DBA Elasticsearch 分词器
分词器
分词的意思就是将一段文字拆分成一个一个的关键字,在搜索时通过关键字搜索出相关数据。
举例:
美国队长
- 美国
- 美国队
- 国队
- 队长
- 美国队长
当然,这里的分词规则只是较常用的一种,除此之外还有非常多的分词规则。
下面我们将使用kibana对其进行详细的测试。
内置分词器
standard
内置的分词器,区分中文、英文。
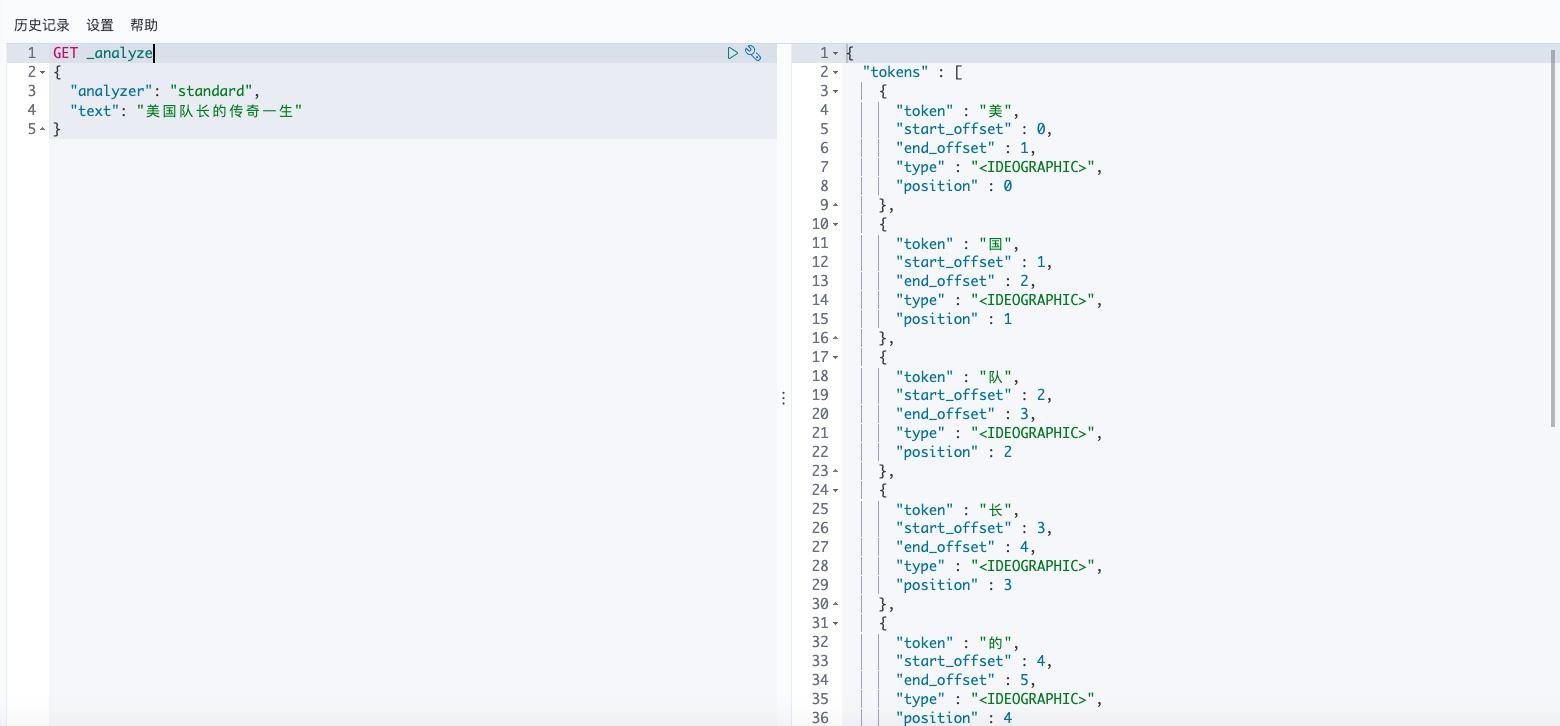
中文为最小单元分词:
GET _analyze
{
"analyzer": "standard",
"text": "美国队长的传奇一生"
}
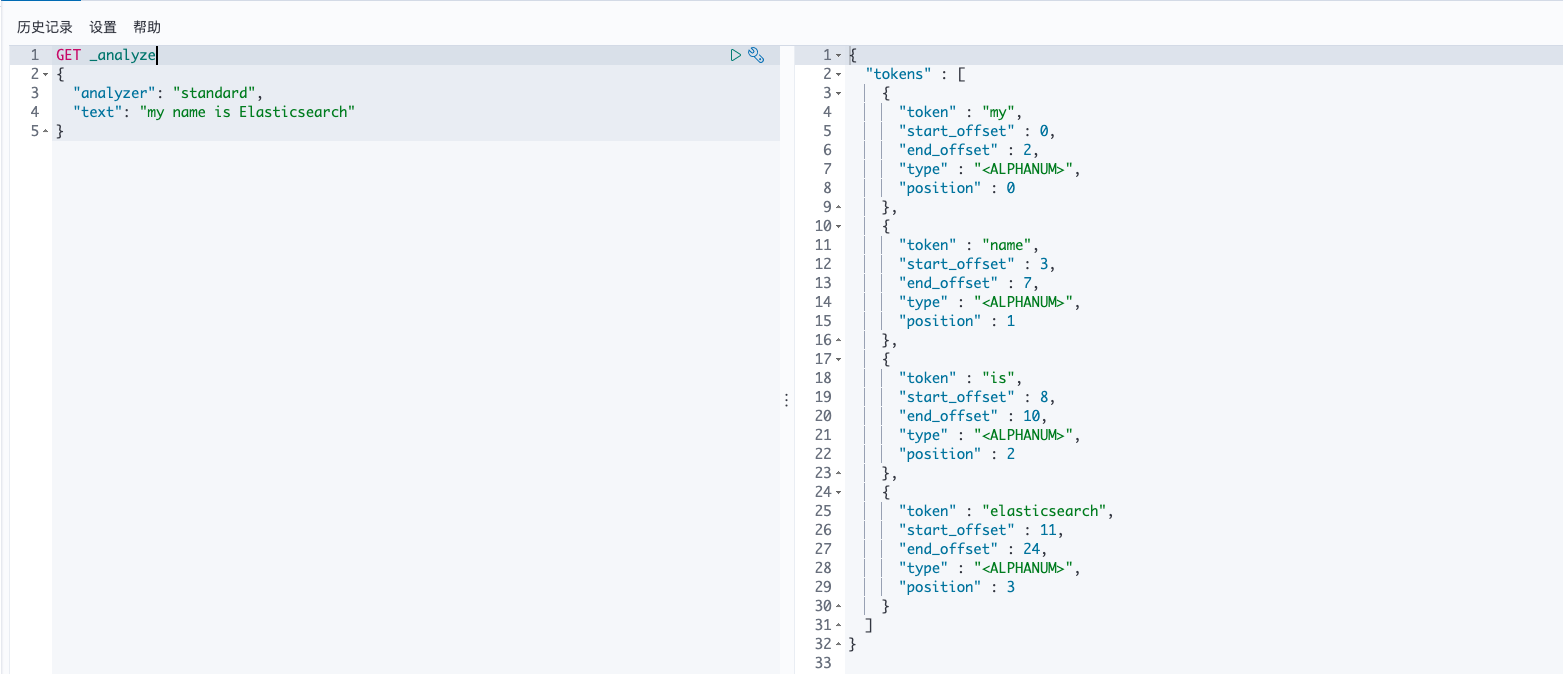
该分词器对英文支持较好:
GET _analyze
{
"analyzer": "standard",
"text": "my name is Elasticsearch"
}
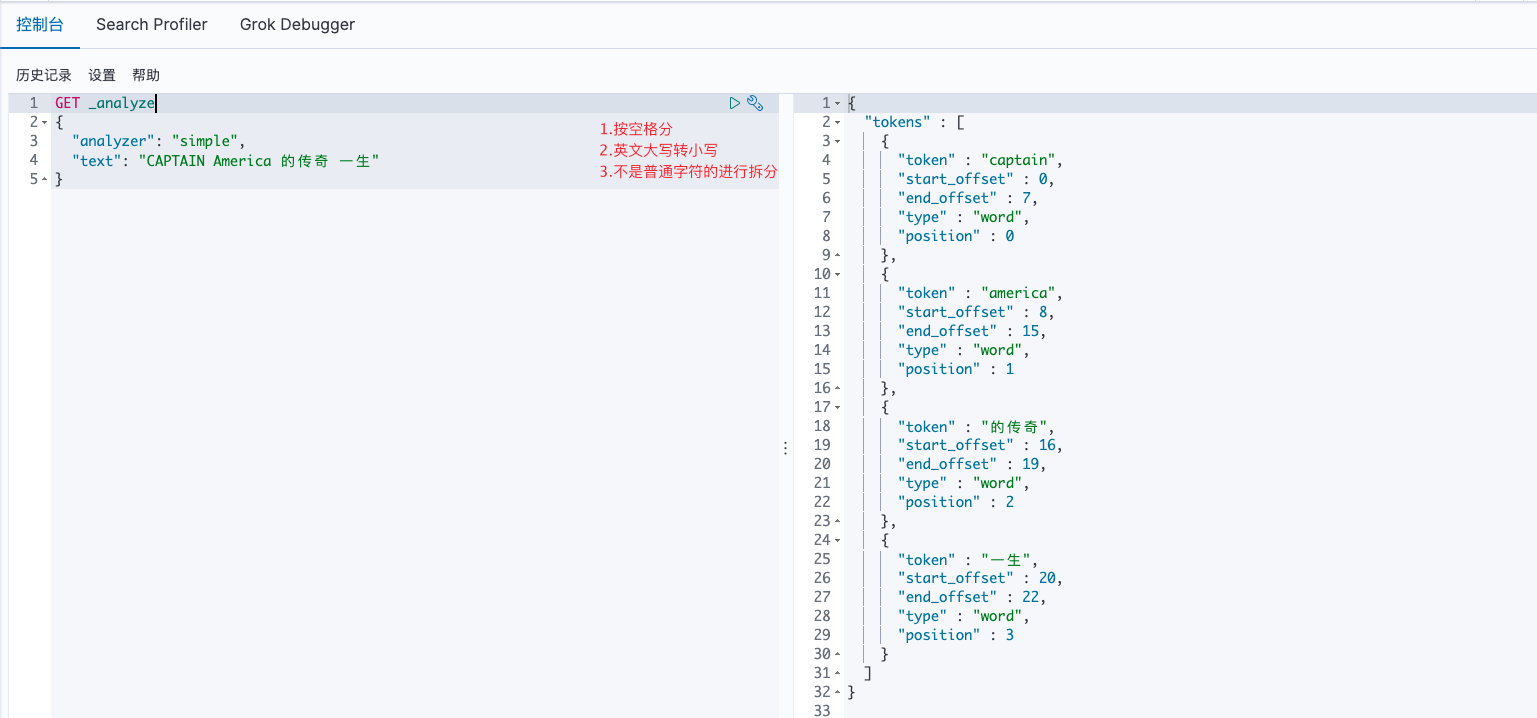
simple
较为轻量级的分词器,先按照空格分,同时它会将大写英文转换为小写,之后只要不是普通字符的就进行一次分词:
GET _analyze
{
"analyzer": "simple",
"text": "CAPTAIN America 的传奇 一生"
}
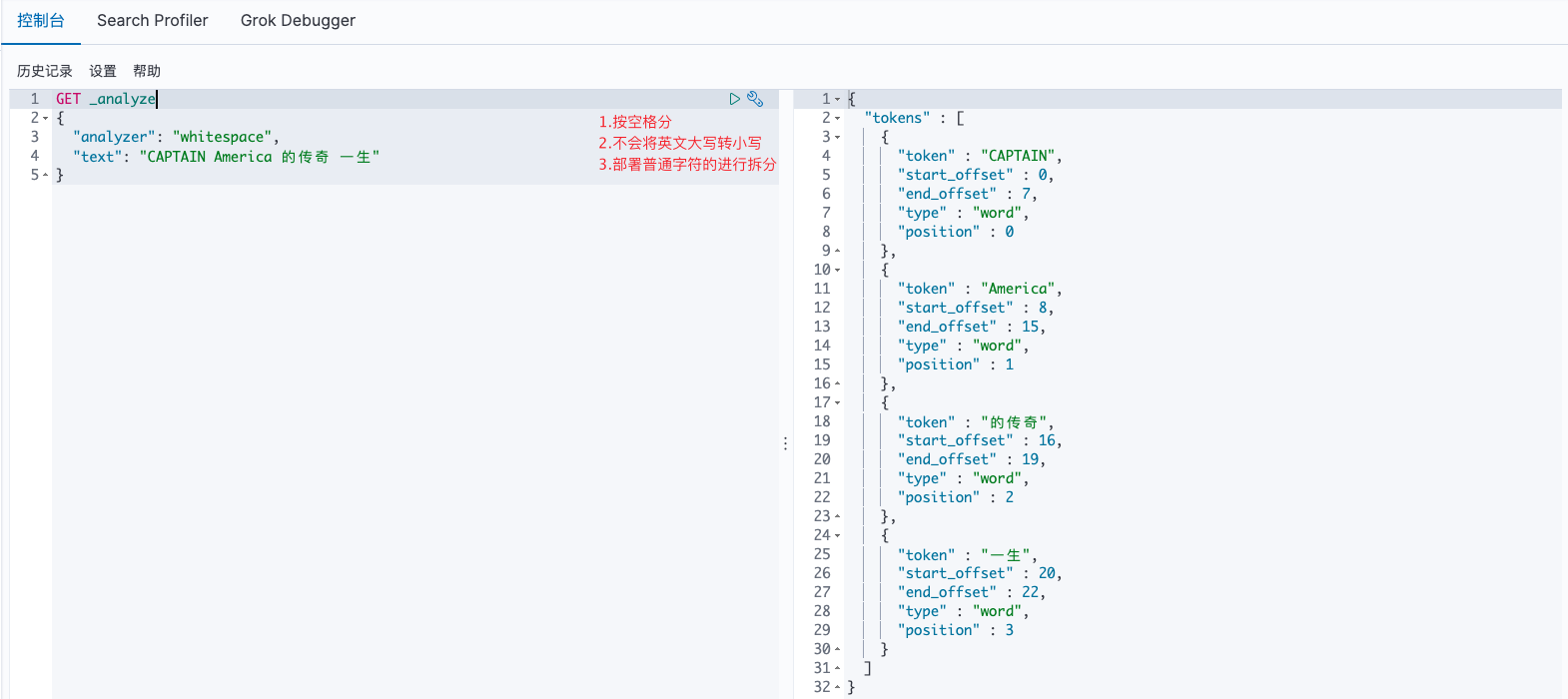
whitespace
较为轻量级的分词器,先按照空格分,它并不会将大写英文转换为小写,
此外、只要不是普通字符的就进行一次分词:
GET _analyze
{
"analyzer": "whitespace",
"text": "CAPTAIN America 的传奇 一生"
}
IK分词器
安装部署
IK分词器是一个非常火的中文分词器,它能够提供多种分词规则。
如果不使用IK分词器,则中文默认按照最小单元进行划分,即每个汉字都拆分开,是十分不方便的,而IK分词器却恰好可以解决这个问题。
除此之外,它还能提供自定义词库等相关操作,从而让开发人员能够随意定制检索关键词。
在下载安装时要注意与Elasticsearch版本对应。
不同于之前介绍到Elasticsearch-head和kibana工具,IK分词器需要安装在Elasticsearch服务终端上以插件的形式进行载入。
Github地址
1)进入Elasticsearch的pubgins目录中:
$ cd /usr/share/elasticsearch/plugins
2)下载并解压zip包:
$ mkdir ik
$ cd ik
$ wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.6.1/elasticsearch-analysis-ik-7.6.1.zip
$ unzip elasticsearch-analysis-ik-7.6.1.zip
3)重启Elasticsearch服务:
$ systemctl restart elasticsearch
4)重启成功后查看是否加载了该插件:
$ cd /usr/share/elasticsearch/bin/
$ /bin/bash elasticsearch-plugin list
ik
分词规则
ik分词器提供2种分词功能。
- ik_smart:相对于智能的拆分,拆分次数较少
- ik_max_word:最细粒度拆分,拆分次数较多
ik_smart
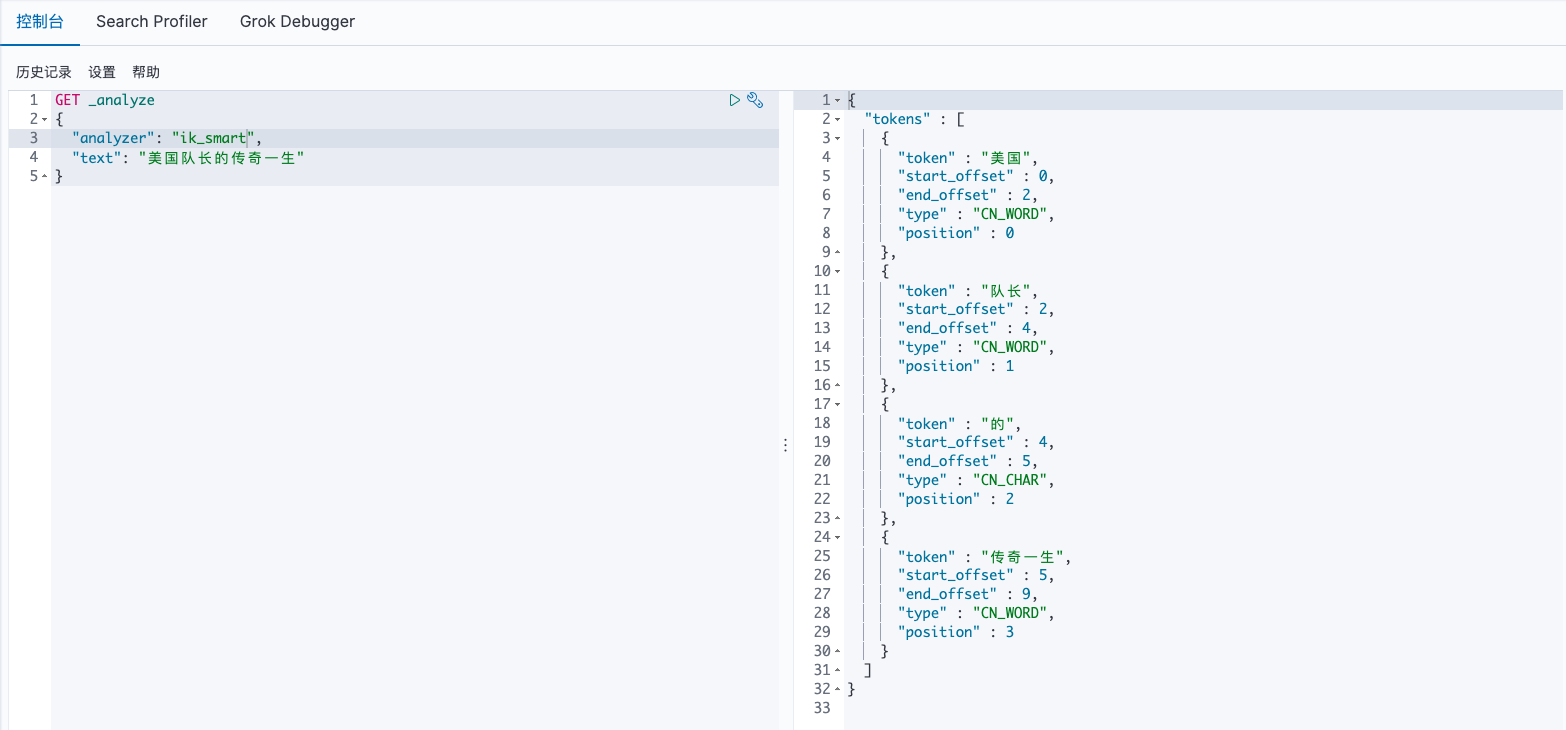
功能测试,ik_smart拆分规则为次数较少的拆分:
GET _analyze
{
"analyzer": "ik_smart",
"text": "美国队长的传奇一生"
}
ik_max_word
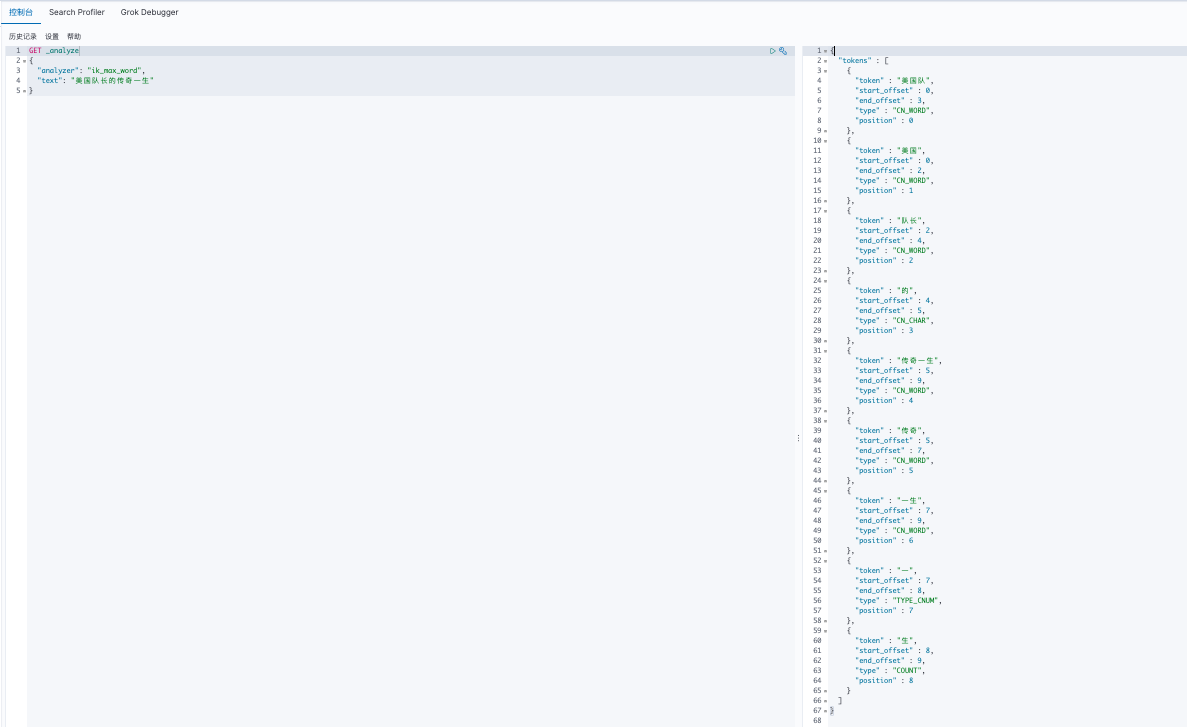
功能测试,ik_max_word拆分规则为最细粒度拆分:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "美国队长的传奇一生"
}
词库配置
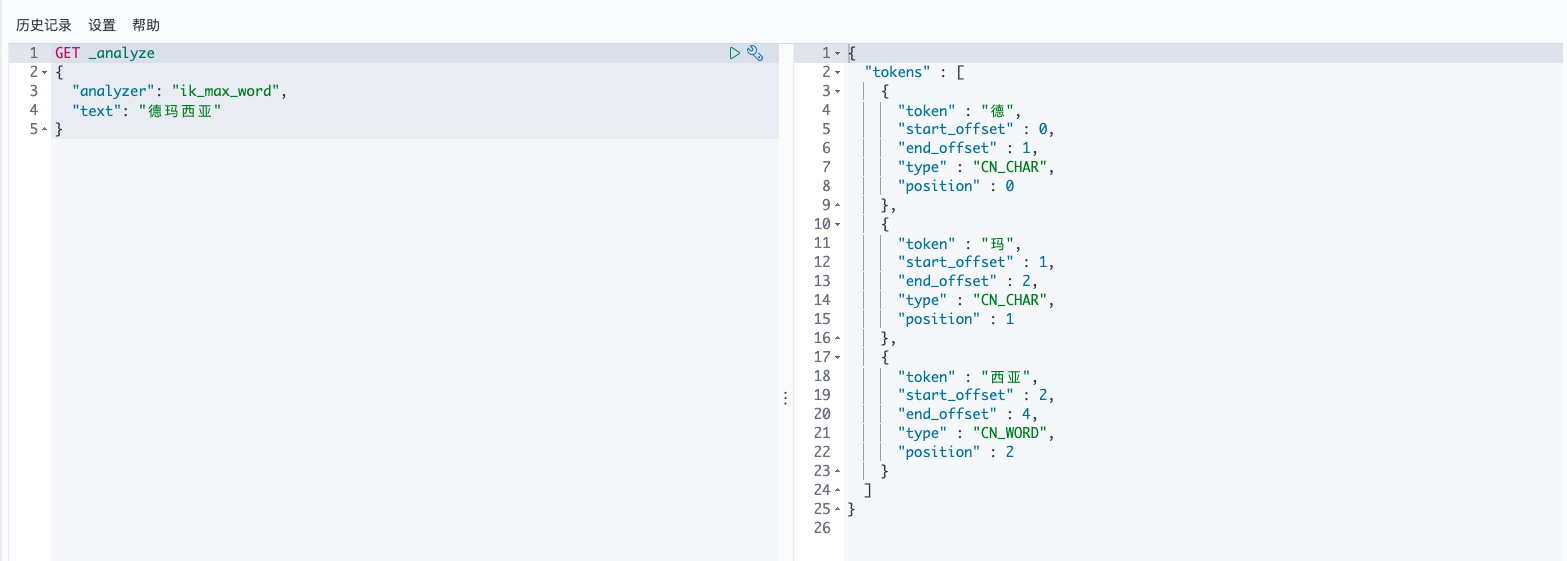
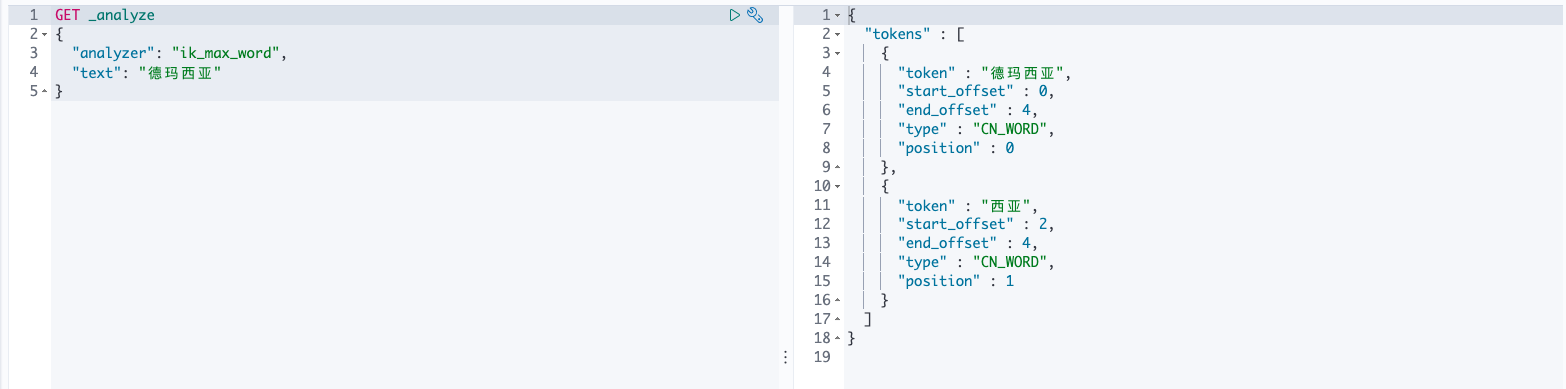
自定义词库,如著名的旅游胜地德玛西亚这个词汇并没有被IK分词器字典所收录:
在Elasticsearch的ik插件目录中新增字典文件:
$ cd /usr/share/elasticsearch/plugins/ik/config/
$ vim ./addr.dic
# 输入
德玛西亚
然后需要加载该配置:
$ vim IKAnalyzer.cfg.xml
# 修改
<entry key="ext_dict">./addr.dic</entry>
最后重启Elasticsearch服务:
$ systemctl restart elasticsearch
再次进行测试:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号