DBA Redis 开发指南
应用场景
Redis常用于数据缓存,与MySQL进行搭配能有良好的效果。
如下图所示:
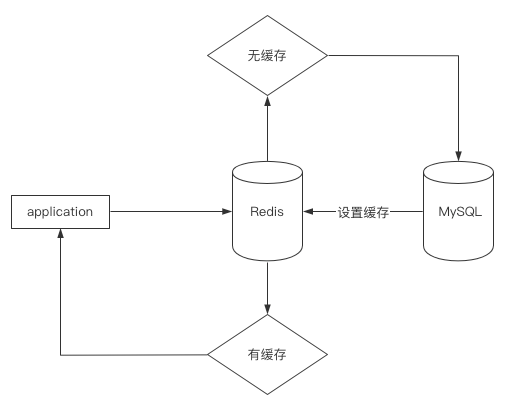
Redis数据存储在内存中,读取操作比MySQL从磁盘数据页读取快了不止千倍,因此使用Redis作为缓存是十分明智的选择。
但是这样的使用场景依然会发生很多意料之外的问题,本文将对其进行简单的探究。
缓存雪崩
名词认识
缓存数据大面积同一时间失效,造成所有查询操作都直逼MySQL,查询速度大幅度降低,并发量高的情况下MySQL可能产生宕机。
导致因素:
- 缓存数据设置了相同的TTL
- Reids挂掉了
解决方案
1)缓存数据时为每一个缓存加上随机值,让其过期时间均有不同
setRedis(Key,value,time + Math.random() * 10000);
2)热点数据永不删除,如首页轮播图等重要数据,只有当MySQL更新后才对该热点缓存进行更新
除此之外,做好主从+哨兵或者集群的高可用架构,分担单Redis服务的压力,防止单服务宕机
当事发时,采用本地缓存+限流的策略,减少MySQL的压力
事发后使用Redis持久化对数据进行恢复
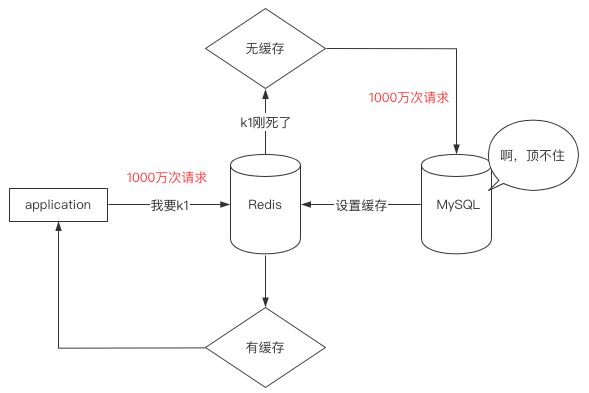
缓存击穿
名词认识
缓存雪崩是大面积缓存同一时刻失效,而缓存击穿是指一个key过于热门,导致大并发频繁请求该key
此时如果该key的过期时间一到,所有请求都直接访问MySQL,这就是缓存击穿
解决方案
1)对热点缓存进行分析,设置其永不过期,只有当MySQL更新后才对该热点缓存进行更新
2)限流策略,当热点缓存失效后进行限流,减少MySQL承载的并发量
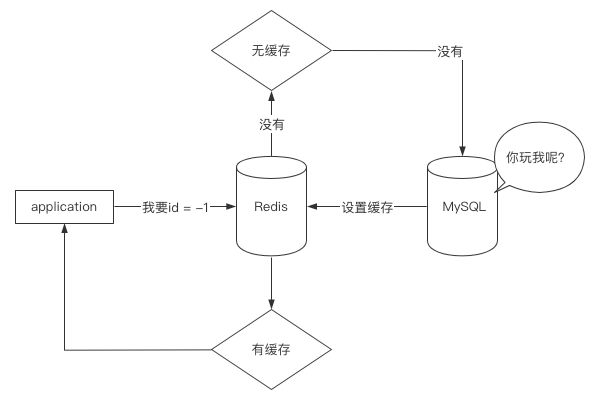
缓存穿透
名词认识
缓存穿透是指大量的请求缓存中不存在而去请求MySQL,但MySQL中也不存在该信息
假设,请求时的条件为id = -1,这是一个非法数据,缓存和数据库都没有,经过2次查询之后发现啥都没有,造成额外的查询资源消耗
可能导致的因素:
- 用户误操作
- 恶意竞争
- 黑客攻击
解决方案
1)在用户请求时屏蔽非法请求,如id < 0的请求直接返回
2)使用性能代价较小的查询对其进行过滤,如布隆过滤器
3)设置一个空值(存活时间短)到缓存中,如请求 id < 0 的我就直接返回给你结果
如果你想了解布隆过滤器,可点击跳转
双写一致性
名词认识
当查询时:
- 读走缓存
- 缓存没有查MySQL
- 查到了更新缓存,查不到进行返回
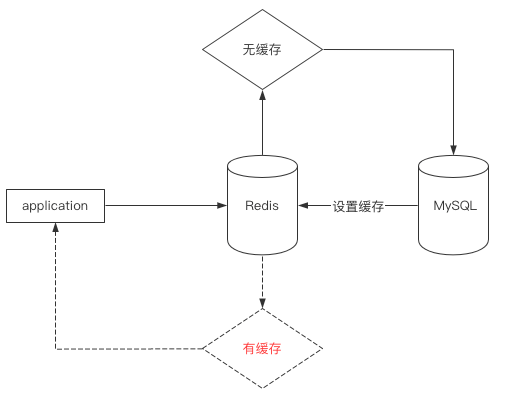
结合本文第一幅图进行了解
双写一致性的问题是,当MySQL数据更新后如何更新缓存中的数据,如下图?
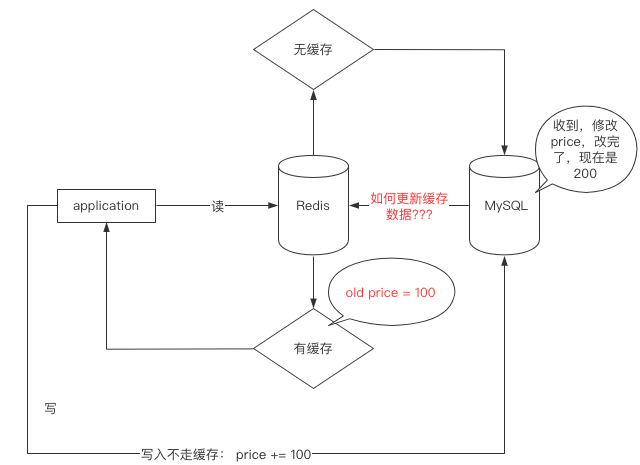
如何一致
前提:两方的修改必须要同时成功或者同时失败,所以这会演变成一个分布式事务的问题。
方案1)先操作数据库再操作缓存:
- 更新数据库
- 删除缓存
这里为什么是删除缓存而非更新缓存呢?
其实我们只需要等待下一次对该数据的读取操作进行时再设置缓存即可。
这样做能带来2点好处:
-
保证了分布式事务的一致性,基于日志优先写的原则,如果数据库没有进行落盘操作而缓存更新了,则可能会导致接下来的操作出现问题
-
减缓写入时间,只写进MySQL而直接删除缓存在高并发情况下是良好的策略,如果此时更新完MySQL的数据再去更新缓存,势必造成写入时间过长,用户体验不好的情况(删除操作比更新操作处理更简单)
方案2)先操作缓存,再操作数据库:
- 删除缓存
- 更新数据库
这个方案比较麻烦一点,必须设置这一过程为串行化,否则在高并发情况下可能出现问题。
以下场景示例:
- 线程A删除了缓存
- 线程B查询,发现缓存已不存在
- 线程B去数据库查询得到旧值
- 线程B将旧值写入缓存
- 线程A将新值写入数据库
解决过程是做一个串行化的任务队列,将每个线程的操作存放在队列中进行逐一执行,保证2边数据的一致性:

综上所述,更推荐方案1,方案2在高并发下的表现并不如意..

 浙公网安备 33010602011771号
浙公网安备 33010602011771号