DBA Redis trib.rb工具集群管理
安装介绍
redis-trib.rb是一款由Redis官方提供的集群管理工具,能够大量减少集群搭建的时间。
除此之外,还能够简化集群的检查、槽迁徙、负载均衡等常见的运维操作,但是使用前必须要安装ruby环境。
1)使用yum进行安装ruby:
yum install -y rubygems
2)默认的ruby包管理工具镜像源在国外,将国外源删除添加国内源
gem sources --remove https://rubygems.org/
gem sources -a http://mirrors.aliyun.com/rubygems/
gem update --system
3)使用ruby的包管理工具下载必备依赖包,由于我使用的是6.2.1的Redis,可能没有最新的,就下载一个老版本的Redis驱动,经测试没有任何问题:
gem install redis -v 3.3.5
另外,在新版Redis中,redis-trib.rb工具的功能都被集成在了redis-cli里,但依然需要ruby环境
搭建前戏
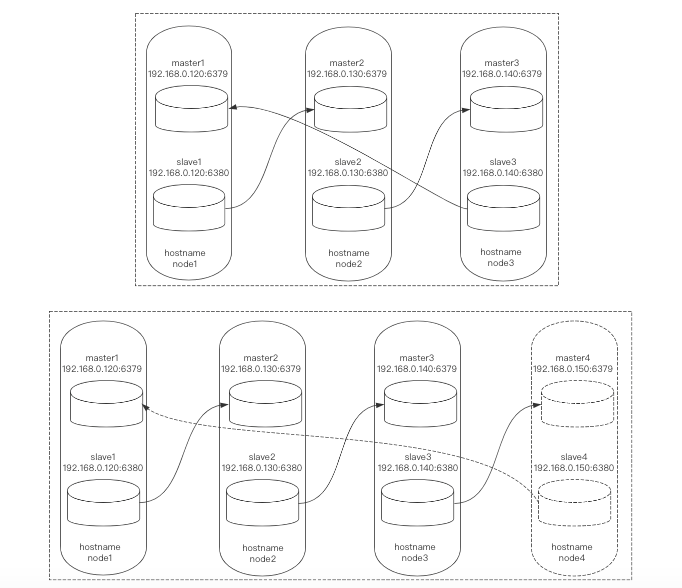
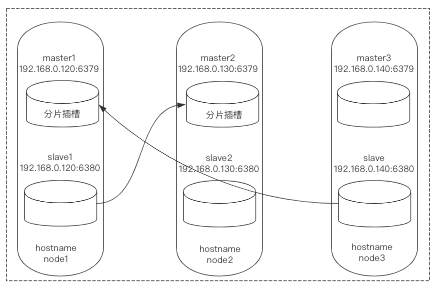
地址规划
首先我们准备2主2从的3台多实例服务器,利用redis-trib.rb工具搭建1个6节点3分片的集群(集群最少6节点)。
然后再使用redis-trib.rb工具增加1台多实例服务器,组成8节点4分片的集群。
之后再使用redis-trib.rb工具下线1台多实例服务器,变为6节点3分片的集群。
地址规划与架构图如下:
在每个节点hosts文件中加入以下内容;
$ vim /etc/hosts
192.168.0.120 node1
192.168.0.130 node2
192.168.0.140 node3
192.168.0.150 node4
!由于该工具具有难以发现的小bug,必定出现以下问题:
- 主从关系自动构建不准确,需要手动重新搭建主从关系,如果主从构建不合理,一旦发生灾难情况后果不堪设想
集群准备
为所有节点下载Redis:
$ cd ~
$ wget https://download.redis.io/releases/redis-6.2.1.tar.gz
为所有节点配置目录:
$ mkdir -p /usr/local/redis_cluster/redis_63{79,80}/{conf,pid,logs}
所有节点进行解压:
$ tar -zxvf redis-6.2.1.tar.gz -C /usr/local/redis_cluster/
所有节点进行编译安装Redis:
$ cd /usr/local/redis_cluster/redis-6.2.1/
$ make && make install
书写集群配置文件,注意!Redis普通服务会有2套配置文件,一套为普通服务配置文件,一套为集群服务配置文件,我们这里是做的集群,所以书写的集群配置文件,共6份:
$ vim /usr/local/redis_cluster/redis_6379/conf/redis.cnf
# 快速修改::%s/6379/6380/g
# 守护进行模式启动
daemonize yes
# 设置数据库数量,默认数据库为0
databases 16
# 绑定地址,需要修改
bind 192.168.0.120
# 绑定端口,需要修改
port 6379
# pid文件存储位置,文件名需要修改
pidfile /usr/local/redis_cluster/redis_6379/pid/redis_6379.pid
# log文件存储位置,文件名需要修改
logfile /usr/local/redis_cluster/redis_6379/logs/redis_6379.log
# RDB快照备份文件名,文件名需要修改
dbfilename redis_6379.rdb
# 本地数据库存储目录,需要修改
dir /usr/local/redis_cluster/redis_6379
# 集群相关配置
# 是否以集群模式启动
cluster-enabled yes
# 集群节点回应最长时间,超过该时间被认为下线
cluster-node-timeout 15000
# 生成的集群节点配置文件名,文件名需要修改
cluster-config-file nodes_6379.conf
集群搭建
启动集群
每个节点上执行以下2条命令进行服务启动:
$ redis-server /usr/local/redis_cluster/redis_6379/conf/redis.cnf
$ redis-server /usr/local/redis_cluster/redis_6380/conf/redis.cnf
集群模式启动,它的进程后会加上[cluster]的字样:
$ ps -ef | grep redis
root 78586 1 0 21:56 ? 00:00:00 redis-server 192.168.0.120:6379 [cluster]
root 78616 1 0 21:56 ? 00:00:00 redis-server 192.168.0.120:6380 [cluster]
root 78636 71501 0 21:56 pts/1 00:00:00 grep --color=auto redis
同时,查看一下集群节点配置文件,会发现生成了一组集群信息,每个Redis服务都是不同的:
$ cat /usr/local/redis_cluster/redis_6379/nodes_6379.conf
c71b52f728ab58fedb6e05a525ce00b453fd2f6b :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
$ cat /usr/local/redis_cluster/redis_6380/nodes_6380.conf
d645d06708e1eddb126a6c3c4e38810c188d0906 :0@0 myself,master - 0 0 0 connected
vars currentEpoch 0 lastVoteEpoch 0
# 第一段信息是这个Redis服务作为集群节点的一个身份编码
# 别名为集群的node-id
自动化
现在我们有2个部分还没有做,1是对集群进行分槽工作,2是构建主从关系。
通过redis-trib.rb工具,这个步骤将变得异常简单,由于我的ruby是装在node1上,所以只需要在node1执行下面一句话即可。
$ cd /usr/local/redis_cluster/redis-6.2.1/src/
# 旧版Redis这里以脚本名开头 redis-trib.rb 跟上后面参数即可
$ redis-cli --cluster create 192.168.0.120:6379 192.168.0.140:6380 192.168.0.130:6379 192.168.0.120:6380 192.168.0.140:6379 192.168.0.130:6380 --cluster-replicas 1
参数释义:
- --cluster-replicas:指定的副本数,其实这一条命令的语法规则是如果副本数为1,第一个ip:port与它后面的1个ip:port建立1主1从关系,如果副本数是2,第一个ip:port与它后面的2个ip:port建立1主2从关系,以此类推
执行完这条命令后,输入yes,会看到以下信息:
$ redis-cli --cluster create 192.168.0.120:6379 192.168.0.140:6380 192.168.0.130:6379 192.168.0.120:6380 192.168.0.140:6379 192.168.0.130:6380 --cluster-replicas 1
# 主从相关
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 192.168.0.140:6379 to 192.168.0.120:6379
Adding replica 192.168.0.130:6380 to 192.168.0.140:6380
Adding replica 192.168.0.120:6380 to 192.168.0.130:6379
M: c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379
slots:[0-5460] (5461 slots) master
M: 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380
slots:[5461-10922] (5462 slots) master
M: 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379
slots:[10923-16383] (5461 slots) master
S: d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380
replicates 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f
S: 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379
replicates c71b52f728ab58fedb6e05a525ce00b453fd2f6b
S: ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380
replicates 6a627cedaa4576b1580806ae0094be59c32fa391
# 询问是否保存配置?输入yes
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join
.
# 分槽相关,全部自动进行,无需手动操作
>>> Performing Cluster Check (using node 192.168.0.120:6379)
M: c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
M: 6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380
slots: (0 slots) slave
replicates 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f
S: 7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379
slots: (0 slots) slave
replicates c71b52f728ab58fedb6e05a525ce00b453fd2f6b
S: ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380
slots: (0 slots) slave
replicates 6a627cedaa4576b1580806ae0094be59c32fa391
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
$
仔细观察上面的主从关系就可以看到异常,我的规划是所有的6379为主节点,而6380为从节点,显然他没有按照我的意思进行划分主从。
这种情况还算好的,至少不同节点都是岔开的,怕就怕一台机器2个实例组成1主1从,如果是那样的结构主从就没有任何意义。
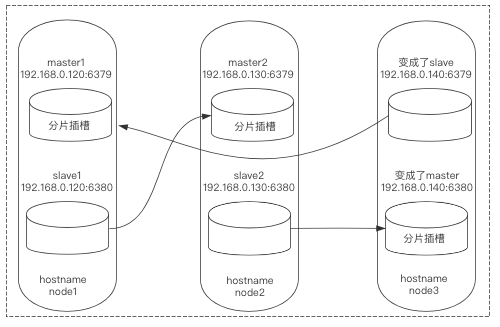
主从校正
由于上面自动部署时主从关系出现了问题,超乎了我们的预期(这可能是该工具的bug),所以我们要对其进行手动校正。
1)登录node3:6380,让其作为node1:6379的从库,由于node3:6380是一个主库,要想变为从库必须先清空它的插槽,而后进行指定:
$ redis-cli -h node3 -p 6380 -c
node3:6380> CLUSTER FLUSHSLOTS
node3:6380> CLUSTER REPLICATE c71b52f728ab58fedb6e05a525ce00b453fd2f6b
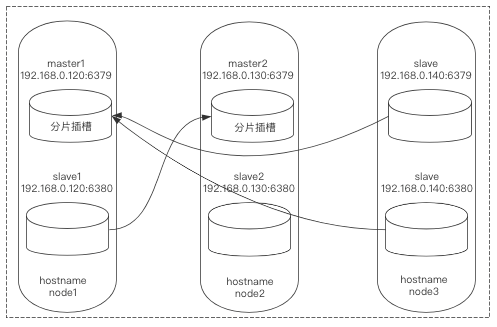
2)登录node3:6379,让该库进行下线,此举是为了重新上线令其角色变为master:
$ redis-cli -h node3 -p 6379 -c
node3:6379> CLUSTER RESET
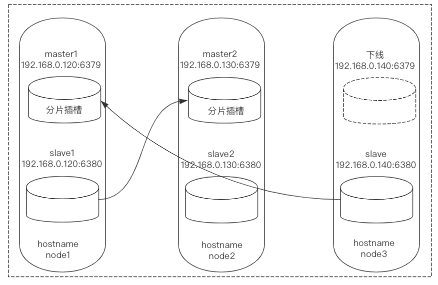
3)登录node1:6379(其实任意集群中的一个都行)重新发现node3:6379,并且记录下缺失的插槽信息:
$ redis-cli -h node1 -p 6379 -c
node1:6379> CLUSTER MEET 192.168.0.140 6379
node1:6379> CLUSTER NODES
# 仅关注master最后这一部分信息,槽位
connected 10923-16383
connected 0-5460
# 已分配10923-16383、0-5460,缺失的插槽位为5461-10922
4)为node3:6379分配插槽:
$ redis-cli -h node3 -p 6379 cluster addslots {5461..10922}
5)登录node2:6380,让其对应node3:6379,即前者作为后者的从库
$ redis-cli -h node2 -p 6380
node2:6380> CLUSTER REPLICATE 7a7392cb66bea30da401d2cb9768a42bbdefc5db
6)查看集群是否是成功运行的状态:
node2:6380> CLUSTER INFO
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:12
cluster_my_epoch:12
cluster_stats_messages_ping_sent:4406
cluster_stats_messages_pong_sent:4225
cluster_stats_messages_meet_sent:1
cluster_stats_messages_sent:8632
cluster_stats_messages_ping_received:4225
cluster_stats_messages_pong_received:4413
cluster_stats_messages_auth-req_received:4
cluster_stats_messages_received:8642
7)检查各个节点关系之间是否正常:
node2:6380> CLUSTER NODES
d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380@16380 slave 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 0 1617335179000 3 connected
282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379@16379 master - 0 1617335177627 3 connected 10923-16383
ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380@16380 myself,slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335178000 12 connected
7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379@16379 master - 0 1617335180649 12 connected 5461-10922
c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379@16379 master - 0 1617335179000 12 connected 0-5460
6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380@16380 slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335179644 12 connected
下面可能是我上面操作时输错了node-id导致的,一般按正确步骤来说不用产生这种情况。
*8)发现节点关系还是不正常,node3:6380也对应了node3:6379,更改一下就好了,让其对应node1的6379:
$ redis-cli -h node3 -p 6380
node3:6380> CLUSTER REPLICATE c71b52f728ab58fedb6e05a525ce00b453fd2f6b
*9)再次检查,节点关系正常:
node3:6380> CLUSTER NODES
c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379@16379 master - 0 1617335489929 12 connected 0-5460
6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380@16380 myself,slave c71b52f728ab58fedb6e05a525ce00b453fd2f6b 0 1617335490000 12 connected
282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379@16379 master - 0 1617335487913 3 connected 10923-16383
d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380@16380 slave 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 0 1617335488000 3 connected
7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379@16379 master - 0 1617335489000 12 connected 5461-10922
ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380@16380 slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617335490931 12 connected
node3:6380>
集群扩容
发现节点
现在我们的node4还没有添加进集群,所以将node4进行添加:
$ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6379
$ redis-cli -h node1 -p 6379 CLUSTER MEET 192.168.0.150 6380
查看节点信息,对内容进行部分截取:
$ redis-cli -h node1 -p 6379
node3:6380> cluster nodes
# 这里
f3dec547054791b01cfa9431a4c7a94e62f81db3 192.168.0.150:6380@16380 master - 0 1617337335000 0 connected
d1ca7e72126934ef569c4f4d34ba75562d36068f 192.168.0.150:6379@16379 master - 0 1617337337289 14 connected
目前node4的6379和6380并未建立槽位,也没有和其他节点建立联系,所以不能进行任何读写操作。
进行扩容
使用redis-trib.rb工具对新节点进行扩容,大体流程是每个节点拿出一部分槽位分配给node4:6379。
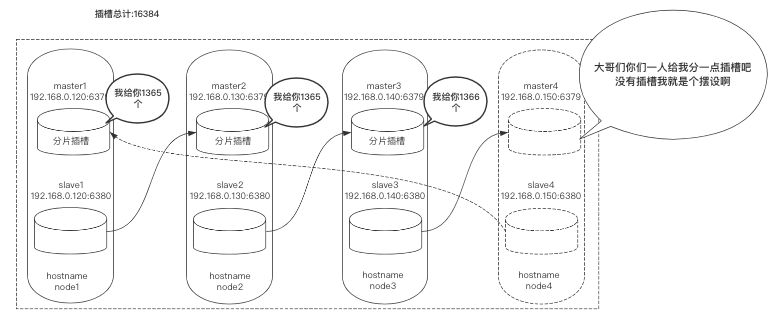
在槽位迁徙时会带着数据一起迁徙,这并不会影响正常业务,属于热扩容。
首先要做4分片的规划,每个节点共分4096个槽位:
$ python3
>>> divmod(16384,4)
(4096, 0)
接下来开始进行扩容,由于我们只在node1上装了ruby环境,所以在node1上执行:
$ cd /usr/local/redis_cluster/redis-6.2.1/src/
# 旧版Redis这里以脚本名开头 redis-trib.rb,并且不需要添加--cluster参数
$ redis-cli --cluster reshard 192.168.0.120 6379
# 你需要分配多少?
How many slots do you want to move (from 1 to 16384)? 4096
# 你要给哪一个集群节点分配插槽?我是给node4节点的6379
what is the receiving node ID? d1ca7e72126934ef569c4f4d34ba75562d36068f
# 你要从哪些集群节点给node4节点6379分配插槽呢?可以输入all代表所有节点平均分配
# 也可以输入所有节点node-ID以done结束,我这里是所有节点,需要node1:6379、node2:6379、node3:6379
# 共拿出4096的槽位分配给node4:6379
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
Source node #1: all
经过漫长的等待,终于扩容完成了:
$ redis-cli -h node1 -p 6379 cluster nodes
192.168.0.150:6379@16379 master - 0 1617337961000 14 connected 0-1364 5461-6826 10923-12287
192.168.0.130:6379@16379 master - 0 1617337967569 3 connected 12288-16383
192.168.0.120:6379@16379 myself,master - 0 1617337967000 12 connected 1365-5460
192.168.0.140:6379@16379 master - 0 1617337963000 13 connected 6827-10922
查看集群节点信息,发现他分配的并不是特别均匀,只要误差在2%以内,就算正常范围。
主从修改
如果你在线上生产环境中对Redis集群进行了扩容,一定要注意主从关系。
手动的对主从关系进行校正,这里不再进行演示。
集群缩容
移除节点
下线节点时,节点如果持有槽必须指定将该槽迁徙到别的节点。
在槽迁徙时,数据也会一并迁徙,并不影响业务。
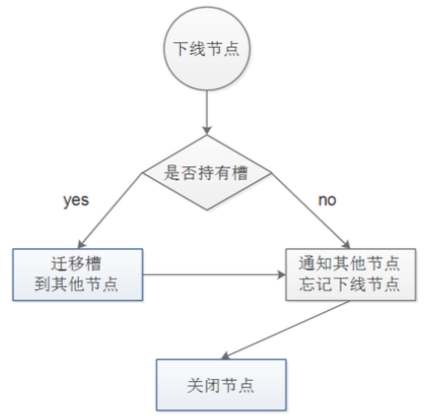
同时,当槽迁徙完成后,可在集群中对该节点进行遗忘。
进行缩容
这里缩容对象还是node4:6379,它本身具有4096个插槽,我们需要分别把4096个插槽移动到node1:6379、node2:6379、node3:6379上。
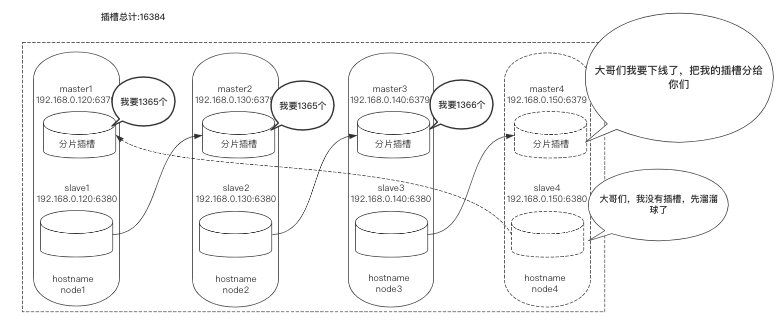
计算每个节点分多少:
$ python3
>>> divmod(4096,3)
(1365, 1)
# 2个分1365 1个分1366
开始缩容,以下操作做3次:
$ cd /usr/local/redis_cluster/redis-6.2.1/src/
# 旧版Redis这里以脚本名开头 redis-trib.rb,并且不需要添加--cluster参数
$ redis-cli --cluster reshard 192.168.0.120 6379
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 你想移动多少插槽?2次1365,1次1366
How many slots do you want to move (from 1 to 16384)? 1365
# 你想由谁来接收? node1:6379、node2:6379、node3:6379的node-id
What is the receiving node ID? 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f
# 你想指定那个节点发送插槽?
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
# node4:6379的node-id
Source node #1: d1ca7e72126934ef569c4f4d34ba75562d36068f
Source node #2: done
# 输入yes
Do you want to proceed with the proposed reshard plan (yes/no)? yes
扩容完成后检查集群状态:
$ redis-cli -h node1 -p 6379 cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:8
cluster_size:3
cluster_current_epoch:17
cluster_my_epoch:15
cluster_stats_messages_ping_sent:17672
cluster_stats_messages_pong_sent:26859
cluster_stats_messages_meet_sent:7
cluster_stats_messages_auth-req_sent:10
cluster_stats_messages_auth-ack_sent:2
cluster_stats_messages_update_sent:23
cluster_stats_messages_mfstart_sent:1
cluster_stats_messages_sent:44574
cluster_stats_messages_ping_received:17283
cluster_stats_messages_pong_received:24508
cluster_stats_messages_meet_received:5
cluster_stats_messages_fail_received:1
cluster_stats_messages_auth-req_received:2
cluster_stats_messages_auth-ack_received:5
cluster_stats_messages_mfstart_received:1
cluster_stats_messages_received:41805
查看node4:6379是否有未分配出去的插槽:
$ redis-cli -h node1 -p 6379 cluster nodes
# 没有占据任何槽位、已被全部分配出去
d1ca7e72126934ef569c4f4d34ba75562d36068f 192.168.0.150:6379@16379 master - 0 1617349187107 14 connected
f3dec547054791b01cfa9431a4c7a94e62f81db3 192.168.0.150:6380@16380 master - 0 1617349182874 0 connected
进行下线
现在就可以对node4:6379与node4:6380进行下线了,任意登录集群中某一节点,输入以下命令:
$ redis-cli -h node1 -p 6379 cluster FORGET d1ca7e72126934ef569c4f4d34ba75562d36068f
$ redis-cli -h node1 -p 6379 cluster FORGET f3dec547054791b01cfa9431a4c7a94e62f81db3
检查是否以从节点中移除:
$ redis-cli -h node1 -p 6379 cluster nodes
ff53e43f9404981a51d4e744de38004a5c22b090 192.168.0.130:6380@16380 slave 7a7392cb66bea30da401d2cb9768a42bbdefc5db 0 1617349417000 17 connected
d645d06708e1eddb126a6c3c4e38810c188d0906 192.168.0.120:6380@16380 slave 282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 0 1617349415310 16 connected
282358c2fb0c7c16ec60f2c4043b52a0eb91e19f 192.168.0.130:6379@16379 master - 0 1617349414244 16 connected 5461-6825 12288-16383
c71b52f728ab58fedb6e05a525ce00b453fd2f6b 192.168.0.120:6379@16379 myself,master - 0 1617349414000 15 connected 0-5460
7a7392cb66bea30da401d2cb9768a42bbdefc5db 192.168.0.140:6379@16379 master - 0 1617349416000 17 connected 6826-12287
6a627cedaa4576b1580806ae0094be59c32fa391 192.168.0.140:6380@16380 slave c71b52f728ab58fedb6e05a525ce00b453fd2f6b 0 1617349417761 15 connected
至此,node4:6379以及node4:6380成功下线。
主从修改
如果你在线上生产环境中对Redis集群进行缩容,一定要注意主从关系。
手动的对主从关系进行校正,这里不再进行演示。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号