DBA MongoDB 聚合操作
数据准备
在网上找了很多关于MongoDB的聚合操作文章,讲的都不是很清晰。
所以这里来写一篇文章吧,做一个简单应用。
还是使用之前使用过的数据:
> db.collection.drop()
> db.collection.insertMany(
[
{
_id:1,
name:"Jack",
gender:"male",
age:18,
grades:
{
Js:88,
Py:92,
Go:78
},
class:{
name:"三年级一班",
numPeople:30,
}
},
{
_id:2,
name:"Tom",
gender:"male",
age:19,
grades:{
Js:72,
Py:81,
Go:56,
},
class:{
name:"三年级一班",
numPeople:30,
}
},
{
_id:3,
name:"Ken",
gender:"male",
age:20,
grades:{
Js:61,
Py:72,
Go:96,
},
class:{
name:"三年级一班",
numPeople:30,
}
},
{
_id:4,
name:"Keisha",
gender:"female",
age:17,
grades:{
Js:31,
Py:42,
Go:26,
},
class:{
name:"三年级二班",
numPeople:21,
}
},
{
_id:5,
name:"Kelly",
gender:"female",
age:18,
grades:{
Js:71,
Py:64,
Go:19,
},
class:{
name:"三年级二班",
numPeople:21,
}
}
]
)
count()
对集合直接调用count()函数,可获取记录条数。
> db.collection.count()
5
也可以进行条件筛选,如找出Js成绩大于80的文档个数:
> db.collection.count({"grades.Js" : {$gt : 80}})
1
distinct()
对集合直接调用distinct()函数,并传入key,用于获取该key的不同value。
如下所示,获取所有文档的name:
> db.collection.distinct("name")
[ "Jack", "Keisha", "Kelly", "Ken", "Tom" ]
aggregate()
基础语法
其实以前的版本会使用group()函数做聚合查询,但是新版本已经不那么用了。
现在使用aggregate()函数完成聚合查询,参数必定是一个数组。
首先基础格式如下:
db.集合名.aggregate(
[
{
$group : {
_id : "$分组1键名","$分组2键名", # 按什么分组,按null就是不分组,必须加$符号
别名 : {聚合运算: "$运算列"},
},
$步骤 : {
上个管道的别名 : {$条件 : 值}
别名 : {$条件 : "$上个管道的别名"}
# 如果是上个管道的别名要应用在{}中,则必须加上$的前缀,且以双引号括起来
# 所以这里会出现两种情况
},
}
]
)
管道与步骤
整个聚合运算由多个管道(Pipeline)组成,而每个运算层次被称为步骤(Stage)。
可以这么理解,在aggregate()函数的[]中,每个{}会被认为是一个管道,每个{}中顶层以$开始的键被称为步骤。
如图所示,正确理解管道和步骤:
-
在管道的表达式{}中使用原管道或文档字段,必须添加$的前缀,且以双引号括起来
-
而在管道的步骤key中引用原管道字段则不需要加$的前缀
下面的示例中引用TotalGrades字段没有在{}中,则不需要加$前缀:
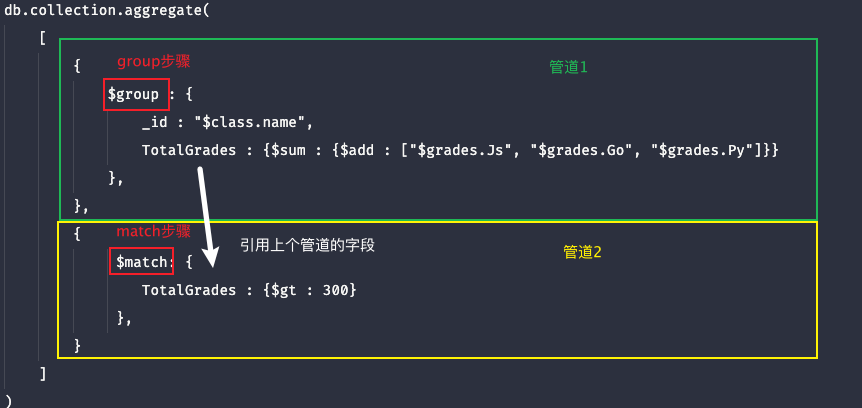
而下面的这个示例中,由于上个管道的字段引用在{}中,则需要加$前缀与双引号:
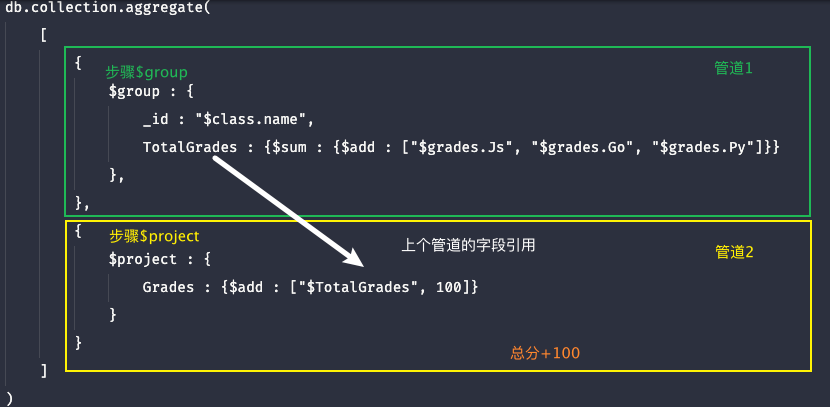
每个管道:
- 接受一系列文档(原始数据);
- 由步骤对这些文档进行一系列运算;
- 结果文档输出给下一个步骤,由下一个步骤的管道继续运算;
如图所示:

当前步骤将管道处理结果交给下一个步骤,最终计算出整个结果,如图所示:

在$match步骤中,where过滤出了status:a的数据,然后交由$group进行处理,而$group根据不同的cust_id,将结果分为2组,并计算了总和。
所以最终结果只是包含字段_id和total。
步骤修改器
以下是常见的步骤修改器:
| 步骤修改器 | 作用 | SQL等价运算符 |
|---|---|---|
| $match | 条件匹配,放在$group前是where,放在$group后是having | WHERE |
| $project | 控制select的结果,相当于as | AS |
| $sort | 条件排序 | ORDER BY |
| $group | 条件分组 | GROUP BY |
| $skip | 跳过文档的数量,相当于limit的第二个值 | SKIP |
| $limit | 限制结果的数量,相当于limit的第一个值 | LIMIT |
| $lookup | 多表关联查询 | JOIN |
| $unwind | 展开数组 | N/A |
| $graphLookup | 图搜索 | N/A |
| $facet/$bucket | 分面搜索 | N/A |
管道修改器
以下是在管道步骤中常用的运算符:
| $MATCH | $PROJECT | $GROUP |
|---|---|---|
| $eq | $map / $reduce / $filter | $sum / $avg |
| $in / $nin | $range | $push / $addToSet |
| $and / $or / $not / $nor | $multiply / $divide / $substract / $add | $first / $last / $max/$min |
| $exists / $type | $year / $month / $dayOfMonth / $hour / $minute / $second | |
| $mod / $regex | ||
| $all / $elemMatch / $size | ||
| $geoWithin / $intersect |
示例演示
$Group>$sum
示例,计算出两个班级的总成绩:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
TotalGrades : {$sum : {$add : ["$grades.Js", "$grades.Go", "$grades.Py"]}}
},
},
]
)
{ "_id" : "三年级二班", "TotalGrades" : 253 }
{ "_id" : "三年级一班", "TotalGrades" : 696 }
示例,计算两个班级的总年龄:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
TotalAge : {$sum : {$add : ["$age"]}}
},
},
]
)
{ "_id" : "三年级一班", "TotalAge" : 57 }
{ "_id" : "三年级二班", "TotalAge" : 35 }
$Group>$avg
示例,计算两个班级的平均Js成绩:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
avgJs : {$avg : {$add : ["$grades.Js"]}}
},
},
]
)
{ "_id" : "三年级一班", "avgJs" : 73.66666666666667 }
{ "_id" : "三年级二班", "avgJs" : 51 }
示例,计算两个班级的平均年龄:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
avgAge : {$avg : {$add : ["$age"]}}
},
},
]
)
{ "_id" : "三年级一班", "avgAge" : 19 }
{ "_id" : "三年级二班", "avgAge" : 17.5 }
$Group>$Max&$Min
示例,拿到两个班级中的最大年龄:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
maxAge : {$max : "$age"}
},
},
]
)
{ "_id" : "三年级一班", "maxAge" : 20 }
{ "_id" : "三年级二班", "maxAge" : 18 }
$match
放在$group之前是where,而放在$group之后是having。
示例,查询平均年龄小于18岁的班级:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
avgAge : {$avg : "$age"}
},
},
{
$match : {
avgAge : {$lt : 18}
}
}
]
)
{ "_id" : "三年级二班", "avgAge" : 17.5 }
$project
$project能对显示结果做任意拼接。
示例,展示每个每个班级的总分,并在此基础上加上100:
db.collection.aggregate(
[
{
$group : {
_id : "$class.name",
TotalGrades : {$sum : {$add : ["$grades.Js", "$grades.Go", "$grades.Py"]}}
},
},
{
$project : {
Grades : {$add : ["$TotalGrades", 100]}
}
}
]
)
{ "_id" : "三年级二班", "Grades" : 353 }
{ "_id" : "三年级一班", "Grades" : 796 }
# 引用上个管道的TotalGrades,在{}中引用,需要加$前缀,且以双引号括起来
了解更多
官方文档
上面举例的仅是冰山一角。
还请参阅官方文档:点我跳转
如何查看这份文档?

红框标注的部分为步骤修改器。
绿框标准的部分为管道修改器。
TJ极客时间
TJ是MongoDB中文社区的大佬。
他对MongoDB做了详细的演示,如果你想了解更多请在极客时间中搜索MongoDB。
这里也有一份关于TJ讲的MongoDB笔记博客:点我跳转

 浙公网安备 33010602011771号
浙公网安备 33010602011771号