数据结构与算法Python版 熟悉哈希表,了解Python字典底层实现
Hash Table
散列表(hash table)也被称为哈希表,它是一种根据键(key)来存储值(value)的特殊线性结构。
常用于迅速的无序单点查找,其查找速度可达到常数级别的O(1)。
散列表数据存储的具体思路如下:
- 每个value在放入数组存储之前会先对key进行计算
- 根据key计算出一个重复率极低的指纹
- 根据这个指纹将value放入到数组的相应槽位中
同时查找的时候也将经历同样的步骤,以便能快速的通过key查出想要的value。
这一存储、查找的过程也被称为hash存储、hash查找。
如图所示:
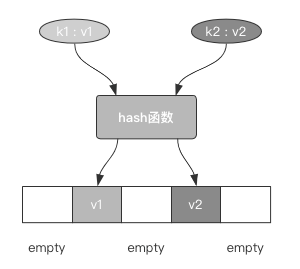
我们注意观察,其实散列表中的每一个槽位不一定都会被占据,它是一种稀疏的数组结构,即有许多的空位,并不像list那种顺序存放的结构一样必须密不可分,这就导致了散列表无法通过index来进行value的操作。
散列表在Python中应用非常广泛,如dict底层就是散列表实现,而dict也是经历了上述步骤才将key-value进行存入的,后面会进行介绍。
名词释义
在学习Hash篇之前,介绍几个基本的相关名词:
- 散列表(hash table):本身是一个普通的数组,初始状态全是空的
- 槽位(slot、bucket):散列表中value的存储位置,用来保存被存入value的地方,每一个槽位都有唯一的编号
- 哈希函数(hash function):如图所示,它会根据key计算应当将被存入的value放入那一个槽位
- 哈希值(hash value):哈希函数的返回值,也就是对数据项存放位置的结算结果
还有2个比较专业性的词汇:
-
散列冲突:打个比方,k1经过hash函数的计算,将v1存在了1号槽位上,而k22也经过了hash函数的计算,发现v2也应该存在1号槽位上。
现在这种情况就发生了散列冲突,v2会顶替v1的位置进行存放,原本1号槽位的存放数据项会变为v2。
-
负载因子:说白了就说这个散列表存放了多少数据项,如11个槽位的一个散列表,存放了6个数据项,那么该散列表的负载因子就是6/11
哈希函数
如何通过key计算出value所需要插入的槽位这就是哈希函数所需要思考的问题。
求余哈希法
如果我们的key是一串电话号码,或者身份证号,如436-555-4601:
- 取出数字,并将它们分成2位数(43,65,55,46,01)
- 对它们进行相加,得到结果为210
- 假设散列表共有11个槽位,现在使用210对11求余数,结果为1
那么这个key所对应的value就应当插入散列表中的1号槽位
平方取中法
平方取中法如下,现在我们的key是96:
- 先计算它的平方值:96^2
- 平方值为9216
- 取出中间的数字:21
- 假设散列表共有11个槽位,现在使用21对11求余数,结果为10
那么这个key所对应的value就应当插入散列表中的10号槽位
字符串求值
上面举例的key都是int类型,如果是str类型该怎么做?
我们可以遍历这个str类型的key,并且通过内置函数ord()来将它字符转换为int类型:
>>> k = "hello"
>>> i = 0
>>> for char in k:
i += ord(char)
>>> i
532
然后再将其对散列表长度求余,假设散列表共有11个槽位,现在使用532对11求余数,结果为4
那么这个key所对应的value就应当插入散列表中的4号槽位。
字符串问题
如果单纯的按照上面的方式去做,那么一个字符完全相同但字符位置不同的key计算的hash结果将和上面key的hash结果一致,如下所示:
>>> k = "ollhe"
>>> i = 0
>>> for char in k:
i += ord(char)
>>> i
532
如何解决这个问题呢?我们可以使用字符的位置作为权重进行解决:
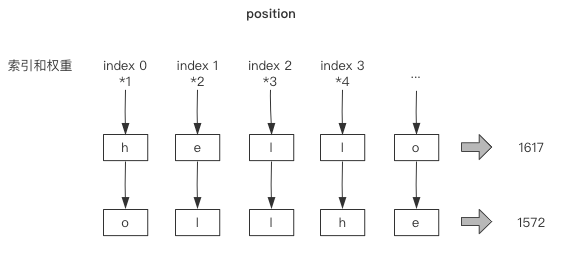
代码设计如下:
def getHash(string):
idx = 0
hashValue = 0
while idx < len(string):
# ord()结果 * 权重
hashValue += ord(string[idx]) * (idx + 1)
idx += 1
return hashValue
if __name__ == "__main__":
print(getHash("hello"))
print(getHash("ollhe"))
# 1617
# 1572
完美散列函数
为了应对散列冲突现象的发生,我们必须严格定制hash函数根据key生产hash值的这一过程,尽量做到每一个不同key产生的hash值都是不重复的,能做到这一点的hash函数被称为完美散列函数。
如何设计完美散列函数?主要看该散列函数产生的散列值是否有以下特性:
- 压缩性:任意长度的数据,得到的“指纹”长度是固定的
- 易计算性:从原数据计算“指纹”很容易
- 抗修改性:对原数据的微小变动,都会引起“指纹”的大改变
- 抗冲突性:已知原数据和“指纹”,要找到相同指纹的数据(伪造)是非常困难的
介绍2种产生散列函数的方案,MD5和SHA系列函数。
- MD5(MessageDigest)将任何长度的数据变换为固定长为128位(16字节 )的“摘要”
- SHA(SecureHashAlgorithm)是另一组散列函数
- SHA-0/SHA-1输出散列值160位(20字节)
- SHA-256/SHA-224分别输出256位、224位
- SHA-512/SHA-384分别输出512位和384位
128位二进制已经是一个极为巨大的数字空间:据说是地球沙粒的数量,MD5能达到这种效果。
160位二进制相当于10的48次方,地球上水分子数量估计是47次方,SHA-0能达到这种效果。
256位二进制相当于10的77方, 已知宇宙所有基本粒子大约是72~87次方,SHA-256能达到这种效果。
所以一般来说,MD5函数作为散列函数是非常合适的,而在Python中使用它们也非常简单:
#! /usr/local/bin/python3
# -*- coding:utf-8 -*-
import hashlib
m = hashlib.md5("salt".encode("utf8"))
m.update("HELLO".encode("utf8"))
print(m.hexdigest())
# ad24f795146b59b78c145fbd6b7f4d1f
像这种方案,通常还被应用到一致性校验中,如文件下载、网盘分享等。
只要改变任意一个字节,都会导致散列值发生巨大的变化。
散列冲突
如果两个不同的key被散列映射到同一个槽位,则需要一个系统化的方法在散列表中保存第2个value。
这个过程称为“解决冲突”,除了可以使用完美散列函数进行解决之外,以下也会介绍一些常见的解决办法。
开放定址法
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
从冲突的槽开始往后扫描,直到碰到一个空槽如果到散列表尾部还未找到,则从首部接着扫描:
- 这种寻找空槽的技术称为“开放定址openaddressing”
- 逐个向后寻找空槽的方法则是开放定址技术中的“线性探测linearprobing”
如下图所示:
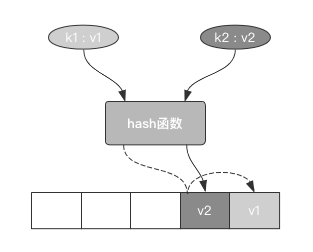
它有一个缺点,就是会造成数据项扎堆形成聚集(clustering)的趋势,这会影响到其他数据项的插入。
比如上图中4号和5号槽位都被占据了,下次的v3本来是要插入到5号槽位的,但是5号槽位被v1占据了,它就只能再次向后查找:
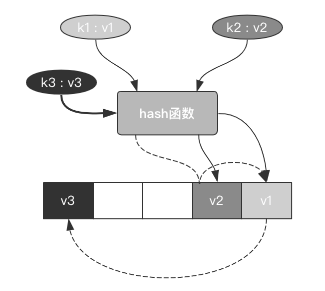
针对这个缺点,可以做一个优化措施,即线性探测的范围从1变为3,每次向后查找3个槽位。
或者让线性探测的范围不固定,而是按照线性的趋势进行增长,如第一次跳3个,第二次跳5个,第三次跳7个等等,也是较好的解决方案。
如果采用跳跃式探测方案,则需要注意:
- 跳跃步数的取值不能被散列表大小整除,否则会产生周期性跳跃,从而造成很多空槽永远无法被探测到
这里提供一个技巧,把散列表的大小设为素数,如11个槽位大小的散列表就永远不会产生跳跃式探测方案的插槽浪费。
再哈希法
再哈希法又叫双哈希法,有多个不同的hash函数,当发生冲突时,使用第二个,第三个,等哈希函数计算槽位,直到出现空槽位后再插入value。
虽然不易发生聚集,但是增加了计算时间。
链地址法
每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向链表向后排列。
如下图所示:
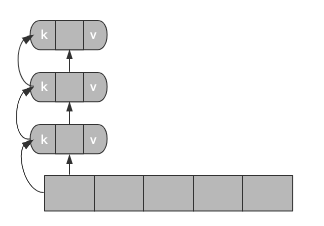
公共溢出区
将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
当要根据key查找value时,先查找基本表,再查找溢出表。
ADT Map
思路解析
Python的dict是以一种key-value的键值对形式进行保存,也被称之为映射。
我们如何使用Python的list来实现一个类似的数据结构呢?参照dict,有2大因素:
- key必须具有唯一性,不可变
- 通过key可以唯一的确定一个value
在做ADT Map之前,思考一下它应该具有哪些方法:
| 方法 | 描述 |
|---|---|
| ADTMap() | 创建一个空的映射,返回空映射对象 |
| set() | 将key-val加入映射中,如果key已存在,将val替换旧关联值 |
| get() | 给定key,返回关联的数据值,如不存在,则返回None |
| pop() | 给定key,删除键值对,返回value,如果key不存在,则抛出KeyError,不进行缩容进制 |
| len() | 返回映射中key-val关联的数目 |
| keys() | 返回map的视图,类似于dict.keys() |
| values() | 返回map的视图,类似于dict.values() |
| items() | 返回map的视图,类似于dict.items() |
| clear() | 清空所有的key-val,触发缩容机制 |
| in | 通过key in map的语句形式,返回key是否存在于关联中,布尔值 |
| [] | 支持[]操作,与内置dict一致 |
| for | 支持for循环,与内置dict一致 |
我们都知道,Python3.6之后的dict是有序的,所以ADT Map也应该实现有序,减少遍历次数。
Ps:详情参见Python基础dict一章
另外还需要思考:
- 散列表应该是什么结构?
- 采用怎样的哈希函数?
- 如何解决可能出现的hash冲突?
- 如何做到动态扩容?
首先第一个问题,我们的散列表采用二维数组方式进行存储,具体结果如下,初始散列表长度为8,内容全为None,与Python内置的dict初始容量保持一致:
[
[hash值, key, value],
[hash值, key, value],
[hash值, key, value],
...
]
第二个问题,这里采用字符串求值的哈希函数,也就是说key支持str类型
第三个问题,解决hash冲突采用开放定址+定性的线性探测
第四个问题,动态扩容也按照Python底层实现,即当容量超过三分之二时,进行扩容,扩容策略为已有散列表键值对个数 * 2,而在pop()时不进行缩容,但是在clear()会进行缩容,将散列表恢复初始状态。
map实现
下面是按照Python的dict底层实现的动态扩容map:
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
class ADTMap:
def __init__(self) -> None:
# 初始容量为8
self.cap = 8
# 已有键值对个数为0
self.size = 0
# 初始map
self.map = [[None] * 3] * self.cap
# map顺序表
self.order = [None] * self.cap
def set(self, key, value):
# 求hash值
hashValue = self.__getHash(key)
# 求插入或者更新槽位
slotIdx = self.__getSlot(hashValue)
# 检查是否需要扩容, 当容量超过三分之二时,即进行扩容(resize)机制
if (self.size + 1 > round(self.cap * (2 / 3))):
self.__resize()
# 添加键值对
self.map[slotIdx] = [hashValue, key, value]
self.size += 1
# 添加顺序表,如果是更新value,则不用添加
for i in range(len(self.order)):
if self.order[i] is None or slotIdx == self.order[i]:
self.order[i] = slotIdx
break
def get(self, key):
# 求hash值
hashValue = self.__getHash(key)
# 求key所在槽位
slotIdx = self.__getSlot(hashValue)
return self.map[slotIdx][2]
def pop(self, key):
# 求hash值
hashValue = self.__getHash(key)
# 求key所在槽位
slotIdx = self.__getSlot(hashValue)
if self.map[slotIdx][2] == None:
raise KeyError("%s" % key)
# 移除key
self.size -= 1
retValue = self.map[slotIdx][2]
self.map[slotIdx] = [None] * 3
for idx in range(len(self.order)):
if self.order[idx] == slotIdx:
# 删除
del self.order[idx]
# 在最后添加空的,确保前面都是有序的不会出现None
self.order.append([None] * 3)
break
return retValue
def keys(self):
for idx in self.order:
if idx is not None:
yield self.map[idx][1]
else:
break
def values(self):
for idx in self.order:
if idx is not None:
yield self.map[idx][2]
else:
break
def items(self):
for idx in self.order:
if idx is not None:
yield self.map[idx][1], self.map[idx][2]
else:
break
def clear(self):
self.cap = 8
self.size = 0
self.map = [[None] * 3] * self.cap
self.order = [None] * self.cap
def __setitem__(self, name, value):
self.set(key=name, value=value)
def __getitem__(self, name):
return self.get(key=name)
def __delitem__(self, name):
# del map["k1"] 无返回值
self.pop(key=name)
def __contains__(self, item):
keyList = self.keys()
for key in keyList:
if key == item:
return True
return False
def __iter__(self):
# 直接迭代map则返回keys列表
return self.keys()
def __getHash(self, key):
# int类型的keyhash值是其本身
if isinstance(key, int):
return key
# str类型需要使用ord()进行转换,并添加位权
if isinstance(key, str):
idx = 0
v = 0
while idx < len(key):
v += ord(key[idx]) * (idx + 1)
idx += 1
return v
# 暂不支持其他类型
raise KeyError("key not supported type %s" % (type(key)))
def __getSlot(self, hashValue):
# 求初始槽位
slotIdx = hashValue % (self.cap)
# 检测没有hash冲突的槽位
return self.__checkSlot(slotIdx, hashValue)
def __checkSlot(self, slotIdx, hashValue):
# 获取原有槽位的hash
slotHash = self.map[slotIdx][0]
# 如果原有槽位不为空,且与新的key值hash不同
if slotHash is not None and slotHash != hashValue:
# 避免线性探测超过散列表长度
if slotIdx < self.cap - 1:
return self.__checkSlot(slotIdx + 1, hashValue)
# 如果线性探测超过散列表长度,则从头开始探测
return self.__checkSlot(0, hashValue)
# 否则就是空槽位,或者旧hash与新hash相同,直接返回即可
return slotIdx
def __resize(self):
# 计算新容量,已有散列表键值对个数 * 2
self.cap += self.size * 2
# 执行扩容
self.map.extend(
[[None] * 3] * (self.size * 2)
)
# 顺序表也进行扩容
self.order.extend([None] * (self.size * 2))
def __len__(self):
return self.size
def __str__(self) -> str:
retStr = ""
for idx in self.order:
if idx is not None:
retStr += " <%r : %r> " % (self.map[idx][1], self.map[idx][2])
else:
break
retStr = "[" + retStr + "]"
return retStr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号