Python三大器之生成器
生成器初识
什么是生成器
生成器本身属于迭代器。继承了迭代器的特性,惰性求值,占用内存空间极小。
为什么要有生成器
我们想使用迭代器本身惰性求值的特点创建出一个可以容纳百万级别的迭代器。(节省内存)又不想通过调用可迭代对象下的
__iter__方法来创建这样的迭代器。(未经过优化的可迭代对象本身就占据内存,如list,tuple,dict,set,str等) 这个时候就需要用到生成器。
怎么用生成器
定义生成器的方式有两种。
1.使用生成器表达式(本章不做介绍)
2.使用生成器函数
斐波拉契数列的创建:
# ==== 使用yield创建生成器 ==== import array # 数组,只能存放单一数据类型。如果要存放同一类型的数据,它比列表更好用 s = array.array("I") def fblq(n): x,y,z = 0,0,1 while x < n: yield y # 相当于return,暂停在此处。再次调用时继续执行下面的代码 y,z=z,y+z x += 1 g = fblq(10) print(g) # 现在的g是一个生成器对象. <generator object fblq at 0x000001F2C6EDE350> for i in g: print(i) # 取出一个,计算一个。 s.append(i) print(s) # array('I', [0, 1, 1, 2, 3, 5, 8, 13, 21, 34])
惰性求值:需要用的时候经过内部计算取出一个。而不是管你目前用不用得到全部给你取出来。
生成器总结
优点
节省内存。不用通过创建一个未经优化的可迭代对象再调用其
__iter__方法创建迭代器。
缺点
由于生成器本身就是属于迭代器。故缺点是只能使用一次,当值全部取出后该生成器对象意味着死亡。 如果生成器要取中间的值,只能通过一个一个的迭代过去。不能直接取出中间的值。
故:Python对于
list,dict等数据类型为何不直接采取引用迭代器的方式呢?这是因为Python考虑到其还有其他的取值方式。如index,key等等取值要比遍历取值更为方便。引用迭代器(经过优化的可迭代对象):
可迭代对象本身并不存储任何值,
for循环该可迭代对象时实际上就是生成一个迭代器,再通过该专属迭代器的__next__方法内部计算出需要的值并且返回。这么做的方式在于不能通过
index取值,但是极大节省内存空间。采用引用迭代器方式的数据类型有很多,比如:keys(),values(),items(),range()。
扩展:生成器与协程
生成器由于具有挂起当前函数状态的特性,所以可以有很多骚操作玩法,也间接的让协程成为可能。我们可以让一个生成器函数做不同的事情,根据不同的情况返回不同的结果。
需要注意,
yield本身具有return返回值的功能。并且还有接收值的功能。
yield返回值所接收的对象将获得两个方法:
send()---> 向yield发送一个任意类型参数。
close()---> 当使用该方法后,将不再具有send()方法。


# ==== 生成器的send与close ==== def dog(): # 等待send(None)或者next(host)执行。 print("dog的绳子被主人拉上了..") a = yield "dog饿了" # 返回值,相当于狗对人说的话。a相当于外部第二次send进来的值 print("dog吃了一坨", a) b = yield "dog渴了" print("dog喝了一口", b) yield "dog吃饱喝足了" host = dog() msg = host.send(None) # 第一次启动必须是None。或者使用next()开始生成器的执行。 print(msg) msg = host.send("冰淇淋") # 对于send来说。内部有几个yield外部就该有几个send print(msg) msg = host.send("82年的雪碧") print(msg) # ==== 执行结果 ==== """ dog的绳子被主人拉上了.. dog饿了 dog吃了一坨 冰淇淋 dog渴了 dog喝了一口 82年的雪碧 dog吃饱喝足了 """
扩展:函数状态挂起底层原理
Python中生成器函数是一个非常牛逼的东西。它可以让函数挂起状态,那么底层到底是怎么实现的呢?
另外推荐深度好文:https://zhuanlan.zhihu.com/p/37109168
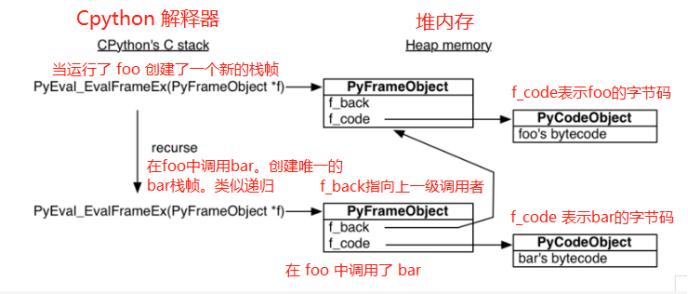
#!/usr/bin/env python # -*- coding:utf-8 -*- # author:love_cat # python的函数是如何工作的 # 比方说我们定义了两个函数 def foo(): bar() def bar(): pass# 首先python解释器(python.exe)会用一个叫做PyEval_EvalFrameEx()的C语言函数去执行foo,所以python的代码是运行在C程序之上的 # 当运行foo函数时,会首先创建一个栈帧(stack frame),表示函数调用栈当中的某一帧,相当于一个上下文,函数要在对应的栈帧上运行。 # 正所谓python一切皆对象,栈帧也是一个对象 # python虽然是解释型语言,但在解释之前也要进行一次预编译,编译成字节码对象,然后在对应的栈帧当中运行 # 关于python的编译过程,我们可以是dis模块查看编译后的字节码是什么样子 import dis print(dis.dis(foo)) # 程序运行结果 ''' 0 LOAD_GLOBAL 0 (bar) CALL_FUNCTION 0 POP_TOP LOAD_CONST 0 (None) RETURN_VALUE None ''' # 首先LOAD_GLOBAL,把bar这个函数给load进来 # 然后CALL_FUNCTION,调用bar函数的字节码 # POP_POP,从栈的顶端把元素打印出来 # LOAD_CONST,我们这里没有return,所以会把None给load进来 # RETURN_VALUE,把None给返回 ''' 以上是字节码的执行过程 '''# 过程就是: ''' 1.先预编译,得到字节码对象 2.python解释器去解释字节码 3.当解释到foo函数的字节码时,会为其创建一个栈帧 4.然后调用C函数PyEval_EvalFrameEx()在foo对应的栈帧上执行foo的字节码,参数就是foo对应的栈帧对象 5.当遇到CALL_FUNCTION,也就是在foo中执行到bar的字节码时,会继续为其创建一个栈帧 6.然后把控制权交给新创建的栈帧对象,在bar对应的栈帧中运行bar的字节码 '''# 我们看到目前已经有两个栈帧了,这不是关键。关键所有的栈帧都分配在堆的内存上,而不是栈的内存上 # 堆内存有一个特点,如果你不去释放,那么它就一直待在那儿。这就决定了栈帧可以独立于调用者存在 # 即便调用者不存在,或者函数退出了也没有关系,因为它始终在内存当中。只要有指针指向它,我们就可以对它进行控制 # 这个特性决定了我们对函数的控制会相当精确。 # 我们可以改写这个函数 # 在此之前,我们要引用一个模块inspect,可以获取栈帧 import inspect frame = None def foo(): bar() def bar(): global frame frame = inspect.currentframe() # 将获取到的栈帧对象赋给全局变量 foo() # 此时函数执行完毕,但是我们依然可以拿到栈帧对象 # 栈帧对象一般有三个属性 # 1.f_back,当前栈帧的上一级栈帧 # 2.f_code,当前栈帧对应的字节码 # 3.f_locals,当前栈帧所用的局部变量 print(frame.f_code) print(frame.f_code.co_name) ''' <code object bar at 0x000000000298C300> bar ''' # 可以看出,打印的是我们bar这个栈帧 # 之前说过,栈帧可以独立于调用方而存在 # 我们也可以拿到foo的栈帧,也就是bar栈帧的上一级栈帧 foo_frame = frame.f_back print(foo_frame.f_code) print(foo_frame.f_code.co_name) ''' <code object foo at 0x000000000239C8A0> foo ''' # 我们依然可以拿到foo的栈帧 # 总结一下:就是有点像递归。遇见新的调用,便创建一个新的栈帧,一层层地创建,然后一层层地返回
这种在函数内调用另一个函数的方式类似于递归,我们可以看一张图:
# 我们之前说了,栈帧是分配在堆内存上的 # 正是因为如此,生成器才有实现的可能 # 我们定义一个生成器 def gen_func(): yield 123 name = "satori" yield 456 age = 18 return "i love satori" # 注意在早期的版本中生成器是不允许有返回值的,但在后来的版本中,允许生成器具有返回值 # python解释之前,也进行预编译,在编译的过程中,发现有yield,就已经被标记为生成器了
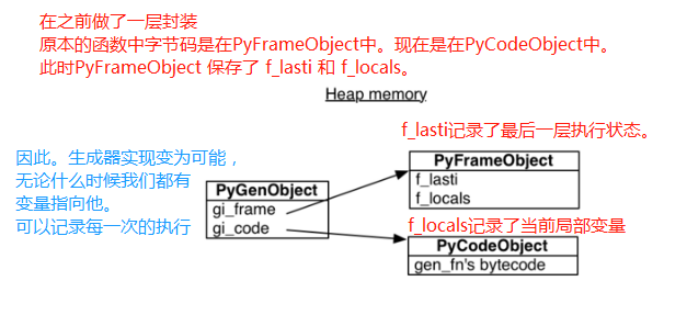
def gen_func(): yield 123 name = "satori" yield 456 age = 18 return "i love satori" import dis gen = gen_func() print(dis.dis(gen)) ''' 0 LOAD_CONST 1 (123) YIELD_VALUE POP_TOP 6 LOAD_CONST 2 ('satori') STORE_FAST 0 (name) 10 LOAD_CONST 3 (456) YIELD_VALUE POP_TOP 16 LOAD_CONST 4 (18) STORE_FAST 1 (age) 20 LOAD_CONST 5 ('i love satori') RETURN_VALUE None ''' # 可以看到,结果中有两个yield,因为我们的函数中有两个yield # 最后的LOAD_CONST后面的('i love satori'),表示我们的返回值 # 最后RETURN_VALUE # 前面的图也解释了,gi_frame的f_lasti会记录最近的一次执行状态,gi_locals会记录当前的局部变量 print(gen.gi_frame.f_lasti) print(gen.gi_frame.f_locals) ''' -1 {} ''' # 我们创建了生成器,但是还没有执行,所以值为-1,当前局部变量也为空 # 我们next一下 next(gen) print(gen.gi_frame.f_lasti) print(gen.gi_frame.f_locals) ''' {} ''' # 我们发现数字是2,所以指向第二行,YIELD_VALUE,yield的值就是123 # 此时局部变量依旧为空 # 继续next,会执行到第二个yield的位置 next(gen) print(gen.gi_frame.f_lasti) print(gen.gi_frame.f_locals) ''' {'name': 'satori'} ''' # 数字是12,所以指向第十二行,第二个YIELD_VALUE,yield的值就是456 # 此时name="satori",被添加到了局部变量当中 # 因此到这里便更容易理解了,为什么生成器可以实现了。 # 因为PyGenObject对函数的暂停和前进,进行了完美的监督,有变量保存我最近一行代码执行到什么位置 # 再通过yield来暂停它,就实现了我们的生成器 # 跟函数一样,我们的生成器对象也是分配在堆内存当中的,可以像函数的栈帧一样,独立于调用者而存在 # 我们可以在任何地方去调用它,只要我们拿到这个栈帧对象,就可以控制它继续往前走 # 正是因为可以在任何地方控制它,才会有了协程这个概念,这是协程能够实现的理论基础 # 因为有了f_lasti,生成器知道下次会在什么地方执行,不像函数,必须要一次性运行完毕 # 以上就是生成器的运行原理
生成器的栈帧与普通函数的栈帧并不相同
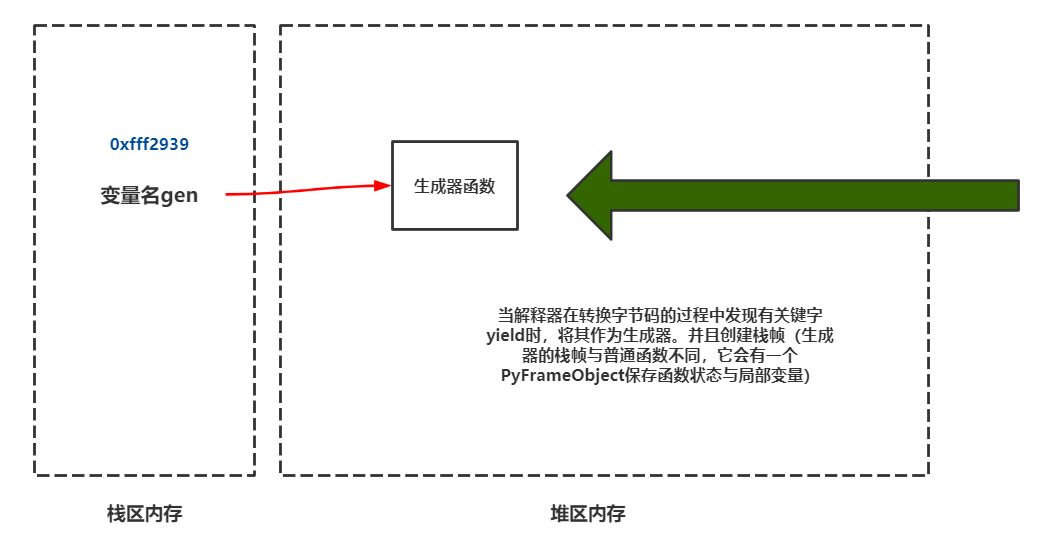
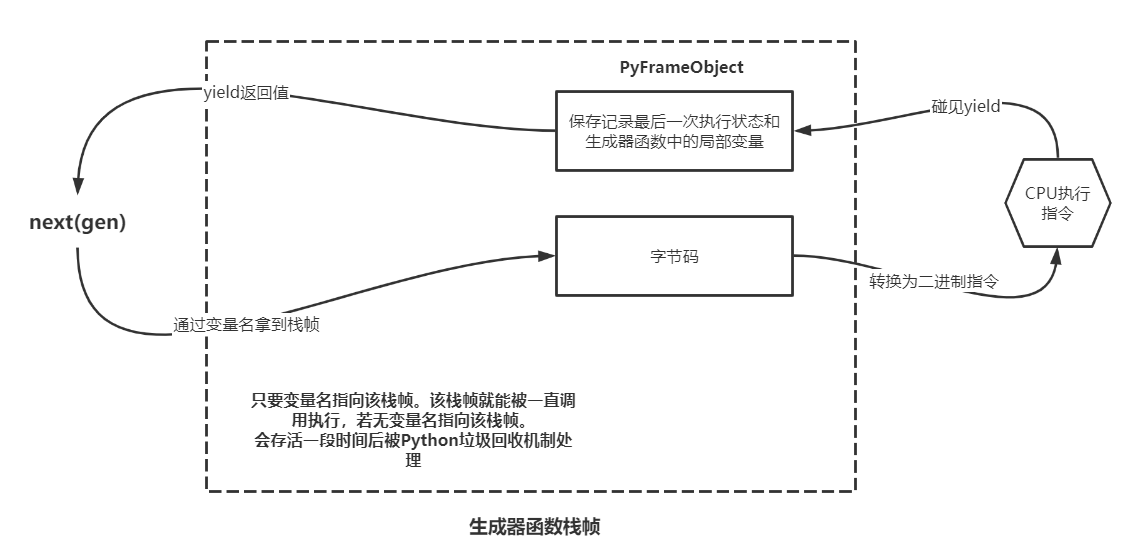
扩展:自定义序列实现迭代器
# ==== 自定义序列实现迭代器 ==== class My_list(object): """为了能让该容器能够多次被循环调用,故做成可迭代对象。 每次for循环为其创建一个专属迭代器。""" def __init__(self,*args): self.args = args def __iter__(self): return My_list_iterator(self.args) class My_list_iterator(object): def __init__(self,args): self.args = args self.index = 0 def __iter__(self): return self def __next__(self): try: return_value = self.args[self.index] except IndexError: raise StopIteration self.index += 1 return return_value if __name__ == "__main__": # for循环原理。 # 1.创建专属迭代器。 # 2.不断执行next方法。 # 3.捕捉StopIteration异常 l = My_list(1,2,3,4,5) l_iterator = iter(l) while True: try: print(next(l_iterator)) except StopIteration: break
注意:即使没有__iter__方法。只要对象具有__getitem__也是可以间接的创建专属迭代器。但是效率偏慢。
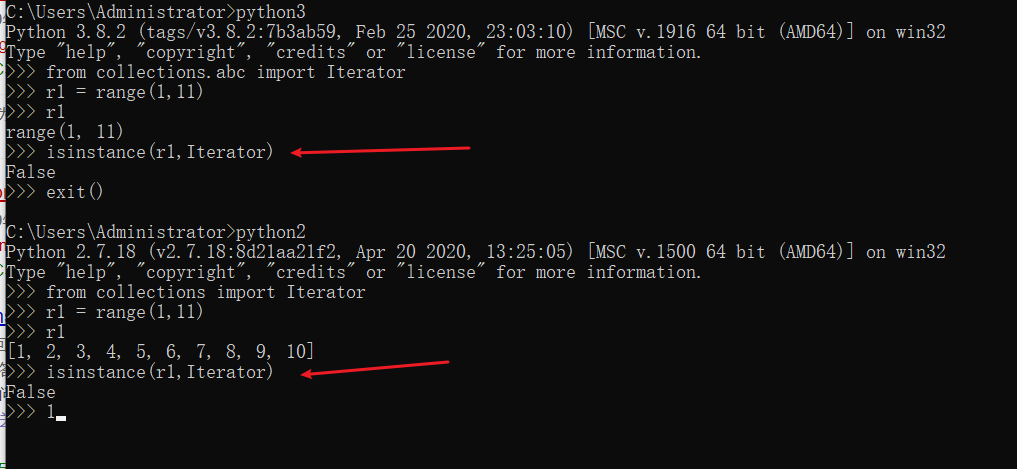
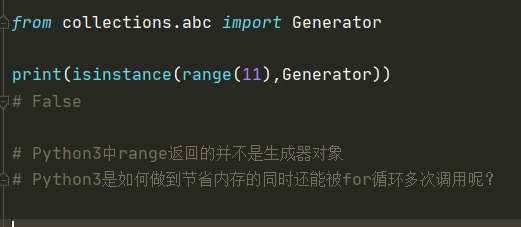
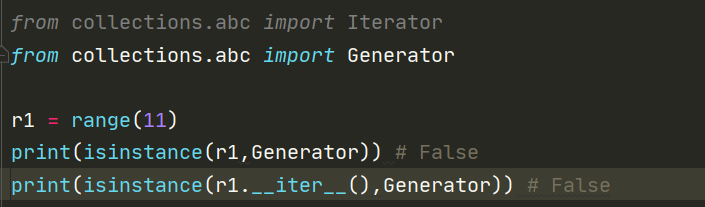
扩展:range()方法的返回值与优化
range()返回的是一个可迭代对象,但是range()这个可迭代对象并不像list那种可迭代对象一样真正占据内存空间。当for循环对其遍历的时候通过range()返回的可迭代对象本身__iter__方法创建出一个专属的迭代器。 然后其专属迭代器中的__next__方法里面是通过计算结束和步长的关系达到惰性求值的效果,range()的__iter__方法创建出的迭代器并不属于生成器范畴但是有着和生成器异曲同工的作用。一句话总结:
range()方法返回的可迭代对象并不存储具体的值,但是要对其进行遍历时创建的专属迭代器是具有惰性求值的特点的。 我将它称为优化后的可迭代对象,注意这个优化只是针对内存空间中的优化。但是它也有不方便的地方,就是不能通过index取值!!!
在此特别感谢武大神!!!
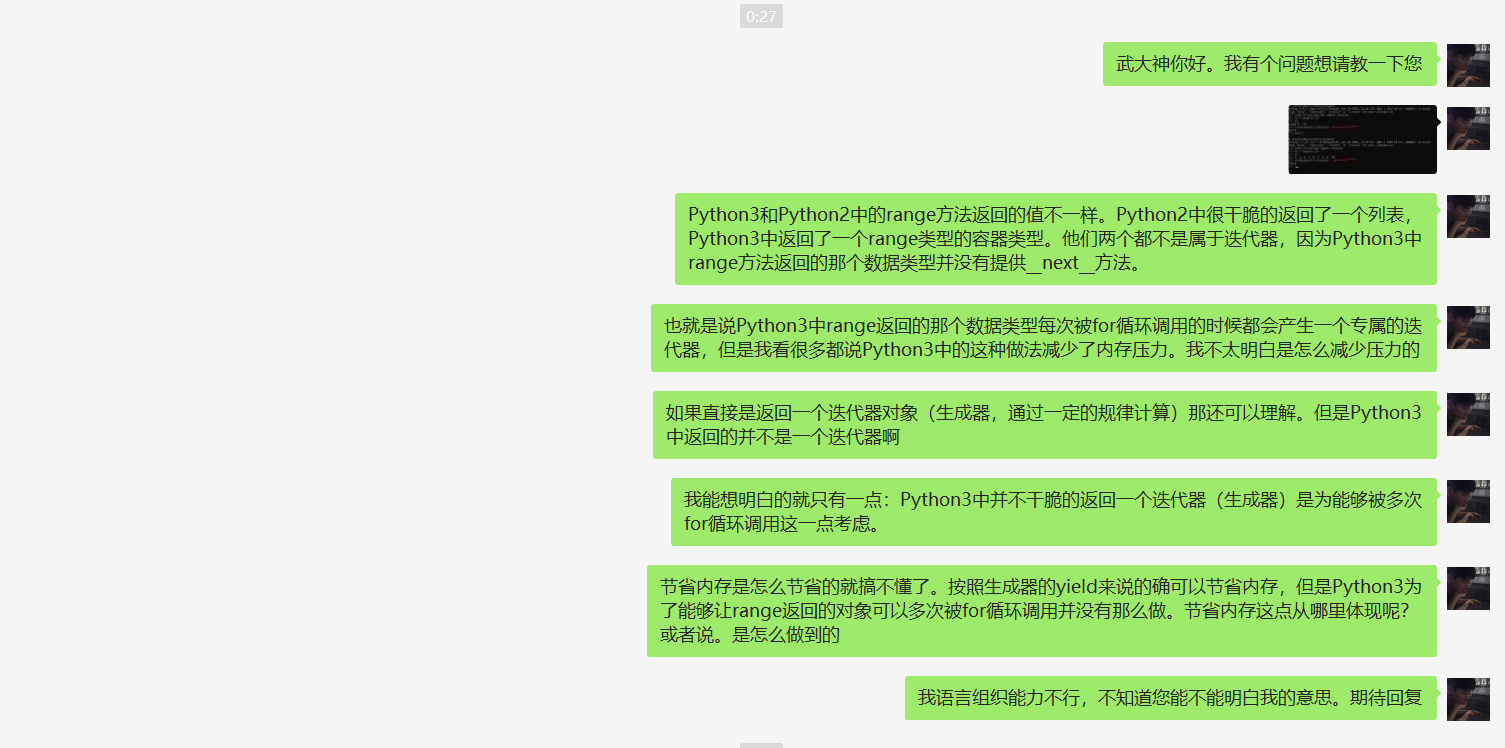

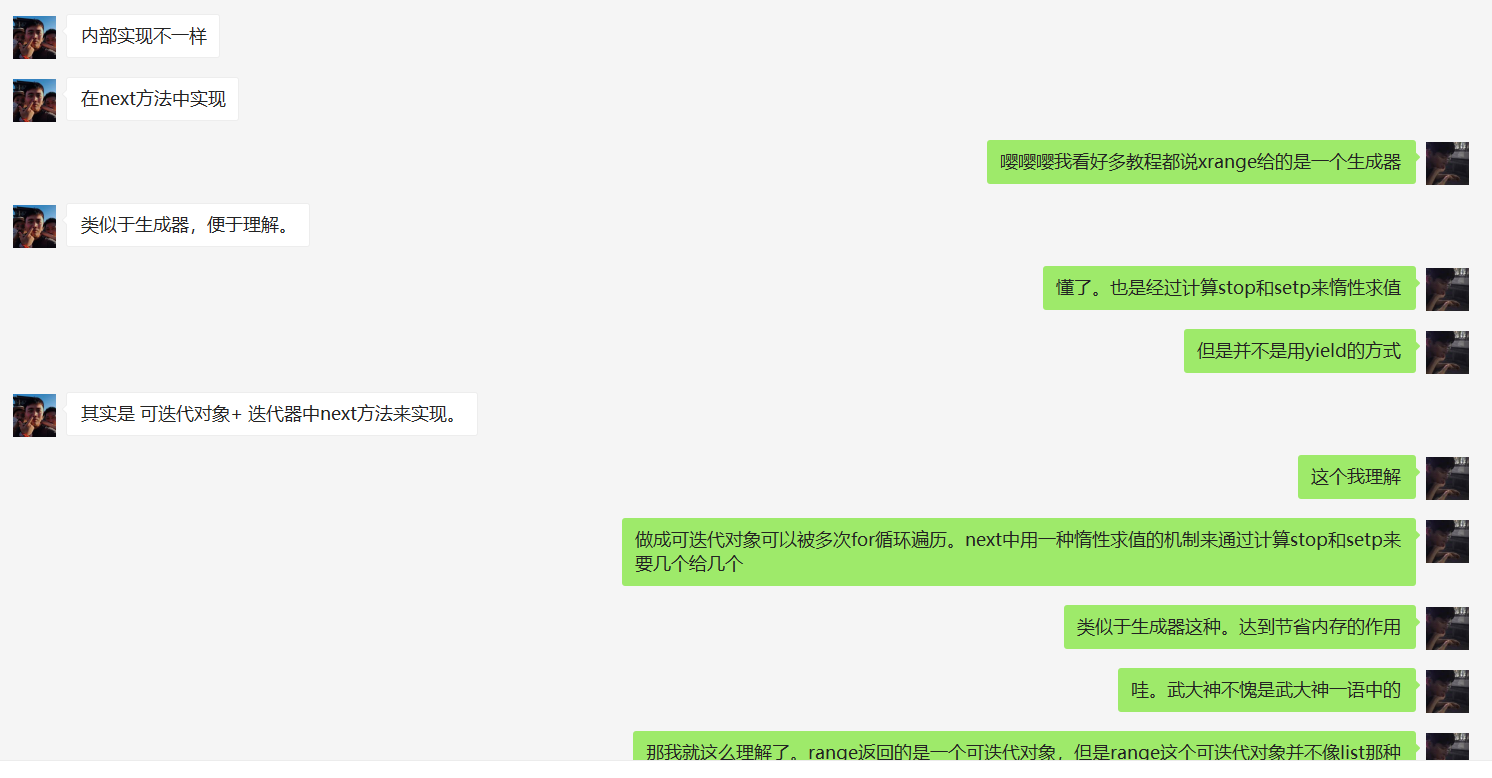

还有!我被武Sir夸了哈哈哈哈哈贴出来炫耀一下可以吹一年!

# 另外附上群中大佬自己写的一个Range # 惰性求值,并且将本身做成了一个可重复调用的迭代器。 # 总结:很强!!! class Range(object): def __init__(self, scale, s=0, d=1): self.s = s # 开始 self.e = scale # 总长度 self.d = d # 步长 def __iter__(self): self.i = self.s # 开始值 return self def __next__(self): if self.i < self.e: x = self.i self.i += self.d return x else: self.i = self.s # self.i = 0 raise StopIteration # 尽管Pyhon3中的range并不是直接返回一个迭代器本身。但是大佬的这种做法 # 依然很厉害,__next__ 中的惰性求值也是和生成器有着异曲同工之妙。而且大佬本身自己就做成了一个可重复使用的迭代器。

