函数的递归调用
什么是递归
递归是一种函数的调用方式。即:自己调用自己。
# ==== 函数的递归调用 ==== def foo(): print("foo...") foo() foo()
递归在某些特定的场景下使用,但是注意不能重复的无限制的对自身进行调用,这会引发异常。Python中默认最大调用自身的次数为1000次:
RecursionError: maximum recursion depth exceeded while calling a Python object
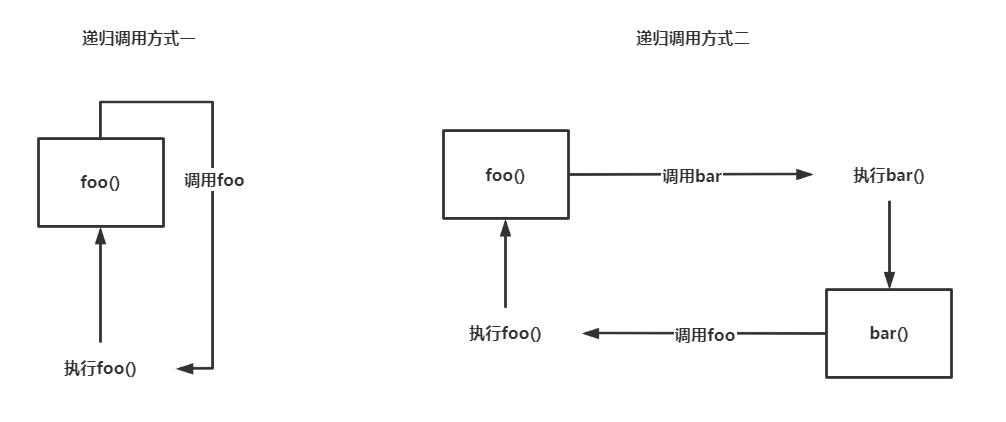
递归调用的两种方式
# ==== 函数的递归调用方式二 ==== def foo(): print("foo...") bar() def bar(): print("bar...") foo() foo()
回溯与递推
函数递归必须经历两个阶段,他们就是回溯与递推阶段。当函数不断递归调用自身时的阶段被称为回溯阶段,当函数退出递归调用时的阶段被称为递推阶段。
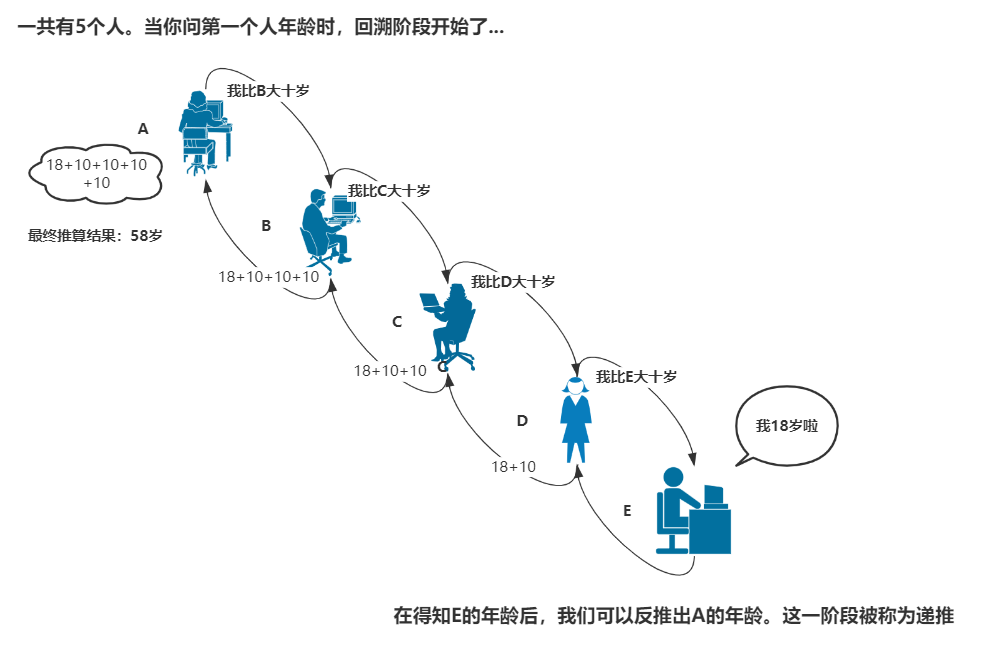
代码表现形式为:
# ==== 回溯与递推案例 ==== def age(n): if n == 1: return 18 return age(n-1) + 10 res = age(5) print(res) # 58
应用场景
著名的汉诺塔游戏:感兴趣的可以搜索一下这个游戏。可以用递归求出游戏结果
这里不举例汉诺塔游戏,而是举了另一个例子,看代码:
# 需求,将下面列表中的每一个值取出来并且进行从小到大的排序。返回一个单维列表 l = [10,1.2,[3,345,2.2,[15,[88.6,[78,[89.3,99,[50]]]]]]] new_l = [] def my_sort(list1): for i in list1: if isinstance(i,list): my_sort(i) else: new_l.append(i) new_l.sort() my_sort(l) print(new_l) # === 执行结果 === """ [1.2, 2.2, 3, 10, 15, 50, 78, 88.6, 89.3, 99, 345] """
扩展:递归与死循环
递归和死循环实际上非常相似。但是Python中的递归效率比循环的效率更低,并且循环能完成的事情递归全部都能完成。
递归与while循环都有共同的特点:必须设置循环体的跳出。
某些情况下,递归比循环更适合解决问题,就如同上面问年龄的这种情况。
扩展:如何修改默认递归层次
import sys print(sys.getrecursionlimit()) # 1000 也是Python默认的最大递归层次 sys.setrecursionlimit(int) # 对于普通的用户来说并不推荐修改该数值。因为这可能导致内存溢出的情况
扩展:尾递归优化
如果读过生成器底层实现那一小结的朋友应该了解到。Python函数在执行时会创建一个栈帧,并且其中f._back所指就是上层函数的栈帧,栈帧会占据极大的内存空间,它包含了当前函数中的局部/全局命名空间的字典,函数字节码等等等等信息。
所谓尾递归优化是指:

