详解Python垃圾回收机制
引入
为什么要有垃圾回收机制
Python中的垃圾回收机制简称(GC
>>> name = "yunya" #yunya 准备改名 >>> name = "yunyaya" #原本yunya这个名字不使用了,现在必须清理掉它否则将会占据内存空间,所幸Python的垃圾回收机制会帮我清理掉 "yunya" >>
堆区和栈区的概念
如果你看我之前写的那篇文章关于Python变量的底层原理的话那么想必对堆区和栈区内存有了一定的了解。如果没有看过那么也没有关系,链接如下:
底层工作原理
引用计数
引用计数说白了就是来对堆区的变量值绑定的栈区变量名来计数。如图:
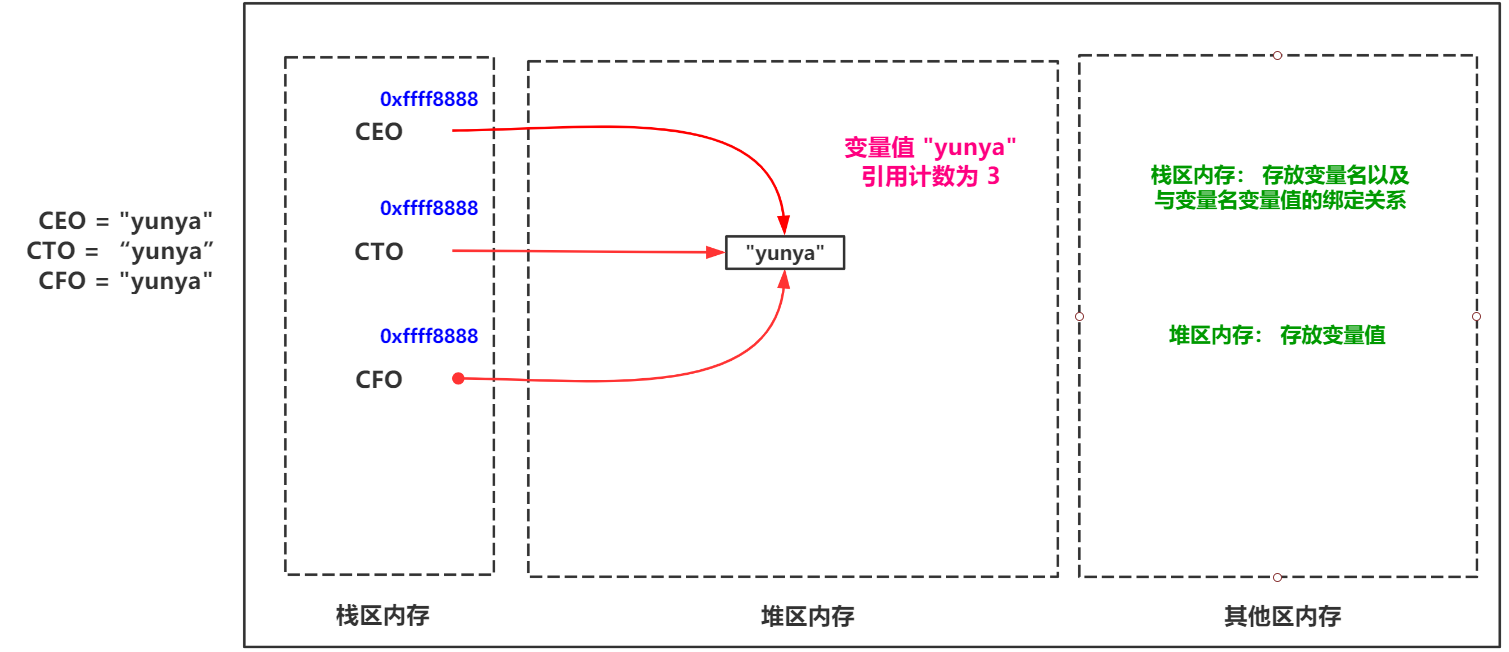
当使用del或者对变量名重新赋值后,该变量值的引用计数就会 -1 。当引用计数为 0 时候下次 Python内存回收机制 进行内存扫描时便会将该变量值当做垃圾进行回收。
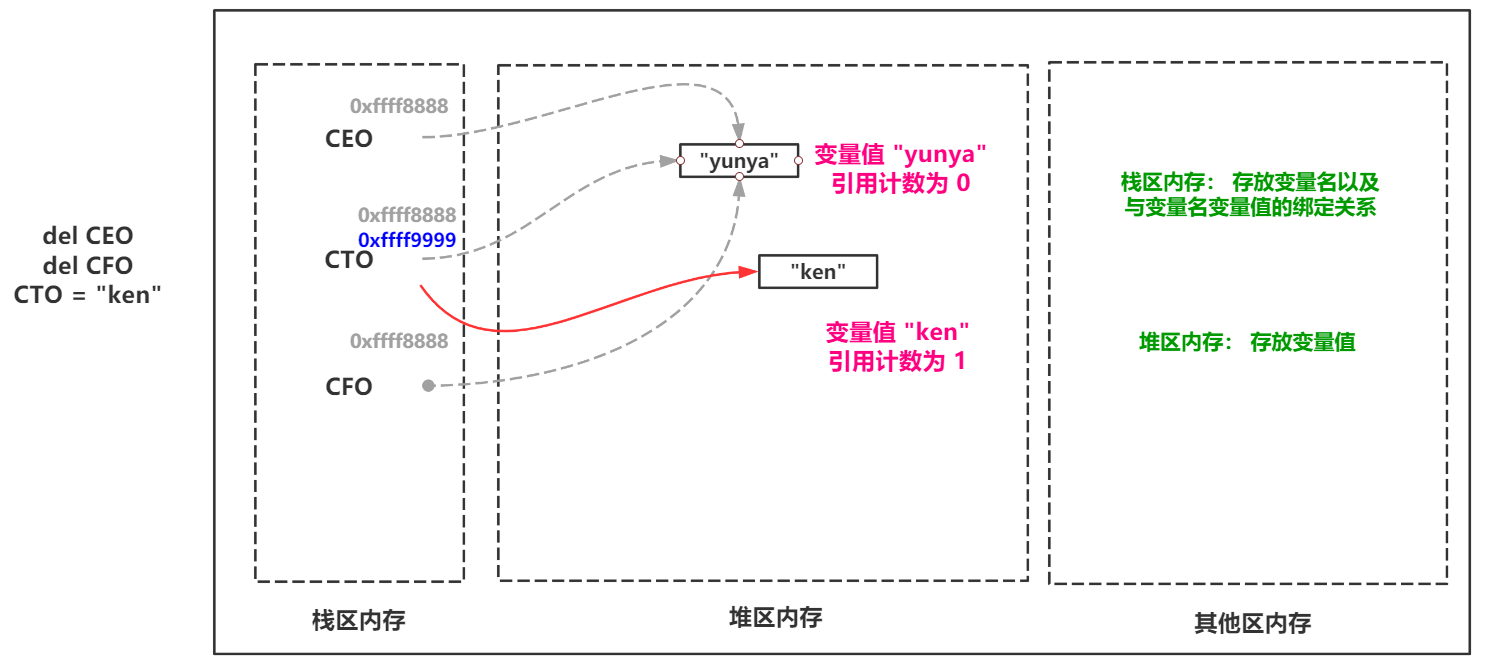
那么这里就是Python内存回收机制中最基本的也最常用的引用计数介绍。
循环引用-内存泄漏
引用计数虽然作为Python内存回收机制中最经常使用的一种机制,但是它本身也是具有一定的缺点。我们来看下面这段代码:
>>> l1 = [1,2,3] >>> l2 = [1,2,3,l1] >>> l1.append(l2) #append()方法用于向列表中添加一个元素值 >>> l1 [1, 2, 3, [1, 2, 3, [...]]] >>> l2 [1, 2, 3, [1, 2, 3, [...]]] >>>
现在l1和l2全部作为互相引用了。那么对于这种引用方式叫做循环引用(也被称为交叉引用),循环引用会带来一个问题:
l1变量值 的引用计数 目前为 2
l2变量值 的引用计数 目前为 2当使用
del l1与del l2后呢?它们的引用变量都减1,但是引用方式的变量名都互相删除了,按理说这些变量值都成了垃圾变量。单根据引用计数是无法清理这些垃圾变量的。
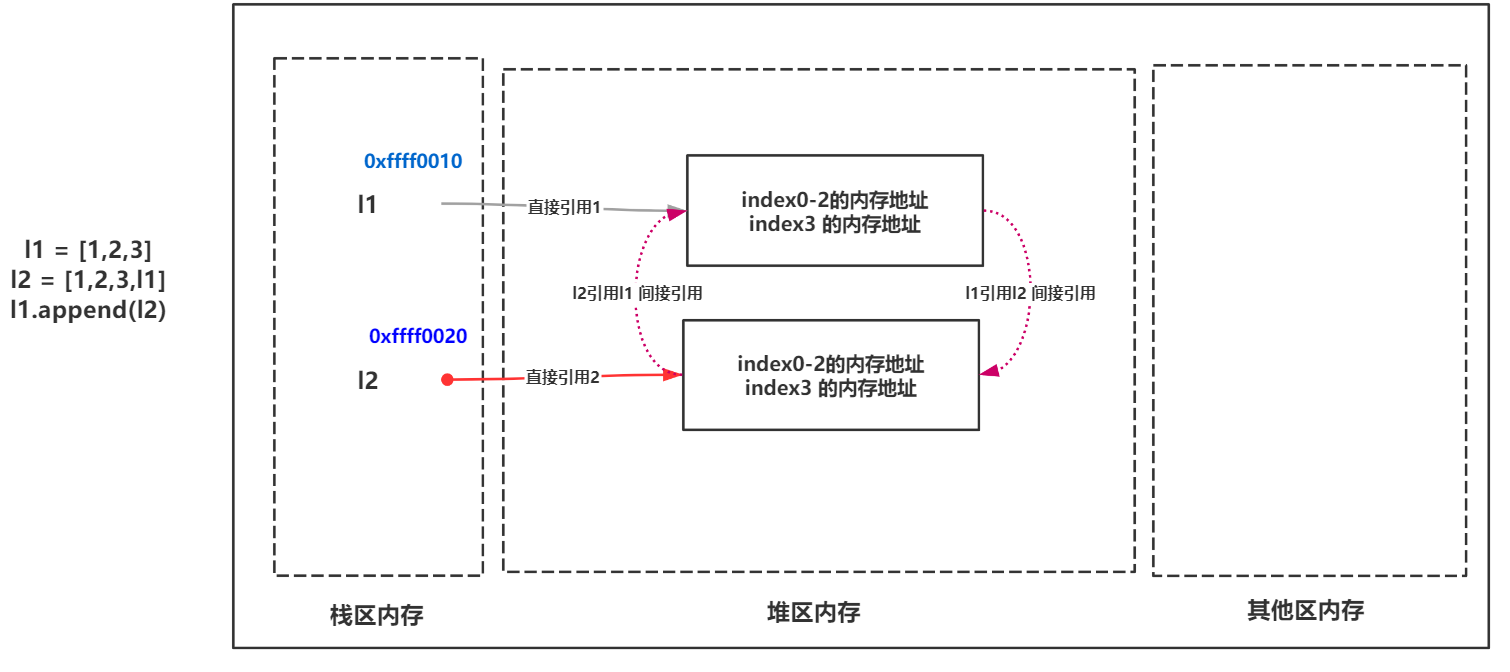
>>> del l1 >>> del l2 >>> #现在怎么访问 li1 或者 li2 呢?访问不到,但是他们的变量值依然存在于内存,引用计数从2变为1
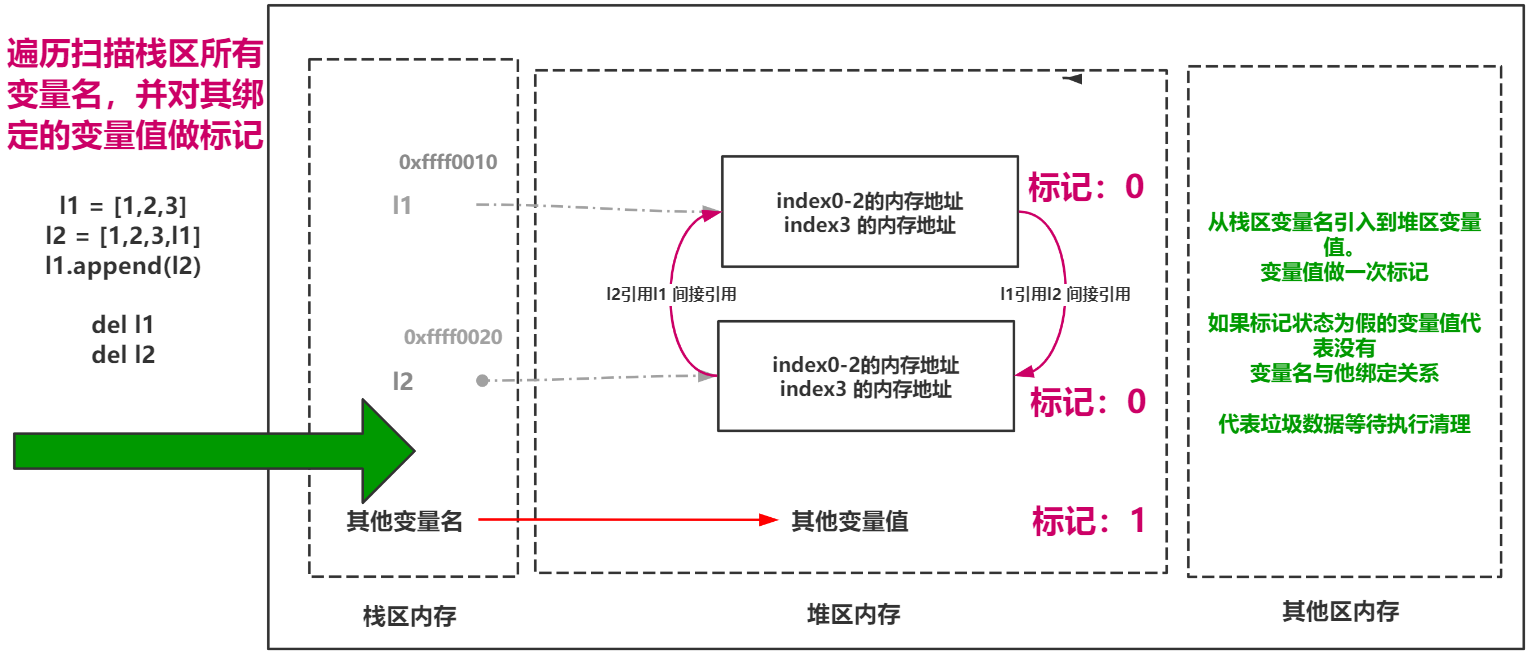
标记-清除
标记清除的意思在于当应用程序可用内存空间即将被耗尽时便开始扫描栈区,并且会顺着栈区变量名对堆区中的变量值做一个标记,如果堆区中存在没有与栈区变量名做对应关系的数据则会被认为是垃圾数据从而被Python垃圾回收机制清理。
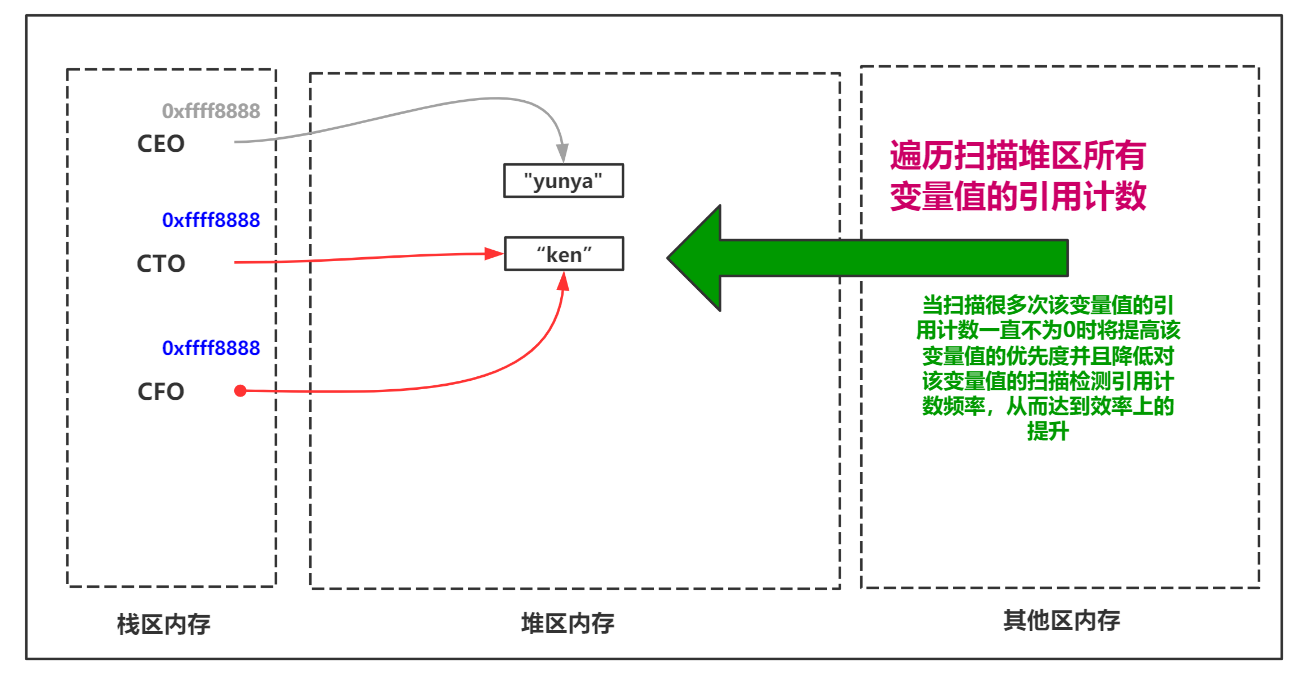
效率问题解决方案-分代回收
基于引用计数的垃圾回收机制每一次执行清理操作前都会将整个堆区的变量值的引用计数做一次遍历统计。这样做是非常消耗时间的,所以Python垃圾回收机制为了效率的提升加入了分代回收的策略。