Python变量与基本数据类型
前言
好了,从本章开始将正式进入Python的学习阶段。本章主要介绍的是Python变量与基本数据类型的认识,这些都是最基本的知识并且必须要牢靠掌握在心中。

注释
学习任何一门语言首要的就是学习它的注释。注释就是说你的脚本程序在运行过程中不会被解释器解释与执行的一部分,它的功能主要是给人阅读方便代码的后期维护。
在Python中(Python2和Python3均可),主要有3种注释方式,其中单行注释1种。多行注释2种:
单行注释:
#多行注释:
"""与'''

我们可以看到。输出结果只有一个 hello,world ,这说明在解释过程中 # 部分 与 ''' 还有 """ 的所有内容并未让解释器解释与执行。
变量
变量的定义与使用
变量就是计算机用来记录事物状态变化过程的东西,这里最主要的一点就是变,它是允许变化的。
首先,绝大部分的编程语言关于变量的定义都分为三部分:
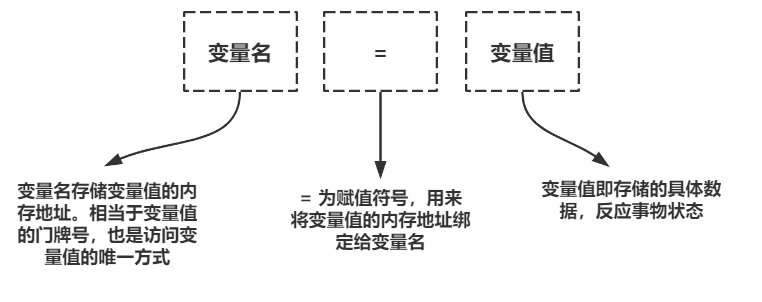
我们来看一看在Python中如何准确的为一个变量赋值(先定义变量,后使用变量)。
>>> name = "yunya" # 记录姓名 >>> age = 18 # 记录年龄 >>> height = 1.92 # 记录身高 >>>
这个就是一个很简单的赋值操作,但是对于底层来说它其实也做了很多的事情
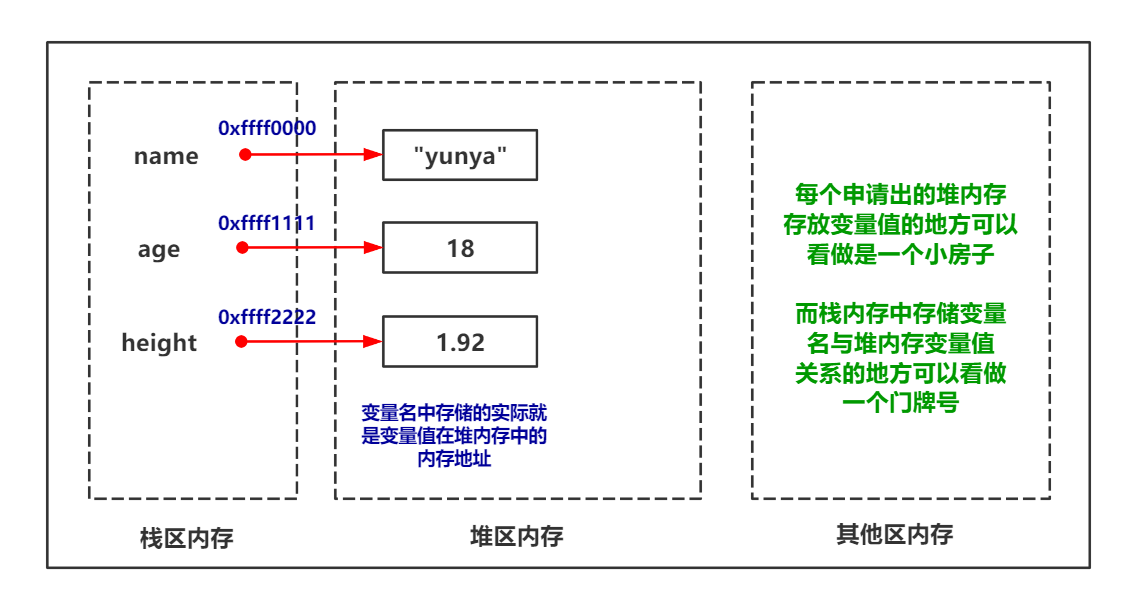
当Python解释器解释到有赋值操作时,会在内存空间(堆内存)中申请一块地方存放该变量值,并且会在内存空间(栈内存)中申请一块地方存放该变量名。再将变量名和变量值的内存地址做一个绑定(不是双向唯一性,而是一对多。一个变量值可以被多个变量名引用,一个变量名只能绑定一个内存地址),这种绑定的关系也存在于栈内存,可以这么理解,变量名存储的并非变量值,而是变量值的内存地址。
这里请记住两个概念,堆内存和栈内存。会在后面的垃圾回收机制中详细介绍。如果难以理解可以尝试看一下图片:
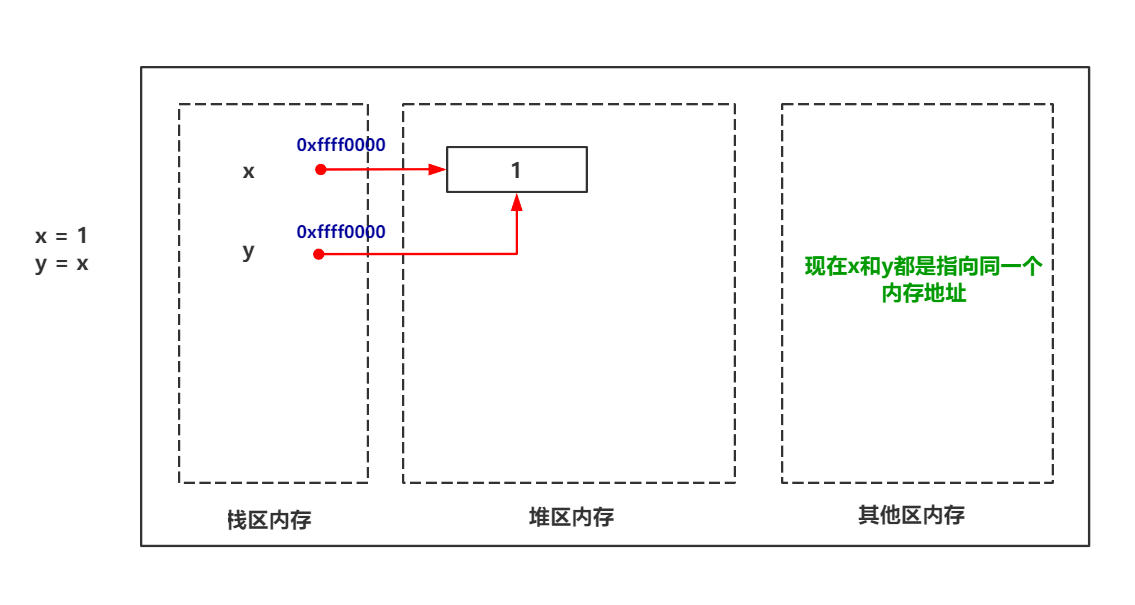
现在介绍一下Python变量赋值的一些基本操作。除开直接赋值。还有交叉赋值,间接赋值(链式赋值)等等,我们这里看一下间接赋值:
>>> x = 1 >>> y = x # x 原本为 1, y通过x也绑定上了1的内存地址,这被称为间接赋值
如何使用一个定义好了的变量呢?方式也很简单。
>>> name = "yunya" #定义变量 >>> age = 18 >>> height = 1.92 >>> >>> >>> x = 1 >>> y = x >>> >>> print(name) #直接引用 yunya >>> print(age) 18 >>> print(height) 1.92 >>> print(x) 1 >>> print(y) #虽然是间接赋值,但是这里还是直接引用,因为y绑定的就是变量值1的内存地址 1 >>>
我们可以看到。当我们打印x的时候是1这个没问题,因为赋值的时候就是赋值成了1.但是打印y的时候依旧是1是为什么呢?因为变量名存储的是变量值的内存地址。所以y中当然也存储的是变量1的内存地址。这个是没问题的。画一张图演示一下:
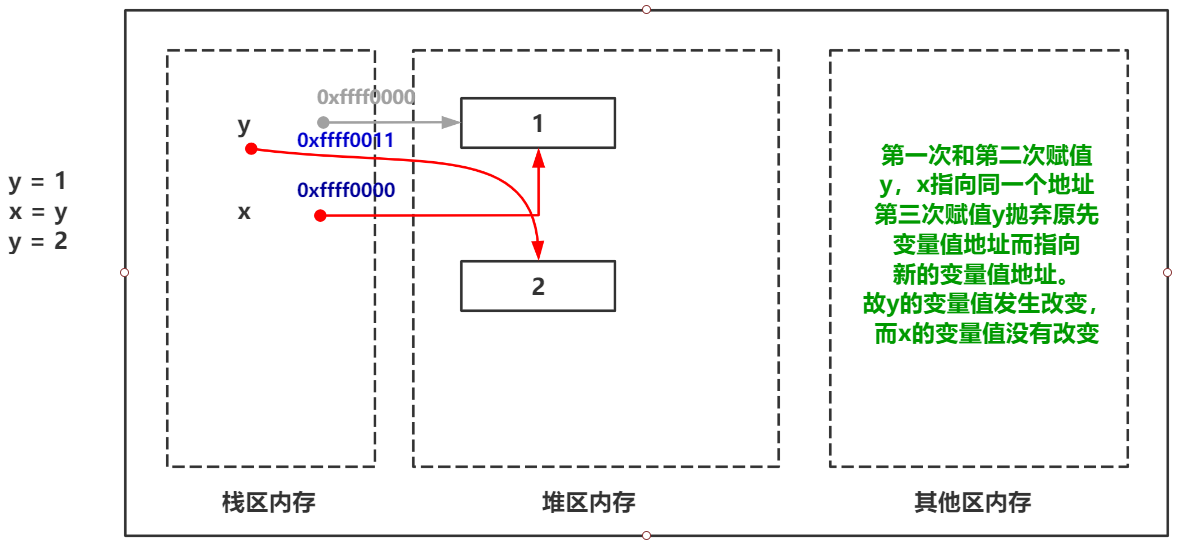
继续来看下一个问题:
>>> y = 1 >>> x = y >>> y = 2 >>> print(x) 1 >>>
为什么y变成了2,打印x却还是1呢?这也是一个常常令新手迷惑的地方,总有人认为这种情况是 x 指向 y 指向的内存地址。并随着 y 的变化而变化 ,但是事实却是 y 的变化并不会影响 x 的内存地址指向。(y第一次指向变量值1并且将y赋值给x,那么x间接也算是指向了变量值1的内存地址,第二次y指向的内存地址发生改变,而x并不会改变指向地址,依旧是指向1的内存地址)
接下来看交叉赋值。
>>> x,y = 1,2 >>> print(x) 1 >>> print(y) 2 >>> x,y = y,x >>> print(x) 2 >>> print(y) 1 >>>
交叉赋值这个应该挺好理解,这里不做多的解释。用文字描述一下就即可:
房间x,房间y中有两个人。他们同时换了两个房间。
那么关于Python变量的基本使用与介绍就讲到这里,最后补充一个关于变量的删除:
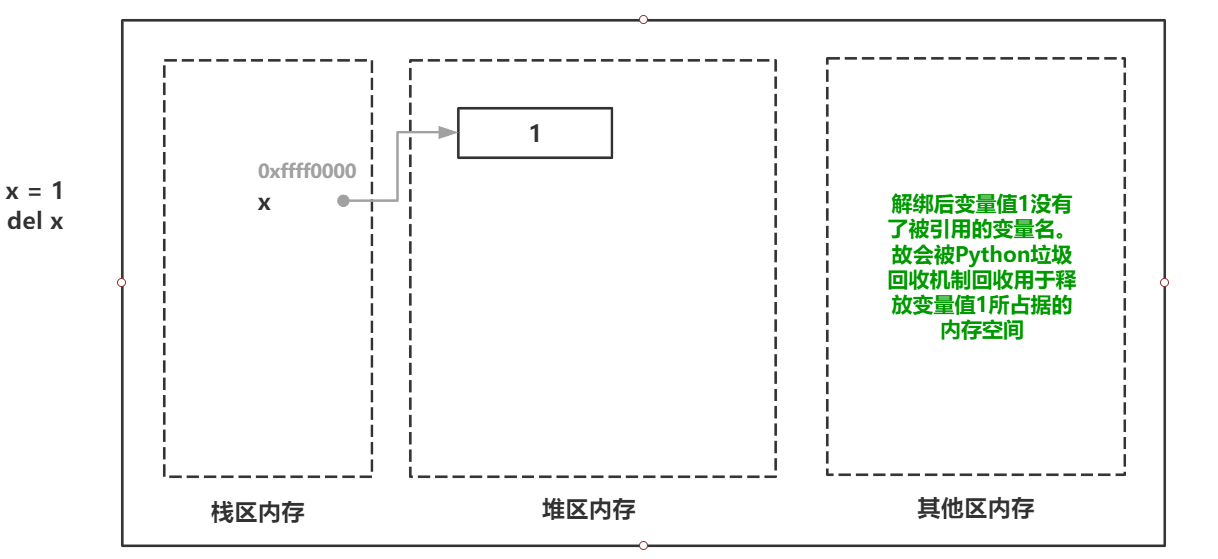
>>> x = 1 >>> del x >>> print(x) Traceback (most recent call last): File "<stdin>", line 1, in <module> NameError: name 'x' is not defined >>>
可以看到当我们使用
del删除 x 的时候实际上是解除了 变量名 x 与变量值 1 的绑定关系,而变量值 1 此时已经没有了绑定关系则会被Python垃圾回收机制所回收用于释放内存,如果使用未与变量值绑定的变量名 x 就会抛出异常。is not defined。关于Python垃圾回收机制接下来会讲到,这里做一个了解即可。重点是del可作用于解除变量名与变量值之间的绑定关系(变量名和关系存在于栈内存,使用del会删除它们)。除此之外我们也可以使用变量名与新的值绑定从而达到与旧值解绑的目的。
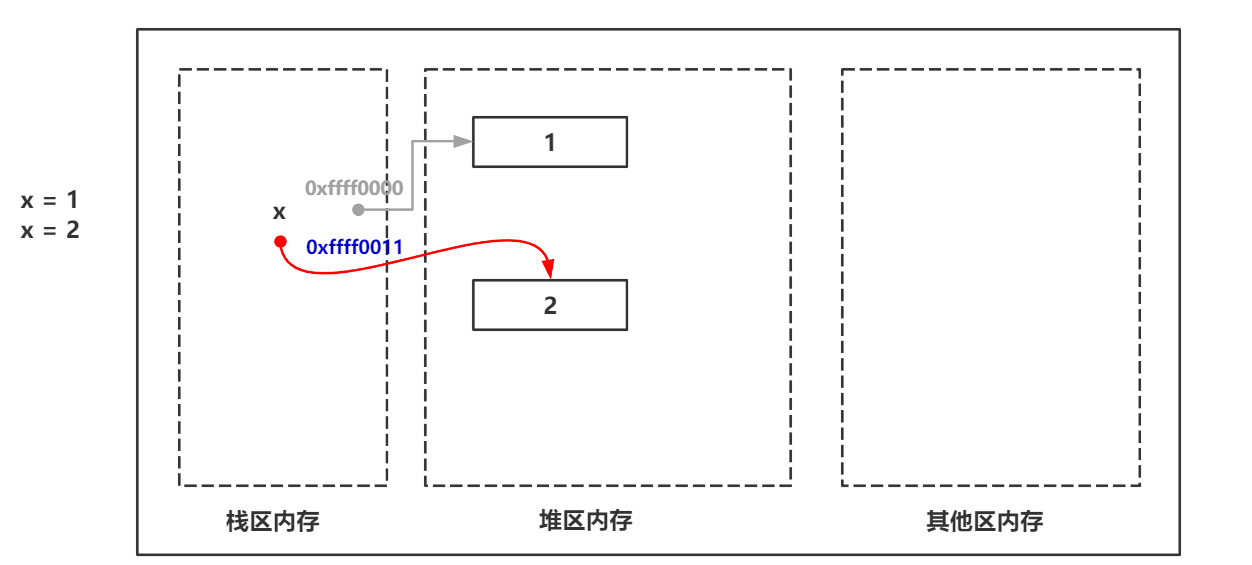
>>> x = 1 >>> print(x) 1 >>> x = 2 # 现在想访问1这个变量值是不可能的,除非用新的变量名来指向变量值1. >>> print(x) 2 >>>
还是画一个图示:
变量命名的规范
上面介绍了变量的使用方式与赋值,那么关于变量的命名方式其实是有一个规范的
变量名应当见名知意
变量名由数字,字母,下划线组成。并且开头不能为数字。
变量名不能使用Python中的关键字(关键字:是指某些具有特殊功能的单词,如
break)
变量命名错误示范:
$name = 'yunya' #具有特殊字符 1year = 365 #数字开头 *_size = 1024 #具有特殊字符 and = 123 #使用了关键字 年级 = 3 #强烈不建议使用中文(占用内存大) (color) = 'red' #虽然这种命名方式可行但是也极为不推荐
变量命名正确方式:
name = 'yunya' __age = 18 #Python中 双下划线开头的变量名一般有隐私的这种说法 page_1 = '首页'
变量命名的风格
下面介绍几种常用的变量命名方式:
>>> YunyaAge = 18 #驼峰式 (驼峰式在Python中并不常用但是也并非完全不能使用,风格因人而异) >>> yunya_name = "云崖" #小写加下划线 (Python中更推荐使用的变量命名方式) >>> myClass = "三年级二班" #Camel标记法 (首字母是小写的,接下来的字母都以大写字符开头。) >>> sMyClass = "三年级一班" #匈牙利类型标记法 (前面的小写字母为变量类型)
这里更加推荐使用匈牙利类标记法,因为Python是一种弱类型语言所以一直有一段话叫做撸码一时爽维护火葬场。因为不能明确的知道变量的类型,这里也只是顺便提一嘴,不必太在意。
变量具有的三大特征
变量的三大特性我们通过函数就能够知道。这里介绍与print()方法差不多的2个方法:
id()
- 返回该变量的内存地址id号(唯一标识)
type()
- 返回该变量的数据类型
value
- 使用变量名拿到与其绑定的变量值(注意这不是一个方法,value中文意思即为值)
我们来看一下使用方式:
>>> name = "云崖" #定义变量 >>> age = 18 >>> print(id(name)) #打印变量指向的内存地址的唯一标示(id) id() 1902025257776 >>> print(id(age)) 140705586665664 >>> print(type(name)) #打印变量值的数据类型 type() <class 'str'> >>> print(type(age)) <class 'int'> >>> print(name) #打印变量值本身 云崖 >>> print(age) 18 >>>
is == 的区别与小整数池
关于Python基本数据类型这里先不做赘述下面很快会介绍的,我们来聊一聊 id() 方法,现在你应该已经知道了 id() 方法是获取变量名指向的内存地址的唯一标识(id),那么请尝试解释下面的情况:
>>> # ------------- 请注意以下测试请到原生Python解释器中执行,Pycharm中执行有所误差 -------------- >>> x = "这里是变量x" >>> x_copy = "这里是变量x" #请注意 x 与 x_copy 中存储的2个变量值都是一样的 >>> print(id(x)) 1928354538192 >>> print(id(x_copy)) #为什么他们变量值是一样的但是存储变量值的内存地址却不一样呢? 1928354538304 >>> y = 200 >>> y_copy = 200 >>> print(id(y)) 140705586671488 >>> print(id(y_copy)) #同样的 y 与 y_copy 存储的变量值也都是一样,并且他们变量值在堆内存中都是引用的同一块内存,这是为什么呢? 140705586671488 >>>
现在肯定是不明白的,做了同样的事情。唯一不同的区别在于一个值好像是数字,另一个值好像是文本。但是他们的结果就是不一样,别着急。还是先介绍2个方法。
is(成员运算符)
- 判断两个对象(也可以认为是值)是否来源于同一块内存地址(也可以说是否引用同一块内存),引用值是否相等
==(算术运算符)
- 判断两个对象(也可以认为是指)是否形式值相等
有了这两个方法我们就能慢慢的介绍上面的情况:
>>> x = "云崖是帅哥" >>> y = "云崖是帅哥" >>> print(x == y) # True,表明形式值相同 True >>> print(x is y) # False,表明内存地址id号不同,则引用值不同 False
这是关于字符串类型的变量值,形式值相同的情况下引用值不同...
>>> i = 100 >>> j = 100 >>> print(i == j) #形式值相同 True >>> print(i is j) #内存地址id号相同,即引用值相同 True >>> n = 10000 >>> m = 10000 >>> print(n == m) #形式值相同 True >>> print(n is m) #内存地址id号不同,即引用值不同 False >>>
关于整数类型的值,形式值相同的情况下引用值可能相同也有可能不同...
是不是更懵逼了?不要着急。解密的时刻到了:
Python解释器会觉得有一些数值会经常被使用(-5到255之间),故当脚本程序运行前就将这些数字写入堆内存中。当用户定义变量且使用到其中的数值时会直接将该数值的内存地址引用到存在于栈内存的变量名上,这样做极大节省了内存空间。
如:一个程序中使用了 100000 次 1 这个数值。那么如果没有Python的这个机制则会开辟出 *100000 个内存空间用来存放相同的数值。这么做显然极大的浪费了内存。故Python的这种机制是十分高效且合理的,并且它的名字叫做小整数池(范围:-5,255)。*
那么为什么字符串没有常用的呢、字符串类型(现在可以理解为文本,就随便输入的东西)实在是变化多端。比如1到10的数值如果用字符串的形式表现那就数不胜数,如一二三四五六七...甚至大写的壹贰仨肆伍陆柒等等都是有可能的。所以Python并没有针对字符串做一个常用池。
注意:关于小整数池的范围一定要注意这是Python原生解释器的范围,而使用
Pycharm则会扩大这一范围 !!!
常量
既然有变量,那么对应的也有常量。常量用于存储一些不允许被改变的值,比如PI,3.1415926535897... 再比如人眼睛的个数总是2个一样。这些都可以使用常量来进行存储,但是很遗憾Python自带的数据类型中没有常量这一说法。故在Python中有一个约定的章法,对于一些常量的值。在命名方式上会采取全部大写的方式。
常见的一些常量:
>>> PI = 3.1415926535897 #圆周率 >>> NUM_OF_EYES = 2 #眼睛个数 >>> SEX = "男" #性别 >>>
数字(虚拟)
整数(int)
整数在Python中叫做整形。Python3中没有小整形长整形(Python2中如果数字后加上L代表长整型,Python3取消了这种数据类型。)之分,并且整形支持四则运算。如:
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> x = 10 >>> y = 10 >>> type(x) # 注:在交互式的环境下可以不使用print() 依旧能返回结果,但是对于初学者仍然建议使用它 <class 'int'> # 查看类型 >>> type(y) <class 'int'> >>> x = x - 5 >>> y -= 5 # -= 与 - 自己体会一下 >>> x 5 >>> y 5 >>> x = x + 5 >>> y += 5 >>> x 10 >>> y 10 >>> x * 2 #乘法 这里没做赋值操作。 x = x * 2 与 x *= 2效果是一样的 20 >>> y * 2 20 >>> x 10 >>> y 10 >>> x ** 2 #2次方 幂运算 这里没做赋值操作。 x = x ** 2 与 x **= 2 效果是一样的 100 >>> y ** 3 #3次方 幂运算 1000 >>> x 10 >>> y 10 >>> x / 2 #除法(结果总是小数,精确求值) 5.0 >>> y // 2 #整除(结果总是整数-除数是浮点型小数除外,向下取整) 5 >>> x % 2 #求余运算。 0 >>> x % 3 1
并且,整形允许与浮点型(小数)做四则运算。所得结果也必然是浮点型(小数):
>>> x = 100 >>> y = 10.5 >>> x + y 110.5 >>> x - y 89.5 >>> x * y 1050.0 >>> x / y 9.523809523809524 >>> x // y #整除(除数为小数,拿到一个浮点型数据。且向下取整) 9.0 >>> x % 3.01.0
小数(float)
小数被称为浮点型,在Python中没有所谓的单精度浮点型或者双进度浮点型。浮点型的四则运算和整形基本差不多,这里不多举例,不过需要注意的是浮点型与整形进行四则运算运算结果必然是浮点型。
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> PI = 3.1415 >>> type(PI) <class 'float'> >>>
字符串(str)
字符串定义与使用
字符串类型,其实上面已经使用到了。字符串类型其实就是若干个字符组成的集合,它可以包含任何内容。定义字符串也很简单,Python中可以使用英文状态下的 ' 单引号。" 双引号,'''三个单引号或者"""三个双引号来表示一组字符串,其中三个单引号或者三个双引号可跨行。并且字符串在内存内部存入方式为顺序存储,即存入方式是有序的,只要是有序的存入方式就支持index操作。
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> str1 = "ABC" >>> print(type(str1)) # 在交互式的环境下可以不用使用print() 依旧能返回结果,但是对于初学者仍然建议使用它 <class 'str'> >>> s1 = '我爱Python,Python使我快乐。注意:单引号不支持跨行操作' >>> s2 = "我爱C语言,C语言是万物基础。注意:双引号不支持跨行操作" >>> s3 = '''我爱Java,除了Java没有什么能让我快乐 ... ,注意:三个单引号支持跨行操作''' >>> s4 = """在21实际,Go语言将成为未来的希望。因此: ... 我爱Go语言!注意:三个双引号支持跨行操作""" >>> print(s1) 我爱Python,Python使我快乐。注意:单引号不支持跨行操作 >>> print(s2) 我爱C语言,C语言是万物基础。注意:双引号不支持跨行操作 >>> print(s3) 我爱Java,除了Java没有什么能让我快乐 ,注意:三个单引号支持跨行操作 >>> print(s4) 在21实际,Go语言将成为未来的希望。因此: 我爱Go语言!注意:三个双引号支持跨行操作 >>> s5 = "*" >>> s5 '*' >>> s5 += "^" >>> s5 '*^' >>> s5 *= 3 >>> s5 '*^*^*^' >>>
尽管三个双引号或者三个单引号十分强大。但是我们仍不建议你滥用它。因为他们还有另外的一层意义:注释。
有的时候我们需要在字符串内使用引号。可以有常用的5种方式:
>>> s1 = '请注意这里:"双引号",看见没有?牛逼不' #单引号中括双引号 >>> print(s1) 请注意这里:"双引号",看见没有?牛逼不 >>> s2 = "现在是双引号中括单'引号',看见没?是不是很吊" #双引号中括单引号 >>> print(s2) 现在是双引号中括单'引号',看见没?是不是很吊 >>> s3 = """在三引号中,单双均可。可以随意使用双引或者单引:如''还有""""" >>> print(s3) "在三引号中,单双均可。可以随意使用双引或者单引:如''还有" >>> s4 = '使用反斜杠来转义,比如:\'<---这个引号不具有特殊意义了' >>> print(s4) 使用反斜杠来转义,比如:'<---这个引号不具有特殊意义了 >>> s5 = r'单引号:\',双引号:",三引号:""",\'''。这是因为开头使用了r,将该字符串中所有字符全部取消特殊意义' # \ 让字符串中单引号不作为结束符 >>> print(s5) 单引号:\',双引号:",三引号:""",\'。这是因为开头使用了r,将该字符串中所有字符全部取消特殊意义 >>>
如果想使用 \ 字符。那么就在对其做一次转义:第一次 \ 具有意义,使用 \ 将 \ 失去意义
>>> print("显示反斜杠:\\") 显示反斜杠:\
索引-index介绍
我们看一下需求:
>>> s1 = "ABCDEFGHIJKLMN" #取出单一字符 C >>>
我们可以通过索引(index)来实现这个需求。

一一对应的来取就好了。
>>> s1 = "ABCDEFGHIJKLMN" >>> s1[2] #交互式环境下可以不使用print() 'C' >>> s1[-12] 'C' >>>
索引不光可以用来取值。还可以用来赋值达到修改变量的目的,但是字符串str类型并不支持使用索引来修改变量(因为str和int以及float都是看做一个整体。如"abc"和数字100),至于原因稍候会讲到。
不可变类型-内部存储方式
我们尝试为字符串使用索引达到修改某一字符的目的:
>>> s1 = "ABC" >>> s1[0] = "a" #我想将大写的A替换成小写的a Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment >>>
可以看到它报了个异常,这个异常大概意思是说 str 对象 不支持使用索引分配值。
这里要引出一个概念,可变类型与不可变类型,比如上面学到的整形与浮点型(小数)等均是不可变类型。(关于整形和浮点型它们甚至不支持index取单一值)
>>> x = 3.14 >>> x[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'float' object is not subscriptable >>> y = 1 >>> y[0] Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'int' object is not subscriptable >>>
不管整形和浮点型是什么样的,这里就论字符串型,为什么字符串型不能使用索引修改单一字符呢?这还要从它的内部存储原理说起。我们可以使用 + 对比整形来测试一下:
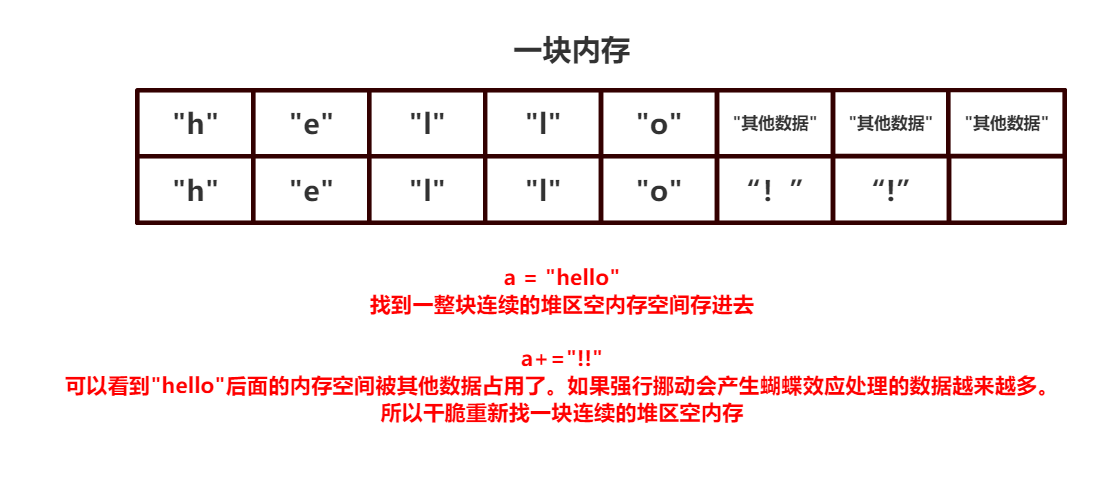
>>> x = 3 >>> id(x) 140705586665184 >>> x = x+3 >>> id(x) 140705586665280 #可以看到引用值出现了改变。这点能理解,毕竟小整数池中取整数不会开辟新的内存空间 >>> s1 = "ABC" >>> id(s1) 2283017853488 >>> s1 = s1 + "DEF" >>> id(s1) 2283018297392 #字符串为什么引用值也出现了改变?这么做岂不是多此一举吗?重新开辟内存空间? >>>
灵魂三连问,一个答案来解疑
如果修改一个字符串的子串,比如添加或者删除。因为字符串是连续的一块内存存放,被看做为一个整体,修改其中某一个元素那么必定会导致后面的内存发生变化,链式反应滚起雪球需要处理的数据量很庞大,于是Python干脆不支持使用index为字符串进行修改(与整形同理)。但是如果和整形以及浮点型一样用 + 作为拼接字符的话底层便会重新给你开辟新的连续的堆内存空间供变量值(str类型)存放。故str内部存储方式为连续顺序存储。
列表
列表定义与使用
我们的字符串可以使用index来取出数据,列表当然也可以。列表的定义是使用 [] ,它可以存取许多不同数据类型的变量值(被称为列表中的元素)并且可以通过index来操纵这些变量值(元素)。所以列表就是一种可变的数据类型(列表内部也是采用顺序存储。但是与字符串的内部存储方式有很大的不同)。
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> li = [1,"A",3.1415] >>> type(li) <class 'list'> # 列表类型为 list >>> li[0] #通过 index来取出存储的变量值 1 >>> li[1] 'A' >>> li[2] 3.1415 >>> li[-1] #index倒序取值 3.1415 >>> li[-2] 'A' >>> li[-3] 1 >>>
列表是我们今后整个Python学习中使用最多的一种数据类型,因为它实在是太方便太好用了。关于列表的基本定义与使用就先介绍到这里,我们来看点进阶的。
多维取值与列表的增删改查
上面说过,列表可以存取不同数据类型的变量值,当然列表中也能嵌套列表。我们看一下:
>>> li = ["A","B",[1,2,["C"]]] >>> li += ["增加元素"] >>> li ['A', 'B', [1, 2, ['C']], '增加元素'] #增 >>> del li[-1] #删 >>> li ['A', 'B', [1, 2, ['C']]] >>> li[0] = 'a' #改 >>> li[2][2][0] #index正序取值 'C' >>> li[-1][-1][-1] #index倒序取值 'C' >>> KeyboardInterrupt >>> li[-1][2][0] #index正序与倒序交叉使用取值 'C' >>> li ['a', 'B', [1, 2, ['C']]] >>> # 列表支持 *= 可以自行测试一下
多维列表的取值操作与index对于列表的增删改查应该尽快熟练,这在日后非常常用。
可变类型-内部存储方式
我们尝试为列表使用index索引赋值,达到增加或者修改列表中元素的目的。
>>> li = ["a","b","c"] >>> li ['a', 'b', 'c'] >>> id(li) #查看变量名li 绑定的 内存地址id 2210045040640 >>> li[0]="A" #可以看到即使修改了其中的元素 变量名li 所绑定的内存地址id 还是没有改变 >>> id(li) 2210045040640 >>> li ['A', 'b', 'c'] >>>
我们尝试使用 + 来试试看:
>>> li = ["a","b","c"] >>> id(li) 2210045360896 >>> li += ["d","e","f"] ['a', 'b', 'c', 'd', 'e', 'f'] >>> id(li) 2210045360896 #可以看到即使使用 + 列表的变量绑定内存地址依旧没有改变,每次的内存地址都一样难道说列表申请的内存地址最够大?才能够存放这么多值? >>>
第三个试验:
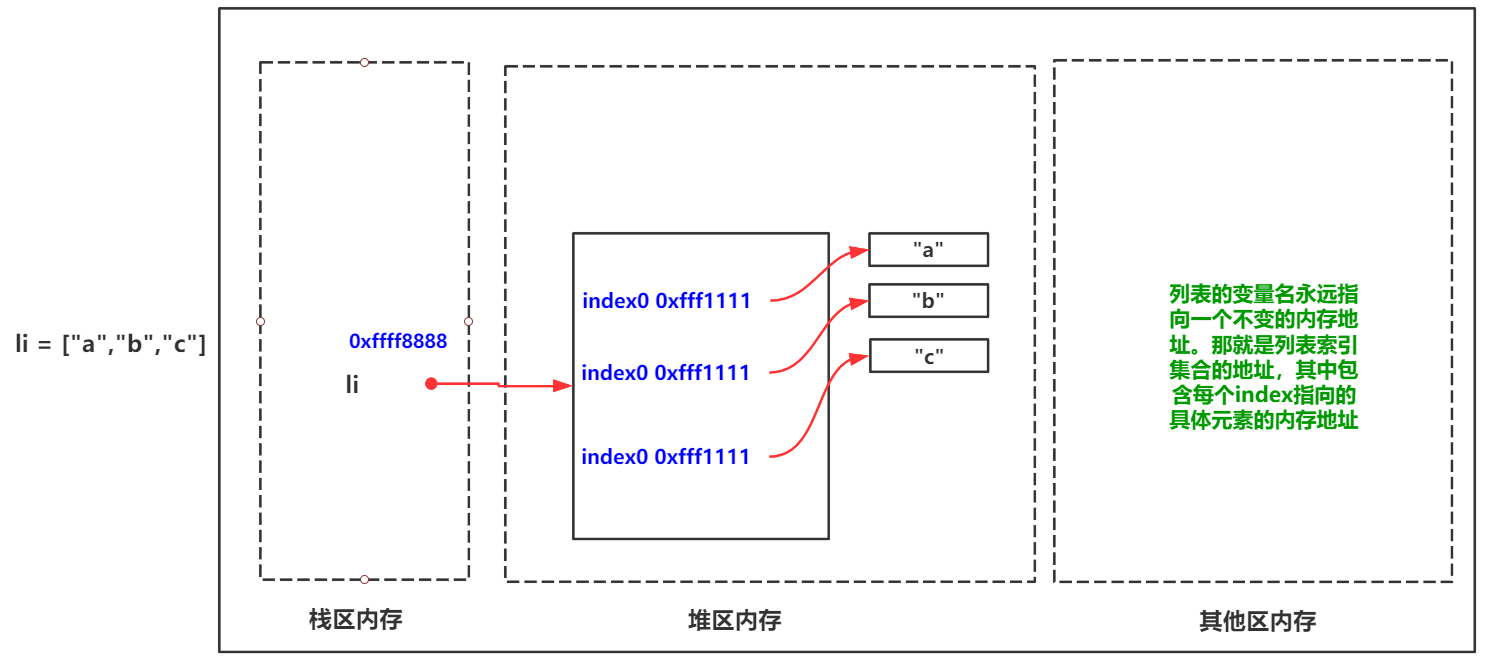
>>> li = ["a","b","c"] >>> id(li) 2210045360960 # 变量名li 绑定的内存地址 >>> id(li[0]) 2210044891248 >>> li[0] = "A" >>> id(li) 2210045360960 # 可以看到其中元素已经改变了,但是其li 绑定的内存地址依旧没有任何改变 >>> id(li[0]) 2210045361456 # li中0号元素内存地址发生了变化 >>>
其实到了这里,大家应该能明白了。列表的变量名绑定的是一个顺序引用内存,该内存中标注了列表中各个index索引值与真正的变量值绑定的关系。如图:
字典(dict)
字典的定义与使用
字典是一种可变的数据类型,外部有一个 {} 大括号来包裹一组一组的元素。每一组元素用 : 表示 键(key) : 值(value), 每一组元素之间用逗号隔开。
我们使用列表时候经常是会将一种类型的数据存放在同一个列表,比如:包含中国城市名的列表就应该很单纯的存储中国城市的名字,而不应该有其他的数据。但是对于字典来说它可以存储更多其他的数据。
字典中没有index,但是依旧提供了 [] 的操作方法,唯一不同的是 [] 中填写的不应该是元素的索引,而应该是引用元素值对应的key名称。我们可以使用key来操纵其对应的value。这也变相说明了字典内部并不是通过顺序方式存储,而是以另一种无序存储的方式(hash存储都是无序存储,也被称为散列存储)
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> d1 = { ... "name": "云崖", ... "age": 18, ... "hobby": ["篮球", "足球", "乒乓球"], ... "relation":{ ... "father":"大云崖", ... "son":"小云崖", ... }} >>> d1["name"] '云崖' >>> d1["age"] 18 >>> d1["hobby"] ['篮球', '足球', '乒乓球'] >>> d1["relation"]["father"] '大云崖' >>>
键值对与字典的增删改查
字典中的存储方式是键值对,那么为什么不使用index呢?这个涉及到底层存储方式的不同。但是键值对的操作方式也是非常的便捷,并且它相较于列表的index来说查找数据更快。
值得一提的是字典虽然是可变的数据类型,但是其键值对中的键(key)则必须是由不可变的数据类型构成。(字符串,整形,浮点型),因为不可变类型是可hash的而字典底层就是通过hash来存储,这个等下会具体讲。但是只要记住这一点就好了。
>>> d1 = {1:"整形,不可变类型"}
>>> d1
{1: '整形,不可变类型'}
>>> d2 = {1.1:"浮点型,不可变类型"}
>>> d2
{1.1: '浮点型,不可变类型'}
>>> d3 = {"str1":"字符串类型。不可变类型"}
>>> d3
{'str1': '字符串类型。不可变类型'}
>>> d4 = {[1,2,3],"可变类型,字典定义抛出异常"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> d5 = {{"k1":"v1"}:"如果使用字典作为键是会抛出异常的,字典本身就是属于可变类型"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'dict'
>>>
基本增删改查:
>>> d1 = {1:"整形,不可变类型"}
>>> d1
{1: '整形,不可变类型'}
>>> d2 = {1.1:"浮点型,不可变类型"}
>>> d2
{1.1: '浮点型,不可变类型'}
>>> d3 = {"str1":"字符串类型。不可变类型"}
>>> d3
{'str1': '字符串类型。不可变类型'}
>>> d4 = {[1,2,3],"可变类型,字典定义抛出异常"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> d5 = {{"k1":"v1"}:"如果使用字典作为键是会抛出异常的,字典本身就是属于可变类型"}
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'dict'
>>>
hash-内部存储方式
上面已经说过了。字典不使用index操作元素是因为底层原理的不同,那么我们来看一下关于字典内部它的底层是怎么实现的。
字典对象的核心是散列表.散列表是一个稀疏数组(总是有空白元素的数组),数组的每个单元叫做bucket,每个bucket有两部分:一个是键对象的引用,一个是值对象的引用.
由于,所有bucket结构和大小一致,我么可以通过偏移量来指定bucket.
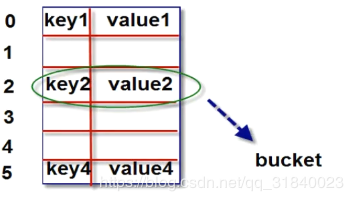
将一个键值对放进字典的底层过程
>>> a={} >>> a["name"] = "yunya"
当将"name"="yunya"这个键值对放到字典对象a中,首先第一步要计算键"name"的散列表.Python可以使用hash()来计算.
>>> a = {} >>> a["name"] = "yunya" >>> bin(hash("name")) #bin()转换二进制 。 hash()查看可hash对象的hash值 --- 也可以理解为不可变类型绝对是可hash的 '0b11001101110010100000000000000001101100011111011011011001011010' >>>
由于数组长度为8,我们可以拿计算出的散列值,最右边3位数作为偏移量,即"010",十进制是数字2,我们查看偏移量2,对应的bucket是否为空,如果为空,则将键值放进去,如果不为空,依次取右边3位作为偏移量'011',十进制是数字3,再查看偏移3的bucket是否为空.直到栈为空的bucket将键值放进去
根据键查找"键值对"的底层过程
一个键值对是如果存储到数组中的,根据键值对象取到值对象,理解起来就简单了
a["name"]
当我们调用a["name"],就是根据键"name"查找"键值对",从而找到值"yunya"。
第一步,我们仍要计算"name"对象的散列值:
bin(hash("name"))
>>> bin(hash("name")) #bin()转换二进制 。 hash()查看可hash对象的hash值 --- 也可以理解为不可变类型绝对是可hash的 '0b11001101110010100000000000000001101100011111011011011001011010'
和存储的底层流程算法一致,也是一次取散列值不同的数字。
假设数组长度为8,我们可以拿计算出的散列值的最右边3位数字作为偏移量,即"010",十进制是数字2,
我们查看偏移量2,对应的bucket是否为空.如果为空则抛出KeyError的异常.
如果不为空,则将这个bucket对象的键对象计算对应的散列值,和我们的散列值进行比较,
如果相等,则将对应的"值对象"返回。
如果不相等,则一次取其它几位数字,重新计算偏移量,直到全部将散列值的便宜了.
用法总结:
- 键必须可散列数字,字符串,元组,都是可散列的
- 字典在内存中开销巨大,典型的空间换时间.
- 键值查询速度很快
- 往字典烈面添加新键可能导致扩容,导致散列表中的键的次序发生变化.因此,不要在遍历字典的同时对字典的修改.
自定义对象需要支持下面三点(新手忽视);
- 支持
hash()函数- 支持通过
__eq__()方法尖刺相等性- 做
a==b为真,则hash(a)==hash(b)也为真.
另外附上一篇我自己学习时做的笔记(新手玩家可忽略):
hash原理: 通过散列值计算来指定一块特定的空间。如果这个空间被其他的数据占用了就会通过取位来重新计算。当找到一块新的空间的时候就会把这个数据存放进去,当然hash会提前声明一块连续的空间(这些空间不会被全部利用) 来方便存入数据。当剩余空间所剩只有一个特定的数的时候 又会去声明一块新的空间。所以: 通过hash来存放数据,内存占用量会比较高但是查询速度是异常的快。================================================
hash查找:计算键的散列值(又称hash函数) -> 使用散列值的一部分来定位散列表(稀松的含有空白的数组,分为2部分key和value)中的一个表元(存储value的地方),那么就会出现下面几种情况 :-> 表元为空 (代表要查找的值没有写入)
->抛出
KeyError(对应上图的处理办法)-> 表元是其他值
-> 使用散列值的另一部分来定位散列表中的另一行
-> 表元是要查找的值 -> 返回表元里的值
dict的key和set中的值必须都是要可hash的对象。不可变对象,就是可hash的! 想要实现自定义类支持hash只需要在类中实现hash方法即可。
dict的存储顺序和元素的添加顺序是有关系的,先添加的元素就有可能先拿到本该属于后者的一个空间。所以在这里有了collections模块下的:OrderedDict( 有序字典 )添加数据,有可能改变已有数据的位置。因为在本身空间到了一定的值得时候会去重新开辟新空间,在运行数据迁徙算法的时候可能和上一次的有所误差。所以我们尽量不要去期望采用哈希算法的类有一定的规律性 ,
set和dict的原理都是一样的==================================================
内置类型查找性能最高的首先是
set,它没有映射关系又是 哈希表 (散列表) 。所以是最快的,其次是dict,因为有一层映射关系在所以相对于set会显得比较慢但是这个时间差基本可以忽略不计。速度最慢的是list和tuple,他们通过下标(索引)index来逐个进行查找,所以这样的数据结构不适合查询大量的数据。并且set和dict的查找速度不会随着被查找数据量的增大而增大。不管你有多少数据,我找到我需要的数据就只要那么几个时间而已,这点也是list和tuple做不到的。
元组(tuple)
元组定义与使用
元组首先是一个不可变数据类型,可以作为字典的key。元组的定义主要是使用逗号将不同的元素进行分割,但是为了能够一眼看到这是元组还会在元组两边加上括号。元组可使用index进行元素的查找(说明本身是顺序存储),但是无法通过index进行元素的修改以及删除。因此常被存储一些一旦被定义好了就不允许修改的变量(可以理解为常量):
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> t1 = "北京","上海","天津","重庆", #元组的定义是使用逗号 >>> type(t1) <class 'tuple'> >>> t2 = ("北京","上海","天津","重庆",) #为了美观和直接所以在2侧加入括号 >>> type(t2) <class 'tuple'> >>> t1[0] '北京' >>> del t1[0] #元组不支持 index 删除 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object doesn't support item deletion >>> t1[0] = "旧金山" #元组不支持 index 修改 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'tuple' object does not support item assignment >>> t1 += ("东京") #元组不支持 += Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can only concatenate tuple (not "str") to tuple >>> id(t1) #查看原本的 内存地址 id 1711529097232 >>> t1 *= 3 #看起来 *= 好像是改变了元组内容。但是实际上是生成一个新的元组,因为内存地址 id不同了。代表开辟了新的内存空间 >>> t1 ('北京', '上海', '天津', '重庆', '北京', '上海', '天津', '重庆', '北京', '上海', '天津', '重庆') >>> id(t1) 1711528765904 >>>
元组使用注意这个坑
>>> t1 = (1,2,[3,4]) #元组套列表。这是非常sb的行为,本身元组具有不可变的特性非要去套上一个可变类型,这不是sb是什么 >>> t1[-1] [3, 4] >>> t1[-1][0] = "三" >>> t1 (1, 2, ['三', 4]) >>> t2 = (1,2,{3:4}) #元组套字典,sb中的sb,对此已经无力吐槽 >>> t2[-1] {3: 4} >>> t2[-1][3] = "四" >>> t2 (1, 2, {3: '四'}) >>>
集合(set)
集合的定义
集合这种数据类型非常特殊,它和字典一样本身是可变类型但是其存储的元素必须是不可变类型。这就说明了集合的内部存储也是使用了hash存储,导致了它的存取速度非常之快且内部元素无序排列的特点,并且集合还有一个特性便是去重。使用集合只需要两边加上 {} ,中间每个元素用 ,号分隔开即可。
集合常用于操纵数据而不是存储数据,如:去重,求2个集合的交叉并等操作。
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>> set1 = {1,1,1,"a","a","A"} #这里使用Python2.x版本,更能看出集合无序的特点 >>>type(set1) >>><class 'set'> >>> set1 set(['a', 1, 'A']) #可以看到集合改变了存入时的顺序 >>> set[0] #集合不支持 index 操作 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'type' object has no attribute '__getitem__' >>> set2 = {1,2,(3,3,4,5)} #集合支持存入 数字,字符串,元组 >>> set2 set([(3, 3, 4, 5), 1, 2]) >>> set3 = {1,2,[1,2,3]} #集合不支持存入 list数据类型 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'list' >>> set4 = {1,2,{1:2}} #集合不支持存入 dict数据类型 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'dict' >>> set5 = {1,1,2,2,{1,1,2,2}} # 当然集合也不支持存入集合。因为首先集合本身就是一种可变的数据类型 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unhashable type: 'set' >>>
布尔(bool)
布尔的定义与作用
布尔类型是不可变类型,它只有2个值,一个是True代表真,一个是Flase代表假。对应数字状态即是 0 和 1,布尔值常被用于分支结构中。目前还没有学习分支结构所以先不着急它的使用,只是了解一下即可。
对于任何空的 :列表,元组,字典,集合,字符串,None,0 等等 它们的布尔值状态都会是 False。
对于任何含有数据的 : 列表,元组,字典,集合,字符串,not None,任意非空的整形或者浮点型数据它们的状态都会是True。
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- bool()方法返回对象的 bool状态 >>>type(False) <class 'bool'> >>> bool(None) #None代表为空,什么都没有的意思 False >>> bool("") #空字符串 False >>> bool([]) #空列表 False >>> bool(()) #空元组 False >>> bool({}) #空字典,注意!!!很多人认为这样的定义是空集合,其实这是空字典。 False >>> bool(set()) #空集合,由于{}被解释器认为是空字典。故使用set()来定义一个空集合。 False >>> bool(0) #空整形(浮点型相同) False
>>> #-----------------------------使用type()方法可查看当前对象(变量值)的数据类型---------------------------- >>>type(False) <class 'bool'> >>> bool(not None) #not None代表不为空。 True >>> bool("str") #字符串 True >>> bool(["list",]) #列表 True >>> bool(("tuple",)) #元组 True >>> bool({"dict":"dict_1"}) #字典 True >>> bool({1,2,3,4}) #集合 True >>> bool(1) #空整形(浮点型相同) True
除此之外,bool类型的True和False还可以与整形或者浮点型进行四则运算(当True或False参与运算时,会从小整数池中取1或者0进行运算):
>>> True + 1 2 >>> True - 1 0 >>> True * 20 20 >>> True ** 20 #True 代表数字 1。所以幂运算不管是多少都是 1 1 >>> True / 20 0.05 >>> True // 20 0 >>> # 关于False的四则运算这里不做举例,它和True的用法都是一样的。

