树分治(一)——点分治入门
 .
.
点分治
对于一类统计树上路径信息(比如距离 \(\le k\) 的点对数量,\(\bmod m\) 意义下最长路径)等,可以考虑使用点分治。
一般来说,点分治的大致框架是这样的:
- 将树上的路径分为两类:一类是不经过根节点的,一类是经过根节点的。
- 对于第一类,不经过根节点意味着这条路径必然完全位于根节点的一个子节点的子树内,可以直接把这棵子树当做一棵新的树,递归下去进行统计。
- 第二类路径是点分治过程的核心部分,这部分的统计方法对每道题都不太一样。
这样说似乎很难懂,我们举几个例子。
例题
Luogu P4178 Tree
给定一棵 \(n\) 个节点的带权树,定义 \((u,v)\) 两点间距离为 \(u,v\) 两点间唯一路径上所有边权之和。
再给定一个正整数 \(K\),求有多少对节点 \((u,v)\) 满足两点距离不超过 \(K\)。\(n\le 40000,K\le 20000\)。
对于一个节点 \(u\),设 \(\text{Dist}(u)\) 为 \(u\) 到根节点的路径长度,\(\text{From}(u)\) 为 \(u\) 所在的子树的根节点编号。例如:
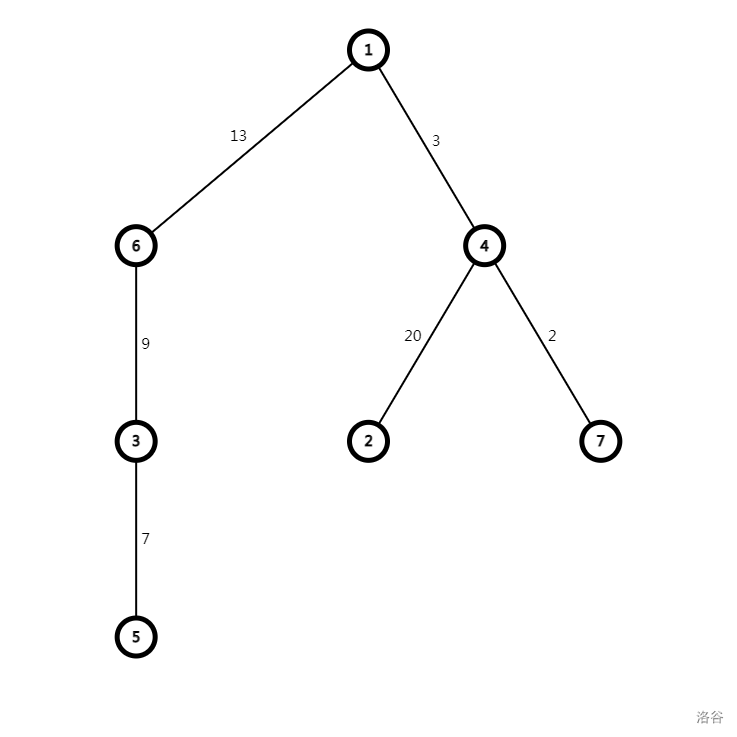
这里的根节点为 \(1\),节点 \(6,3,5\) 的 \(\text{From}\) 值均为 \(6\),因为它们都在以 \(6\) 为根的这棵子树内。
同理,\(4,2,7\) 的 \(\text{From}\) 值均为 \(4\)。
我们考虑如何统计「经过根节点且长度不超过 \(K\)」的路径。这类路径可以分为两种:
- 以根节点为端点。即满足 \(\text{Dist}(u)\le K\) 的点 \(u\) 的数量。
- 不以根节点为端点的路径 \((u,v)\) 。此时为了让这条路径经过根节点,必须有 \(\text{From}(u)\neq \text{From}(v)\)。不难发现这条路径的长度就是 \(\text{Dist}(u)+\text{Dist}(v)\)。
前一类路径显然很好统计。
对于后一类路径,我们依次处理根节点的每个儿子的子树。假设目前处理到了第 \(i\) 棵子树,我们将前 \(i-1\) 棵子树内的所有点的 \(\text{Dist}\) 值扔进一棵平衡树里,同时枚举这棵子树内的每个节点 \(u\),那么满足条件的 \(v\) 的数量就是平衡树中权值 \(\le K-\text{Dist}(u)\) 的点的个数。这可以在平衡树内直接 \(O(\log n)\) 统计。
大致的算法框架如下:
- 首先维护一棵初始为空的平衡树。
- 对于根节点的每一个儿子的子树,首先算出来这个子树内的所有点的 \(\text{Dist}\) 值。
- 对于这棵子树内的每个点 \(u\),计算平衡树内权值 \(\le K-\text{Dist}(u)\) 的点数,并累计答案。
- 接下来将每个点 \(u\) 的 \(\text{Dist}\) 值插入平衡树内,并接着计算下一个儿子的子树。
注意到此时我们仍然需要统计以根节点为端点的路径。实际上只需要将根节点看作一条长为 \(0\) 的路径,并在一开始插入平衡树即可。
实际上可以不使用平衡树:将所有节点按 \(\text{Dist}\) 值排序。注意到此时对于一个点 \(u\),满足 \(\text{Dist}(v)+\text{Dist}(u)\le K\) 的 \(v\) 的位置是单调不增的。
维护两个指针 \(s,t\),并维护一个数组 \(\text{Count}(x)\) 表示区间 \([s,t]\) 内 \(\text{From}\) 值 \(=x\) 的元素个数,那么以 \(s\) 为一个端点的路径个数就是 \(t-s-\text{Count}\big(\text{From}(s)\big)\)。
每一次右移 \(s\) 接着左移 \(t\) 直到 \(\text{Dist}(s)+\text{Dist}(t)\le K\) 并更新答案,就可以 \(O(n)\) 统计答案。算上排序的 \(O(n\log n)\),总的时间为 \(O(n\log n)\)。
总而言之,我们统计完了「经过根节点且长度不超过 \(K\)」的路径数量。
对于不经过根节点的路径,我们可以直接把每个子节点的子树看做一棵新的树递归下去计算。
然而这个算法有一些问题:如果树是一条链并且我们选了链的一个端点作为根,那么算法就会递归 \(n\) 层。每层递归都有一次 \(O(n\log n)\) 的计算,肯定会 TLE。
注意到如果以树的重心作为根节点,那么其每个子节点的子树大小均不会超过 \(n/2\),这表明递归至多进行 \(O(\log n)\) 层。
算法的时间复杂度为 \(O(n\log ^2n)\)。
这里给出一个代码实现。实际实现的时候也有一些细节,建议阅读一遍代码实现。
Luogu P3806 【模板】点分治
给定一棵有 \(n\) 个点的树,边有边权。
有 \(m\) 次询问,每次询问树上距离为 \(k\) 的点对是否存在。
\(n\le 10000,m\le 100,k\le 10^7\),边权 \(\le 10000\)。
和上题类似,对于本题,点分治的过程中只需要判断「是否存在 \((u,v)\) 使得 \(u,v\) 在不同子树内,且 \(\text{Dist}(u)+\text{Dist}(v)=k\)」即可。
类似于上题的平衡树那种做法,我们开一个 bool 的数组 \(\text{Exist}(x)\) 表示前 \(i-1\) 棵子树内是否存在一个 \(u\) 使得 \(\text{Dist}(u)=x\),并对当前子树内的所有点 \(v\) 判断一下 \(\text{Exist}\big(k-\text{Dist}(u)\big)\) 是否为真,最后统一对每个 \(u\) 赋值 \(\text{Exist}\big(\text{Dist}(u)\big):=1\) 即可。
边权之和可以达到 \(10^8\) 级别,不过可以开一个 bitset 就不会卡空间了。
时间复杂度 \(O(nm\log n)\)。代码实现
自己 yy 的题
给一棵有 \(n\) 个节点的树,边有边权。给定正整数 \(m\),你需要求出 \(\bmod m\) 意义下边权和最大的路径。\(n,m\le 10^5\)。
仍然只需要计算「对于所有在不同子树内的 \(u,v\), \(\text{Dist}(u)+\text{Dist}(v)\) 模 \(m\) 的最大值」。
先将所有 \(\text{Dist}\) 值对 \(m\) 取模。不难发现此时两个数加起来要么小于 \(m\),要么在 \([m,2m)\) 之间。
枚举 \(u\),对于第一种情况,只需要计算出 \(<m-\text{Dist}(u)\) 的最大的 \(\text{Dist}\) 值,二分即可;对于第二种情况显然直接取最大值即可。
时间复杂度为 \(O(n\log ^2n)\)。本来感觉挺有趣的想出成题,直到我发现了这个:
Luogu P5563 「Celeste-B」No More Running
给一棵有 \(n\) 个节点的树,边有边权。
给定正整数 \(m\),你需要对每个点 \(u\) 求出以 \(u\) 为一个端点,且在 \(\bmod m\) 意义下边权和最大的路径。
\(1\le n\le 10^5,m=2\) 或 \(32\) 或 \(65536\)。
很开心地重题了呢(笑)
这道题还需要对每个点都求出来以它为端点的最优路径,实际上只需要在上题中枚举端点时顺便统计一下就行了。
具体来说,我们首先把所有儿子的子树内的点都扔进一个 multiset 里面,然后统计到对应的子树时,就把这棵子树内的点删掉并统计答案,然后再插入回去。
在代码实现上就是这样。
话说 Celeste 的 7B 好难啊。。。。我死了一千四百多次才过 QAQ
UVa12161 Ironman Race in Treeland
给定一个有 \(n\) 个结点的树,每条边有两个权值 \(l\) 和 \(d\)。
给定正整数 \(m\),你需要求出一条路径,使得其上的所有边的 \(d\) 值之和 \(\le m\) 且 \(l\) 值之和最大。
\(1\le n\le 30000,1\le m\le 10^8,1\le d,l\le 1000\),输入包含不多于 \(10\) 组数据。
点分治。记一条路径 \(x\) 上的 \(d\) 值之和为 \(D_x\),\(l\) 值之和为 \(L_x\)。
当我们处理第 \(i\) 个子树时,需要做的就是:
- 对每一条该子树中从根出发的路径 \(x\),在前 \(i-1\) 个子树的所有路径中,找到满足 \(D_y\le m-D_x\) 且 \(L_y\) 最大的路径 \(y\)。
一个自然的想法是开一个权值线段树,那么这个操作就相当于查询一个 \([1,m-D_x]\) 上的前缀最大值。
然而 \(m\) 最大是 \(10^8\) 开不下权值线段树=_=
注意到一个性质:如果两条路径 \(x\) 和 \(y\),若 \(D_x\le D_y,L_x\ge L_y\),那么 \(y\) 显然不会被选择。
因此我们按 \(D\) 排序,然后从前往后扫一遍,如果前面的 \(L\) 值比后面的 \(L\) 值大,那么就把后面的删掉;查询的时候二分一下就行了。参考代码
总结一下:
- 当我们需要统计一些树上路径信息时,可以考虑点分治。
- 点分治将树上的路径分为「经过根节点的路径」和「不经过根节点的路径」两类。
- 第一类路径的统计是我们具体要做的内容。第二类则可以递归下去计算。
- 每次选取树的重心作为根节点递归下去,递归层数就是 \(O(\log n)\) 的。
点分治的英文名叫 \(\text{Tree Decomposition}\),树分解。
为什么叫这个名字呢?我们发现点分的过程其实就是找出树的重心,统计经过重心的所有路径,然后删掉这个重心。删除的过程体现在代码上,就是那句 vis[u]=1。
删掉重心后这棵树会分解为若干棵较小的树,我们再递归进每一棵树分别统计即可。每层递归的复杂度为 \(O(n)\),那么总的复杂度就是 \(O(n\log n)\)。
不妨切几道萌萌题练练手:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号