Python+Selenium----处理登录图片验证码
1.说明
在做自动化测试的时候,经常会遇到登录,其中比较麻烦的就是验证码的处理,现在比较常用的图形验证码,每次刷新,得到的验证码不一致,所以,一般来说,获取验证码图片有两种方式:
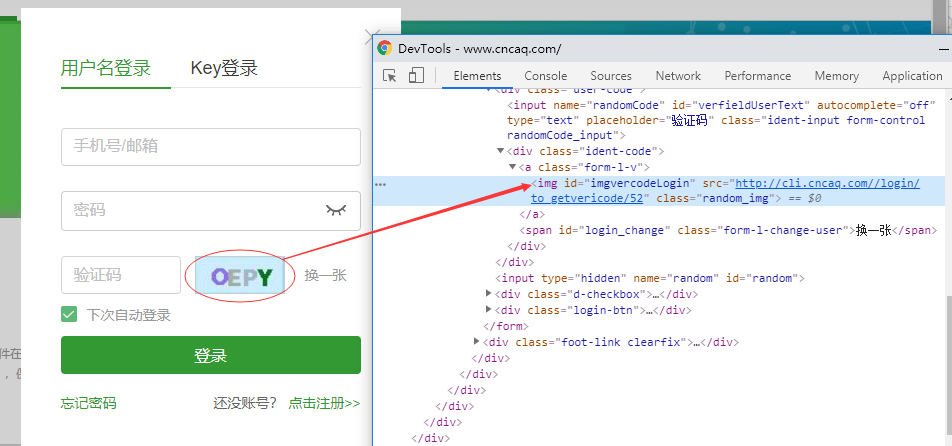
(1)拿到验证码的图片链接:src=”http://cli.cncaq.com//login/to_getvericode/52”,但是这种方式有时候行不通。因为有时候会发现当前的验证码和通过提取出来的url链接打开的验证码,内容是不一样的,其内容不断发生变化。
(2)利用selenium先进行可视区域的截屏,然后定位验证码元素的位置以及大小,然后利用Image(PIL模块中)进行裁剪,得到验证码图片,然后送往验证码模块或者打码平台处理。
2.代码
方法一:获得验证码图片地址,下载到本地,然后,进行图文识别,得到验证码中的内容(但是因为同一个地址,每次访问获得的验证码也不一样,所以,当前场景并不适用)
import random # 导入 random(随机数) 模块 from selenium_demo3_test.utils.file import * #引入下载图片函数所在的py文件
yanzhengma_src = driver.find_element_by_id('imgvercodeLogin').get_attribute('src') #根据验证码img的id获得元素,并使用get_attribute方法得到图片的地址 img_url = yanzhengma_src+'.png' #根据上图看到,我当前的地址 /52结尾,所以,我这边添加后缀,方便稍后下载 file_name = random.randint(0, 100000) #生成一个100000以内的随机数 file_path = 'img\\login' #下载验证码图片的时候的保存地址,默认为当前脚本运行目录下的file_path文件夹中 save_img(img_url, file_name,file_path) #下载图片(调用的其它文件中已经写好的下载方法)_要下载的文件路径,保存的文件名,保存路径
下载文件方法:
import urllib.request import os import random # 导入 random(随机数) 模块 #(要下载的文件地址,保存的文件名,保存地址) def save_img(img_url,file_name,file_path): #保存图片到磁盘文件夹 file_path中,默认为当前脚本运行目录下的 file_path文件夹 try: if not os.path.exists(file_path): print('文件夹',file_path,'不存在,重新建立') #os.mkdir(file_path) os.makedirs(file_path) #获得图片后缀 file_suffix = os.path.splitext(img_url)[1] #拼接图片名(包含路径) filename = '{}{}{}{}'.format(file_path,os.sep,file_name,file_suffix) urllib.request.urlretrieve(img_url,filename=filename) print('********************************文件保存成功') except IOError as e: print('文件操作失败',e) except Exception as e: print('错误 :',e)
方法二:截屏,然后裁剪出验证码,再进行图片识别
#截图裁剪出验证码,并写入验证码输入框中(保存地址,验证码元素,验证码输入框元素) jietu_xieru(driver,'img\\login\\','imgvercodeLogin','verfieldUserText')
截图并裁剪图片以及图文识别的方法:
from PIL import Image import random #导入 random(随机数) 模块 import pytesseract #导入识别验证码信息包 import time #截图,裁剪图片并返回验证码图片名称 # _save_url 保存路径 ;yuansu 验证码元素标识 def image_cj(driver,_save_url,yuansu): try: _file_name = random.randint(0, 100000) _file_name_wz = str(_file_name) + '.png' _file_url = _save_url + _file_name_wz driver.get_screenshot_as_file(_file_url) # get_screenshot_as_file截屏 captchaElem = driver.find_element_by_id(yuansu) # # 获取指定元素(验证码) # 因为验证码在没有缩放,直接取验证码图片的绝对坐标;这个坐标是相对于它所属的div的,而不是整个可视区域 # location_once_scrolled_into_view 拿到的是相对于可视区域的坐标 ; location 拿到的是相对整个html页面的坐标 captchaX = int(captchaElem.location['x']) captchaY = int(captchaElem.location['y']) # 获取验证码宽高 captchaWidth = captchaElem.size['width'] captchaHeight = captchaElem.size['height'] captchaRight = captchaX + captchaWidth captchaBottom = captchaY + captchaHeight imgObject = Image.open(_file_url) #获得截屏的图片 imgCaptcha = imgObject.crop((captchaX, captchaY, captchaRight, captchaBottom)) # 裁剪 yanzhengma_file_name = str(_file_name) + '副本.png' imgCaptcha.save(_save_url + yanzhengma_file_name) return yanzhengma_file_name except Exception as e: print('错误 :', e) # 获取验证码图片中信息(保存地址,要识别的图片名称) def image_text(_save_url,yanzhengma_file_name): pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files (x86)\Tesseract-OCR\tesseract' yanzhengma_file_url = 'F:\\Python\\workspace\\selenium_demo3_test\\test\\case\\PT\\'+ _save_url image = Image.open(yanzhengma_file_url + yanzhengma_file_name) text = pytesseract.image_to_string(image) print('$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$图片中的内容为:', text) return text #截图并写入验证码(保存地址,验证码元素,验证码输入框元素) def jietu_xieru(driver,_save_url,yuansu,yanzhma_text): # 截图当前屏幕,并裁剪出验证码保存为:_file_name副本.png,并返回名称 yanzhengma_file_name = image_cj(driver,_save_url, yuansu) ##对页面进行截图,弹出框宽高(因为是固定大小,暂时直接写死了) # 获得验证码图片中的内容 text = image_text(_save_url, yanzhengma_file_name) # 写入验证码 driver.find_element_by_id('verfieldUserText').send_keys(text) time.sleep(2)
3.登录
from selenium import webdriver #引入浏览器驱动 import time from selenium.webdriver.common.action_chains import ActionChains # 引入 ActionChains 类进行鼠标事情操作 import pytesseract #导入识别验证码信息包 from PIL import Image #from .utils.log import logger 引入日志模块 import random # 导入 random(随机数) 模块 from selenium_demo3_test.utils.file import * #引入下载图片函数所在的py文件 from selenium_demo3_test.utils.image import * #引入图片操作 from selenium_demo3_test.utils.llqi import * #引入浏览器操作 #coding=utf-8 driver = llq_qudong('Chrome') open_url(driver,'http://www.cncaq.com/') denlu =driver.find_element_by_id('top_login_a') #根据id获取登录元素 ActionChains(driver).click(denlu).perform() #点击登录,打开弹出层 driver.find_element_by_id('loginNameText').send_keys('188XXXXXXXX') driver.find_element_by_id('passwordText').send_keys('111111') time.sleep(2) #截图裁剪出验证码,并写入验证码输入框中(保存地址,验证码元素,验证码输入框元素) jietu_xieru(driver,'img\\login\\','imgvercodeLogin','verfieldUserText') driver.find_element_by_xpath('//*[@id="loginForm"]/div[6]/button').click() #点击登录 _user_name = driver.find_element_by_xpath('//*[@id="userWrap"]/div/p').get_attribute('innerHTML') user_name = '用户1' #判断不相等,则未登录成功,则为验证码输入错误(此时,只考虑验证码,且图文识别并非百分之百正确)一直循环读取验证码输入 while _user_name != user_name: jietu_xieru(driver, 'img\\login\\', 'imgvercodeLogin', 'verfieldUserText') driver.find_element_by_xpath('//*[@id="loginForm"]/div[6]/button').click() # 点击登录 _user_name = driver.find_element_by_xpath('//*[@id="userWrap"]/div/p').get_attribute('innerHTML') else: print('#############################################登录成功#############################################') pass

 浙公网安备 33010602011771号
浙公网安备 33010602011771号