的动作。开关索引值就是用来执行一个跳转表内数组引用,来确定目标指令的情况。和用一组很长的 if-else 嵌套不同,使用跳转表的优点是执行开关语句的时间和开关的数量无关。
下面通过一个具体的例子来讲解:
int switch_eg (int x, int n){
int result = x;
switch (n) {
case 100:
result *= 13;
break;
case 102:
result += 10;
case 103:
result += 11;
break;
case 104:
case 106:
result *= result;
break;
default:
result = 0;
}
return result;
}
这个例子包含了很多特殊情况:
- 共享的条件:104 和 106 会执行相同的部分。
- 没有break:102 会继续执行 103 的部分。这个要十分小心,一般Switch出现错误的源头就是忘了break。如果确定要这么用,最好写上注释。
- 缺失条件:101 和 105
具体怎么办呢?使用跳转表。(你会发现表的解决方式在很多地方都有用:虚函数,继承,内存管理,动态规划等等。)下面的汇编代码就是跳转表:
.section .rodata # 只读数据
.align 4 # 对齐要求
.L7:
.long .L3 # x = 0 时选择,L3里操作是 result *= 13; goto done;
.long .L2 # x = 1 时选择,因为101是缺失条件,直接 goto default;
.long .L4 # x = 2 时选择,result += 10; 然后顺序执行,没有break
.long .L5 # x = 3 时选择,result += 11; goto done;
.long .L6 # x = 4 时选择,result *= result; goto done;
.long .L2 # x = 5 时选择,因为105是缺失条件,直接 goto default;
.long .L6 # x = 6 时选择,result *= result; goto done;注意到104和106执行相同的部分
对 switch 语句的处理是:
movl 8(%epb), %edx # 参数 x
movl 12(%epb), %eax # 参数 n
subl $100, %eax # n -= 100;
cmpl $6, %eax
ja .L2 # if(n>6) goto default;
jmp *.L7(,%eax,4) # else goto *jumptable[index];
C语言的原始代码是 100、102~106 这样的值,针对这些值编译器可以选择做出优化——编译器将 n 的值减去 100,把取值范围移动到 0~6 之间。根据 switch 的参数 n,决定是进入跳转表还是 default 分支。jmp 指令的操作数有前缀 * ,代表这是一个间接跳转,操作数指定一个存储器位置。跳转位置是跳转表里面保存的一个地址,由寄存器 %eax 给出的索引作为引导。(在数据结构部分可以知道如何将数组引用翻译成机器代码)
编译C语言代码时注意事项
采取比较低的优化等级,这样子才能看到一些特性,不至于因为被编译器优化而看不到我们想要的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号