
数据仓库基础知识
1. 数据仓库的关键特征
数据仓库是一个面向主题的、集成的、随时间而变化的、不容易丢失的数据集合,支持管理部门的决策过程。
面向主题:
面向主题,是数据仓库显著区别于关系数据库系统的一个特征
围绕一些主题,如顾客、供应商、产品等
关注决策者的数据建模与分析,而不是集中于组织机构的日常操作和事务处理。
排除对于决策无用的数据,提供特定主题的简明视图。
数据集成:
一个数据仓库是通过集成多个异种数据源来构造的。
关系数据库,一般文件,联机事务处理记录
使用数据清理和数据集成技术。
确保命名约定、编码结构、属性度量等的一致性。
当数据被移到数据仓库时,它们要经过转化。
随时间而变化:
数据仓库是从历史的角度提供信息
数据仓库的时间范围比操作数据库系统要长的多。
操作数据库系统: 主要保存当前数据。
数据仓库:从历史的角度提供信息(比如过去 5-10 年)
数据仓库中的每一个关键结构都隐式或显式地包含时间元素,而操作数据库中的关键结构可能就不包括时间元素。
不容易丢失:
尽管数据仓库中的数据来自于操作数据库,但他们却是在物理上分离保存的。
操作数据库的更新操作不会出现在数据仓库环境下。
不需要事务处理,恢复,和并发控制等机制
只需要两种数据访问:
数据的初始转载和数据访问(读操作)
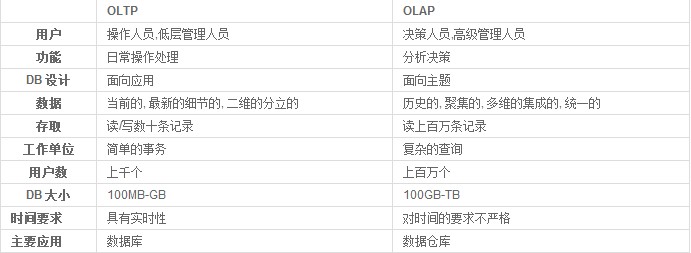
2. OLTP和OLAP的区别:
OLTP与OLAP的介绍
-
OLTP:系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
-
OLAP:系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
-
决策支持系统(DDS,Decision support system),典型的操作是全表扫描,长查询,长事务,但是一般事务的个数很少,往往是一个事务独占系统。
OLTP与OLAP的区别:
OLTP的瓶颈与优化技术:
OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
1)CPU出现瓶颈常表现在逻辑读总量与计算性函数或者是过程上,逻辑读总量等于单个语句的逻辑读乘以执行次数,如果单个语句执行速度虽然很快,但是执行次数非常多,那么,也可能会导致很大的逻辑读总量。设计的方法与优化的方法就是减少单个语句的逻辑读,或者是减少它们的执行次数。另外,一些计算型的函数,如自定义函数、decode等的频繁使用,也会消耗大量的CPU时间,造成系统的负载升高,正确的设计方法或者是优化方法,需要尽量避免计算过程,如保存计算结果到统计表就是一个好的方法。
2)磁盘子系统在OLTP环境中,它的承载能力一般取决于它的IOPS处理能力. 因为在OLTP环境中,磁盘物理读一般都是db file sequential read,也就是单块读,但是这个读的次数非常频繁。如果频繁到磁盘子系统都不能承载其IOPS的时候,就会出现大的性能问题。
OLTP比较常用的设计与优化方式为Cache技术与B-tree索引技术:
Cache决定了很多语句不需要从磁盘子系统获得数据,所以,Web cache与Oracle data buffer对OLTP系统是很重要的。另外,在索引使用方面,语句越简单越好,这样执行计划也稳定,而且一定要使用绑定变量,减少语句解析,尽量减少表关联,尽量减少分布式事务,基本不使用分区技术、MV技术、并行技术及位图索引。因为并发量很高,批量更新时要分批快速提交,以避免阻塞的发生。
OLTP 系统是一个数据块变化非常频繁,SQL 语句提交非常频繁的系统。 对于数据块来说,应尽可能让数据块保存在内存当中,对于SQL来说,尽可能使用变量绑定技术来达到SQL重用,减少物理I/O 和重复的SQL 解析,从而极大的改善数据库的性能。
这里影响性能除了绑定变量,还有可能是热快(hot block)。 当一个块被多个用户同时读取时,Oracle 为了维护数据的一致性,需要使用Latch来串行化用户的操作。当一个用户获得了latch后,其他用户就只能等待,获取这个数据块的用户越多,等待就越明显。 这就是热快的问题。 这种热快可能是数据块,也可能是回滚端块。 对于数据块来讲,通常是数据库的数据分布不均匀导致,如果是索引的数据块,可以考虑创建反向索引来达到重新分布数据的目的,对于回滚段数据块,可以适当多增加几个回滚段来避免这种争用。
OLAP的缺点与优化:
在这样的系统中,语句的执行量不是考核标准,因为一条语句的执行时间可能会非常长,读取的数据也非常多。所以,在这样的系统中,考核的标准往往是磁盘子系统的吞吐量(带宽),如能达到多少MB/s的流量。
磁盘子系统的吞吐量则往往取决于磁盘的个数,这个时候,Cache基本是没有效果的,数据库的读写类型基本上是db file scattered read与direct path read/write。应尽量采用个数比较多的磁盘以及比较大的带宽,如4Gb的光纤接口。
在OLAP系统中,常使用分区技术、并行技术。
分区技术在OLAP系统中的重要性主要体现在数据库管理上,比如数据库加载,可以通过分区交换的方式实现,备份可以通过备份分区表空间实现,删除数据可以通过分区进行删除,至于分区在性能上的影响,它可以使得一些大表的扫描变得很快(只扫描单个分区)。另外,如果分区结合并行的话,也可以使得整个表的扫描会变得很快。总之,分区主要的功能是管理上的方便性,它并不能绝对保证查询性能的提高,有时候分区会带来性能上的提高,有时候会降低。
并行技术除了与分区技术结合外,在Oracle 10g中,与RAC结合实现多节点的同时扫描,效果也非常不错,可把一个任务,如select的全表扫描,平均地分派到多个RAC的节点上去。
在OLAP系统中,不需要使用绑定(BIND)变量,因为整个系统的执行量很小,分析时间对于执行时间来说,可以忽略,而且可避免出现错误的执行计划。但是OLAP中可以大量使用位图索引,物化视图,对于大的事务,尽量寻求速度上的优化,没有必要像OLTP要求快速提交,甚至要刻意减慢执行的速度。
绑定变量真正的用途是在OLTP系统中,这个系统通常有这样的特点,用户并发数很大,用户的请求十分密集,并且这些请求的SQL 大多数是可以重复使用的。
分开设计与优化
在设计上要特别注意,如在高可用的OLTP环境中,不要盲目地把OLAP的技术拿过来用。
如分区技术,假设不是大范围地使用分区关键字,而采用其它的字段作为where条件,那么,如果是本地索引,将不得不扫描多个索引,而性能变得更为低下。如果是全局索引,又失去分区的意义。
并行技术也是如此,一般在完成大型任务时才使用,如在实际生活中,翻译一本书,可以先安排多个人,每个人翻译不同的章节,这样可以提高翻译速度。如果只是翻译一页书,也去分配不同的人翻译不同的行,再组合起来,就没必要了,因为在分配工作的时间里,一个人或许早就翻译完了。
位图索引也是一样,如果用在OLTP环境中,很容易造成阻塞与死锁。但是,在OLAP环境中,可能会因为其特有的特性,提高OLAP的查询速度。MV也是基本一样,包括触发器等,在DML频繁的OLTP系统上,很容易成为瓶颈,甚至是Library Cache等待,而在OLAP环境上,则可能会因为使用恰当而提高查询速度。
对于OLAP系统,在内存上可优化的余地很小,增加CPU 处理速度和磁盘I/O 速度是最直接的提高数据库性能的方法,当然这也意味着系统成本的增加。
比如我们要对几亿条或者几十亿条数据进行聚合处理,这种海量的数据,全部放在内存中操作是很难的,同时也没有必要,因为这些数据快很少重用,缓存起来也没有实际意义,而且还会造成物理I/O相当大。 所以这种系统的瓶颈往往是磁盘I/O上面的。
对于OLAP系统,SQL 的优化非常重要,因为它的数据量很大,做全表扫描和索引对性能上来说差异是非常大的。
对于OLAP系统来说,绝大多数时候数据库上运行着的是报表作业,执行基本上是聚合类的SQL 操作,比如group by,这时候,把优化器模式设置为all_rows是恰当的。 而对于一些分页操作比较多的网站类数据库,设置为first_rows会更好一些。 但有时候对于OLAP 系统,我们又有分页的情况下,我们可以考虑在每条SQL 中用hint。 如:Select a.* from table a;
3. 多维数据模型
数据仓库和OLAP工具基于多维数据模型
在多维数据模型中,数据以数据立方体(data cube)的形式存在。数据立方体允许以多维数据建模和观察。它由维和事实定义。维是关于一个组织想要记录的视角或观点。每个维都有一个表与之相关联,称为维表。
多维数据模型围绕中心主题组织,该主题用事实表表示。事实表包括事实的名称或度量以及每个相关维表的关键字。事实指的是一些数字度量。
概念模型:
星型模式、雪花模式、或事实星座模式的形式存在。
星型模式(Star schema): 事实表在中心,周围围绕地连接着维表(每维一个),事实表含有大量数据,没有冗余。
雪花模式(Snowflake schema): 是星型模式的变种,其中某些维表是规范化的,因而把数据进一步分解到附加表中。结果,模式图形成类似于雪花的形状。
事实星座(Fact constellations): 多个事实表共享维表, 这种模式可以看作星型模式集,因此称为星系模式(galaxy schema),或者事实星座(fact constellation)
4. 数据仓库的架构![]()

底层:数据仓库的数据库服务器
关注的问题:如何从这一层提取数据来构建数据仓库(通过Gateway(ODBC,JDBC,OLE/DB等)来提取)
中间层:OLAP服务器
关注的问题:OLAP服务器如何实施(关系型OLAP,多维OLAP等)
前端客户工具层
关注的问题:查询工具、报表工具、分析工具、挖掘工具等
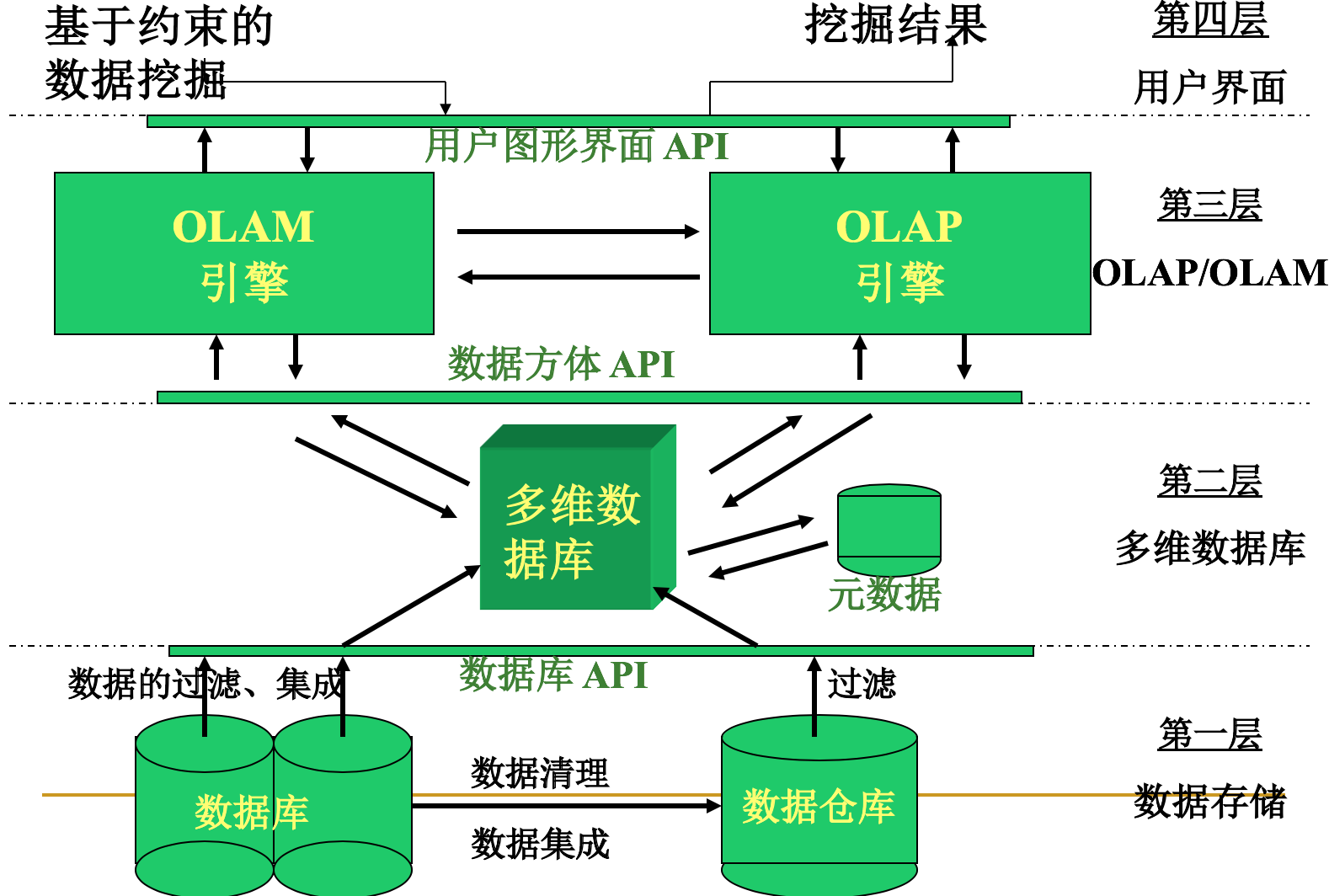
5. 联机分析挖掘OLAM的体系结构

 浙公网安备 33010602011771号
浙公网安备 33010602011771号