数据类型和sizeof
类型
整数
char short int long long long
浮点数
float double long double
逻辑
bool
指针
自定义类型
类型区别
名称: int long double
输入输出的格式化:%d ,%ld, %lf (入) %f(出)
所表达的数的范围:char < short < int < float < double
内存中所占据的大小:1字节到16字节
内存中的表达形式: 二进制数(补码)【整型】 编码【浮点数】
C是有类型的语言
有检查,但不严格
类型安全
面向底层强调类型,离底层越远,越强调逻辑
整数类型
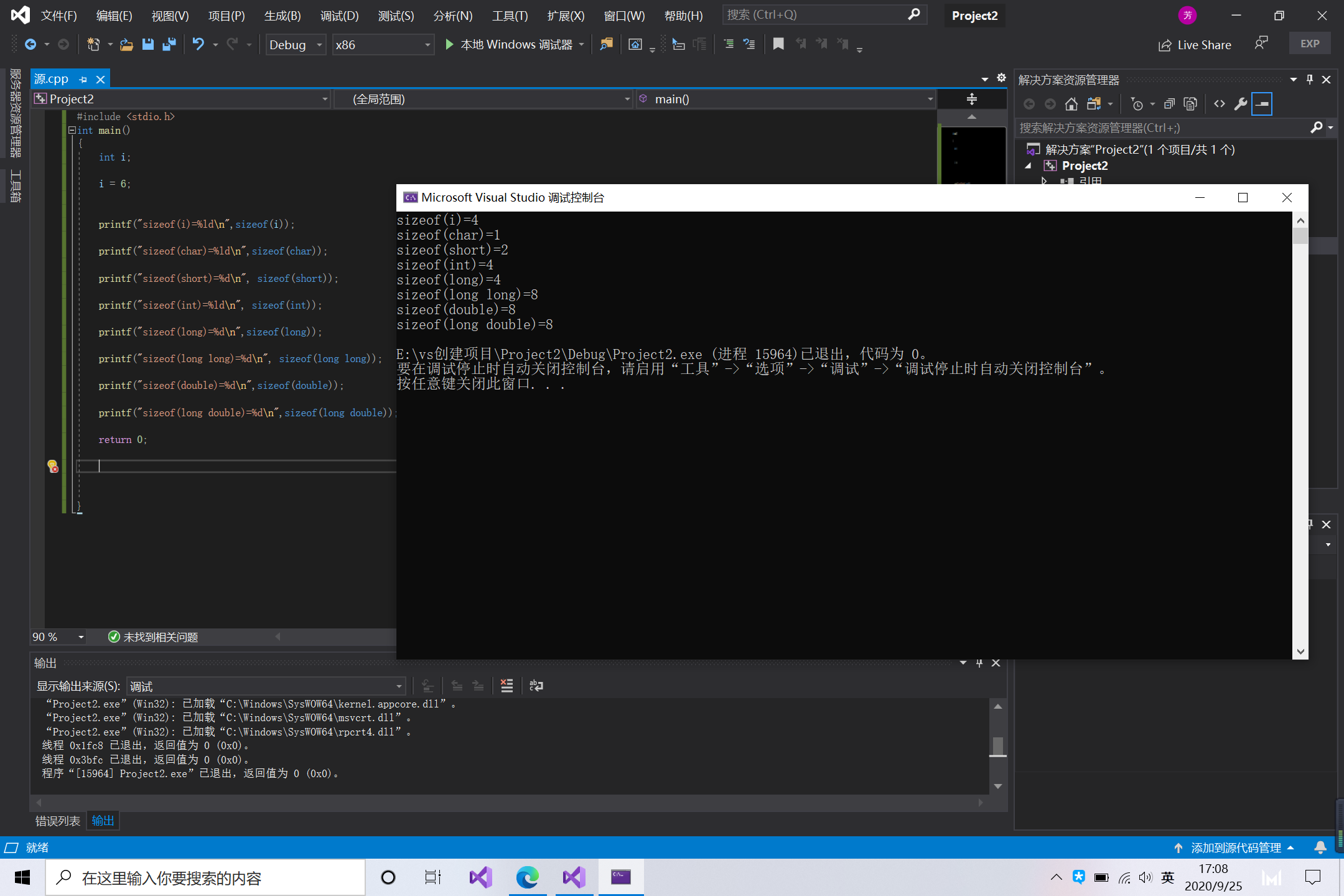
char 1字节(8比特)
short 2字节
int,long取决于编译器(32),通常的意义是1个字
long long 8字节
字长
- int 就是用来表示寄存器的
- 寄存器是多宽的,几个bit,一个寄存器的大小。一次可以传递和处理
- {CPU(Reg寄存器)}=总线=
整数的内部表达
以什么方式看待
eg:18的表示 用不同的进制表达
一个字节可以表达的数:00000000 —— 11111111(八位) 即0——255
三种方案
- 仿照十进制 有一个特殊的标志表示负数
- 取中间的数为0.类似数轴
- 补码
计算机内部一切都是二进制
十进制(在运算结果上处理) 八进制 十六进制 二进制
前两种存在问题,故选择第三种方案
补码
考虑-1.-1+1=0.
如何用二进制表示
0——>0000 0000
1——>1111 1111
1111 1111 + 0000 0001 = 1 0000 0000
因为0-1=-1,所以,-1=
(1)0000 0000 - 0000 0001 ——>1111 1111
1 1111 1111 被当作二进制看待时,是255,被当作补码看待时,是-1
同理,对于-a,其补码就是0-a,实际是2的n次方-a,n是这种类型的位数。
补码の意义就是 拿补码和原码可以加出一个溢出的0
数的范围
对于一个字节(8位)可以表达的是
0000 0000 —— 1111 1111
其中
0000 0000 ——>0
1111 1111~ 1 0000 0000 ——>-1~-128
0000 0001~ 0111 1111 ——>1~127
计算不同类型所能表达的整数范围(-2的n-1次方~2的n-1次方-1)
unsigned 不以补码的形式来表示负数,不把高位为1的舍去
使得数据表达范围在正数范围扩大一倍,负数无法表达
如果一个字面量常数想要表达自己是unsigned,可以在后面加u或者U
eg:255U
unsigned 的初衷并非为了扩充数能表达的范围,而是为了做纯二进制运算,主要是为了移位
eg: int 的最大数是多少? (利用⚪)
整数的输入输出
只有两种形式:int 或long long
%d:int
%u:unsigned
%ld: long long
%lu:unsigned long long
取决于正确的方式看待 格式化
8进制和16 进制
-
一个以0开始的数字字面量是8进制
-
一个以0x开始的数字字面量是16进制
-
%o用于8进制 %x用于16进制
-
吧、8进制和16进制只是如何把数字表达为字符串,与内部如何表达数字无关
-
16进制很适合表达2进制数据,因为4为将进制正好是一个16进制位
-
8进制的一位数字正好表示3位二进制
-
因为早期 计算机的字长是12的倍数,而非8
选择整数类型
为什么整数要有那么多种?
为了准确表达内存,做底层程序的需要
没有什么特殊需要就选择int
现在的CPU的字长普遍是32位或64位,一次内存读写就是一个int,一次计算也是一个int,选择更短的类型不会更快,甚至可能更慢
现在的编译器一般也会涉及内存条对齐,所以更短的类型实际在内存中也可能占据一个int的大小(虽然sizeof告诉你更小)
unsigned与否只是输出的不同,内部计算是一样的,
浮点类型
| 类型 | 字长 | 范围 | 有效数字 |
|---|---|---|---|
| float | 32 | 0,±inf,fan | 7 |
| double | 64 | -0,±inf,fan | 15 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号