Python线程池与进程池
前言
前面我们已经将线程并发编程与进程并行编程全部摸了个透,其实我第一次学习他们的时候感觉非常困难甚至是吃力。因为概念实在是太多了,各种锁,数据共享同步,各种方法等等让人十分头痛。所以这边要告诉你一个好消息,前面的所有学习的知识点其实都是为本章知识点做铺垫,在学习了本章节的内容后关于如何使用多线程并发与多进程并行就采取本章节中介绍的方式即可。
这里要介绍一点与之前内容不同的地方,即如果使用队列进行由进程池创建的进程之间数据共享的话不管是multiprocessing模块下的Queue还是queue模块下的Queue都不能为进程池中所创建的进程进行数据共享,我们需要用到另一个队列即multiprocessing.Manager()中的Queue。当然这个我也会在下面介绍到。那么开始学习吧!
执行器
最早期的Python2中是没有线程池这一概念的,只有进程池。直到Python3的出现才引入了线程池,其实关于他们的使用都是非常简单,而且接口也是高度统一甚至说一模一样的。而线程池与进程池的作用即是为了让我们能够更加便捷的管理线程或进程。
我们先说一下,如果需要使用线程池或进程池,需要导入模块concurrent.futures。
from concurrent.futures import ThreadPoolExecutor# 线程池执行器
from concurrent.futures import ProcessPoolExecutor# 进程池执行器
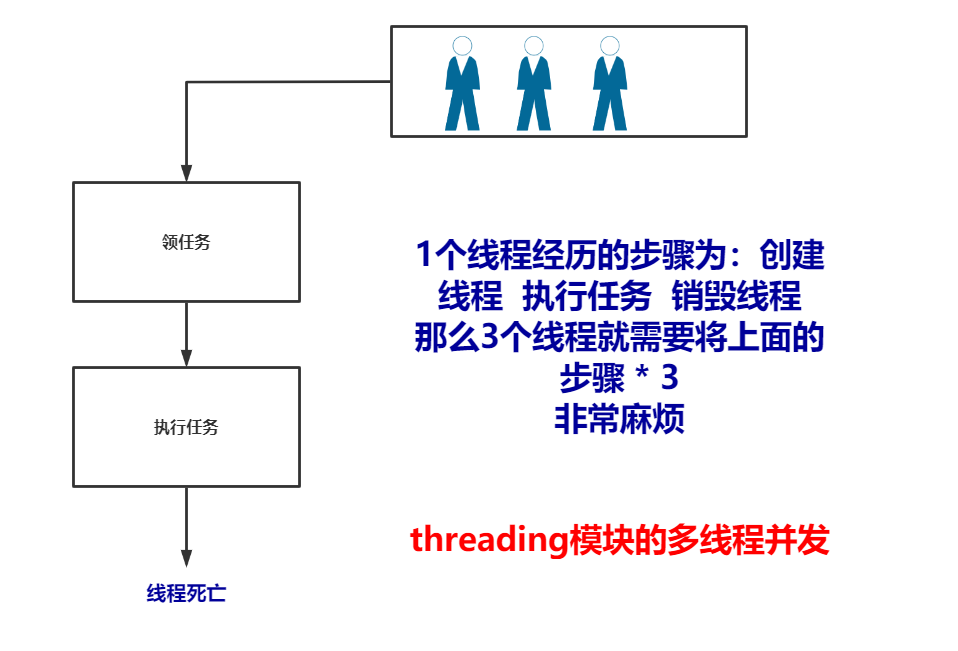
这里介绍一下,关于线程池或者进程池创建出的线程与进程与我们使用multiprocessing模块或者threading模块中创建的线程或进程有什么区别。我们以多线程为例:
import threading def task(): ident = threading.get_ident() print(ident) # 销毁当前执行任务的线程 if __name__ == '__main__': for i in range(10): t1 = threading.Thread(target=task,) # 领任务 t1.start() # 等待CPU调度,而不是立即执行 # 执行 # ==== 执行结果 ==== Ps:可以看到每个线程的id号都不一样,这也印证了图上说的。 """ 10392 12068 5708 13864 2604 7196 7324 9728 9664 472 """
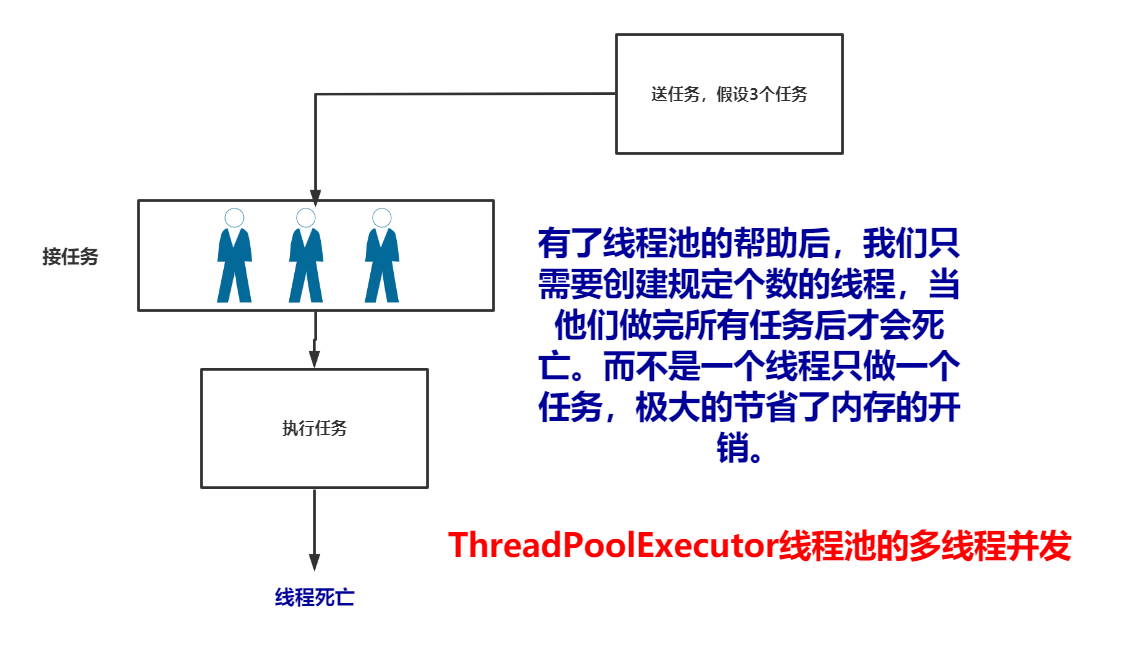
import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(): ident = threading.get_ident() print(ident) # 结束任务,不销毁当前执行任务的线程,直到所有任务都执行完毕。 if __name__ == '__main__': pool = ThreadPoolExecutor(max_workers=2) # 这里代表有2个线程可以领取任务 for i in range(10): pool.submit(task) # 执行器启动任务,将这些任务给2个人分配,也就是说task这个任务会被这2个线程不断的执行,直到执行完毕后这2个线程才会死亡 # ==== 执行结果 ==== Ps:可以看到这里都让这2个线程把任务接了,内存开销相比于上面的要小。 """ 7272 7272 7272 7272 11596 7272 11596 11596 11596 11596 """
方法大全
| 执行器方法大全 | |
|---|---|
| submit(fn, *args, **kwargs) | 调度可调用对象 fn,以 fn(*args **kwargs) 方式执行并返回 |
| map(func, *iterables, timeout=None, chunksize=1) | 类似于 |
| shutdown(wait=True) | 等待,类似join()方法,并且在所有的任务完成后关闭执行器。wait=True为关闭,为False则是不关闭执行器的意思。 |
| Ps:其实对于线程池或进程池来说,他们的池都有一个官方的名称叫做执行器,接口都是一样的。那么接下来我就将线程池进程池这样的名字换做执行器了,也是方便理解。 | |
基本使用
其实关于执行器的使用,我们有两种方式,一种是依赖于with语句,一种是不依赖于with语句,那么我在这里推荐使用依赖于wait语句的执行器。
不依赖于with语句的执行器使用:
import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(): print("执行了") if __name__ == '__main__': pool = ThreadPoolExecutor(max_workers=2) # 这里代表有2个线程可以领取任务 , 对于线程池来讲它是默认值是CPU核心数+4,对于进程池来讲最大开启的进程数是CPU核心数。 for i in range(10): pool.submit(task) # 执行器启动任务,将这些任务给2个人分配,也就是说task这个任务会被这2个线程不断的执行,直到执行完毕后这2个线程才会死亡 # ==== 执行结果 ==== Ps:可以看到这里都让这2个线程把任务接了,内存开销相比于上面的要小。 """ 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 """
依赖于with语句的执行器使用:
import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(): print("执行了") # 销毁 if __name__ == '__main__': with ThreadPoolExecutor(max_workers=2) as pool: # 这里代表有2个线程可以领取任务 , 对于线程池来讲它是默认值是CPU核心数+4,对于进程池来讲最大开启的进程数是CPU核心数。 for i in range(10): pool.submit(task) # 执行器启动任务,将这些任务给2个人分配,也就是说task这个任务会被这2个线程不断的执行,直到执行完毕后这2个线程才会死亡 # ==== 执行结果 ==== Ps:可以看到这里都让这2个线程把任务接了,内存开销相比于上面的要小。 """ 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 执行了 """
期程对象
方法大全
| 期程对象(由执行器执行的任务的返回结果)方法大全 | |
|---|---|
| 方法/属性名称 | 功能描述 |
| cancel() | 尝试取消调用。 如果调用正在执行或已结束运行不能被取消则该方法将返回 False,否则调用会被取消并且该方法将返回 True。 |
| cancelled() | 如果调用成功取消返回 True。 |
| running() | 如果调用正在执行而且不能被取消那么返回 True 。 |
| done() | 如果调用已被取消或正常结束那么返回 True。 |
| result(timeout=None) | 即获取任务的返回结果,最大等待timeout秒,如不设置则死等,超时触发CancelledError异常。 |
| add_done_callback(fn) | 增加回调函数fn,这个fn应该至少有一个形参来接收当前期程对象。 |
| exception(timeout=None) | 返回由调用引发的异常。如果调用还没完成那么这个方法将等待 timeout 秒。如果在 timeout 秒内没有执行完成,concurrent.futures.TimeoutError将会被触发。timeout 可以是整数或浮点数。如果 timeout 没有指定或为 None,那么等待时间就没有限制。 |
| Ps:还有一些期程对象的方法没有举例出来。详情参见文档 | |
期程对象的作用
我们可以看到,我们上面的函数并没有返回值,如果有返回值的话怎么办呢?
import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(): print("执行了") return "玫瑰花" # 销毁 if __name__ == '__main__': with ThreadPoolExecutor(max_workers=2) as pool: res = pool.submit(task) print(res) # <Future at 0x2539ea97850 state=finished returned str> 这个就是期程对象,可以看到他里面还有当前任务的执行状态。 finished = 执行完了的意思 print(res.result()) # 通过该方法就可以拿到任务的返回结果 # ==== 执行结果 ==== """ 执行了 <Future at 0x2539ea97850 state=finished returned str> 玫瑰花 """
期程对象,也被称为未来对象,是一个非常重要的概念。这里可以记一笔,在Django框架中也有些地方采取了期程对象这样的设定,这是后话,后面再聊。
期程对象如何获取返回结果
我们尝试着将它的任务数量增多,发现使用期程对象直接获取任务结果会导致阻塞,怎么解决?
import time import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(x): print("执行了,这是第%s个任务"%x) time.sleep(3) return "玫瑰花" # 销毁 if __name__ == '__main__': with ThreadPoolExecutor(max_workers=2) as pool: for i in range(10): res = pool.submit(task,i) print(res.result()) # 每次获取结果的时候都是阻塞,怎么办?这个速率就变得非常的Low逼了。 # ==== 执行结果 ==== """ 执行了,这是第0个任务 玫瑰花 执行了,这是第1个任务 玫瑰花 执行了,这是第2个任务 玫瑰花 执行了,这是第3个任务 玫瑰花 执行了,这是第4个任务 玫瑰花 执行了,这是第5个任务 玫瑰花 执行了,这是第6个任务 玫瑰花 执行了,这是第7个任务 玫瑰花 执行了,这是第8个任务 玫瑰花 执行了,这是第9个任务 玫瑰花 """
我这里有一个办法,可以值得尝试一下。就是执行器本身有个方法shutdown(wait=True),它会导致当前主线程的阻塞。那么我们就可以这样操作,主程序阻塞住,再将启程对象全部放到一个列表中,当所有任务处理完毕后阻塞通行,这个时候我们再循环这个列表拿出其中的结果。
import time import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(x): print("执行了,这是第%s个任务"%x) time.sleep(3) return "玫瑰花" # 销毁 if __name__ == '__main__': res_list = [] # 用于存放所有期程对象 with ThreadPoolExecutor(max_workers=2) as pool: for i in range(10): res = pool.submit(task,i) res_list.append(res) # 将期程对象放入列表 pool.shutdown(wait=True) # 代表必须将所有子线程的任务跑完再继续向下执行主线程。 for i in res_list: print(i.result()) # ==== 执行结果 ==== """ 执行了,这是第0个任务 执行了,这是第1个任务 执行了,这是第2个任务 执行了,这是第3个任务 执行了,这是第4个任务 执行了,这是第5个任务 执行了,这是第6个任务 执行了,这是第7个任务 执行了,这是第8个任务 执行了,这是第9个任务 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 玫瑰花 """
如果你觉得这种方法很赞,我只能送你两个字,太low了。我们注意执行器的submit()方法,这玩意儿是异步提交。异步提交的结果需要用到回调函数来进行调用,我们来看一下它有多牛逼。
回调函数
import time import threading from concurrent.futures import ThreadPoolExecutor # 线程池执行器 def task(x): print("执行了,这是第%s个任务"%x) time.sleep(3) return "玫瑰花" # 销毁 def callback(res): # 必须有一个形参,来接收期程对象 print(res.result()) # 打印结果,即task任务的返回结果 if __name__ == '__main__': with ThreadPoolExecutor(max_workers=2) as pool: for i in range(10): res = pool.submit(task,i) res.add_done_callback(callback) # <--- 增加回调函数,当期程对象中的任务处理状态完毕后将自动调用回调函数 # ==== 执行结果 ==== # 异步提交牛逼不?只要任务返回了我们立马就可以获取到结果进行处理。 """ 执行了,这是第0个任务 执行了,这是第1个任务 玫瑰花 玫瑰花 执行了,这是第2个任务 执行了,这是第3个任务 玫瑰花 玫瑰花 执行了,这是第4个任务 执行了,这是第5个任务 玫瑰花 玫瑰花 执行了,这是第6个任务 执行了,这是第7个任务 玫瑰花 玫瑰花 执行了,这是第8个任务 执行了,这是第9个任务 玫瑰花 玫瑰花 """
扩展:进程池执行器任务数据共享
当我们使用进程池执行器启动多进程执行任务时,如果想用数据共享,单纯multiprocessing.Queue进程队列并不支持。
import multiprocessing from concurrent.futures import ProcessPoolExecutor # 进程池执行器 def task_1(q): q.put("玫瑰花") print("放完了...") def task_2(q): print(q.get()) print("取到了") if __name__ == '__main__': q = multiprocessing.Queue() with ProcessPoolExecutor(max_workers=2) as pool: pool.submit(task_1,q) pool.submit(task_2,q) # ==== 执行结果 ==== # 阻塞住 """ """
这个时候我们需要用到multiprocessing中的Manager()中的Queue。
from multiprocessing import Manager from concurrent.futures import ProcessPoolExecutor # 进程池执行器 def task_1(q): q.put("玫瑰花") print("放完了...") def task_2(q): print(q.get()) print("取到了") if __name__ == '__main__': q = Manager().Queue() with ProcessPoolExecutor(max_workers=2) as pool: pool.submit(task_1,q) pool.submit(task_2,q) # ==== 执行结果 ==== # 成功 """ 放完了... 玫瑰花 取到了 """

