DBA MySQL MyCat中间件
MyCat简介
MyCat是目前最流行的基于Java语言编写的数据库中间件,是一个实现了MySQL协议的服务器,前端用户可以将它看做是一个数据库代理,用MySQL客户端工具和命令对其进行访问,其核心功能是分库分表,配合数据库的主从模式还可以实现读写分离。
它的后端不仅仅可以支持MySQL,还可以支持SQL Server、Oracle、DB2、PostgreSQL等主流数据库,并且还支持MongoDB这种新型的NoSQL存储方式。
在学习MyCat之前,我们先要了解一下为何要使用它,那么就得从下一小节的架构演变开始说起。
架构演变
单机时代
最早的时候,单机单服务,若服务器发生故障,则业务也会受到影响:
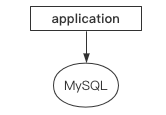
主从单活
有没有什么好的办法能够解决这种状况呢?主从复制诞生。
主从复制解决了单机提供服务的问题,从库数据和主库一模一样,主库宕机后从库顶上,但是每次主库发生故障后都需要手动进行切换,十分繁琐。
于是MHA诞生了,它可以检测主库宕机后让从库自动顶上,而且可以监听多组主从,十分的方便(缺点就是一次性服务):
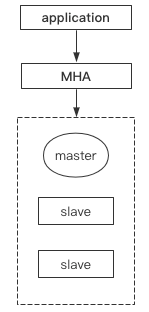
读写分离
看起来上面的方案已经十分完美了,但是三台服务器中只有一台提供对外服务,读写都在主库上,让硬件资源造成了极大的浪费,真正意义上的主库有难从库围观。
有没有什么方案能让主库只负责写,剩下的两个从库来处理读操作呢?
随之而来MySQL官方提供了一种读写分离的中间件,名为MysqlProxy,但是由于各方面原因使用的人较少,在前面的文章中我们介绍了一种更好的替代产品,第三方读写分离中间件Atlas。
现在,我们已经能成功解决硬件资源利用率低的问题:
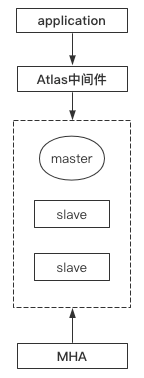
分片集群
互联网的发展总是迅猛的,数据量级的提升是飞速的,如果仅用上面的架构来存储超大量级的数据,假如有6亿条数据,即使在有索引的情况下查询也会十分缓慢,因为主库和从库的数据都一致,不管从哪个节点上进行读取,速度都会非常慢。
有没有什么好的方案进行解决呢?有,我们可以将6亿数据拆成3份,再配以多个MHA架构节点进行分片处理,如下图所示,mycat中间件能够提供读写分离机制+数据分片策略,下图应该算是一个比较不错的解决方案:
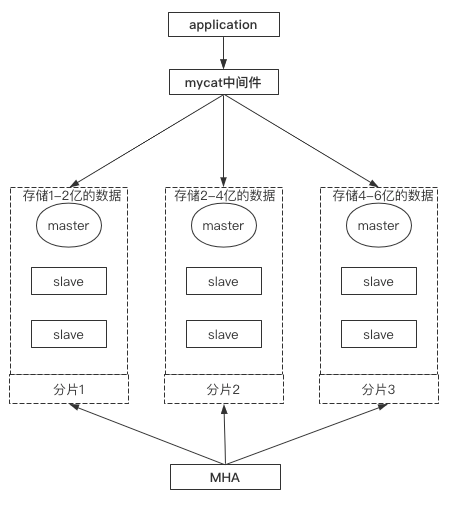
如果分片1上的master挂掉之后,则分片1的slave将在MHA控制下自动顶替上,其他的分片组同理。
同时,如果用户发起的是读取操作,mycat中间件会根据分片策略在不同节点上从库中进行读取,如果是写入操作,则会根据分片策略在不同节点上的主库中进行写入。
MyCat切片
垂直拆分
将一个原本存储于单库上的数据存储在多库中。
如图所示:
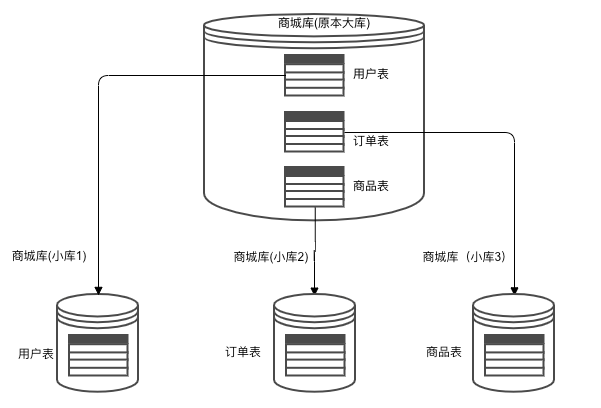
原本应用对三个表的所有请求都只在一个库中完成,该库压力比较大。
通过垂直拆分,将这三个表拆成三个独立的库中存放,那么应用对不同表的操作其实就会分发到单独的库中进行处理。
但是无法解决单表数据量太大的问题。
水平拆分
将单表的数据拆分到多表中,如下图所示:
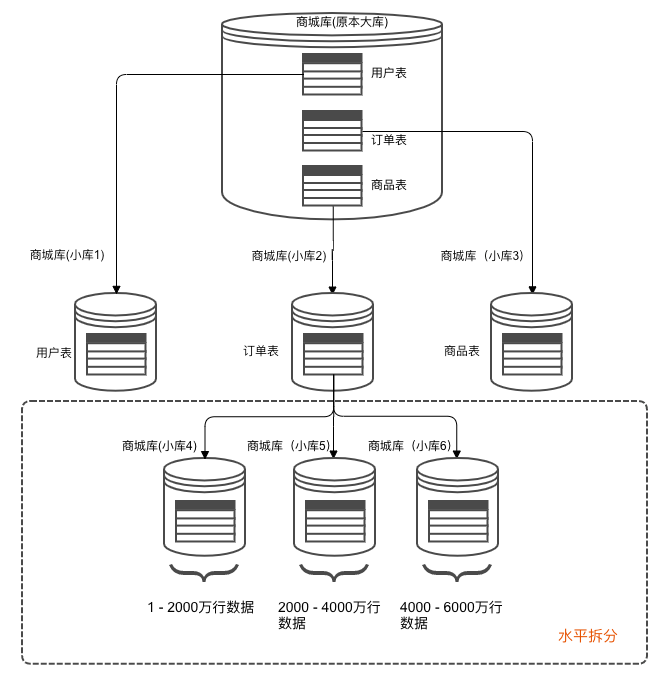
这样做的好处会提升单表的并发能力,且能提升磁盘I/O性能。
缺点是无法提供表连接查询。
MyCat概念
逻辑库
MyCat中定义的库,物理中并不存在,仅针对纵向切片提供的概念:
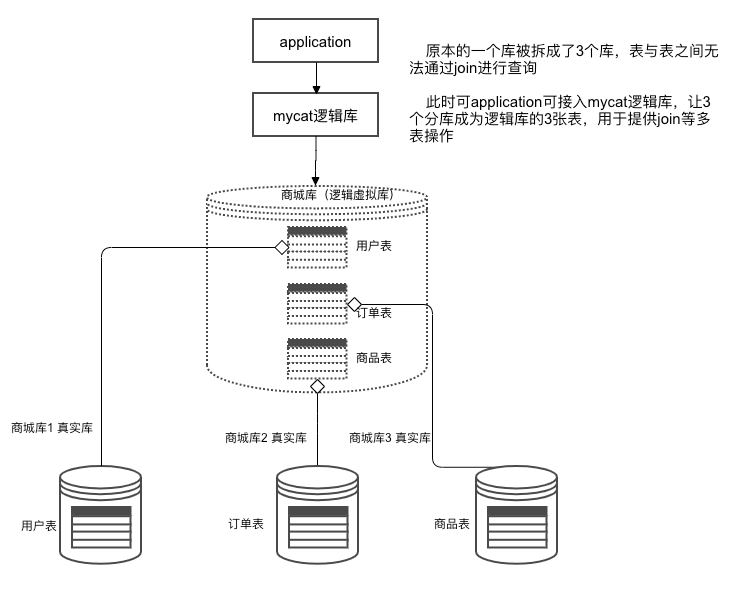
逻辑表
MyCat中定义的表,物理中并不存在,仅针对横向分片提供的概念:
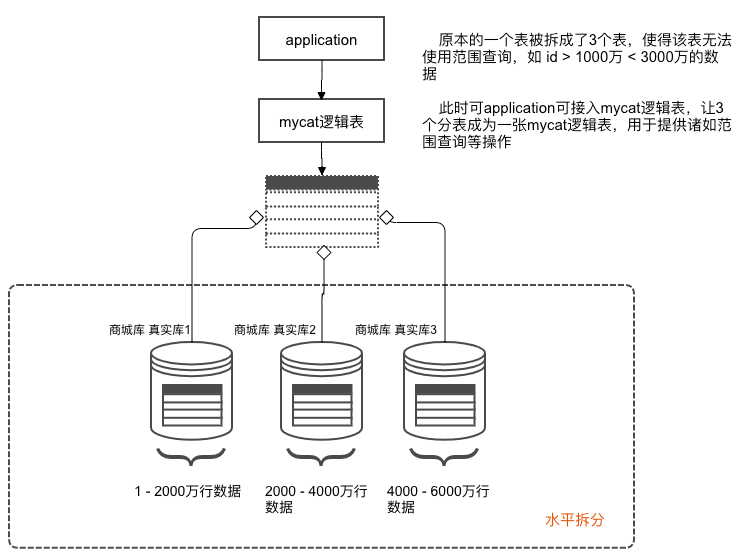
主从搭建
规划配置
由于MHA服务需要多台虚拟机,所以这里演示不搭建上面的MHA架构,仅用最简单的1主1从配合mycat来进行读写分离和分库分表的应用。
地址规划如下:
Master : 192.168.1.120
Slave : 192.168.1.121
mysql安装
首先要在两台机器上安装mysql,先下载:
T > cd ~
T > wget https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.28-linux-glibc2.12-x86_64.tar.gz
下载完成后,进行解压操作:
T > tar -zxvf mysql-5.7.28-linux-glibc2.12-x86_64.tar.gz -C /usr/local
解压完成后重命名:
T > mv /usr/local/mysql-5.7.28-linux-glibc2.12-x86_64 /usr/local/mysql
进入/usr/local文件夹,创建数据文件目录和日志文件目录:
T > cd /usr/local/
T > mkdir -p logs
T > mkdir -p data
创建mysql用户和用户组:
T > groupadd mysql
T > useradd mysql -g mysql
修改权限:
T > chown -R mysql:mysql ./mysql
T > chown -R mysql:mysql ./data
T > chown -R mysql:mysql ./logs
设置配置文件
T > vim /etc/my.cnf
[mysqld]
user=mysql
server_id=2 # 主库改1,从库改2
port=3306
basedir=/usr/local/mysql
datadir=/usr/local/data
log_error=/usr/local/logs/mysqld.log
log_bin=/usr/local/logs/mysql_bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
slow_query_log=1
long_query_time=10
slow_query_log_file=/usr/local/logs/slow.log
log_queries_not_using_indexes
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
default-storage-engine=INNODB
socket=/tmp/mysql.sock
设置sys服务:
cat >/etc/systemd/system/mysqld.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
EOF
设置环境变量:
T > vim /etc/profile
export PATH=/usr/local/mysql/bin:$PATH
T > source /etc/profile
进行免密初始化:
T > mysqld --initialize-insecure
开启mysqld.service服务:
T > systemctl start mysqld.service
这一步骤仅在主库上执行,创建复制用户:
T > mysql -uroot -p -S /tmp/mysql.sock -e "GRANT REPLICATION SLAVE ON *.* TO repl@'192.168.1.%' IDENTIFIED BY '123'"
接下来的步骤是从库执行的,先登录mysql:
T > mysql -uroot -p -S /tmp/mysql.sock
然后是开启复制:
M > CHANGE MASTER TO MASTER_HOST='192.168.1.120',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10,
MASTER_AUTO_POSITION=1;
检查复制状态:
M > START SLAVE;
至此,普通的主从搭建完成了。
安装MyCat
java环境
由于我们只有一主一从,因此我打算在从库节点上安装MyCat。
需要在从库节点上先安装java环境:
T > yum install java -y
MyCat
趁着安装java环境的时间,我们看一看去哪里下载MyCat。
刚好,我准备下载1.6.7.6版本,也是目前比较新的一版,链接地址如下,通过wget直接下载就好。
T > cd ~
T > wget http://dl.mycat.org.cn/1.6.7.6/20201104174609/Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz
下载完成后,对其进行解压操作:
T > tar -zxvf Mycat-server-1.6.7.6-test-20201104174609-linux.tar.gz -C /usr/local/
解压完成后,可以查看该目录下具有一个mycat文件夹了:
T > cd /usr/local
T > ll | grep mycat
drwxr-xr-x 7 root root 85 3月 18 21:02 mycat
查看目录结构:
T > ls ./mycat
bin catlet conf lib logs version.txt
目录介绍:
- bin :启动脚本
- conf :配置文件
- catlet :扩展功能
- lib :MyCat及其依赖jar
- logs :wrapper.log保存启动日志,mycat.log保存mycat的工作日志
server.xml
打开文件
server.xml主要用于定义了application链接MyCat中间件的用户,以及该链接用户对逻辑库表的权限方面配置。
使用vim编辑器,打开该文件,观察文件结构:
T > vim /usr/local/mycat/conf/server.xml
文件节选内容如下,略有改动:
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="ignoreUnknownCommand">0</property><!-- 0遇上没有实现的报文(Unknown command:),就会报错、1为忽略该报文,返回ok报文。 -->
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
</mycat:server>
配置解读
其实该文件的配置项非常多,但是我们仅需关注上面的即可。
主要看这里:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">TESTDB</property>
<property name="defaultSchema">TESTDB</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<user name="user">
<property name="password">user</property>
<property name="schemas">TESTDB</property>
<property name="readOnly">true</property>
<property name="defaultSchema">TESTDB</property>
</user>
它定义了2个用户用于让application进行链接,并且密码也有所不同:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<user name="user">
<property name="password">user</property>
这两个用户默认链接的虚拟库都是TESTDB:
<property name="defaultSchema">TESTDB</property>
这两个用户拥有对该虚拟库不同的权限,其中user用户是只能读,而root用户没有进行定义,则是可读可写:
<user name="user">
<property name="readOnly">true</property>
接下来我们看一看root用户的DDL设置,注意它是注释了的:
# 权限为4位数,顺序如下:
# insert、update、select、delete
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
# TESTDB逻辑库权限:0110 则对该库不能插入,不能删除
<schema name="TESTDB" dml="0110" >
# 对tb01(这是个逻辑库,但真正的默认配置文件schema.xml中没有配置)
# 不能增删改查
<table name="tb01" dml="0000"></table>
# 对tb02则可以允许全部操作
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
schema.xml
打开文件
schema.xml主要定义MyCat中逻辑库与逻辑表对应的MySQL中物理库表的配置。
除此之外,还有读写分离以及分片规则等配置。
使用vim编辑器,打开该文件,观察文件结构:
T > vim /usr/local/mycat/conf/schema.xml
文件节选内容如下,略有改动:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="customer" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="jdbc:mysql://localhost:3306" user="root"
password="root">
<readHost host="hostS1" url="jdbc:mysql://192.168.1.121:3306" user="root"
password="root">
</readHost>
</writeHost>
</dataHost>
</mycat:schema>
逻辑库表相关
下面这4个标签,是比较基础的4个配置标签:
| 标签 | 描述 |
|---|---|
| schema | 配置逻辑库,name与server.xml中schema对应 |
| table | 配置逻辑表 |
| dataNode | 配置逻辑表中有哪些物理库 |
| dataHost | 配置物理库的读写分离策略 |
schema标签
该标签为配置逻辑库的标签:
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
...
</schema>
主要属性如下:
-
name :逻辑库名称,与server.xml中schema对应
-
checkSQLschema :是否检测SQL语法中的schema信息,假如MyCat逻辑库名称为A,dataNode(分库的表)名称为B,如果该参数为false,则SQL查询语句为SELECT * FROM A.table;, 如果该参数为true,则查询语句为SELECT * FROM table;
-
sqlMaxLimit:如果MyCat在执行SQL查询时,没有指定limit子句,则自动添加并且值为100
table标签
table标签位于schema标签中,用于定义逻辑表:
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="customer" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
主要属性如下:
- name :逻辑表名称
- dataNode :物理数据库中的数据库名称,即指定当application请求读取虚拟表时,通过哪些物理库来找这张真实表
- rule :分片规则,具体规则请参照rule.xml文件
dataNode标签
dataNode标签与table标签中的dataNode属性做对应,它的作用是指定一个真实的物理库,将多个物理库加入到逻辑库中,当application请求读取虚拟表时,通过哪些物理库来找这张真实表:
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="customer" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
<!-- 当application请求customer表是,可以通过db1库里找这张表,也可以通过db2库找这张表 -->
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
主要属性如下:
- name :节点名称,是一个可以随意命名的逻辑名称,主要与schema标签或者table标签dataNode属性做对接
- dataHost :与dataHost标签的name做对接,用于引用该库在复制集群中的配置信息等,如读写分离配置
- database :指定指定逻辑表对应的真实表在哪个物理库下进行存放
dataHost标签
dataHost标签是与dataNode做对接,主要负责dataNode标签中物理库读写分离的相关事宜:
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" randomDataNode="dn1">
<table name="customer" primaryKey="id" dataNode="dn1,dn2" rule="sharding-by-intfile" autoIncrement="true" fetchStoreNodeByJdbc="true">
</table>
</schema>
<dataNode name="dn1" dataHost="localhost1" database="db1" />
<dataNode name="dn2" dataHost="localhost1" database="db2" />
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
....
</dataHost>
主要属性如下:
- name : 主要与dataNode标签的dataHost参数做对接,用于提供复制集读写策略等配置给dataNode标签的物理数据库
- maxCon/minCon:最大链接数与最小链接数
- writeType :0,所有写操作都发送到可用的writeHost上。1,所有写操作都随机的发送到readHost。2,所有写操作都随机的在writeHost、readHost上发。
- dbType :数据库类型,mysql数据库
- dbDriver :数据库驱动类型,native是MyCat自带的一种用于驱动MySQL的驱动程序
- banlance :0,读操作都在写库中。1,当有多主多从的时候,主之间互为主从,mater1->slave1 master2->slave2 master1和master2互为主备,select会在slave1 master2 slave2随机调用。2,所有读操作将会在所有数据库中随机执行。3, 所有读操作将会在所有读数据库中执行
- switchType :-1,表示不自动切换。1,表示自动切换,推荐使用。2,基于mysql主从同步状态切换
heartbeat标签
heartbeat标签位于dataHost标签中,用于MyCat对MySQL服务的心跳检测。
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
...
</dataHost>
writeHost标签
writeHost标签位于dataHost标签中,用于定义物理库在复制集群中写时的操作:
<dataHost name="localhost1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="jdbc" switchType="1" slaveThreshold="100">
<writeHost host="hostM1" url="jdbc:mysql://localhost:3306" user="root"
password="root">
....
</writeHost>
</dataHost>
主要属性如下:
- host :数据库命名
- url : 数据库访问路径
- user : 数据库访问用户名
- password : 访问用户的密码
readHost标签
readHost标签位于writeHost标签中,用于定义物理库在复制集群中读时的操作:
<writeHost host="hostM1" url="jdbc:mysql://localhost:3306" user="root"
password="root">
<readHost host="hostS1" url="jdbc:mysql://192.168.1.121:3306" user="root"
password="root">
</readHost>
</writeHost>
主要属性如下:
- host :数据库命名
- url : 数据库访问路径
- user : 数据库访问用户名
- password : 访问用户的密码
配置图示
大量的文字描述是否感觉很心累?这里有一张图供你查看:

rule.xml
打开文件
rule.xml主要定义了分片规则。
使用vim编辑器,打开该文件,观察文件结构:
T > vim /usr/local/mycat/conf/rule.xml
文件节选内容如下,略有改动:
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
...
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
...
</mycat:rule>
tableRule标签
该标签定义分片规则以及分片列,如下所示:
<tableRule name="rule1">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
name表示分片规则,内嵌rule表示详细规则
columns表示拆分列,algorithm表示分片函数
function标签
该标签定义了分片函数,如下所示:
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
name为函数本身,class为指定的分片算法具体类名
property表示该分片算法会用到的一些属性
MyCat前戏
用户创建
我们需要在复制集上创建一个用户,让MyCat通过该用户链接MySQL。
只需要在主库上做以下操作即可,用户名为root,密码也为root:
T > mysql -uroot -S /tmp/mysql.sock -e "GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' identified by 'root';"
从库由于已经搭建好了复制集,也会自动的复制该用户。
库表创建
我们创建一个名为db1的数据库,并且插入3条数据在里面,接下来在主库中操作:
T > mysql -uroot
M > CREATE DATABASE db1 CHARSET utf8mb4;
M > use db1;
M > CREATE TABLE t1(id INT PRIMARY KEY AUTO_INCREMENT COMMENT "主键",name CHAR(32) NOT NULL COMMENT "姓名");
M > INSERT INTO t1(name) VALUES("Jack"),("Ken"),("Tom");
管理命令
以下是MyCat的基础管理命令。
启动MyCat:
/usr/local/mycat/bin/mycat start
停止命令:
/usr/local/mycat/bin/mycat stop
重启命令:
/usr/local/mycat/bin/mycat restart
查看状态:
/usr/local/mycat/bin/mycat status
如何排错
MyCat的错误大多集中在启动时。
如发现服务启动不成功,则可以查看wrapper.log这个启动日志。
里面关键的错误信息都是使用中文编写,十分的方便。
读写分离
schema.xml配置
配置文件如下:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100" dataNode="dn1">
</schema>
<dataNode name="dn1" dataHost="mycatLocal1" database= "db1" />
<dataHost name="mycatLocal1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.1.120:3306" user="root" password="root">
<readHost host="hostS1" url="192.168.1.121:3306" user="root" password="root" />
</writeHost>
</dataHost>
</mycat:schema>
-
balance=”0”, 不开启读写分离机制,所有读操作都发送到当前可用的writeHost上
-
balance=”1”,全部的readHost与stand by writeHost参与select语句的负载均衡
-
balance=”2”,所有读操作都随机的在writeHost、readhost上分发
-
balance=”3”, 所有读请求随机的分发到writeHost对应的readhost执行,writerHost 不负担读压力
功能测试
接下来启动MyCat:
/usr/local/mycat/bin/mycat start
<property name="serverPort">8066</property> <property name="managerPort">9066</property>
登录主库中,查看MyCat是否链接主库:
M > show processlist;
+----+------+---------------------+------+------------------+-------+---------
| Id | User | Host | db | Command | Time | State | Info |
+----+------+---------------------+------+------------------+-------+---------
| 5 | repl | 192.168.1.121:47766 | NULL | Binlog Dump GTID | 15897 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 20 | root | 192.168.1.106:53245 | db1 | Sleep | 2347 | | NULL |
| 21 | root | localhost | NULL | Query | 0 | starting | show processlist |
使用Navicat链接MyCat中间件:
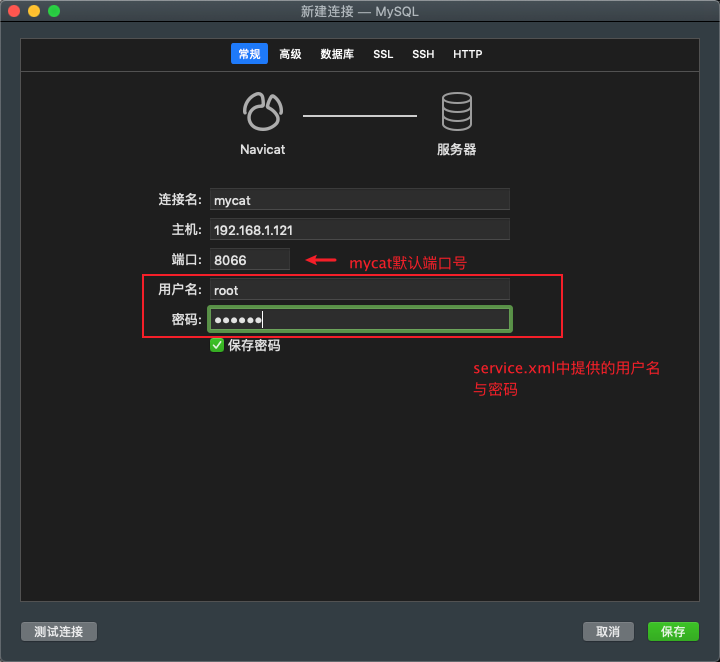
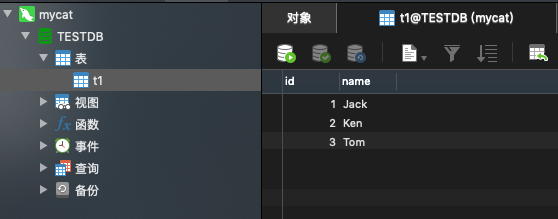
现在,我们对于物理库db1(逻辑库TESTDB)做了一个读写分离。
创建一个t2表,然后插入2条数据:
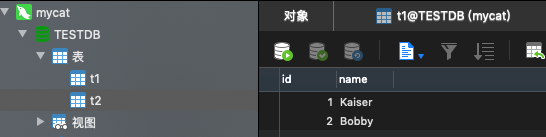
查看MyCat的mycat.log日志(太乱了,该兴趣的自己看吧)。
注意事项
在这个schema.xml的配置文件中,并没有配置虚拟表,而是直接指定了一个虚拟库,使用dataNode参数对其做了物理库的指定。
如果你用table虚拟表来指定dataNode的话,是无效的,这会导致MyCat打不开其中的任何表。
如我对配置文件中进行了下面的修改:
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<table name="mycatTable001" dataNode="dn1"></table>
</schema>
在我测试时,发现打不开表,所以这是一个坑点吧:
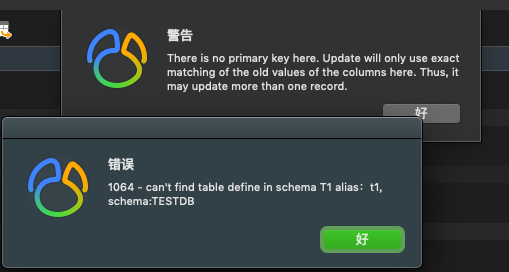
另外,使用MyCat搭建读写分离,仅能针对某个数量的库进行读写分离(取决于虚拟库的dataNode参数),而不能针对全库。
相较于Atlas的全库读写分离,这一点希望能有所改进。
分库分表
垂直分库
因为节点的原因,所以我们这里不再进行试验而是进行演示操作。
假如我们本来有一个商城bazaar库,在里面存了orders、users、goods这3张表。
此时想对bazaar库中的3张表进行拆分,要怎么做呢?
如下图所示:

完美方案是MHA集群架构,总共需要9台服务器(如果不做MHA则3台足以),在各个MHA集群上的Master中添加bazaar库,并且在其中添加3张表:
server1 -> bazaar
server2 -> bazaar
server3 -> bazaar
server1 -> bazaar -> users
server2 -> bazaar -> orders
server3 -> bazaar -> goods
然后需要到schema.xml中进行配置:
<schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- 如果用户读写虚拟库TESTDB中的3个表中的任意一个 -->
<table name="users" dataNode="sh1" />
<table name="orders" dataNode="sh2" />
<table name="goods" dataNode="sh3" />
</schema>
<!-- 都会走以下的策略,如读取users表会在repSet1的bazaar库中查找 -->
<dataNode name="sh1" dataHost="repSet1" database="bazaar" />
<dataNode name="sh2" dataHost="repSet2" database="bazaar" />
<dataNode name="sh3" dataHost="repSet3" database="bazaar" />
<!-- users的读写配置 -->
<dataHost name="repSet1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.110:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.111:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- orders的读写配置 -->
<dataHost name="repSet2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.120:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.121:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- goods的读写配置 -->
<dataHost name="repSet3" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.130:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.131:3306" user="root" password="root" />
</writeHost>
</dataHost>
</schema>
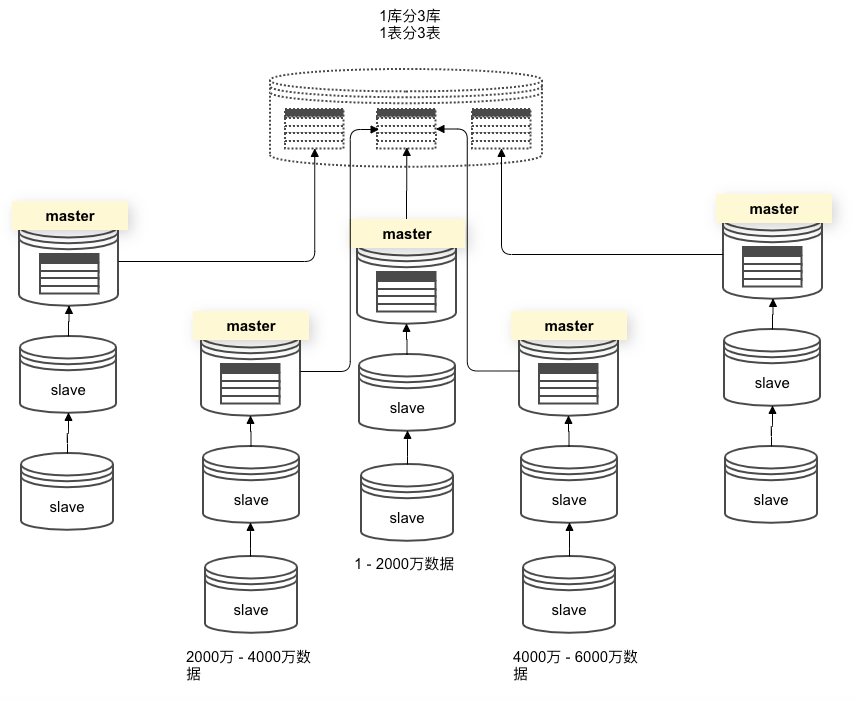
水平分表
我们继续对orders做一个水平分表。
同样的,如果该表中有6000万数据,我们需要将表分成3分,又要用到3个MHA集群。
在所有MHA集群主库上同样创建3个bazaar库:
server2 -> bazaar # 如果按照上面的策略继续往下做,就不用创建这个库了
server2_1 -> bazaar
server2_2 -> bazaar
并且在3个节点的bazaar库中,创建3个orders表:
server2 -> bazaar -> users # 如果按照上面的策略继续往下做,就不用创建这个库了
server2_1 -> bazaar -> orders
server2_2 -> bazaar -> goods
如下图所示:
然后需要到schema.xml中进行配置:
<schema xmlns:mycat="http://io.mycat/">
<schema name="TESTDB" checkSQLschema="true" sqlMaxLimit="100">
<!-- 如果用户读写虚拟库TESTDB中的3个表中的任意一个 -->
<table name="users" dataNode="sh1" />
<!-- orders指定分片策略,按照id进行分片 -->
<table name="orders" dataNode="sh2,sh4,sh5" rule="auto-sharding-long" />
<table name="goods" dataNode="sh3" />
</schema>
<!-- 都会走以下的策略,如要访问orders表,则由repSet2,4,5的bazaar中的3个orders表组成逻辑表 -->
<dataNode name="sh1" dataHost="repSet1" database="bazaar" />
<dataNode name="sh3" dataHost="repSet3" database="bazaar" />
<!-- orders水平拆分的集群与物理库 -->
<dataNode name="sh2" dataHost="repSet2" database="bazaar" />
<dataNode name="sh4" dataHost="repSet4" database="bazaar" />
<dataNode name="sh5" dataHost="repSet5" database="bazaar" />
<!-- 访问users,读写配置 -->
<dataHost name="repSet1" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.110:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.111:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- 访问goods,读写配置 -->
<dataHost name="repSet3" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.130:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.131:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- 访问orders,读写配置 -->
<!-- 水平分片1 -->
<dataHost name="repSet2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.120:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.121:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- 水平分片2 -->
<dataHost name="repSet2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.140:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.141:3306" user="root" password="root" />
</writeHost>
</dataHost>
<!-- 水平分片3 -->
<dataHost name="repSet2" maxCon="1000" minCon="10" balance="1" writeType="0" dbType="mysql" dbDriver="native" switchType="1">
<heartbeat>
select user()
</heartbeat>
<writeHost host="repMaster" url="192.168.1.150:3306" user="root" password="root">
<readHost host="repSlave" url="192.168.1.151:3306" user="root" password="root" />
</writeHost>
</dataHost>
</schema>
至此,水平分表构建完成。
拆分策略
指定片键
我们以范围拆分为例,如果想指定拆分的键(上面是id),可以打开配置文件rule.xml中修改即可:
<tableRule name="auto-sharding-long">
<rule>
<columns>id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
常见拆分
针对拆分策略,有以下的几种常见的:
| 策略 | 描述 |
|---|---|
| auto-sharding-long | range,范围拆分 |
| mod-long | 取余 |
| sharding-by-intfile | 枚举 |
| hash | 哈希 |
| time | 时间 |
若想了解更多,可参见如下文章:
点我跳转
工作管理
基本概述
MyCat具有工作端口和管理端口之分。
工作端口号为8066,也是application链接的端口号。
管理端口号为9066,可对MyCat配置与节点等做出管控。
相关文章
由于篇幅原因,这里不再介绍,如果你感兴趣,可参见如下文章:
点我跳转

 浙公网安备 33010602011771号
浙公网安备 33010602011771号