MQ RabbitMQ 基本应用
RabbitMQ
RabbitMQ可以说是目前较为火热的一款消息中间件,其本身由Erlang语言进行编写,部署简单操作方便,是必备的一门技术栈。
它支持各种主流语言的驱动,如下所示:

那么现在本章将用Python来探究一下RabbitMQ的使用。
RabbitMQ官方提供多种安装方式,具体可参照官网,这里将采用Docker部署,版本为3.8.14:
docker run -d --name rabbitmq -p 5672:5672 -p 15672:15672 rabbitmq:3-management
同时我们还需要为Python安装对应操纵RabbitMQ的驱动模块,名为pika,可直接通过pip进行安装:
pip3 install pika
基础的p2p
简单模式
基础的p2p在RabbitMQ中被称为简单模式,即一个生产者的信息仅能被一个消费者所接收,整个流程步骤如下:
- 生产者/消费者链接RabbitMQ服务
- 生产者/消费者创建消息队列
- 生产者产生消息,放入消息队列中
- 消费者获得消息,并且消费该消息
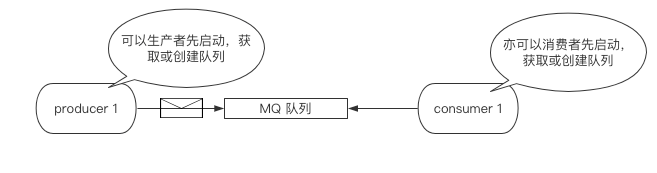
生产者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
# 如果有用户名和密码
# credentials = pika.PlainCredentials("username","password")
# 建立链接时还需要传入一个位置参数
# credentials=credentials
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 创建/获取队列
channel.queue_declare(queue="q1")
# exchange = "": 普通的p2p模式
# routing_key:放进那个队列
# body:消息主体
channel.basic_publish(
exchange="",
routing_key="q1",
body="this is a message",
)
print("The message is sent to q1!")
消费者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 创建/获取队列
channel.queue_declare(queue="q1")
# 回调函数:ch,method,properties都是固定写法,body参数是消息体,bytes格式
def callback(ch, method, properties, body):
print(body.decode("utf8"))
print("The consumer successfully gets the message from the q1 queue!")
# queue:监听的队列
# auto_ack:自动回复ack确认
channel.basic_consume(
queue="q1",
auto_ack=True,
on_message_callback=callback,
)
# 开始监听队列,会一直进行监听
channel.start_consuming()
多个消费
如果仅有一个生产者,而有多个消费者想要获取数据,那这些消费者则会轮询的依次的从队列中获得数据,如下代码可对其进行验证,你只需要并行的多开几个消费者即可:
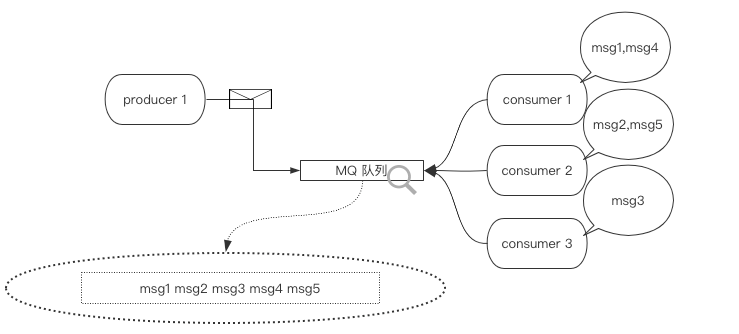
生产者代码 如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
channel.queue_declare(queue="q1")
for i in range(5):
channel.basic_publish(
exchange="",
routing_key="q1",
body="this is a message{0}".format(i),
)
print("The message{0} is sent to q1".format(i))
消费者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
channel.queue_declare(queue="q1")
def callback(ch, method, properties, body):
print(body.decode("utf8"))
print("The consumer successfully gets the message from the q1 queue!")
channel.basic_consume(
queue="q1",
auto_ack=True,
on_message_callback=callback,
)
channel.start_consuming()
相关参数
应答参数
在消费者中,有一条这样的代码:
# auto_ack=True
channel.basic_consume(
queue="q1",
auto_ack=True,
on_message_callback=callback,
)
这条代码的意思是一旦消费者从队列中取出消息,不论是否消费该消息,都会立即向RabbitMQ服务发送一个我以接收,你可以从队列中将该消息抹除的信号。
如下图所示:
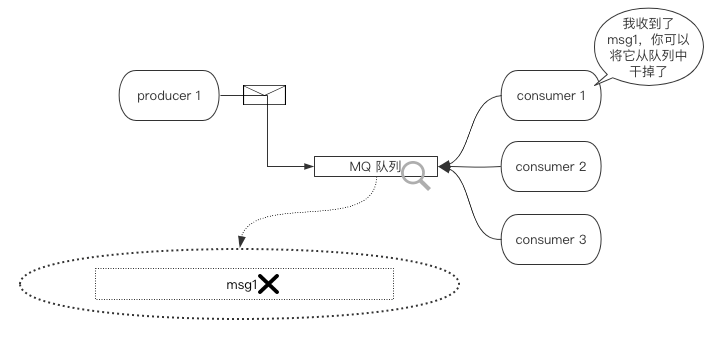
如果该参数设置为False,则代表消费者向RabbitMQ的这条ack确认信号转为手动触发,也就是说,我们可以在消费者成功的消费掉这条信息后再手动通知RabbitMQ从队列中将该消息进行移除。
本质上,该参数如果为False,消费者是不会取出队列中的信息,而是完全拷贝一份。

在消费完成后,你可以手动通知RabbitMQ删除消息的代码如下,固定写法:
ch.basic_ack(delivery_tag=method.delivery_tag)
还是上一个整体的消费者代码吧...
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
channel.queue_declare(queue="q1")
def callback(ch, method, properties, body):
print("Processing...")
time.sleep(3)
# 通知RabbitMQ,你可以删除了
ch.basic_ack(delivery_tag=method.delivery_tag)
# auto_ack:手动回复ack确认
channel.basic_consume(
queue="q1",
auto_ack=False,
on_message_callback=callback,
)
channel.start_consuming()
另外,如果此时你启动3个消费者,你会发现队列中的消息不是轮询了,而是被第一个消费者独占:

持久化参数
RabbitMQ中所有的消息都存储在内存中,这意味着某些特殊情况下,如RabbitMQ服务突然宕掉之后,在队列中的数据都会丢失。
我们可以对队列进行持久化设置,让其将数据保存在磁盘中。
有趣的是,RabbitMQ中对队列的持久化分为2个层次:
- 你这个队列要不要持久化?
- 你这个队列中的消息要不要持久化?
需要注意的是,在RabbitMQ的一次服务周期中,一个队列如果已经声明是非持久化队列,则不能将其改变为持久化队列,你需要重新创建一个新的持久化队列。
用代码看一下实际效果吧,将下面这段生产者代码尝试运行:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
# durable:如果为True则代表着是持久化队列,默认是False
channel.queue_declare(queue="q2", durable=True)
# delivery_mode:2是对该消息持久化,1是不持久化,默认为1
channel.basic_publish(
exchange="",
routing_key="q2",
body="持久化信息",
properties=pika.BasicProperties(
delivery_mode=2,
)
)
channel.basic_publish(
exchange="",
routing_key="q2",
body="非持久化信息",
)
print("The messages is sent to q2")
现在q2队列中应该具有2条信息,我们停止Docker容器的运行在对其重新进行启动:
$ docker container stop rabbitmq
$ docker container start rabbitmq
然后启动消费者,看能拿到几条信息:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
# durable:如果为True则代表着是持久化队列,默认是False
channel.queue_declare(queue="q2", durable=True)
def callback(ch, method, properties, body):
print(body.decode("utf8"))
channel.basic_consume(
queue="q2",
auto_ack=True,
on_message_callback=callback,
)
channel.start_consuming()
当然,结果只能拿到持久化信息,非持久化信息是拿不到的。
闲置消费
默认的队列消息分发策略是轮询分发,这会导致一个问题,如我有2个消费者:
- 消费者A拿出消息,并处理
- 消费者B拿出消息,并处理
- 消费者A想拿出消息,但是消费者B还没有处理完,消费者A拿不出消息
所以我们可以将分发策略改为闲置消费,即谁处理的快,下一条消息就归谁,而不再使用轮询分发,你只需要在消费者的下面加上这句代码即可。
channel.basic_qos(prefetch_count=1)
还是拿多个消费一节的例子来举例,修改一下消费者的代码,生产者依旧用上面的即可:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
channel.queue_declare(queue="q1")
def callback(ch, method, properties, body):
print(body.decode("utf8"))
# 第二个消费者取消注释
time.sleep(50)
ch.basic_ack(delivery_tag=method.delivery_tag)
# 关闭轮询策略,改为闲置优先,必须写在监听的上面
channel.basic_qos(prefetch_count=1)
channel.basic_consume(
queue="q1",
auto_ack=False,
on_message_callback=callback,
)
channel.start_consuming()
交换机模式
普通发布订阅
RabbitMQ中的发布订阅与Kafka中的有所不同,它必须依赖一个被称为交换机的东西来进行消息的发布,整个流程如下:
- 生产者创建交换机
- 消费者创建队列链接至交换机
- 生产者创建消息,放入交换机中
- 消费者通过队列拿出交换机中的消息
如下图所示:
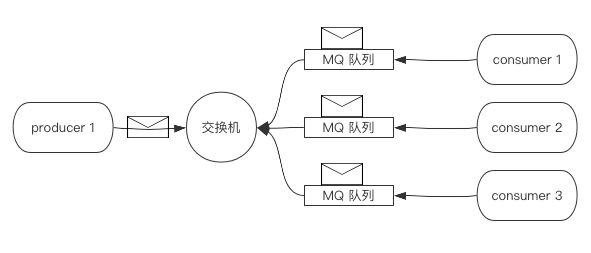
不同于p2p模式,交换机模式下所有监听该交换机的队列都会获取到信息,并且传递给消费者。
注意!必须先启动消费者,再启动生产者
生产者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
channel = connection.channel()
# 创建交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,普通的发布订阅模式
channel.exchange_declare(
exchange="switch",
exchange_type="fanout",
)
# exchange = "switch": 向交换机中发送消息
# routing_key:消息关键字
# body:消息主体
for i in range(5):
channel.basic_publish(
exchange="switch",
routing_key="",
body="this is a message{0}".format(i),
)
print("The message{0} is sent to switch".format(i))
消费者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 监听的交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,普通类型(发布订阅)
channel.exchange_declare(
exchange="switch",
exchange_type="fanout",
)
# 创建一个用于去交换机中获取消息的队列
# exclusive:队列名随机
# result:创建结果
result = channel.queue_declare("", exclusive=True)
# 从创建结果中获取队列名
queue_name = result.method.queue
# 队列绑定交换机
channel.queue_bind(
exchange="switch",
queue=queue_name
)
# 回调函数:ch,method,properties都是固定写法,body参数是消息体,bytes格式
def callback(ch, method, properties, body):
print(body.decode("utf8"))
# queue:监听的队列
# auto_ack:自动回复ack确认
channel.basic_consume(
queue=queue_name,
auto_ack=True,
on_message_callback=callback,
)
# 开始监听队列
channel.start_consuming()
关键字订阅
在上面的普通发布订阅模式中,只要生产者生产了数据,消费者就必须接收。
而在关键字订阅中,消费者可以筛选交换机中的数据,如下图所示:
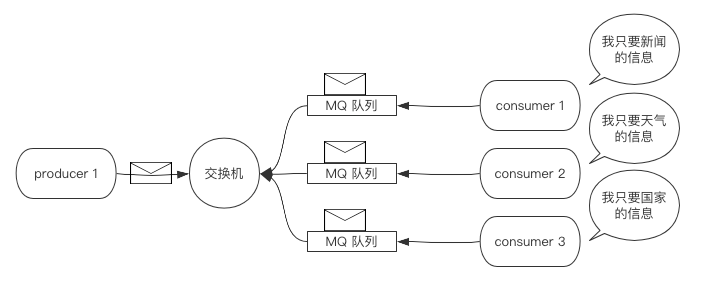
我们需要做的是改变交换机的类型为关键字类型,并且指定消费者所关心的数据关键字。
注意!必须先启动消费者,再启动生产者
生产者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 创建交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,关键字发布订阅模式
channel.exchange_declare(
exchange="switch1",
exchange_type="direct",
)
# exchange = "switch1": 向交换机中发送消息
# routing_key:消息关键字
# body:消息主题
for i in range(3):
li1 = ["新闻", "天气", "国家"]
li2 = ["大新闻", "好天气", "某国家成立了"]
channel.basic_publish(
exchange="switch1",
routing_key=li1[i],
body=li2[i],
)
print("The message{0} is sent to switch1".format(i))
消费者代码如下,仅能接收到大新闻:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 监听的交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,关键字发布订阅模式
channel.exchange_declare(
exchange="switch1",
exchange_type="direct",
)
# 创建一个用于去交换机中获取消息的队列
# exclusive:队列名随机
# result:创建结果
result = channel.queue_declare("", exclusive=True)
# 从创建结果中获取队列名
queue_name = result.method.queue
# 队列绑定交换机,仅获取新闻相关的
channel.queue_bind(
exchange="switch1",
queue=queue_name,
routing_key="新闻",
)
# 回调函数:ch,method,properties都是固定写法,body参数是消息体,bytes格式
def callback(ch, method, properties, body):
print(body.decode("utf8"))
# queue:监听的队列
# auto_ack:自动回复ack确认
channel.basic_consume(
queue=queue_name,
auto_ack=True,
on_message_callback=callback,
)
# 开始监听队列
channel.start_consuming()
模糊订阅
模糊订阅是关键字订阅的一种升级版。
关键字订阅的信息必须归于某一类型,关键字一个不能多一个不能少,比如我绑定了国家这个关键字,那么就只能匹配国家的信息。
而对于国家.天气、国家.新闻这种信息一概不会匹配。
而模糊订阅就可以做到关键字订阅做不到的,我们可以使用通配符*以及#来对关键字进行模糊匹配。
- *是指仅匹配后面的任意的一个字符
- #是指匹配后面的连续多个字符
现在,我们可以使用国家.#来匹配到任何关于国家的词汇,如国家天气、国家新闻等等信息。
如下图所示:
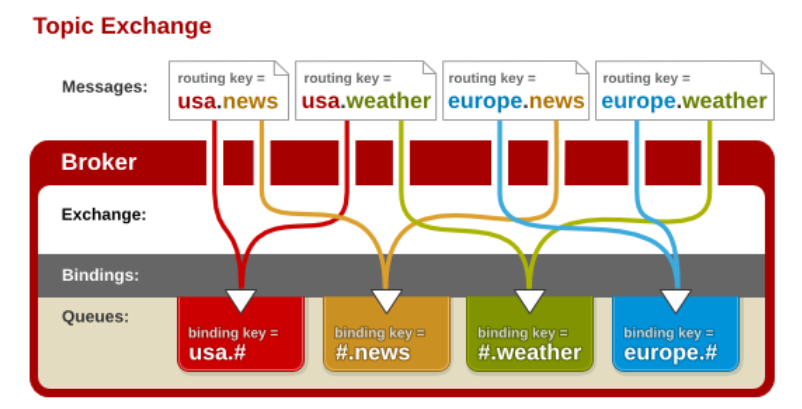
注意!必须先启动消费者,再启动生产者
生产者代码如下:
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 创建交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,模糊的订阅模式
channel.exchange_declare(
exchange="switch3",
exchange_type="topic",
)
# exchange = "switch3": 向交换机中发送消息
# routing_key:消息关键字,必须严格按照.进行分割才能匹配
# body:消息主体
channel.basic_publish(
exchange="switch3",
routing_key="国家.新闻",
body="xx国家的新闻",
)
channel.basic_publish(
exchange="switch3",
routing_key="国家.天气",
body="xx国家的天气",
)
channel.basic_publish(
exchange="switch3",
routing_key="天气.新闻",
body="xx天气的新闻",
)
print("The messages is sent to switch3")
消费者代码如下,仅能接收到国家.新闻、国家.天气,而对于天气.新闻来说是接收不到的::
#!/usr/local/bin/python3
# -*- coding:utf-8 -*-
import time
import pika
# 建立链接
connection = pika.BlockingConnection(pika.ConnectionParameters(host="localhost", port=5672))
# 拿到操纵对象
channel = connection.channel()
# 监听的交换机
# exchange:交换机的名字
# exchange_type:交换机的类型,模糊的订阅模式
channel.exchange_declare(
exchange="switch3",
exchange_type="topic",
)
# 创建一个用于去交换机中获取消息的队列
# exclusive:队列名随机
# result:创建结果
result = channel.queue_declare("", exclusive=True)
# 从创建结果中获取队列名
queue_name = result.method.queue
# 队列绑定交换机,仅获取国家xx相关的
channel.queue_bind(
exchange="switch3",
queue=queue_name,
routing_key="国家.#",
)
# 回调函数:ch,method,properties都是固定写法,body参数是消息体,bytes格式
def callback(ch, method, properties, body):
print(body.decode("utf8"))
# queue:监听的队列
# auto_ack:自动回复ack确认
channel.basic_consume(
queue=queue_name,
auto_ack=True,
on_message_callback=callback,
)
# 开始监听队列
channel.start_consuming()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号