寒假作业2/2
寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》并提出问题、编写WordCount程序、使用并记录PSP表格 |
| 其他参考文献 | 1.《JAVA代码规范》 2.Java常用I/O流操作详解 3.String、StringBuffer和StringBuilder的区别 4.java Pattern和Matcher详解 5.HashMap统计每个单词出现的次数 6.Java面试题:如何对HashMap按键值排序 7.ArrayList和LinkedList区别? 8.《Java程序性能优化》-葛一鸣 9.提升代码覆盖率的经验 |
| 项目地址 | PersonalProject-Java |
任务一:阅读《构建之法》并提问
问题1:re-work
问题来源:
“有人试图用“re-work”来表示质量,那么改动少的代码最初质量高,因为re-work的次数少。笔者认为,re-work只是表明在软件开发过程中花费的时间,re-work的多寡并不跟最终的质量成正比。”
我的疑惑:
那软件质量与哪些因素有关?re-work次数主要反映了什么?
我的思考:我查阅资料时发现,软件质量的基础是流程、技术和组织。其中技术一栏有写到“良好的需求分析便是项目成功的关键所在,若是需求分析做不好不可避免的要出现返工;设计,软件的质量是设计出来的,良好的设计基本上决定了软件产品的最终质量;编码技术产生正确高效的代码;测试是保证软件的一道防线。所以各种技术对质量来说都是很重要的”。所以re-work次数过多首先反映了需求分析的不到位,如果一个软件的需求分析没有做好,后续工作的开展就会更困难一点。但这次作业,给出了明确的需求,但我还是re-work了好多次,主要还是在设计上欠缺考虑。
问题2:goto语句
问题来源:
“函数最好有单一出口,为了达到这一目的,可以使用goto。只要有助于函数逻辑的清晰体现,什么方法都可以使用,包括goto。”
我的疑惑:
“goto语句在我的印象里,老师一般都不太提倡使用,因为可能会使程序难以理解,难以查错,并且可以使用其他语句来代替。所以goto语句是否应该被使用,其存在的合理性是什么?
我的思考:
我查阅资料时发现,不提倡使用goto语句的语言,如:Java、C#,大多带有自带的垃圾回收机制,也就是说不需要过多关心资源的释放问题,因为在程序中没有“为资源设置统一出口”的需求。但在一些没有自带垃圾回收机制的语言中,如:C++,在设置统一出口时,合理使用goto语句可以简化程序,也不容易忘记释放资源。
而且在实现单一出口原则时,也可以使用do{}while(0)语句,这种方法好像更建议使用。
问题3:结对编程
问题来源:
“结对编程中驾驶员和领航员的角色要经常互换,避免长时间紧张工作而导致观察力和判断力的下降。”
我的疑惑:
我一直以为结对编程甚至团队编程时,是大家主要负责自己更擅长的事情。这种经常互换角色的操作,其实会不会不利于编程?因为可能互换后我对这一部分的工作并没有那么熟悉,反而做的更不好。
我的思考:
我查阅资料时看到一段话“如果二者都是可互换角色的专家,那么驾驶员-领航员模式会很理想,对于专家与新手的组合来说也不错。这个模式在专家做领航员时最容易起效,因为让菜鸟来当领航员,他可能只会被动地干坐着而让专家分饰两角。”两个人对各个部分工作都很熟悉当然可以,但就像文中所说,如果角色互换后菜鸟当领航员了,那这不就不太好?
问题4:迷思之三:好的想法会赢
问题来源:
“原始布局设计的优点失去了原有的价值,反而变成了弱点。但是,长期以来,人们已经习惯了QWERTY键盘,所谓先入为主。”
作者观点:
好的想法不一定会赢。
我的观点:
我不否认先入为主的概念对人的影响确实很深。正如高中做数学题时,一开始用了先学的方法,后来老师也讲了新颖的更为便捷的方法。当下次遇到同类型的题的时候,你还是会选择之前先学会的麻烦方法,因为先入为主。或者一开始用错误的方法做题但没有及时改正,之后再遇到同类型的题的时候,你脑海中浮现的还会是那种错误的解法。但是为了提高做题效率,为了提高正确率,你不得不改变先入为主的那些做法,选择更好的更正确的那些方法。所以我还是认为好的想法会赢,只是可能时机未到,或者没有坚持或者改变的决心。而且既然是要创新,就必然要打破固有的僵局。
问题5:迷思之五:要成为领域的专家,才能创新
问题来源:
“研究表明,70%的创新者说,他们最成功的创新,是在他们拿手领域之外发现的。”
我的疑惑:
我一直以为,创新的基础,是要他已经掌握了这项技能或者知识。正如作者在第三章技能的反面那里说的魔方的技能层次6——能够设计出新型的魔方,但这个层次6之前的层次5是要求已经对魔方玩法的掌握达到了顶尖水平,甚至可以说是该领域的专家?但为什么在拿手之外领域,更容易创新呢?
我的思考:
我查阅资料时看到一段话“持续性的创新是在某个产品的基础上作一些改进,不会危及该产品的市场份额,破坏性的创新则完全不同,旨在取而代之。有趣的是,许多破坏性的创新很多时候都出于业余者之手。业余发明家的成功与其说是他不缺想象力,不如说他与自己的发明没有利益冲突,与某一主导产业的距离能让他可以自由地创造发明。那些与原产业紧密相关,甚至利益所得者,显然会对有害于原产业的发明避之不及,而局外人就无此顾虑。”所以其实领域之外的创新其实对自身以及自身领域所带来的隐患或者伤害几乎可以不计,因为可以不被束缚,大展拳脚。
附加题:冷知识和故事
电脑病毒的设计初衷并非是造成损害
史上第一款电脑病毒,是由防御技术专家Fred Cohen亲手设计出来的。他创造电脑病毒的目的仅仅是为了证明程序对电脑感染的可行性,从未希望借此对电脑造成任何危害。但这款程序却能够对电脑进行感染,并且能通过软盘等移动介质在不同计算机之间进行传播,因而命名为病毒。
后来,他又创造出一种主动式电脑病毒,主要目的是帮助电脑用户找到未受感染可执行文件。
来源于有趣的八个IT冷知识
任务二:完成词频统计个人作业
Github项目地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 20 | 30 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 60 | 125 |
| Design Spec | 生成设计文档 | 30 | 20 |
| Design Review | 设计复审 | 20 | 45 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 60 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 300 | 400 |
| Code Review | 代码复审 | 30 | 25 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 60 | 35 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 30 |
| 合计 | 750 | 985 |
解题思路
WordCount程序要求:
1.读取文件数据
2.统计文件中字符数
3.统计单词总数
4.统计有效行数
5.统计单词出现频率(TOP10)
6.按格式输出数据至文件
主要涉及到的问题和我的思路:
1.命令行程序
args[ ]传入输入文件和输出文件。//百度后才知道的Hhh
2.文件I/O流
(1)因为要统计字符数,所以我直接选择了字符流Reader、Writer。
(2)又因为BufferedReader和BufferedWriter可以实现字符、数组和行的高效读取和写入。所以选择BufferedReader和BufferedWriter。
3.字符串处理
(1)统计字符数:因为题目要求只需要统计ASCII码,且测试文件不会出现ASCII以外的字符。所以我选择在读取后文件数据将其存入字符串后直接通过length()获取数据长度。
(2)统计单词总数:因为单词要求——至少以4个英文字母开头,跟上字母数字,且以分隔符分割,不区分大小写。所以考虑直接使用正则表达式来判定单词。
(3)统计有效行数:本来考虑过直接使用BufferedReader的readLine()方法来统计,但后来不想因此多读一遍文件数据,而且开始使用readLine()方法读取文件数据时,处理不当反而在得到的字符串中遗漏了所有的换行符使得字符数统计出现错误。所以后来采取了跟统计单词总数一样采取正则匹配的方法。
(4)统计单词输出频率:一开始没有头绪,觉得怎么都好麻烦,百度后采取了使用HashMap保存单词和使用频率,转化成List然后进行排序,排序成功后将结果应重新转化为LinkedHashMap。
代码规范
设计与实现过程
类和函数的设计
WordCount类为主类,Lib类为工具类。通过WordCount类主函数来调用Lib的beginCount()方法和writeFileContent()方法实现所要求各个功能。
public class Lib {
//读取文件内容至StringBuffer
public static String readFileContent(String inputFile) throws IOException {}
//统计字符数
public static int countChars(String builderString) {}
//统计有效行数
public static int countLines(String builderString) {}
//统计单词数
public static int countWords(String builderString) {}
//按规则对有效单词进行排序
public static Map<String, Integer> sortWords(String builderString) {}
//将结果写至指定文件
public static void writeFileContent(String outputFile) throws IOException {}
//调用读文件以及所有的统计方法
public static void beginCount(String inputFile) {}
}
beginCount()会先调用readFileContent()方法得到文件内容字符串后再执行四个有关统计的函数,这样文件只需要读取一次。
writeFileContent()方法会在上述函数执行完毕后再执行,一次性写入结果至指定文件而不用重复的开闭文件。
实现
读入文件内容
秉着高效读取和性能优先的原则采用了BufferedReader,使用其read()方法按字符读入到StringBuilder中,并在读取完毕后将其转化为小写字符串,以备之后使用(开始选择readLine()是想方便行数的读取,但是这样得到的字符串少了换行符,所以改用了read())。
while ((tempStr = reader.read()) != -1) {
builder.append((char)tempStr);
}
//中间内容省略
return builder.toString().toLowerCase();
统计字符数
将得到的字符串传入此函数后,直接通过length()获取数目。
charNumber = builderString.length();
统计有效行数
用正则表达式(^|\n)(\s*\S+)来匹配有效行。
Pattern linePattern = Pattern.compile(LINE_REGEX);
Matcher matcher = linePattern.matcher(builderString);
while(matcher.find()) {
lineNumber++;
}
统计单词数
前面读取文件所获得的字符串已经全部处理为小写。所以在此处依旧使用正则表达式(^|[^a-z0-9])([a-z]{4}[a-z0-9]*)来匹配单词。(一开始我使用的表达是为[a-z]{4}[a-z0-9]*,经姐妹提醒,才发现忽略了类似"1233_hdksl37"这种情况。)
//代码与统计有效行数类似,此处不再展示。
获取正确单词
每找到一个符合上面正则表达式(^|[^a-z0-9])([a-z]{4}[a-z0-9]*)的单词,使用matcher.group(2)来提取单词中只符合[a-z]{4}[a-z0-9]*的部分存入HaspMap中,以便之后进行排序和输出。
Map<String, Integer> mapWords = new HashMap<>();
Pattern wordPattern = Pattern.compile(WORD_REGEX);
Matcher matcher = wordPattern.matcher(builderString);
while(matcher.find()) {
String word = matcher.group(2);
if(!mapWords.containsKey(word)) {
mapWords.put(word, 1);
} else{
mapWords.put(word, mapWords.get(word)+1);
}
}
排序
将HashMap转化为LinkedList进行排序。为什么没有选择ArrayList,是因为对于插入来说,LinkedList会更快。但同时它所占据的内存就更多,此处选择LinkedList也算是牺牲空间来换时间。
Set<Entry<String, Integer>> mapEntry = mapWords.entrySet();
List<Entry<String, Integer>> entryList = new LinkedList<Entry<String, Integer>>(mapEntry);
entryList.sort(new Comparator<Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
if (o1.getValue().equals(o2.getValue())) {
return o1.getKey().compareTo(o2.getKey());
} else {
return o2.getValue().compareTo(o1.getValue());
}
}
});
排序完只选择将前十个转化为LinkedHashMap,因为LinkedHashMap可以保存记录的插入顺序,方便之后写入文件。
linkedMapWords = new LinkedHashMap<>();
int i = 0;
for(Entry<String, Integer> entry: entryList) {
if(i < 10) {
linkedMapWords.put(entry.getKey(), entry.getValue());
i++;
} else {
break;
}
}
写入文件
选择在所有工作做完之后一次性写入文件,不用重复开闭文件。
//代码此处不再展示。
性能改进
1.I/O流的选取了选择了
BufferedReader和BufferedWriter,以此来实现高效读取和写入。并且读取和写入只执行一次。
2.存储文件内容的字符串本来选择的是StringBuffer,但IDEA提示我可以换成StringBuilder,CSDN搜索后发现,相比于StringBuffer,StringBuilder性能略高,所以选择了StringBuilder。(虽然安全性而言,StringBuffer是线程安全的。)
3.使用HashMap保存单词和使用频率,HashMap可以使存储、查找的时间效率都在O(1)内完成,而TreeMap却是log(N);
4.使用LinkedList进行排序,因为在链表中插入元素比数组列表更快。
5.因为静态方法的调用速度快于实例方法,所以改用了静态方法,果然运行速度变快了。
性能测试
我主要是用时间来换空间。所以占用的内存很多。当测试150mb的文件数据时,花费的时间在17s左右。
测试结果
但当我测试500mb的文件时,就出现了如下错误。(可能与我在读取整个文件数据时采取一个字符串存储文本全部内容有关)
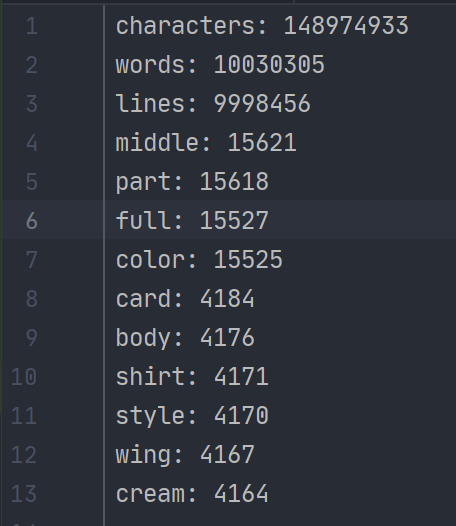
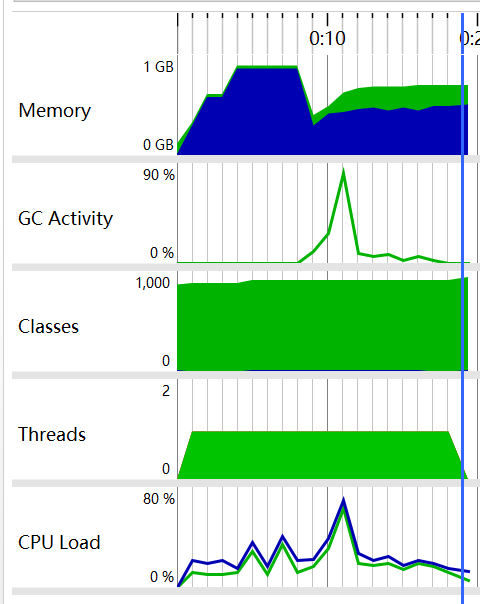


单元测试
覆盖率
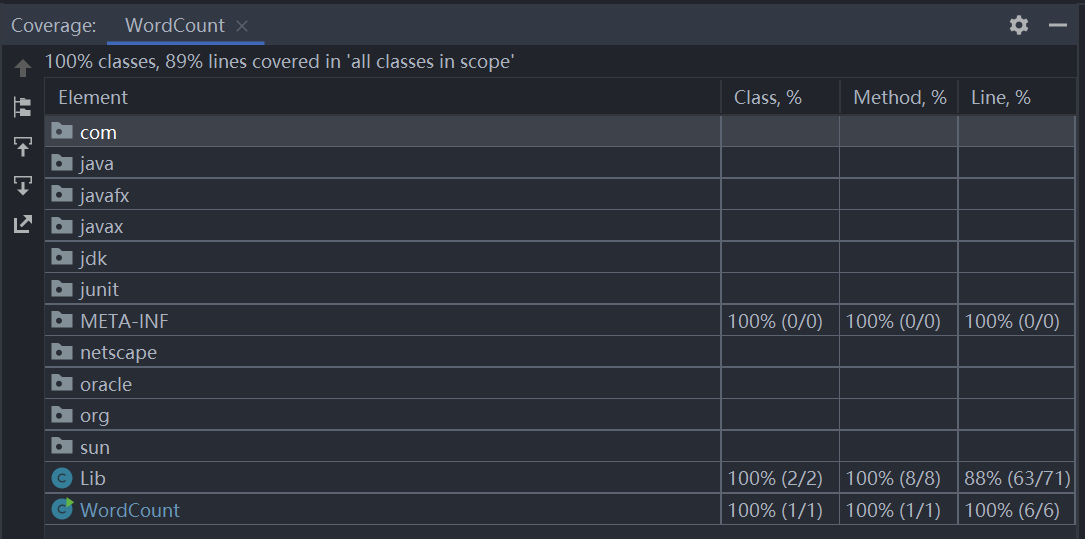
没有覆盖到的代码是catch语句的相关内容。
提升代码覆盖率的主要方法:
1.增加用例
2.优化代码
正确性测试
使用assertEquals(xxx,xxx)将测试函数结果与预期结果进行比较。测试文件中已包含字母、数字、各种符号。
1.字符数验证
@Test
public void countChars() throws IOException {
String input ="test\\input4.txt";
String str =Lib.readFileContent(input);
assertEquals(168,Lib.countChars(str));
}
2.有效行验证
@Test
public void countLines() throws IOException {
String input ="test\\input4.txt";
String str =Lib.readFileContent(input);
assertEquals(12,Lib.countLines(str));
}
3.有效单词验证
@Test
public void countWords() throws IOException {
String input ="test\\input4.txt";
String str =Lib.readFileContent(input);
assertEquals(10,Lib.countWords(str));
}
4.单词频率Top10验证
@Test
public void sortWords() throws IOException {
String input ="test\\input4.txt";
String str =Lib.readFileContent(input);
StringBuilder topWords = new StringBuilder();
LinkedHashMap<String, Integer> linkedHashMap = (LinkedHashMap<String, Integer>) Lib.sortWords(str);
for(Map.Entry<String, Integer> entry: linkedHashMap.entrySet()) {
topWords.append(entry.getKey()).append(": ").append(entry.getValue()).append("\n");
}
String result ="aabp14: 2\n" + "agiabgh21w2: 2\n" + "roeh1516: 2\n" + "iaohro: 1\n" +
"iohpq: 1\n" + "oihaihoi: 1\n" + "qiohtqp: 1\n";
assertEquals(result,topWords.toString());
}
四个函数均测试正确。

异常处理
1.主要是I/O异常。读或写文件出现错误时,会用catch捕获异常,然后关闭文件,抛出异常,并在命令行提示异常。如"File read error!"。
2.命令行参数无输入/输出文件的情况:
if(args.length<2) {
System.out.println("The parameter is less than two, please run again");
return;
}
3.输入文件不存在时:会输出FileNotFoundException。
总结
开始看到这次作业的时候,我的第一感觉是我的快乐寒假结束了(虽然并没有当时就接着开始写作业)。
在这次作业中,我明确了自己的代码规范,并希望自己积极践行。
学习了Git和github相关的知识,并在实践中同时感受到版本控制、尤其是回退时的便捷(git desktop确实好用!)。
感受到了自己对java掌握程度之差,这次作业也算是对java有了一个初步回顾。
提高了查阅资料的能力(很好的实践了面向百度编程)。
第一次使用了PSP表格、对程序进行了单元测试,但是掌握程度并不够,没有很好的利用起来,需要改进。
最后感谢我的姐妹zfr同学陪我一起debug.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号