k8s 基础知识
kubernetes简介
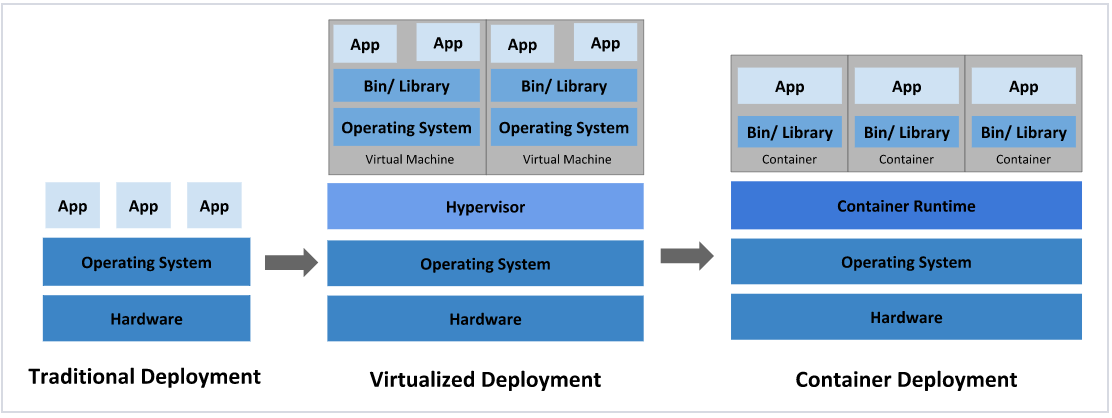
部署演变
在部署应用程序的方式上,主要经历了三个时代:
-
传统部署:互联网早期,会直接将应用程序部署在物理机上
优点:简单,不需要其它技术的参与
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
-
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
优点:程序环境不会相互产生影响,提供了一定程度的安全性
缺点:增加了操作系统,浪费了部分资源
-
容器化部署:与虚拟化类似,但是共享了操作系统
优点:
可以保证每个容器拥有自己的文件系统、CPU、内存、进程空间等
运行应用程序所需要的资源都被容器包装,并和底层基础架构解耦
容器化的应用程序可以跨云服务商、跨Linux操作系统发行版进行部署
容器管理
为了降低虚拟机造成的物理主机资源浪费,提高物理主机的资源利用率,并能够提供像虚拟机一样良好的应用程序隔离运行环境,人们把这种轻量级的虚拟机,称为“容器”。
容器管理工具类似于虚拟机管理工具,主要用于容器的创建、启动、关闭、删除等。
容器管理工具有:
- Docker公司的Docker
- Alibaba的Pouch
- LXC、LXD、RKT等等。
容器化部署方式给带来很多的便利,但是也会出现一些问题,比如说:
- 一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器
- 当并发访问量变大的时候,怎么样做到横向扩展容器数量
这些容器管理的问题统称为容器编排问题,为了解决这些容器编排问题,就产生了一些容器编排的软件:
- Swarm:Docker自己的容器编排工具
- Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
- Kubernetes:Google开源的的容器编排工具
kubernetes
kubernetes,是一个全新的基于容器技术的分布式架构领先方案,是谷歌严格保密十几年的秘密武器----Borg系统的一个开源版本,于2014年9月发布第一个版本,2015年7月发布第一个正式版本,简称k8s。

说起kubernetes,其实也有一段故事。
在Docker公司没有推出Docker容器时,Google公司就已经开始使用容器相关技术,并且也拥有一款属于自己的容器编排工具,随着Docker越来越火热,Docker公司推出了Docker Swarm这款容器编排工具,配合Apache Mesos能达到很好的效果(Mesos主要作用是在分布式计算过程中,对计算机资源进行管理和分配)。
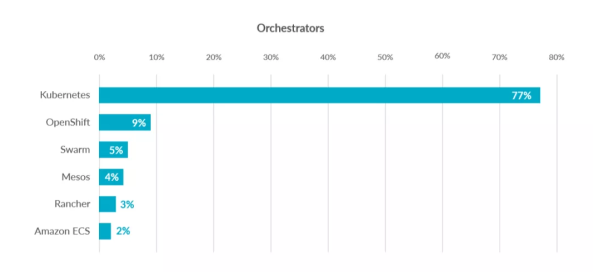
由于Docker Swarm+Apache Mesos抢占了大部分市场,Google公司坐不住了,忽然发现自己内部使用的容器编排工具其实更加优秀和强大,于是利用Go语言对其进行重构,并在2014年进行发布,一经问世Docker Swarm+Apache Mesos的组合就溃不成军,目前整个容器编排工具市场kubernetes占有率稳居第一,高达80%。

需要注意的是,kubernetes能够支持多种容器的编排部署,但默认是Docker容器。
功能介绍
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
- 自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
- 弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
- 服务发现:服务可以通过自动发现的形式找到它所依赖的服务
- 负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
- 版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
- 存储编排:可以根据容器自身的需求自动创建存储卷
kubernetes架构
架构图示
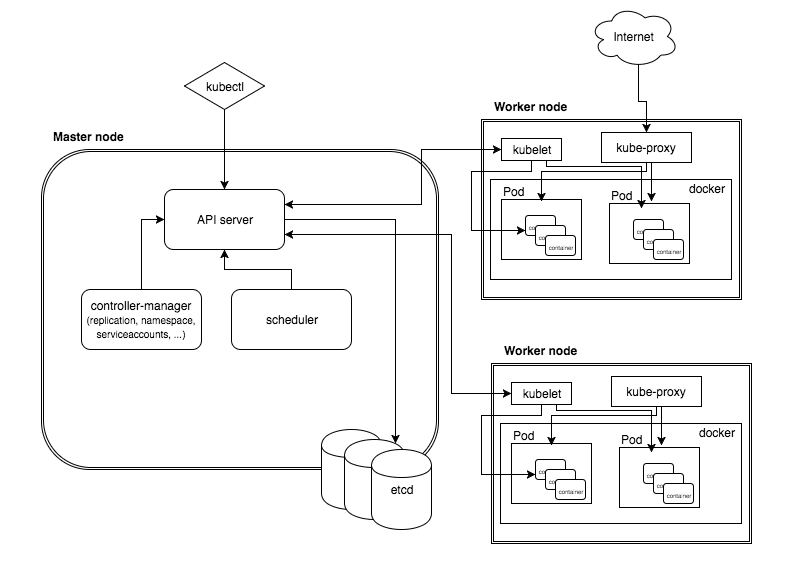
一个kubernetes集群主要是由控制节点(master)、工作节点(node)构成,每个节点上都会安装不同的组件:
Node(节点)数支持:
- 早期版本管理100台现版本
- 可以管理2000台
pod管理支持:
- 早期版本管理1000个
- 现版本管理150000个
Master
Master是集群的控制平面,负责集群的决策 ( 管理 )。
由以下组件构成:
- Api Server:资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制,它是一个RestFul接口,用于接收外部资源请求,是整个集群的统一入口,请求信息交由etcd进行存储
- Scheduler:资源调度器,负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
- ControllerManager:控制管理器,负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等,每个Node节点都会对应一个控制器对其进行管理
- etcd:负责存储集群中各种资源对象的信息,用于保存集群相关数据
Node
Node是集群的数据平面,负责为容器提供运行环境 ( 干活 )。
由以下组件构成:
- Kubelet:由Master指派到Node节点中用于管理本机容器的代表,类似于agent, 负责维护容器的生命周期,即通过控制docker,来创建、更新、销毁容器
- Kube Proxy:对该Node节点提供网络代理,负载均衡等操作
- Docker:负责节点上容器的各种操作
核心概念
Pod:它是整个kubernetes集群中最小的部署/执行单元,可以由1个或者n个容器组成,是一个容器集合,一个Pod中的容器网络是共享的,且一个Pod的生命周期是短暂的,你可以将它当做k8s中的容器,如果你想了解更多,点我跳转。
Volume:数据卷,用于提供Pod的数据存储,声明在Pod容器中可访问的文件目录,可以被挂载到Pod中一个或者多个容器的指定路径下,支持多种后端存储方式,如本地存储,分布式存储,云存储等。
Controller:指示Pod干活的指挥者,可以确保Pod是预期的副本数量,提供无状态应用部署(不用事先规划),确保所有的Node都运行同一个Pod,能够定制一次性任务或者定时任务,以及掌控Pod的销毁。
Service:用于定义一组Pod的访问规则,Pod的负载均衡,提供一个或多个Pod的稳定访问地址,支持多种方式,如ClusterIP、NodePort、LoadBalancer。
Label:告诉Controller应该对那个Pod下达指令,Controller与Pod通过Label建立一对一的关系。
NameSpace:用于隔离不同之间Pod的资源
控制流程
如下图所示:
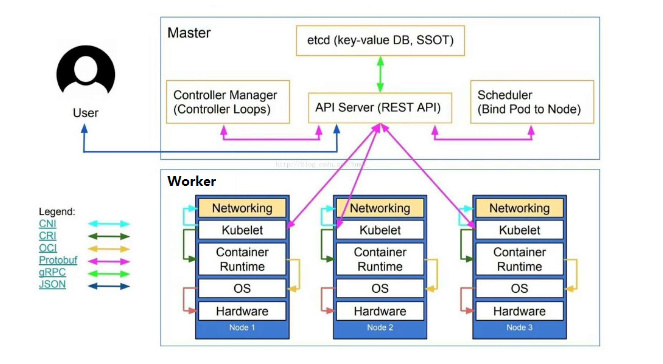
首先要明确,一旦kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中。
Kubelet作为Node节点的核心,接收并处理来自Master中Controller Manager的操作。
- 当有请求到来时,API Server会先交由etcd进行存储,存储完成后API Server将进行下一步操作
- API Server通知Scheduler进行资源调度,调度完成后将调度结果返回给API Server
- API Server通知Controller Manager根据Scheduler指定的调度结果对特定Node节点的Kubelet发出指令
- Kubelet收到指令后,会将指令交由Container Runtime进行执行
Container Runtime是指容器运行环境,是负责运行容器的软件。
如kubernetes支持的容器运行环境非常多:Docker、Containerd、cri-o等任何实现k8s容器运行环境接口的软件均可被k8s作为Container Runtime。
搭建前戏
搭建方式
集群搭建的方式多种多样,如kubeadm搭建、二进制搭建等。
这里将使用kubeadm进行搭建,kubeadm是官方社区推出的一个用于快速部署kubernetes集群的功能,2条命令就能完成集群搭建。
- 搭建Master节点,使用命令kubeadm init
- 加入节点至当前集群,使用命令 $ kubeadm join MasterIp:MasterPort
如果你对二进制搭建感兴趣,可参考文章点我跳转。
相比于kubeadm搭建方式,二进制搭建更显繁琐,由于Api Server是HTTPS方式接收请求,所以需要手动的为API Server生成CA证书与手动部署etcd集群。
而kubeadm直接内部全部都做好了。
集群类型
kubernetes集群大体上分为两类:一主多从和多主多从。
- 一主多从:一台Master节点和多台Node节点,搭建简单,但是有单机故障风险,适合用于测试环境
- 多主多从:多台Master节点和多台Node节点,搭建麻烦,安全性高,适合用于生产环境
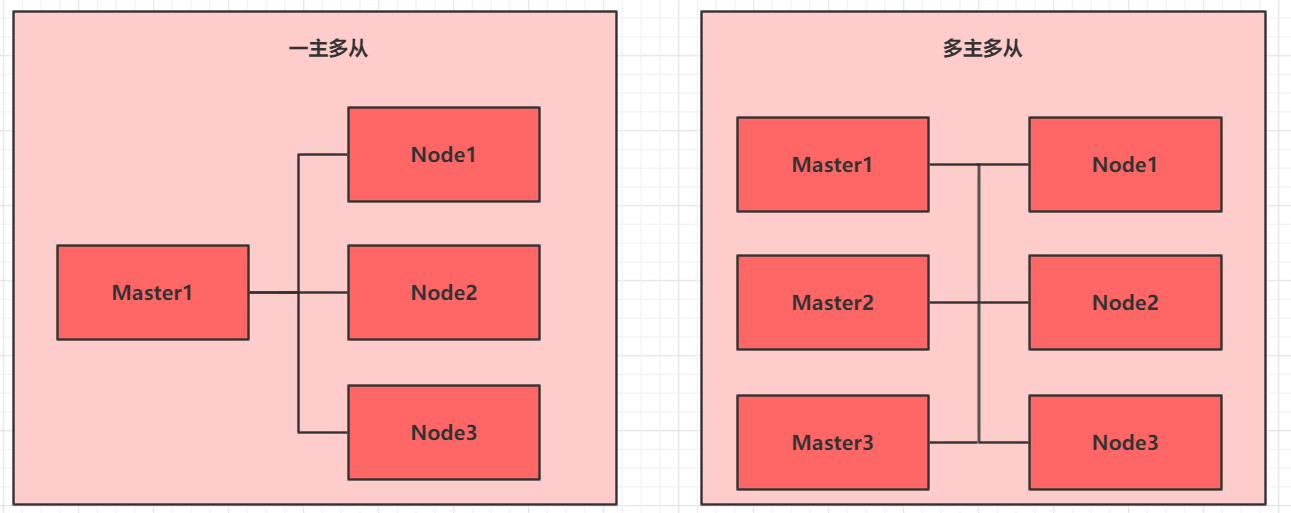
为了测试简单,我们选择1主2从的集群类型。
搭建规划
以下是主机规划:
| 作用 | IP地址 | 操作系统 | 配置 |
|---|---|---|---|
| Master | 192.168.109.101 | Centos7.3 基础设施服务器 | 2颗CPU 2G内存 20G硬盘 |
| Node1 | 192.168.109.102 | Centos7.3 基础设施服务器 | 2颗CPU 2G内存 20G硬盘 |
| Node2 | 192.168.109.103 | Centos7.3 基础设施服务器 | 2颗CPU 2G内存 20G硬盘 |
本次环境搭建需要安装三台Centos服务器(一主二从),然后在每台服务器中分别安装docker(18.06.3),kubeadm(1.17.4)、kubelet(1.17.4)、kubectl(1.17.4)程序。
系统准备
1)所有节点关闭防火墙
为了能够使端口进行暴露,避免不必要的麻烦,还是直接粗暴的关闭防火墙较好,如果是生产环境,则需要酌情考虑
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld
2)所有节点禁用selinux
selinux是linux系统下的一个安全服务,如果不关闭它,在安装集群中会产生各种各样的奇葩问题
[root@master ~]# sed -i 's/enforcing/disabled/' /etc/selinux/config # 永久
[root@master ~]# setenforce 0 # 临时
3)所有节点禁用swap分区
swap分区指的是虚拟内存分区,它的作用是在物理内存使用完之后,将磁盘空间虚拟成内存来使用
启用swap设备会对系统的性能产生非常负面的影响,因此kubernetes要求每个节点都要禁用swap设备
但是如果因为某些原因确实不能关闭swap分区,就需要在集群安装过程中通过明确的参数进行配置说明
[root@master ~]# sed -ri 's/.*swap.*/#&/' /etc/fstab # 永久
[root@master ~]# swapoff -a # 临时
4)更改所有节点的hostname
为了能够使各节点管理更方便,我们需要修改每个节点的hostname
[root@master ~]# hostnamectl set-hostname <hostname>
# master, node1, node2
5)在Master节点添加hosts
利于管理,如果后期Node节点的IP地址发生变化,我们只需要修改/etc/hosts文件即可
[root@master ~]# cat >> /etc/hosts << EOF
192.168.109.101 master
192.168.109.102 node1
192.168.109.103 node2
EOF
6)所有节点修改Linux内核参数,添加网桥过滤和地址转发
[root@master ~]# cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
# 重载配置
[root@master ~]# sysctl -p
# 加载网桥过滤模块(可选)
[root@master ~]# modprobe br_netfilter
# 查看网桥过滤模块是否加载成功(可选)
[root@master ~]# lsmod | grep br_netfilter
# 生效
[root@master ~]# sysctl --system
7)所有节点配置ipvs功能(可选)
在kubernetes中service有两种代理模型,一种是基于iptables的,一种是基于ipvs的
两者比较的话,ipvs的性能明显要高一些,但是如果要使用它,需要手动载入ipvs模块
# 1 安装ipset和ipvsadm
[root@master ~]# yum install ipset ipvsadmin -y
# 2 添加需要加载的模块写入脚本文件
[root@master ~]# cat <<EOF > /etc/sysconfig/modules/ipvs.modules
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
# 3 脚本文件添加执行权限
[root@master ~]# chmod +x /etc/sysconfig/modules/ipvs.modules
# 4 执行脚本文件
[root@master ~]# /bin/bash /etc/sysconfig/modules/ipvs.modules
# 5 查看对应的模块是否加载成功
[root@master ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
8)所有节点的时间同步
kubernetes要求集群中的节点时间必须精确一致,企业中建议配置内部的时间同步服务器,以下提供2种方案
# 方案1
# 下载ntpdate软件
[root@master ~]# yum install ntpdate -y
# 启动时间更新
[root@master ~]# ntpdate time.windows.com
# 方案2
# 启动chronyd服务
[root@master ~]# systemctl start chronyd
# 设置chronyd服务开机自启
[root@master ~]# systemctl enable chronyd
# chronyd服务启动稍等几秒钟,就可以使用date命令验证时间了
[root@master ~]# date
kubeadm搭建
所有节点
1)安装Docker,这里指定为18.06.3的版本:
[root@master ~]# cd ~
# 切源
[root@master ~]# wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo
# 下载
[root@master ~]# yum -y install docker-ce-18.06.3.ce-3.el7
# 启动服务
[root@master ~]# systemctl enable docker && systemctl start docker
# 检查是否安装成功
[root@master ~]# docker --version
2)配置Docker registery为国内源:
[root@master ~]# cat > /etc/docker/daemon.json << EOF
{
"registry-mirrors": ["https://b9pmyelo.mirror.aliyuncs.com"]
}
EOF
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl restart docker
3)配置kubernetes镜像仓库为国内源:
[root@master ~]# cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
4)安装kubeadm和kubelete以及kubectl,由于与Docker之间的兼容性问题,故我们统一指定版本号为1.17.4:
[root@master ~]# yum install -y kubelet-1.17.4-0 kubeadm-1.17.4-0 kubectl-1.17.4-0
[root@master ~]# systemctl enable kubelet
kubernetes Master
Master节点上执行以下操作,先初始化kubernetes集群:
[root@master ~]# kubeadm init --apiserver-advertise-address=192.168.109.101 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.17.4 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16
# --apiserver-advertise-address: apiserver的地址,就是Master地址
# --image-repository: 仓库地址,配置为阿里云,国内
# --kubernetes-version: k8s版本
# --service-cidr: 和当前ip不冲突即可,指明 pod 网络可以使用的 IP 地址段。
# --pod-network-cidr: 和当前ip不冲突即可,指定节点的名称
在完成后,它会提示以下信息:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
# 这个是Master节点执行的
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
# 这个是node节点上执行的
kubeadm join 192.168.109.101:6443 --token mp0064.6tld9ohg7265co6r \
--discovery-token-ca-cert-hash sha256:c018e1720ae37ee0eec5d4ac0c2e8d4f8622e006401f2077575b164f1d6b41b3
拿出第一条命令,在Master节点上执行:
[root@master ~]# mkdir -p $HOME/.kube
[root@master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@master ~]# chown $(id -u):$(id -g) $HOME/.kube/config
现在kubernetes集群中已经存在一个Master节点信息了:
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 5m56s v1.17.4
kubernetes Node
在2个Node节点中,输入上面提示命令中的第二条,该命令的作用是将Node节点也加入kubernetes集群中:
[root@node1 ~]# kubeadm join 192.168.109.101:6443 --token mp0064.6tld9ohg7265co6r --discovery-token-ca-cert-hash sha256:c018e1720ae37ee0eec5d4ac0c2e8d4f8622e006401f2077575b164f1d6b41b3
输入完成后,回到Master节点执行以下命令查看集群节点信息,Node节点也被成功加入:
[root@master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
master NotReady master 6m43s v1.17.4
node1 NotReady <none> 22s v1.17.4
node2 NotReady <none> 19s v1.17.4
网络插件
观察集群节点信息,可以发现各个节点的STATUS是NotReady,这是因为我们还需要在Master上配置一款网络插件才能让状态各个节点状态变为Ready。
kubernetes支持多种网络插件,比如flannel、calico、canal等等,任选一种使用即可,本次选择flannel:
[root@master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
如果发生链接错误,这是因为flannel文件是一个国外地址,多尝试几次即可。
如果一直失败,则可以在浏览器中打开该文件复制内容并进行粘贴:
如果你的VIM未进入paste模式,则可能导致粘贴结果缩进有误
# 1.浏览器访问
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
# 2.复制内容并进行粘贴
[root@master ~]# vim ~/kube-flannel.yml
# 3.输入内容并保存退出
# 4.进行应用
[root@master ~]# kubectl apply -f ~/kube-flannel.yml
apply完成之后,再次查看集群节点信息,各个节点的STAUTS都从NotReady变成了Ready:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
master Ready master 15m v1.17.4
node1 Ready <none> 8m53s v1.17.4
node2 Ready <none> 8m50s v1.17.4
此时我们需要执行以下命令,等待Pod的STATUS都变为Running时,即可部署应用:
[root@master ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-7ff77c879f-b2kmb 1/1 Running 0 3h46m
coredns-7ff77c879f-skcfh 1/1 Running 0 3h46m
etcd-master 1/1 Running 0 3h47m
kube-apiserver-master 1/1 Running 0 3h47m
kube-controller-manager-master 1/1 Running 0 3h47m
kube-flannel-ds-488xf 1/1 Running 0 21m
kube-flannel-ds-dfj55 1/1 Running 0 21m
kube-flannel-ds-s5hz6 1/1 Running 0 21m
kube-proxy-8vxgm 1/1 Running 0 3h46m
kube-proxy-b92nh 1/1 Running 0 3h39m
kube-proxy-xw256 1/1 Running 0 3h39m
kube-scheduler-master 1/1 Running 0 3h47m
集群测试
接下来在kubernetes集群中部署一个nginx程序,测试下集群是否在正常工作。
# 部署nginx
[root@master ~]# kubectl create deployment nginx --image=nginx:1.14-alpine
# 暴露端口
[root@master ~]# kubectl expose deployment nginx --port=80 --type=NodePort
# 查看服务状态
[root@master ~]# kubectl get pods,service
NAME READY STATUS RESTARTS AGE
pod/nginx-86c57db685-fdc2k 1/1 Running 0 18m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 82m
service/nginx NodePort 10.104.121.45 <none> 80:30073/TCP 17m
# 4 最后在电脑上访问下部署的nginx服务
局域网内其他机器访问以下任意地址,即可看到Nginx页面:
http://192.168.109.101:30073/
http://192.168.109.102:30073/
http://192.168.109.103:30073/
