第四次作业
哦、、原来寒假早已经过了吗,有点迷
本次作业的github链接
有 Microsoft Visual Studio 2017 的同学,可以直接打开 四则运算/四则运算.sln 这个项目。不然的话麻烦请自己重新用自己的编译器编译啦,并把对应的文件放好!
相同部分
1) 两位合作者的学号和对应博客主页链接
赵畅 111500206 http://www.cnblogs.com/ZCplayground/
胡绪佩 031602114 http://www.cnblogs.com/heihuifei/
2)描述实现设计思路
这次作业的思路不难理解。同一个软件的各种语言版本,不应该写在代码里,而是要把这些语句抽出来形成“资源文件”,而且这是很有必要做的一件事情。
在看作业时,老师给了一条参考链接How to: Create a Localized Version of a Resource File,在链接的底部,有一个提示,让我们参考CultureInfo类。如果点进去看的话,就进入了无限的大坑……我和王源同学一样,一开始也是一头扎进msdn的文档中……很多都是.Net和C#的东西。啃API的时候,也强行啃了一些代码。例如:

这里赞一下王源同学,王源同学看文档学习的能力非常强!他最后是通过啃文档,调用这些API,完成了任务,而且效果非常的不错!然而我却看不下去这些API了,于是乎就和栋哥聊了一会天……

什么,简单的方式???

仔细一想,确实也不应该为刚刚学C++的同学们布置有着这么奇奇怪怪完成方式的任务,是我一开始的思路就被文档下面的那个CultureInfo类给导偏了。
于是乎,在C语言文件操作的基础上,我就简单地学习了一下C++的文件流操作,并且想了一些办法实现了通过文件读写来达到本次作业要求的最核心的一条要求:
当每增加一种语言时,是不可通过修改源代码及重编译的方式实现
这不仅让我们所有与用户交互的显示内容不能写在代码里,而且需要我们想出一种新思路——不仅能够让程序自动识别支持哪些语言,还能可以调用它们、显示给用户。
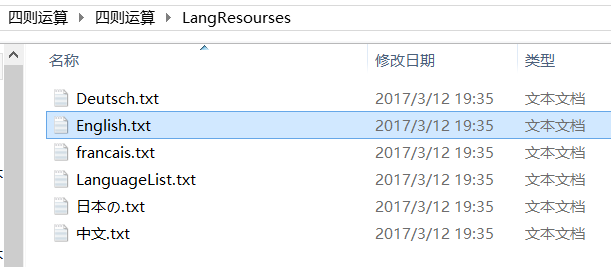
在代码项目的文件夹下,我新建了一个文件夹,名为 LangResourses。其中有一个文本文件叫做 LanguageList.txt,其内容如图所示,里面包含着所支持各种语言的名字。用户可以通过输入这些语言的名字来选择需要的版本。程序识别用户输入的语言后,可以打开对应的文件,调用对应的“资源”(虽然没放到.rc文件中)。
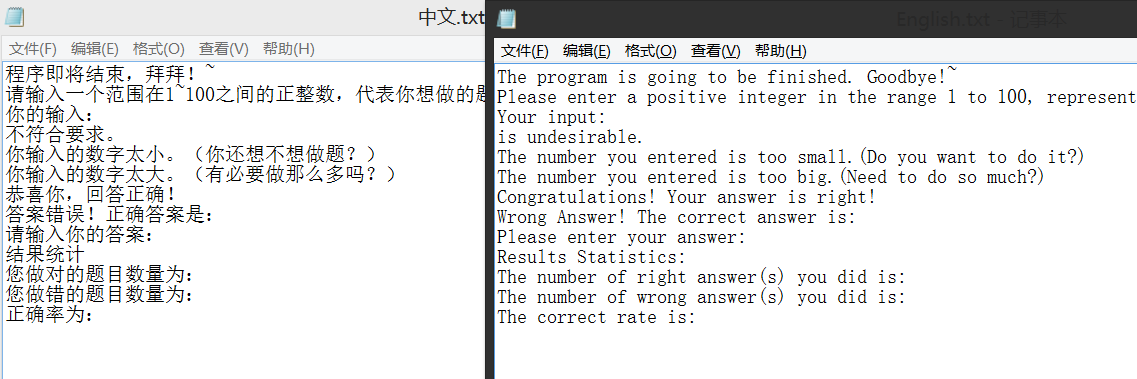
而下面的是文本文件 中文.txt 和 English.txt 的内容。同一行的内容意思是一样的,只不过是所使用的语言不同(这是一个核心操作)。其余的文件中是其他语言的翻译版本(大家可以clone下来看看)。
我主要是在之前的版本上进行迭代。会显示与用户交互信息的一些函数都有做修改,例如输入检测、答案判定、结果输出等等。最重要的是多了一个头文件LanguageResource.h。其中包含了以下内容:
- 展示目前支持的语言列表
- 检测用户输入的语言是否支持。
- 根据正确的语言文档路径,取得其中的内容以便使用。
最重要的关键一步是获得某个语言资源中的文件。本来我是这样想的:由于fgets这个函数,使用过一次,可以使得光标停留在下一行开头。下一次调用fgets时,就可以读取下一行。所以说,我可以在txt文件中按照顺序排列好一些文段,然后不断地使用fgets就可以。但是,在我之前的代码中包括了输入检测的模块,这就意味着不能按照上面那个思路来(因为可能多次输出相同的内容)。我也不想放弃这个输入检测模块,这个模块对于要给用户使用的程序来说非常重要。更何况,用户输入的题目数量也不一定,用fgets直接一行行输出的思路是行不通的。
最后,我想到了预先读取txt文件中的内容,把内容存到一个指针数组里。通过控制下标i,让相同的下标代表相同的内容。对应在不同的文件中,就是相同的行数代表相同的内容,只是语言版本的不同。核心代码如下:
/*根据正确的语言文档路径,取得其中的内容以便使用。存放到全局指针数组Resource中*/
void GetResource(char * filepath)
{
fstream File;
File.open(filepath, ios::in);
char one_Line[MAXLEN];
/*将每行文件的内容放到Resource[i]中,这样可以通过下标i访问各种语句*/
int i;
for (i = 0; File.getline(one_Line, MAXLEN); i++)
{
Resource[i] = (char *)malloc(MAXLEN * sizeof(char));
strcpy_s(Resource[i], MAXLEN * sizeof(char), one_Line);
}
File.close();
}

(这里的对齐,简直强迫症福利,但传到github上就乱了,心很累)
3)程序实现和结果测试的截图
第一个图展示了中文版本。上个版本已有的输入检测就不展示截图了。(在还没有选择语言的时候,使用的界面语言是英语)
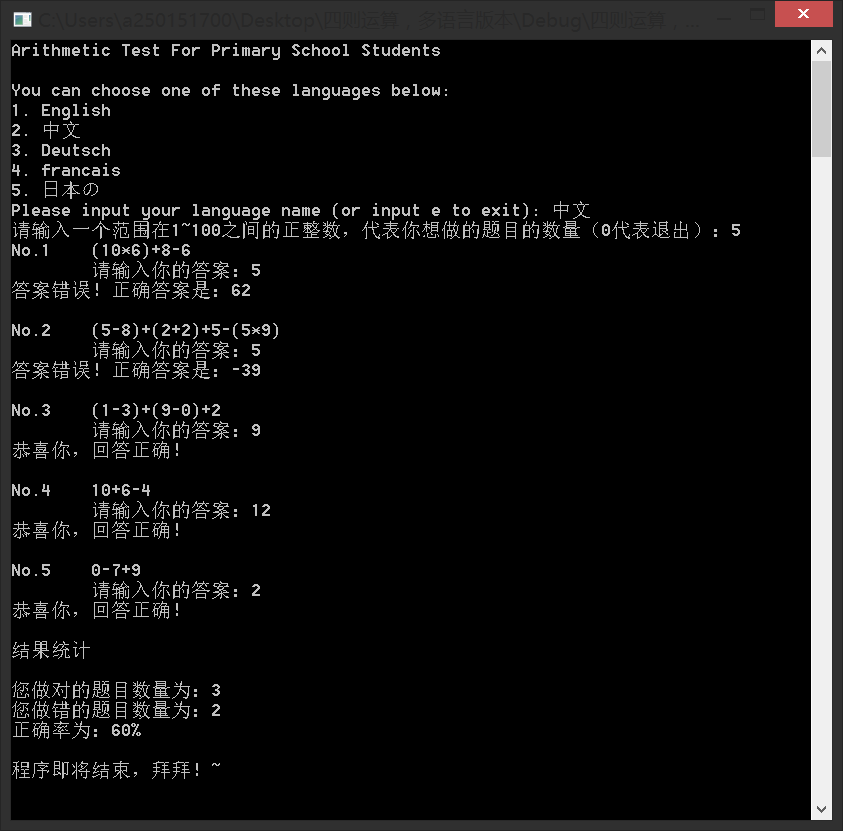
第二个图展示了日文版本,顺带一提,输入语言时我也写了输入检测,如果用户输入了不支持的语言或者输入错误,会让用户重新输入一次。但也可以通过输入e来退出。

4)提交日志截图
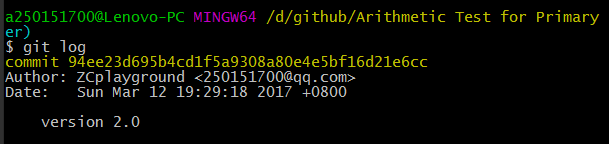
5)两位同学的分工和协作证据截图
胡同学由于文件操作没时间学会,又临近deadline,所以这次的所有工作都是由我来完成的。
差异部分
此次作业感想
上面也提到了,一开始被文档的导向吸引,所以思路很狭窄。后面也是跟栋哥聊天才发现不对……最后想出来一个还不错的方式。通过这种方式可以比较好的学习C++文件流,也可以复习(如果不会的话就是学习)一下指针数组的用法。
这次完成的作业同样有不足。本来是有想出来一个问题的:

所以有考虑寻找一下C语言或者C++中,能够支持Unicode编码的方法。然而查找了很多资料,试过了很多方法,依旧失败。最坑爹(浪费了很多精力)的当属wfstream流和wchar_t(宽字符)。对于宽字符的正确输出方式,虽说网上有很多人写了转换函数之类,然而这东西涉及编码规则,有很多位运算。在对Unicode编码不是特别了解的情况下,最后我还是放弃使用这种机制。后来王源同学找到msdn文档说fopen有打开Unicode文本文件的功能,我编码一番确实可以。但从文件输出文字依然困扰着我,于是我就放弃了。
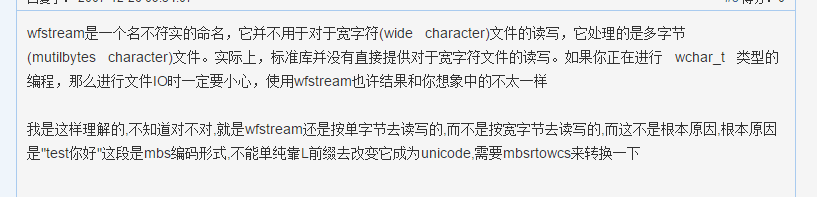
最后的解决方案:在法语翻译的时候,用了不是特别标准的(百度)翻译,内容是ANSI字符的(其他用的是Google翻译)。
在编码时,有一点体会:在上一次作业时,把接口写好、模块分好。在此基础上,给自己迭代版本时带来了一定的方便性。如果偷懒不把这块工作做好(例如注释、接口什么的),那么软件的可维护性会很差。
另外,把嵌在代码中的用户交互语言删除,换成调用资源的写法,让整个代码看起来清爽许多,并且如果要添加新的语言的版本,更新资源的内容即可。
参考链接
以下是msdn文档的一些API:
- System.Globalization 命名空间
- CultureInfo 类
- Console 类
- UnicodeEncoding 类
- ResourceManager::GetResourceSet 方法
- ResourceSet 类
一些文件操作:
其他:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号