DBA MySQL MHA架构
功能概述
MHA架构是一种单活的高可用架构,搭建条件最少是1主2从,且必须为独立的机器,不能单机多实例进行搭建。
下面是一个比较完整的MHA架构图,1主2从为1组节点,可以有多组节点都交由一个Manager进行管理:
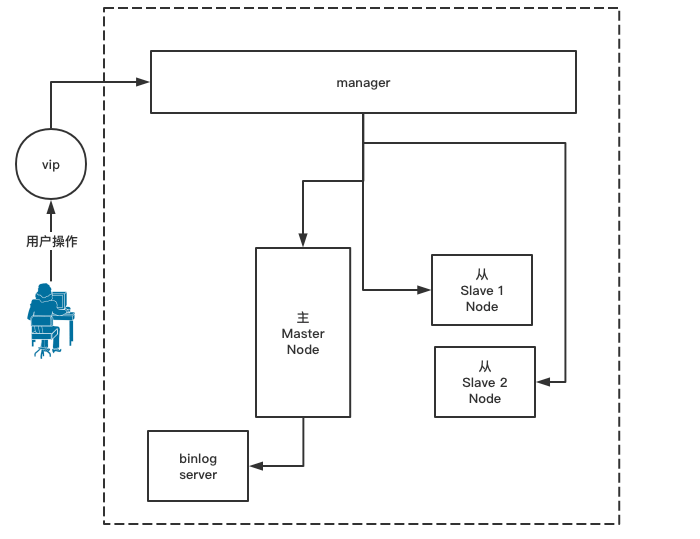
它的功能在于能够对主从运行状态进行监控,自动的在主节点宕机之后能提供单次的主从角色互换功能及故障恢复功能。
在主库宕机后,可以通过邮件方式通知管理员,由管理员进行简单配置后再次提供服务,所以整体来说令主从的管理维护变的十分方便与高效。
设计思路
软件部分
软件部分主要分为Manager软件与Node软件,所有软件工具均有prel语言脚本构成。
Manager软件安装在管理的服务器上,该服务器只负责对Node进行管理,本身不存储任何与业务有关的数据:
主要工具如下:
masterha_manger - 启动MHA
masterha_check_ssh - 检查MHA的SSH配置情况
masterha_check_repl - 检查MySQL主从复制情况
masterha_master_monitor - 检测Master是否宕机
masterha_check_status - 检测当前MHA运行状态
masterha_master_switch - 控制故障转移Failover,即故障自动恢复
masterha_conf_host - 添加或者删除Manager中配置的server信息
Node软件安装在所有节点上,包括以下工具:
save_binary_logs - 保存并复制Master的binlog
apply_diff_relay_logs - 识别差异的中继日志事件并将其差异的事件应用于其他的
purge_relay_logs - 自动清除中继日志,且不会阻塞SQL_T线程
主体思路
首先,MHA会通过masterha_manger脚本启动MHA的功能,对主从进行监控。
当MHA启动后,通过masterha_check_ssh脚本进行互信的检查,以及通过masterha_check_repl检查主从的复制情况。
所有检查通过,监控功能开始正常工作,根据设定每间隔s秒来向主库进行一次ping,该工作由masterha_master_monitor完成。
在ping三次主库没有响应时,Manager认为主库宕机,开始进行自动故障恢复流程。
由于我们配置了多个从库,Manager会根据以下算法进行选主过程,将选中的从库变更为主库:
- 算法一:读取配置文件中是否有强制的选主参数,
candidate_master=1与check_repl_delay=0 - 算法二:自动判断目前已有从库的日志量,将最接近主库日志量的从库选为新的主库
- 算法三:根据配置文件中先后顺序进行选主
当选主完成后,Manager会判断主库的SSH链接情况,情况如下所示:
-
情况一:主库的
SSH能够链接,逻辑因素宕机,此时Manager会通过save_binary_logs脚本,计算各个从库(包括新主库)与已宕机主库之间binlog差异,将已宕机主库的binlog位置找出来并进行截取,分发到各个从库上进行数据对齐,确保一致性 -
情况二:主库的
SSH不能链接,物理因素宕机,此时Manager会通过apply_diff_relay_logs脚本,计算各个从库relay-log的差异,将差异较大的从库与新主库进行relay-log对齐,确保一致性
当所有的从库数据一致性被确保之后,所有从库将会与新主库建立主从关系,同时旧的已宕机主库信息将会从Manager配置文件中移除,至此整个MHA架构服务结束,Manager不再对Node进行管理,接下来需要管理员手动对已宕机主库进行排查恢复,并且手动搭建与新主库之间的主从关系且重新启动MHA架构服务。
其他补充
应用透明VIP功能:这是一种在应用层提供的对外功能,即暴露在外部的虚拟IP,如果将真实主库的IP交由用户群体进行访问,那么主库宕机之后即使已经进行故障转移抓取了从库来替代主库的位置,但由于用户群体皆是访问已宕机的主库IP,所以依然会造成服务暂停,新主库得不到任何用户的访问。值得一提的是,目前版本的MHA已经自带的支持应用透明功能,你只需要在Master端做相应的设置即可。点我了解更多
二进制日志存储服务器:这是一个单独存放拷贝主库binlog的服务器,不会参与任何业务处理,并且不会与主库的binlog产生任何延迟,具体思路是当主库的事务准备提交前,会将binlog记录发送给该服务器,只有当二进制日志存储服务器将该条记录成功存储后,主库上这一事务方可被提交,由此可见,这种技术是在牺牲性能的前提下保证了数据的一致性,一般来说我们都会进行开启,在主机宕机且SSH不可被链接状态下,从库的数据恢复依然可以从二进制日志存储服务器中获取数据。
向管理员发送邮件提醒功能:这其实是一个额外的功能,对此来提醒管理员重新构建MHA架构了。
主从搭建
地址介绍
MHA架构仅支持单数的Node,所以我们按照最低标准1主2从进行搭建,如下所示:
Master_server:192.168.1.120
Slave_server_1:192.168.1.121
Slave_server_2:192.168.1.122
基础配置
首先是主库的my.cnf文件:
[mysqld]
user=mysql
server_id=1
port=3306
basedir=/usr/local/mysql
datadir=/usr/local/data
log_error=/usr/local/logs/mysqld.log
log_bin=/usr/local/logs/mysql_bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
slow_query_log=1
long_query_time=10
slow_query_log_file=/usr/local/logs/slow.log
log_queries_not_using_indexes
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
default-storage-engine=INNODB
socket=/tmp/mysql.sock
从库的my.cnf文件,注意,两个从库的server_id号不能相同,并且,从库也需要开启binlog记录:
[mysqld]
user=mysql
server_id=2 # 注意,还有个从库需要更改
port=3306
basedir=/usr/local/mysql
datadir=/usr/local/data
log_error=/usr/local/logs/mysqld.log
log_bin=/usr/local/logs/mysql_bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
slow_query_log=1
long_query_time=10
slow_query_log_file=/usr/local/logs/slow.log
log_queries_not_using_indexes
character-set-server=utf8mb4
collation-server=utf8mb4_general_ci
default-storage-engine=INNODB
socket=/tmp/mysql.sock
对上述所有数据库添加systemctl系统服务:
T > cat >/etc/systemd/system/mysqld.service <<EOF
[Unit]
Description=MySQL Server
Documentation=man:mysqld(8)
Documentation=http://dev.mysql.com/doc/refman/en/using-systemd.html
After=network.target
After=syslog.target
[Install]
WantedBy=multi-user.target
[Service]
User=mysql
Group=mysql
ExecStart=/usr/local/mysql/bin/mysqld --defaults-file=/etc/my.cnf
LimitNOFILE = 5000
EOF
对上述所有数据库开启服务:
T > systemctl start mysqld.service
T > systemctl enable mysqld.service
数据模拟
在GTID主从环境搭建未搭建之前,给主库录入一点数据:
M > mysql -uroot -p -S /tmp/mysql.sock
M > CREATE DATABASE db1 CHARSET utf8mb4;
M > use db1;
M > CREATE TABLE userInfo(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT "记录编号",
name CHAR(32) NOT NULL COMMENT "用户姓名",
INDEX idx_name(name) COMMENT "普通索引"
);
接下来是插入数据:
M > INSERT INTO userInfo(name) VALUES ("Jack"),("Ken"),("Tom");
开始搭建
搭建第一步,在主库上创建一个用于复制的用户,值得注意的是,我们并不需要在从库上创建该用户,因为主从一旦建立,从库会复制主库的binlog,所以也就会自动的创建该用户,MHA即使进入故障转移,也能够确保新主库有复制用户:
T > mysql -uroot -p -S /tmp/mysql.sock -e "GRANT REPLICATION SLAVE ON *.* TO repl@'192.168.1.%' IDENTIFIED BY '123'"
接着我们需要使用mysqldump工具对主库数据进行一次全备:
T > mysqldump -uroot -p -S /tmp/mysql.sock -A --master-data=2 --single-transaction -R -E --triggers > /tmp/full.sql
GTID的主从搭建时如果使用mysqldump进行全备,则并不需要关注全备文件中关于SET @@GLOBAL.GTID_PURGED值的设定。
将主库的全备文件,上传至两个从库:
T > scp /tmp/full.sql root@192.168.1.121:/tmp/master_full.sql
T > scp /tmp/full.sql root@192.168.1.122:/tmp/master_full.sql
从库搭建
第一步,我们需要登录两个从库,对主库的全备文件做一次恢复操作:
T > mysql -uroot -p -S /tmp/mysql.sock
两个从库依次登录mysql-client端进行恢复:
M > SET sql_log_bin=0;
M > SOURCE /tmp/master_full.sql;
M > SET sql_log_bin=1;
两个从库开始编写链接信息,使其连接到主库:
M > CHANGE MASTER TO MASTER_HOST='192.168.1.120',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10,
MASTER_AUTO_POSITION=1;
启用复制:
M > START SLAVE;
检查状态:
M > SHOW SLAVE STATUS\G;
# Slave_IO_Running: Yes
# Slave_SQL_Running: Yes
# Retrieved_Gtid_Set: master_server_uuid:transaction_id
# Executed_Gtid_Set: master_server_uuid:transaction_id
# Auto_Position:1
MHA搭建
地址介绍
现在,基础的GTID主从已经搭建完成了。
我们准备进行MHA的搭建,地址如下:
Manager_server:192.168.1.200
Binlog_server:192.168.1.201
软链接配置
MHA在启动后,不会加载环境变量,而是从/usr/bin下读取需要的应用,所以我们要在1主2从上做下面两条软链接:
ln -s /usr/local/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /usr/local/mysql/bin/mysql /usr/bin/mysql
互信配置
我们需要在Manager服务端与1主2从的服务端之间打通SSH互信,保证彼此能够互相链接,且在链接时不会有任何弹出提示要求输入密码的操作等。
首先在Manager服务端做公钥,然后将这份公钥scp上传至1主2从的服务端:
T > rm -rf /root/.ssh
T > ssh-keygen # 一直回车,产生公私钥
T > cd /root/.ssh
T > mv id_rsa.pub authorized_keys
T > scp -r /root/.ssh root@192.168.1.120:/root # 输入yes
T > scp -r /root/.ssh root@192.168.1.121:/root
T > scp -r /root/.ssh root@192.168.1.122:/root
# 或者你也可以使用命令ssh-copy-id user@host来进行公钥传输
# 如果用ssh-copy-id命令,则不用进行mv操作
上传完成之后,在Manager中做SSH链接,避免今后链接时出现弹出信息:
T > ssh root@192.168.1.120 pwd
T > ssh root@192.168.1.121 pwd
T > ssh root@192.168.1.122 pwd
同时你需要登录1主2从,进行相似的操作:
# Master
T > ssh root@192.168.1.121 pwd
T > ssh root@192.168.1.122 pwd
T > ssh root@192.168.1.200 pwd
# Slave1
T > ssh root@192.168.1.120 pwd
T > ssh root@192.168.1.122 pwd
T > ssh root@192.168.1.200 pwd
# Slave2
T > ssh root@192.168.1.120 pwd
T > ssh root@192.168.1.121 pwd
T > ssh root@192.168.1.200 pwd
如果你想了解更多SSH相关的知识,点我跳转
软件安装
在所有服务器上下载MHA相关软件:
# 官网
https://code.google.com/archive/p/mysql-master-ha/
# github
https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
下载包含的内容如下:
mha4mysql-manager-0.56-0.el6.noarch.rpm
mha4mysql-manager-0.56.tar.gz -- 有VIP脚本,以及EMAIL脚本
mha4mysql-node-0.56-0.el6.noarch.rpm
mha4mysql-node-0.56.tar.gz
为Manager服务端,安装软件:
# 安装epel源
T > wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-6.repo
T > yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
T > rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
为1主2从,即所有Node节点安装软件依赖包:
T > yum install perl-DBD-MySQL -y
T > rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
在Master主库上创建MHA必要的用户,因为root用户不允许远程登录,为何不在从库上创建呢?因为主从关系已搭建,从库会自动复制:
M > GRANT ALL PRIVILEGES ON *.* TO mha@'192.168.1.%' IDENTIFIED BY 'mha';
配置文件
现在在Manager服务端,创建配置文件以及日志文件的存放目录:
T > mkdir -p /etc/mha
T > mkdir -p /var/log/mha/app1
# app1为项目名称,实际生产中以项目名为准
使用vim编辑器,填入以下配置项:
T > vim /etc/mha/app1.cnf
[server default]
manager_workdir=/var/log/mha/app1
manager_log=/var/log/mha/app1/manager
master_binlog_dir=/usr/local/logs
user=mha
password=mha
ping_interval=2
repl_user=repl
repl_password=123
ssh_user=root
[server1]
hostname=192.168.1.120
port=3306
[server2]
hostname=192.168.1.121
port=3306
[server3]
hostname=192.168.1.122
port=3306
下面是配置项说明:
| 配置项 | 描述 |
|---|---|
| manager_workdir | 当前Manager的工作目录 |
| manager_log | 当前Manager产生的日志存放路径及名称 |
| master_binlog_dir | 主库中binlog的存放路径,注意,不需要日志前缀名 |
| user | 执行MHA管控的主库用户 |
| password | 执行MHA管控的主库用户密码 |
| ping_interval | Manager向主库Ping的时间间隔,依次来判定主库是否宕机 |
| repl_user | 主库中为从库复制binlog的用户 |
| repl_password | 主库中为从库复制binlog的用户密码 |
| ssh_user | Manager进行SSH链接时,将会用那个Unix用户进行链接 |
状态检查
第一步,在Manager服务端上对1主2从的服务器进行SSH互信检查:
T > masterha_check_ssh --conf=/etc/mha/app1.cnf
第二步,在Manager服务器上进行主从状态检查:
T > masterha_check_ssh --conf=/etc/mha/app1.cnf
确认都是ok状态后,进行下一步操作。
MHA命令
Manager端现在已经能够进行MHA的各种服务了。
开启MHA监控的命令如下:
T > nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
# --conf:配置文件
# --remove_dead_master_conf:该参数代表当发生主从切换后,老的主库的IP将会从配置文件中移除
# --ignore_last_failover:默认情况下MHA会生成一个文件,该文件限制了手动切换时间不能低于8小时,添加该参数移除限制。文件名是app1.failover.complete
检查MHA是否正常运行中:
T > masterha_check_status --conf=/etc/mha/app1.cnf
T > mysql -umha -pmha -h 192.168.1.120 -e "show variables like 'server_id'"
T > mysql -umha -pmha -h 192.168.1.121 -e "show variables like 'server_id'"
T > mysql -umha -pmha -h 192.168.1.122 -e "show variables like 'server_id'"
停止当前MHA的监控工作:
masterha_stop --conf=/etc/mha/app1.cnf
MHA中可以对多个主从进行监控,只需要配置不同的Manager文件,然后进行启动即可
这里对常用命令进行例举,注意,在命令后应当跟上配置文件:
| 终端命令 | 描述 |
|---|---|
| masterha_check_repl | 检查主从复制情况 |
| masterha_check_ssh | 检查SSH互信配置情况 |
| masterha_check_status | 检查当前MHA运行状态 |
| masterha_manager | 启动MHA |
| masterha_stop | 停止MHA |
| masterha_master_monitor | 检测Master是否宕机 |
| masterha_master_switch | 控制故障转移 |
| masterha_secondary_check | 多线路检测Master是否存活 |
额外功能
以下操作均是在Manager服务器进行。
想开启MHA监控到Master异常自动发送邮件的功能,需要对Manager配置文件进行修改,填入以下配置项:
T > vim /etc/mha/app1.cnf
[server default]
report_script=/usr/local/bin/send_report
这里需要用到一个脚本,点我下载。
这个脚本里面有一些代码需要你自行修改:
my $smtp='smtp.163.com';
my $mail_from='from@163.com';
my $mail_user='from@163.com';
my $mail_pass='password';
my $mail_to='to@qq.com';
# 必须注册163smtp邮箱作为发送邮箱
# my $mail_from:发送警告的邮箱地址
# my $mail_user:用户名
# my $mail_pass:密码
# my $mail_to:发送给谁
然后把下载好的文件丢到下面的路径中:
T > mv ./send_report /usr/local/bin/send_report
该文件中如果存在一些中文信息的话,可以对其进行一次unix转码:
T > dos2unix /usr/local/bin/send_report
一切就绪后,为该文件添加执行权限:
T > chmod +x /usr/local/bin/send_report
现在,你可以重启MHA服务了:
T > masterha_stop --conf=/etc/mha/app1.cnf
T > nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
应用透明
以下操作均是在Manager服务器进行。
想开启应用透明的VIP功能,需要对Manager配置文件进行修改,填入以下配置项:
T > vim /etc/mha/app1.cnf
[server default]
master_ip_failover_script=/usr/local/bin/master_ip_failover
这里需要用到一个脚本,点我下载。
或者你也可以在软件下载的脚本包中找到该文件,路径如下:
mha4mysql-manager-0.56/samples/scripts
在下载脚本时,你要打印一下你的网卡信息,并将你目前正在使用的网卡进行记录:
T > ifconfig
这个脚本里面有一些代码需要你自行修改:
my $vip = '192.168.1.220/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth1:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth1:$key down";
# $vip:设置一个没人用的地址,作为虚拟IP
# $key:随便设置
# $ssh_start_vip:设置为自己的网卡
# $ssh_stop_vip:与上面代码网卡设置相同
当下载完成后,你首先要做的就是在Manager端做一个虚拟的VIP-IP,如下所示:
T > ifconfig eth1:1 192.168.1.220/24
# 网卡名字必须与$ssh_开头的两个中的网卡名相同
# 网卡后的数字1必须与$key相同
# 地址必须与$vip相同
# 确保eth1:1未被使用
然后把下载好的文件丢到下面的路径中:
T > mv ./master_ip_failover /usr/local/bin/master_ip_failover
该文件中如果存在一些中文信息的话,可以对其进行一次unix转码:
T > dos2unix /usr/local/bin/master_ip_failover
一切就绪后,为该文件添加执行权限:
T > chmod +x /usr/local/bin/master_ip_failover
现在,你可以重启MHA服务了:
T > masterha_stop --conf=/etc/mha/app1.cnf
T > nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
binlog_server
如果想支持binlog_server,则binlog_server服务器安装的MySQL版本必须大于5.6,且开启gtid。
在Manager服务器的MHA配置中,加入以下配置项:
T > vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=192.168.1.201
master_binlog_dir=/usr/local/logs
# no_master:主库宕机后binlog_server永远不竞选主库
# 如有从库设定为延时从库,则也应该令其永不竞选
你别忘了在binlog_server下创建目录…,如下所示:
T > mkdir -p /usr/local/logs/
T > chown -R mysql.mysql /usr/local/logs
然后是在binlog_server中拉取主库的binlog:
T > cd /usr/local/logs
T > mysqlbinlog -R --host=192.168.1.120 --user=mha --password=mha --raw --stop-never mysql_bin.000001 &
# 注意,拉取日志时要先在主库中使用SHOW MASTER STATUS;
# 查看当前所使用的binlog文件
主库候选
如果你想指定一些从库在主库宕机后进行有力的竞选,可配置如下两个参数,如Slave1竞争:
[server2]
hostname=192.168.1.121
port=3306
candidate_master=1
check_repl_delay=0
# candidate_master:设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主
# 库不是集群中GTID号最新的slave
# check_repl_delay:默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一
# 个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新
# 的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的# 过程中一定是新的master
这个竞争主库可以用在一地二中心的应用上,即查看三个Node节点的地理位置。
Master -> 中心
Slave1 -> 距离Master有1000米
Slave2 -> 距离Master有5000米
此时就可以让Slave1来做主库候选。
故障演练
模拟故障
执行以下命令,停止当前主库120的执行:
T > systemctl stop mysqld.service
使用如下命令,观察MHA日志的自动切换:
T > tail -f /var/log/mha/app1/manager
当结尾显示successfully时,代表已经有从库替换了主库的位置,此时MHA监控结束。
恢复过程
启动已宕机主库120:
T > systemctl start mysqld.service
如果你不知道谁是新主库,可登录一个绝对不可能是主库的Slave中,执行以下命令进行查看:
M > SHOW SLAVE STATUS\G;
# Master_Host:主库地址
在已宕机主库120中与新主库建立主从关系:
M > CHANGE MASTER TO
MASTER_HOST='192.168.1.121', -- 新主库为121
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='repl',
MASTER_PASSWORD='123';
M > START SLAVE ;
登录Manager节点,在配置文件中重新加入已宕机主库的信息,另外还要检查binlog_server的配置是否还在,如果不在就进行添加:
T > vim /etc/mha/app1.cnf
[server1]
hostname=192.168.1.120
port=3306
登录binlog_server服务器,清除以拉取得原本主库的二进制日志数据,重新进行拉取:
T > mv /usr/local/logs/* /usr/local/tmp
T > cd /usr/local/logs
T > mysqlbinlog -R --host=192.168.1.121 --user=mha --password=mha --raw --stop-never mysql_bin.000001 &
# 注意,拉取日志时要先在新主库中使用SHOW MASTER STATUS;
# 查看当前所使用的binlog文件
最后在Manager服务器上重启MHA,开启监控:
T > masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &

 浙公网安备 33010602011771号
浙公网安备 33010602011771号