DBA Redis 数据类型
字符串
存储方式
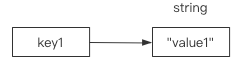
string在内存中按照一个key对应一个value进行存储:
获取操作
以下是常用获取操作:
| 命令 | 描述 |
|---|---|
| GET key | 获取指定 key 的值 |
| MGET key1 [key2..] | 获取所有(一个或多个)给定 key 的值 |
| GETRANGE key start end | 返回 key 中字符串值的子字符 |
| GETSET key value | 将给定 key 的值设为 value ,并返回 key 的旧值(old value) |
| STRLEN key | 返回 key 所储存的字符串值的长度 |
设置操作
以下是常用设置操作:
| 命令 | 描述 |
|---|---|
| SET key value | 设置指定 key 的值 |
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
| MSET key value [key value …] | 同时设置一个或多个 key-value 对 |
| MSETNX key value [key value ...] | 同时设置一个或多个 key-value 对,当且仅当所有给定 key 都不存在 |
内容修改
以下是常用内容修改操作:
| 命令 | 描述 |
|---|---|
| SETRANGE key offset value | 用 value 参数覆写给定 key 所储存的字符串值,从偏移量 offset 开始 |
| APPEND key value | APPEND 命令将指定的 value 追加到 key 原来值(value)的末尾,前提是该key必须存在 |
计数器相关
以下是常用计数器相关操作:
| 命令 | 描述 |
|---|---|
| INCR key | 将 key 中储存的整数值值增1 |
| INCRBY key increment | 将 key 所储存的整数值加上给定的增量值(increment) |
| INCRBYFLOAT key increment | 将 key 所储存的数字值加上给定的浮点增量值(increment) |
| DECR key | 将 key 中储存的整数值减1 |
| DECRBY key decrement | key 所储存的整数值减去给定的减量值(decrement) |
注意:INCR key、INCRBY key increment、DECR key、DECRBY key decrement必须确保修改的数值是整数,浮点数将会失败。
而如果使用INCRBYFLOAT key increment来对浮点数进行自增自减,则不用保证修改的数值必须是整数,浮点数亦可。
计数器减法虽然不支持浮点数,但是可以通过INCRBYFLOAT key increment来指定负数进行减法:
INCRBYFLOAT key -1 # 减1.0
注意!如果对一个超越了Redis中数字串最大值的数字,将不能使用计数器对其进行操作。
最大值为:9223372036854775807
时效性方法
以下是常用时效性操作:
| 命令 | 描述 |
|---|---|
| SETEX key seconds value | 将值 value 关联到 key ,并将 key 的过期时间设为 seconds (以秒为单位) |
| PSETEX key milliseconds value | 同上,单位为毫秒 |
使用场景
1)普通string值的可以做访问量非常大的信息,如微博大V的显示粉丝数、微博数量等。
2)计数器string可以做网站访问量、页面访问量、接口访问量等。
3)时效性string可以做优惠券、做热门活动(到期活动取消)。
哈希
存储方式
内存中一个key对应一个hash空间:
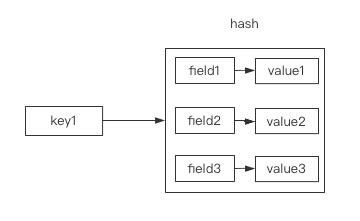
注意!Hash中的value始终是string类型,也只能存string类型
获取操作
以下是常用获取操作:
| 命令 | 描述 |
|---|---|
| HEXISTS key field | 查看哈希表 key 中,指定的字段是否存在 |
| HGET key field | 获取存储在哈希表中指定字段的值 |
| HMGET key field1 [field2…] | 获取所有给定字段的值 |
| HGETALL key | 获取在哈希表中指定 key 的所有字段和值 |
| HLEN key | 获取哈希表中字段的数量 |
| HKEYS key | 获取所有哈希表中的字段 |
| HVALS key | 获取哈希表中所有值 |
设置操作
以下是常用设置操作:
| 命令 | 描述 |
|---|---|
| HSET key field value | 将哈希表 key 中的字段 field 的值设为 value |
| HMSET key field1 value1 [field2 value2 …] | 同时将多个 field-value (域-值)对设置到哈希表 key 中 |
| HSETNX key field value | 只有在字段 field 不存在时,设置哈希表字段的值 |
删除操作
以下是常用删除操作:
| 命令 | 描述 |
|---|---|
| HDEL key field1 [field2...] | 删除一个或多个哈希表字段 |
计数器相关
以下是常用计数器相关操作:
| 命令 | 描述 |
|---|---|
| HINCRBY key field increment | 为哈希表 key 中的指定字段的整数值加上增量 increment |
| HINCRBYFLOAT key field increment | 为哈希表 key 中的指定字段的数字值加上增量 increment |
虽然没有对于Hash的decr方法,不过我们可以进行加负数的操作,达到相同的结果:
HINCRBY k1 f1 -10
迭代获取
HSCAN key cursor [MATCH pattern] [COUNT count]用于增量式迭代获取,对于数据大的数据非常有用,该方法可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆,请使用它代替hgetall:
HSCAN key cursor [MATCH pattern] [COUNT count]
- cursor:游标
- match:匹配指定的field,如果不填则代表所有key
- count:每次取多少
使用场景
1)Hash类型与MongoDB的文档模型非常相似,但没有那么强大。我们可以用Hash类型来模拟出MySQL中的一行数据:
MySQL:
------------------------------
| id | name | age | gender |
------------------------------
| 1 | jack | 18 | male |
------------------------------
Redis:
hset user1 name jack age 18 gender male
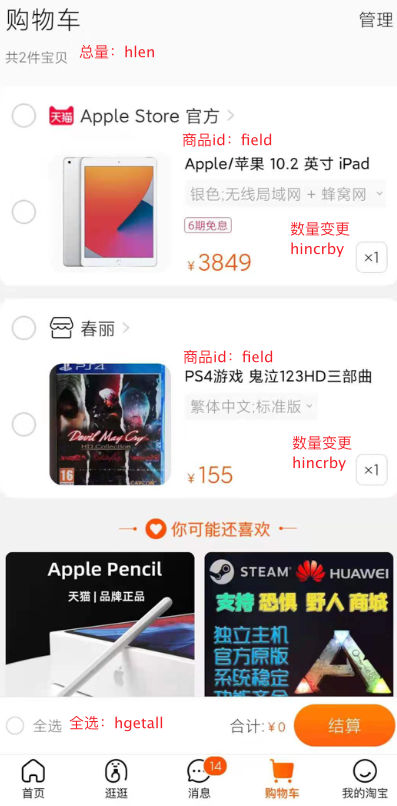
2)整个电商的购物车相关信息,也可以使用Hash进行模拟:
列表
存储方式
内存中按照一个key对应一个list空间:
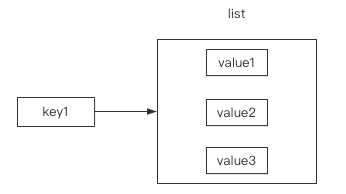
注意!Redis中的列表取值顾头顾尾!
并且Redis列表支持负向索引取值,如-1是最后一个元素
获取操作
以下是常用获取操作:
| 命令 | 描述 |
|---|---|
| LLEN key | 获取列表长度 |
| LINDEX key index | 通过索引获取列表中的元素 |
| LRANGE key start stop | 获取列表指定范围内的元素 |
| LPOP key | 移出并获取列表的第一个元素 |
| RPOP key | 移出并获取列表的最后一个元素 |
设置操作
以下是常用设置操作:
| 命令 | 描述 |
|---|---|
| LPUSH key value1 [value2…] | 将一个或多个值插入到列表头部 |
| LPUSHX key value | 将一个值插入到已存在的列表头部 |
| RPUSH key value1 [value2…] | 将一个或多个值插入到列表尾部 |
| RPUSHX key value | 将一个值插入到已存在的列表尾部 |
| LSET key index value | 通过索引设置列表元素的值 |
| LINSERT key BEFORE|AFTER pivot value | 在列表的元素前或者后插入元素 |
删除操作
以下是常用删除操作:
| 命令 | 描述 |
|---|---|
| LPOP key | 移出并获取列表的第一个元素 |
| RPOP key | 移出并获取列表的最后一个元素 |
| LREM key count value | 根据元素值移除列表元素 |
| LTRIM key start stop | 移除没有在列表start-stop索引之间的元素 |
多列表操作
以下是常用多列表操作:
| 命令 | 描述 |
|---|---|
| RPOPLPUSH source destination | 移除列表的最后一个元素,并将该元素添加到另一个列表头部并返回 |
生产与消费
下面三个方法,可将列表作为生产者消费者模型。
| 命令 | 描述 |
|---|---|
| BLPOP key1 [key2 ] timeout | 弹出列表左侧第一个元素,如果没有元素则阻塞多少秒 |
| BRPOP key1 [key2 ] timeout | 弹出列表右侧第一个元素,如果没有元素则阻塞多少秒 |
| BRPOPLPUSH source destination timeout | 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧,,如果没有元素则阻塞多少秒 |
使用场景
1)微信朋友圈点赞,要求按照点赞顺序显示点赞好友信息,如果取消点赞,移除对应好友信息:
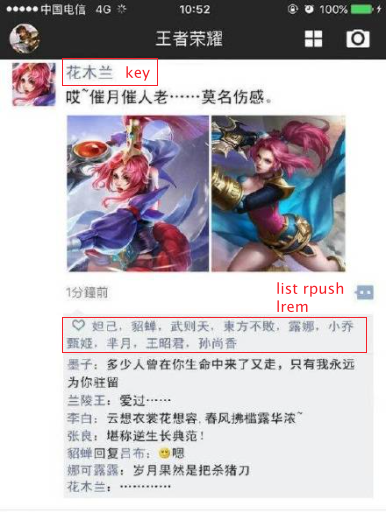
2)twitter、新浪微博、腾讯微博中个人用户的关注列表需要按照用户的关注顺序进行展示,粉丝列表需要将最近关注的粉丝列在前面:
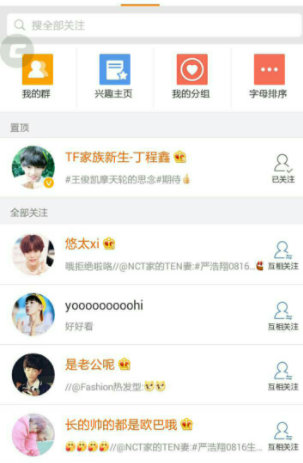
3)新闻、资讯类网站的最新推荐。
4)生产者消费者模型,可用于长轮询的消息队列。
集合
存储方式
在内存中按照一个key对应一个set空间:

与list相比,set中的元素不能重复
获取操作
以下是常用获取操作:
| 命令 | 描述 |
|---|---|
| SISMEMBER key member | 判断 member 元素是否是集合 key 的成员 |
| SCARD key | 获取集合的成员数 |
| SMEMBERS key | 返回集合中的所有成员 |
| SPOP key | 移除并返回集合中的一个随机元素 |
| SRANDMEMBER key [count] | 返回集合中一个或多个随机数元素 |
设置操作
以下是常用设置操作:
| 命令 | 描述 |
|---|---|
| SADD key member1 [member2] | 向集合添加一个或多个成员 |
删除操作
以下是常用删除操作:
| 命令 | 描述 |
|---|---|
| SPOP key | 移除并返回集合中的一个随机元素 |
| SREM key member1 [member2] | 根据元素名移除集合中一个或多个成员 |
多集合操作
以下是常用多集合操作:
| 命令 | 描述 |
|---|---|
| SMOVE source destination member | 将 member 元素从 source 集合移动到 destination 集合 |
交叉并集
图示:

交集相关:
SINTER key1 [key2 ...] # 返回给定所有集合的交集
SINTERSTORE destination key [key ...] # 将返回给定所有集合的交集并存储在 destination 新集合中
差集相关:
SDIFF key1 [key2 ...] # 回给定所有集合的差集
SDIFFSTORE destination key1 [key2 ...] # 返回给定所有集合的差集并存储在 destination 新集合中
并集相关:
SUNION key1 [key2 ...] # 返回所有给定集合的并集
SUNIONSTORE destination key1 [key2 ...] # 将返回给定所有集合的并集并存储在 destination 新集合中
迭代获取
SSCAN key cursor [MATCH pattern] [COUNT count]用于增量式迭代获取,对于数据大的数据非常有用,该方法可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆,请使用它代替SMEMBERS key
SSCAN key cursor [MATCH pattern] [COUNT count]
- cursor:游标
- match:匹配指定的field,如果不填则代表所有key
- count:每次取多少
使用场景
1)社交软件中的共同爱好、共同好友、共同关注等,用于同兴趣推送服务
2)游戏中装备拾取(背包已有、背包没有)
3)记录网站的不同IP访问数
有序集合
存储方式
内存中按照一个key对应一个zset空间:
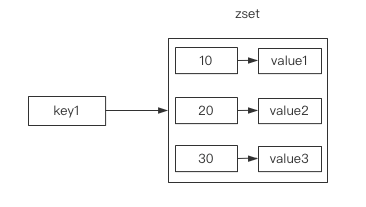
与list相比,zset中的元素不能重复
与set相比,zset中的元素可以用于排序,指定score优先级
获取操作
以下是常用获取操作:
| 命令 | 描述 |
|---|---|
| ZCARD key | 获取有序集合的成员数 |
| ZLEXCOUNT key min max | 获取有序集合中指定字典区间内成员数量 |
| ZCOUNT key min max | 获取有序集合中指定分数区间的成员数量 |
| ZSCORE key member | 返回有序集合中指定成员的分数值 |
| ZRANK key member | 返回有序集合中指定成员的索引值 |
| ZREVRANK key member | 返回有序集合中指定成员的排名,有序集成员按分数值递减(从大到小)排序 |
| ZREVRANGE key start stop [WITHSCORES] | 返回有序集合中指定索引区间内的成员,分数从高到低排序 |
| ZREVRANGEBYSCORE key max min [WITHSCORES] | 返回有序集合中指定分数区间内的成员,分数从高到低排序 |
| ZRANGE key start stop [WITHSCORES] | 通过索引区间返回有序集合指定区间内的成员 |
| ZRANGEBYLEX key min max [LIMIT offset count] | 通过字典区间返回有序集合指定区间内的成员 |
| ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT] | 通过分数区间返回有序集合指定区间内的成员 |
设置操作
以下是常用设置操作:
| 命令 | 描述 |
|---|---|
| ZADD key score1 member1 [score2 member2...] | 向有序集合添加一个或多个成员,或者更新已存在成员的分数 |
| ZUNIONSTORE destination numkeys key [key ...] | 计算给定的一个或多个有序集的并集,并存储在新的 key 中 |
删除操作
以下是常用删除操作:
| 命令 | 描述 |
|---|---|
| ZREM key member [member ...] | 按照元素名移除有序集合中的一个或多个成员 |
| ZREMRANGEBYLEX key min max | 移除有序集合中给定的字典区间的所有成员 |
| ZREMRANGEBYRANK key start stop | 移除有序集合中给定的排名区间的所有成员 |
| ZREMRANGEBYSCORE key min max | 移除有序集合中给定的分数区间的所有成员 |
计数器相关
以下是常用计数器相关操作:
| 命令 | 描述 |
|---|---|
| ZINCRBY key increment member | 有序集合中对指定成员的分数加上增量 increment |
交叉并集
图示:
交集相关:
# 返回给定所有集合的交集
ZINTER numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
# 计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 destination 新集合中
ZINTERSTORE destination numkeys key [key ...]
差集相关:
# 返回给定所有集合的差集
ZDIFF numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
# 计算给定的一个或多个有序集的并集并将结果集存储在新的有序集合 destination 新集合中
ZDIFFSTORE destination numkeys key [key ...]
并集相关:
# 返回给定所有集合的并集
ZUNION numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] [WITHSCORES]
# 计算给定的一个或多个有序集的并集并将结果集存储在新的有序集合 destination 新集合中
ZUNIONSTORE destination numkeys key [key ...]
迭代获取
ZSCAN key cursor [MATCH pattern] [COUNT count]可用于增量式迭代获取,对于数据大的数据非常有用,该方法可以实现分片的获取数据,并非一次性将数据全部获取完,从而防止内存被撑爆
请使用它代替大规模获取元素操作:
ZSCAN key cursor [MATCH pattern] [COUNT count]
- cursor:游标
- match:匹配指定的field,如果不填则代表所有key
- count:每次取多少
使用场景
1)各类排行榜,亲密度,活跃度统计
2)带有权重类的任务,权重高的先进行执行
3)新消息置顶提示

