ACL2020 Contextual Embeddings When Are They Worth It 精读
上下文嵌入(Bert词向量): 什么时候值得用?
ACL 2018
预训练词向量 (上下文嵌入Bert,上下文无关嵌入Glove, 随机)详细分析文章
1 背景
图1 Bert
| 优点 | 效果显著 |
| 缺点 | 成本昂贵 (Memory,Time, Money) (GPT-3,1700亿的参数量) |
| 困惑 | 线上环境,资源受限(内存 CPU GPU) bert不一定是最佳 选择 用word2vec, glove等词向量有时候也能取得近似效果 但什么时候可以近似,需要实验说明,于是作者设计了实验 |
2 三种词向量

图2 三种词向量
| 类型 | 说明 | 实验 |
|---|---|---|
| 上下文词嵌入 | BERT XLNet | 作者实验中选BERT 768维 |
| 上下文词无关嵌入 | Glove Word2Vec FastText | 作者实验中选Glove 300维 |
| 随机嵌入 | n*d矩阵 (n是词汇量, d是嵌入维度) | 作者实验中选循环随机嵌入 800维, 空间复杂度O(nd) => O(n) |
3 实验和结论
| 任务 | 模型 |
|---|---|
| 命名实体识别 (NER) | BiLSTM |
| 情感分析 (sentiment analysis) | TextCNN |
3.1 影响因素一:训练数据规模
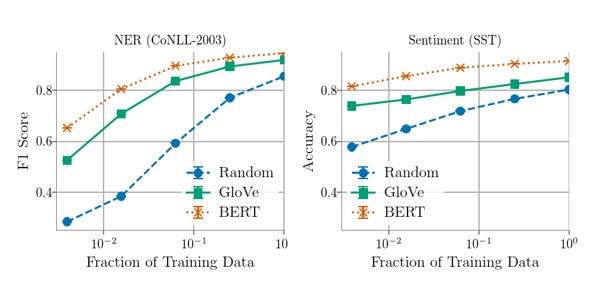
图3 影响因素一:训练数据规模 01
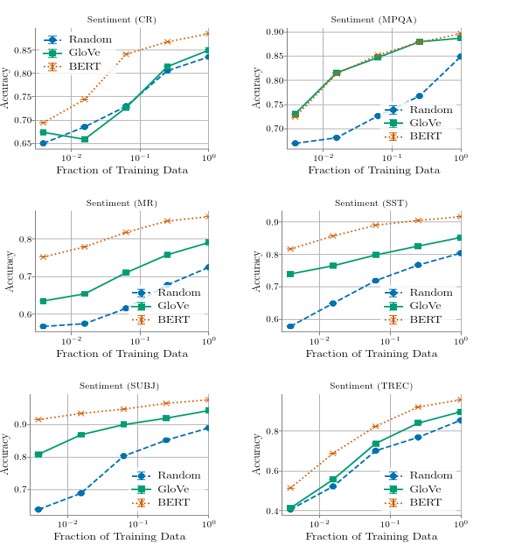
图4 影响因素一:训练数据规模 02
在许多任务中,供充足的数据,GloVe这些词向量可匹配BERT
3.2 影响因素二:语言的特性
3.2.1 Complexity of setence structure
NER: 实体占据几个token (George Washington)

图5 NER中的句子复杂度
Sentiment analysis:句子依存分析中依赖标记对之间的平均距离

图6 Sentiment analysis中的句子复杂度
3.2.2 Ambiguity in word usage
NER: 实体有几个标签(George Washington可以作为人名、地名、组织名)

图7 NER中的句子模糊度
Sentiment analysis:
\begin{array}{l}
H\left( {\frac{1}{{\left| S \right|}}\sum\limits_{w \in S} {p\left( { + 1\left| w \right.} \right)} } \right) \
{\rm{where }}H\left( p \right) = - p{\log _2}\left( p \right) - \left( {1 - p} \right){\log _2}\left( {1 - p} \right) \
\end{array}

图8 Sentiment analysis中的句子模糊度
3.2.3 Prevalence of unseen words
NER: token出现次数得倒数

图9 NER中的未登录词流行度
Sentiment analysis:
给定一个句子,句子中未在训练集中出现token占比

图10 Sentiment analysis中未登录词流行度
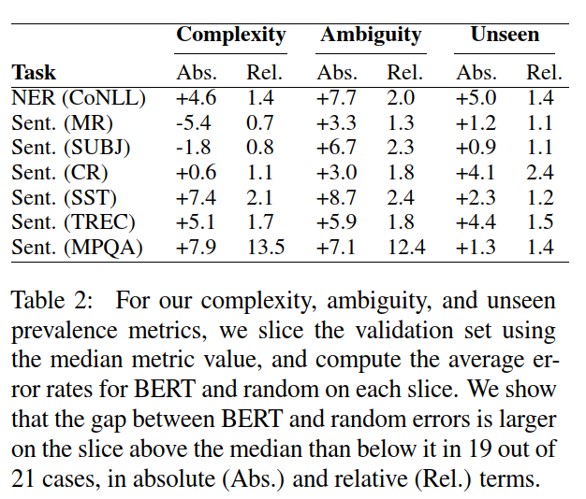
图11 Bert和随机向量对比
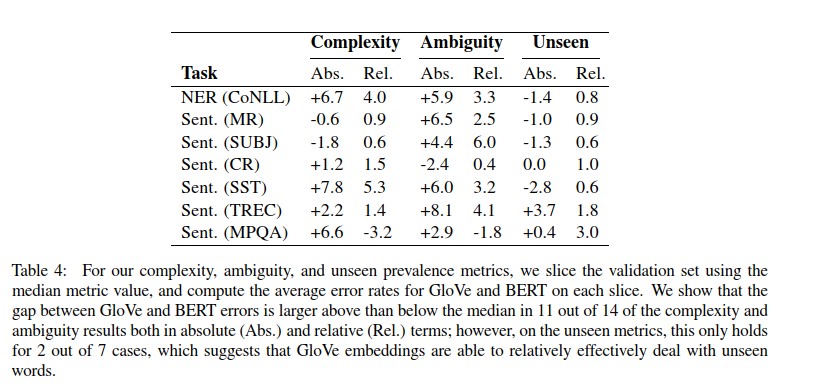
图12 Bert和Glove对比
文本结构复杂度高和单词歧义性方面: BERT更好
未登录词方面: GloVe 更好
总结
大量训练数据和简单语言的任务中,考虑算力和设备等,GloVe 代表的 Non-Contextual embeddings 是个不错的选择
对于文本复杂度高和单词语义歧义比较大的任务,BERT代表的 Contextual embeddings 有明显的优势。
未登录词方面: GloVe 更好

 浙公网安备 33010602011771号
浙公网安备 33010602011771号