DBA MySQL索引相关
功能概述
一张数据表中具有百万级的数据时,如何精确且快速的拿出其中某一条或多条记录成为了人们思考的问题。
InnoDB存储引擎的出现让这个问题得到了很好的解决,InnoDB存储引擎是以索引来进行数据的组织,而索引在MySQL中也被称之为键,因此UNIQUE KEY,PRIMARY KEY约束字段会作为索引字段。
当没有明确指出PRIMAY KEY时,InnoDB存储引擎首先会查找是否具有非空且唯一约束条件的字段。
如果有将则将其转变为主键,如果没有则会自动的创建一个6字节的隐藏主键用于组织数据,但是由于该主键是隐藏的所以对查询没有任何帮助。
索引相当于一本大字典的目录,有了目录来找想要的内容就快很多,否则就只能进行一页一页的遍历查询
索引相关
索引算法
常见的索引算法如下:
| 索引算法 | 描述 |
|---|---|
| B树 | B树索引,也有其升级版B+树,B*树 |
| R树 | 一般不用 |
| Hash | 自适应哈希索引,不必过分关注,内部自己会进行使用 |
| Full Text | 全文索引,类似ES |
| GIS | 地理位置索引,类似MangoDB |
MySQL中默认采用B*Tree索引算法。
B树算法
B树算法分为普通B树、B-Tree,B+Tree以及B*Tree,先从B-Tree入手,它与普通B树的差别仅有叶子节点能够突破最多2个的限制。
下图是普通B-Tree的结构图:
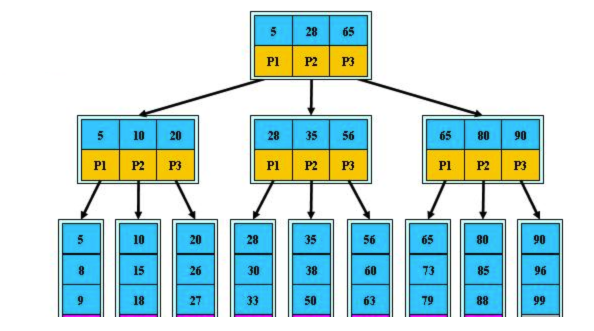
- 首先整棵树分为三层,分别为根节点,枝节点和叶子节点
- 每一块区域就是InnoDB最小存读单元16kb的page
- 蓝色部分为存储的数据、黄色部分为下层节点的指针
- 只有最下层的叶子节点中,才存放一整行记录
观察该结构,可以发现每一层中的蓝色数据块都是下层中每个page的最小值。
模拟查询数据项50过程如下:
- 从磁盘中加载根节点page至内存,发生1次I/O
- 在内存中以二分法形式,确定数据项大于28小于65,根据根节点指针P2指向枝节点中第2个page
- 根据指针从磁盘中加载枝节点第2个page至内存,发生第2次I/O
- 在内存中以二分法形式,确定数据项大于40小于56,根据枝节点第二个page中的P2指针指向叶子节点中第5个page
- 根据指针从磁盘中加载叶子节点第5个page,发生第3次I/O
- 在内存中以二分法形式,拿到数据项50,查找完成
可以发现,总共只需3次I/O即可拿到数据项50。
其实3层高度的B树可以表示上百万的数据,如果上百万的数据查找只需要三次I/O,性能提高将是巨大的。
如果没有使用索引,则不会利用B树查找算法对数据项进行获取,届时百万级数据将进行百万次I/O,数据查找速度直线下降。
下图是`B+Tree`的结构图:
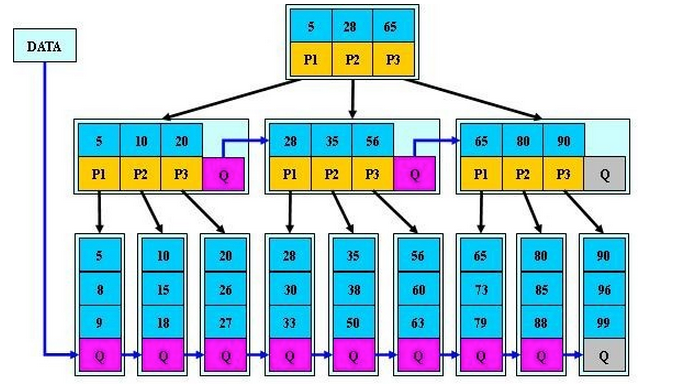
相比于普通B-Tree,它在叶子节点中也加入了指针Q(双向,上图表述有误)用来指向相邻的叶子节点。
这对于范围查找速度的提升是巨大的。
比如,查找大于20的数据项,如果没有叶子节点指针,则查找完 20/26/27 这一page后,下一页page将从根节点开始重新进行查找。
当有了叶子节点指针后,只需要从叶子节点往后拿数据项即可。
下图是B*Tree的结构图:
相比于B+Tree,它在B+Tree的基础上对枝节点也加入了指针Q,(双向,上图表述有误)用来指向相邻的枝节点。
在某些特定的情况下,如我们的查找条件是大于20小于99并且不要28至63中的数据项,此时就可以通过枝节点进行跳跃查找。
B*Tree是三种B树算法中效率最高的,也是MySQL目前正在使用的索引算法。
B-Tree聚集索引
一张表中必须有且只能有一个聚集索引。
聚集索引B树最底层的叶子节点是一整行数据记录,所以聚集索引能够十分快速的拿到一整行记录。
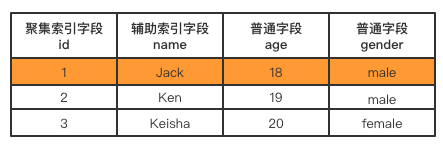
- MySQL会自动选择主键作为聚集索引列,若没有主键则会选择非空且唯一键,如果都没有会生成隐藏的主键
- MySQL进行存储数据时,会按照聚集索引列值得顺序进行有序的存储数据行
- 聚集索引直接将原表数据页,作为叶子节点,然后提取聚集索引列向上生成枝和根
B-Tree辅助索引
一张表中可以有多个辅助索引,也可以没有辅助索引。
辅助索引B树最底层的叶子节点并不会存储一整行记录,而是只存储单列索引的数据,并且还存储了聚集索引的值信息。
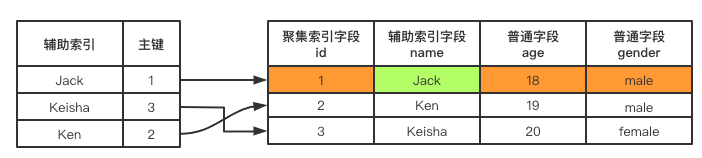
- 提取索引列的所有值并进行排序
- 将排好序的值,均匀的存放在叶子节点,进一步生成枝节点和根节点
- 在叶子节点中的值,都会对应到聚集索引即主键值中
使用索引
索引类型
MySQL常见索引类型如下表所示:
| 索引名 | 描述 | 类别 |
|---|---|---|
| PRIMARY KEY(field) | 主键索引,加速查找,非空且唯一约束 | 聚集索引 |
| INDEX(field) | 普通索引,只加速查找,无约束条件 | 辅助索引 |
| UNIQUE(field) | 唯一索引,加速查找,唯一约束 | 辅助索引 |
| INDEX(field1,field2) | 联合普通索引 | 辅助索引 |
| PRIMARY KEY(field1,field2) | 联合主键索引 | 聚集索引 |
| UNIQUE(field1,field2) | 联合唯一索引 | 辅助索引 |
| FULLTEXT(field) | 全文索引 | 辅助索引 |
| SPATIAL(field) | 空间索引 | 辅助索引 |
索引命令
索引应当再建立表时就进行创建,如果表中已有大量数据,再进行创建索引会花费大量的时间。
索引相关命令如下所示,关于如何创建联合索引,联合主键索引请参照 MySQL 约束条件:
# 创建表时就创建索引
CREATE TABLE 表名(
字段名1 类型(宽度) 约束条件1,约束条件2... COMMENT 字段描述信息,
字段名2 类型(宽度) 约束条件1,约束条件2... COMMENT 字段描述信息,
索引类型 索引名字(字段名(索引长度)) COMMENT 索引描述信息
) ENGINE 存储引擎 CHARSET 字符编码 COLLATE 校对规则;
# 在已存在的表上创建索引01
# 如果是INDEX类型索引,则不用指明索引类型
CREATE 索引类型 INDEX 索引名字
ON 表名(字段名(索引长度)) COMMENT 索引描述信息;
# 在已存在的表上创建索引02
# 如果是INDEX类型索引,则不用指明索引类型
ALTER TABLE 表名 ADD
索引类型 索引名字(字段名(索引长度)) COMMENT 索引描述信息 ;
# 查询索引
SHOW INDEX FROM 表名\G;
# 删除索引
DROP INDEX 索引名 ON 表名字;
示例演示:
# 创建表时就创建索引
CREATE TABLE userInfo(
id INT PRIMARY KEY AUTO_INCREMENT COMMENT "记录编号",
name CHAR(32) NOT NULL COMMENT "用户名",
age TINYINT(3) UNSIGNED NOT NULL DEFAULT 0 COMMENT "年龄",
gender ENUM("MALE", "FEMALE", "UNKNOW") NOT NULL DEFAULT "UNKNOW" COMMENT "性别",
INDEX idx_name(name) COMMENT "普通索引"
) ENGINE innodb CHARSET utf8mb4 COLLATE utf8mb4_general_ci;
# 查询索引
SHOW INDEX FROM userinfo\G;
# 删除普通索引
DROP INDEX idx_name ON userinfo;
# 在已存在的表上创建索引01,创建唯一索引
# 非INDEX类型索引,需指明索引类型
CREATE UNIQUE INDEX unique_index_name
ON userInfo(name) COMMENT "唯一索引";
# 删除唯一索引
DROP INDEX unique_index_name ON userinfo;
# 在已存在的表上创建索引01,创建普通索引
# 如果是INDEX类型索引,则不用指明索引类型
CREATE INDEX idx_name
ON userInfo(name) COMMENT "普通索引";
# 删除普通索引
DROP INDEX idx_name ON userinfo;
# 在已存在的表上创建索引02,创建普通索引
# 如果是INDEX类型索引,则不用指明索引类型
ALTER TABLE userInfo ADD
INDEX idx_name(name) COMMENT "普通索引";
# 删除普通索引
DROP INDEX idx_name ON userinfo;
# 在已存在的表上创建索引02,创建唯一索引
# 非INDEX类型索引,需指明索引类型
ALTER TABLE userInfo ADD
UNIQUE INDEX unique_index_name(name) COMMENT "唯一索引";
索引名词
索引结构
如果想更加深刻的了解索引,则需要更底层的认识索引的结构。
你可以将聚集索引与辅助索引想象成两张索引表。
对于聚集索引来说,它直接包含索引字段(主键)的值与其他一整行记录字段的值。
对于辅助索引来说,它仅仅包含索引字段的值与聚集索引的主键值。

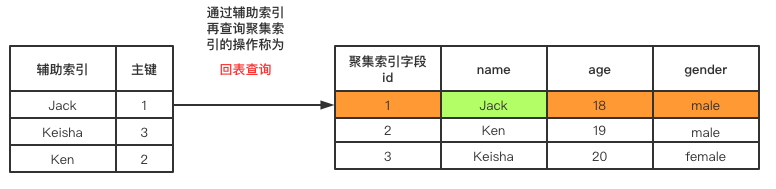
回表查询
使用辅助索引进行查询时,如果SELECT需要的字段并未存在于辅助索引中,则会根据辅助索引中存储的主键值使用聚集索引再查询一次。这个过程叫做回表查询。
回表查询的效率虽然比直接查询聚集索引低,但是比不走索引查询效率高。
如下所示,以下查询语句会执行回表查询:
SELECT age FROM userInfo WHERE name = "Jack";
# 1.查询到Jack的辅助索引,由于辅助索引只存当前索引列与聚集索引字段的值所以拿不到age
# 2.通过辅助索引中的聚集索引字段值,进行聚集索引查询、聚集索引中包含一整行记录,所以能拿到age
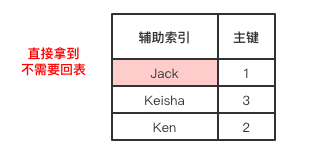
覆盖索引
通过辅助索引进行查询时,如果SELECT需要的字段正好存在于辅助索引中,则不必再进行回表查询,如下所示:
SELECT name FROM userInfo WHERE name = "Jack";
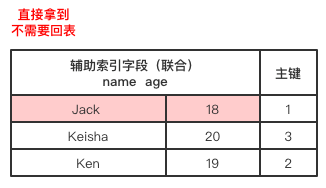
如果(name,age)字段为联合索引,则下面这种查询也属于覆盖索引:
SELECT name,age FROM userInfo WHERE name = "Jack";
SELECT name,age FROM userInfo WHERE age = 18;
如果查询条件是主键,则必定是覆盖索引,因为会直接走聚集索引进行查询。
索引合并
使用多个辅助索引(单列,非联合)进行查询时,被称之为索引合并。
索引合并的查询速度小于联合索引,并且不会有最左前缀匹配的限制:
SELECT * FROM userInfo WHERE name = "Jack" AND age > 17;
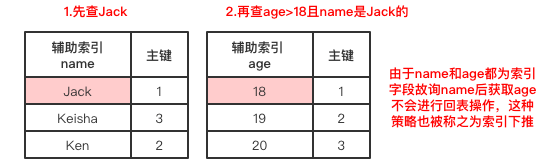
最左前缀匹配特性
这个主要是在联合索引中体现,如下所示,(name,age)字段为联合索引,必须从左边查询才会走索引:
SELECT * FROM userInfo WHERE name = "Jack" AND age > 18;
# 联合索引是name在前,age在后
# 查询条件name在前,age在后,走索引
如果向下面这种情况,就不会走索引:
SELECT * FROM userInfo WHERE age > 18 AND name = "Jack";
# 联合索引是name在前,age在后
# 查询条件age在前,name在后,不走索引
如果联合索引中都是使用=作为查询条件,则最左前缀匹配特性失效:
SELECT * FROM userInfo WHERE age = 18 AND name = "Jack";
短索引
如果一个字段中,前缀或者后缀都相同的情况下,如:
name CHAR(64)
user01203023
user92392023
user92328823
user02388322
将整条记录完整的做索引显然很浪费空间,只从第四个字符开始向后做索引是最明智的选择,这种索引被称之为短索引。
创建或修改短索引,详见创建索引中的语法。
正确编写SQL语句
索引未命中
以下的查询都会造成索引未命中的情况:
- 使用
LIKE进行模糊查询,且%在前面时,则会造成索引未命中:
SELECT * FROM userInfo WHERE name LIKE "%ya";
- 使用函数进行查询,则会造成索引未命中:
SELECT * FROM userInfo WHERE REVERSE(name) = "ayuny"
- 使用
OR进行查询时,如果OR的两方有任何一方未建立索引,则会造成索引未命中:
SELECT * FROM userInfo WHERE id = 1 OR gender = "male";
# gender未建立索引
- 条件类型不一致,如
name是字符串类型,而查找时未加引号,则会造成索引未命中:
# 不走索引
SELECT * FROM userInfo WHERE name = 1234;
# 走索引
SELECT * FROM userInfo WHERE name = "1234";
- 使用
!=时,不会走索引,主键除外:
# 不走索引
SELECT * FROM userInfo WHERE name != "yunya";
# 走索引
SELECT * FROM userInfo WHERE id != 1;
- 使用
>时,如果不是主键或者索引不是整数类型,则不会走索引:
# 不走索引
SELECT * FROM userInfo WHERE name > "yunya";
# 走索引,id为主键索引
SELECT * FROM userInfo WHERE id > 10;
# 走索引,age为普通索引,且是整数类型
SELECT * FROM userInfo WHERE age > 10;
- 使用
ORDER BY排序时,选择的排序字段如果不是索引,则不走索引,此外,如果是按照主键排序,则走索引:
# 不走索引,gender不是索引列
SELECT gender,CONCAT(name) FROM userInfo ORDER BY gender DESC;
# 走索引,id是主键
SELECT * FROM userInfo ORDER BY id DESC;
SQL编写建议
- 避免使用
SELECT *进行查询,如果要使用,请加上LIMIT N - 使用
COUNT(id)来代替COUNT(*) - 创建表时尽量使用
CHAR类型来代替VARCHAR类型 - 表的字段顺序固定长度优先
- 在经常使用多条件查询时,使用组合索引代替多个单列索引
- 合理的使用短索引,前缀索引
- 使用连接查询来代替子查询
- 连表查询时注意条件类型需一致
- 索引散列值少的不适合建立索引,如性别
- 查询一条数据时,使用
LIMIT 1来结尾,否则会查询整张表 - 对于特定的查询语句,使用
UNION来代替多个OR的查询语句

 浙公网安备 33010602011771号
浙公网安备 33010602011771号