命名实体如何进行概念消歧?
1 引言
命名实体概念消歧是命名实体消歧(英语:Named Entity Disambiguation)的一个重要研究子领域(命名实体概念可见本文3.1章)。什么叫概念消歧了?在这里举一个简单例子进行说明,一个命名实体“天龙八部”,它有许多个不同的含义,其中有电视剧类的含义,电视剧含义有好几个,如“1997黄日华版电视剧”、“1982年TVB版本电视剧”、“2003年内地胡军版电视剧”、“”2013年内地版电视剧“等;其中有漫画类的含义,漫画含义有好几个,如“腾讯动漫的漫画”、“黄玉郎改编的漫画”。虽然电视剧类的含义有好几个,但这些含义都是同一个概念,它们都属于“电视剧”这个概念。

图1 不同的含义的天龙八部
因此命名实体概念消歧的任务是识别一段文本中给定的命名实体到底属于哪一个概念。例如有下面3个文本。
| 文本 | 含义 | 概念 | |
|---|---|---|---|
| A | 港版天龙八部还是经典啊,黄日华才演出萧峰的气质 | 97黄日华版电视剧 | 电视剧 |
| B | 我是张纪中的铁杆粉丝,我当然喜欢天龙八部啦 | 03内地胡军版电视剧 | 电视剧 |
| C | 我喜欢香港漫画,如《天子传奇》《天龙八部》 | 黄玉郎改编的漫画 | 漫画 |
文本A中天龙八部是“1997黄日华版电视剧”,文本B中天龙八部是“2003年内地胡军版电视剧”,文本C中的天龙八部是“黄玉郎改编的漫画”。虽然文本A和文本B中的天龙八部不是同一个意思,但文本A和文本B中的天龙八部都是同一个概念类别,都是“电视剧“的天龙八部。那么概念消歧做的任务就是将文本A和文本B中的天龙八部都划分到“电视剧”这一概念中,将文本C中的天龙八部划分到“漫画”这一概念中。
接下来本文简单介绍如何对命名实体进行概念消歧。
2 概念消歧流程
2.1 实体全体含义的获取
本文以天龙八部百度百科为数据源进行说明,首先要获取天龙八部这个实体所有含义的“描述”文本和“属性”表格,如下为天龙八部其中一个含义——1997黄日华版电视剧的“描述”文本和“属性”表格。
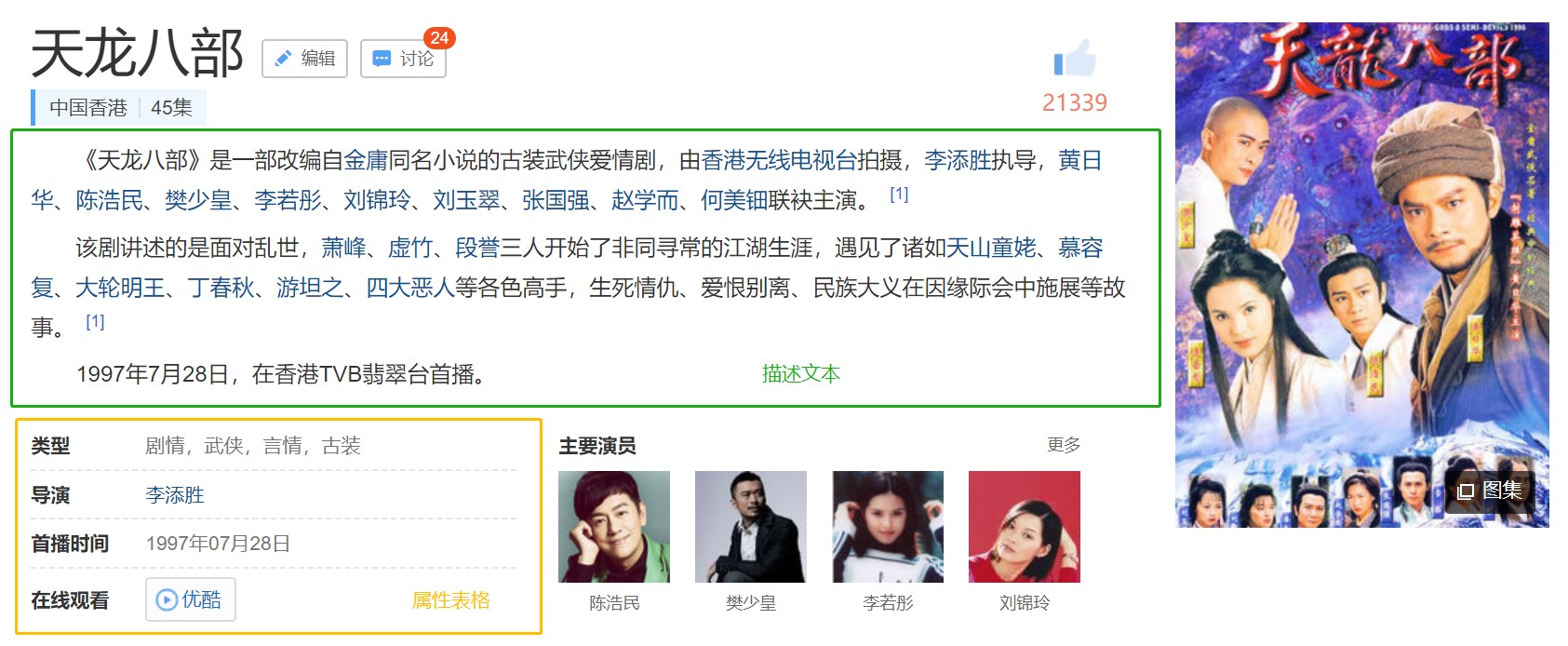
图2 需要爬取1997黄日华版电视剧的内容
2.2 文本分词构建关键词词组
得到每一个含义的“描述”文本和“属性”表格后,利用jieba分词工具对描述本文“《天龙八部》是一部改编自金庸同名小的古装爱情剧,由香港无线电视台……”进行分词处理,得到一些列词语构成的list1。然后从“属性”表格中提取“剧情,武侠,言情,古装”和“李添胜”等属性词,这些属性词又构成list2。接着合并list1和list2,就可以得到“1997黄日华版电视剧“含义的关键词词组。
对天龙八部每一个含义都进行如下处理,我们可得到如下所示的表格
| 含义 | 关键词词组 |
|---|---|
| 97黄日华版电视剧 | ["1997", "李添胜", "天龙八部", "黄日华", "樊少皇", "张国强", "陈浩民", "李若彤", "刘锦玲", "赵学而", "何美钿", "28", "陈国梁", "香港", "金庸", "武侠", "古装", "刘玉翠", "萧峰", "慕容复"] |
| 03内地胡军版电视剧 | ["电视剧", "2003", "古装", "于敏", "刘亦菲", "鞠觉亮", "周晓文", "赵箭", "林志颖", "12", "11", "22", "金鹰奖", "天龙八部", "高虎", "胡军", "刘涛", "陈好", "张纪中", "优秀作品"] |
| 82版香港电视剧 | ["虚竹", "1982", "天龙八部", "神剑", "黄日华", "黄杏秀", "之六脉", "萧笙", "梁家仁", "汤镇业", "陈玉莲", "石修", "TVB", "03", "22", "传奇", "武侠", "中国香港", "香港", "乔峰"] |
| 黄玉郎改编的漫画 | ["武林", "乔峰", "帮主", "黄玉郎", "天龙八部", "威名", "丐帮", "虚竹", "段家", "英雄辈出", "大宋", "他族", "大帮", "北乔峰", "之妻", "康敏", "堕地", "段誉", "胡绍权", "风云际会"] |
| 腾讯动漫的漫画 | ["漫画作品", "天龙八部", "连载", "腾讯", "动漫", "凤凰", "娱乐", "创作"] |
| …… | …… |
2.3 概念抽取和归并
上提及的“电视剧”、“漫画”这些概念不是凭空而来的,它是通过下述算法而得:
(1)含义标题分词和词性标注
使用jieba分词工具对含义标题 “1997年黄日华版电视剧”进行分词和词性标处理。我们可得到这样一个数组[['1997', 'm'], ['年', 'm'], ['黄日华', 'nz'], ['版', 'n'], ['电视剧', 'n']],第i个元素是一个由分词和对用词性组成的数组。
(2)获取概念候选词
只选取上一步中获取的名词词语,那么我们可以得到['黄日华', '版', '电视剧']
(3)确定候选词
通常含义标题最后一个名词往往是能代表此含义具体概念类别的词语,由上一步我们可知最后一个名词是“电视剧“,恰好符合标题对应概念。因此可得到如下列表
| 含义 | 关键词词组 | 概念 |
|---|---|---|
| 97黄日华版电视剧 | ["1997", "李添胜", "天龙八部", "黄日华", "樊少皇", "张国强", "陈浩民", "李若彤", "刘锦玲", "赵学而", "何美钿", "28", "陈国梁", "香港", "金庸", "武侠", "古装", "刘玉翠", "萧峰", "慕容复"] | 电视剧 |
| 03内地胡军版电视剧 | ["电视剧", "2003", "古装", "于敏", "刘亦菲", "鞠觉亮", "周晓文", "赵箭", "林志颖", "12", "11", "22", "金鹰奖", "天龙八部", "高虎", "胡军", "刘涛", "陈好", "张纪中", "优秀作品"] | 电视剧 |
| 82版香港电视剧 | ["虚竹", "1982", "天龙八部", "神剑", "黄日华", "黄杏秀", "之六脉", "萧笙", "梁家仁", "汤镇业", "陈玉莲", "石修", "TVB", "03", "22", "传奇", "武侠", "中国香港", "香港", "乔峰"] | 电视剧 |
| 黄玉郎改编的漫画 | ["武林", "乔峰", "帮主", "黄玉郎", "天龙八部", "威名", "丐帮", "虚竹", "段家", "英雄辈出", "大宋", "他族", "大帮", "北乔峰", "之妻", "康敏", "堕地", "段誉", "胡绍权", "风云际会"] | 漫画 |
| 腾讯动漫的漫画 | ["漫画作品", "天龙八部", "连载", "腾讯", "动漫", "凤凰", "娱乐", "创作"] | 漫画 |
| …… | …… | …… |
得到上述列表后易知,无论是“97黄日华版电视剧”,还是“03内地胡军版电视剧”,或者是“82版香港电视剧”它们都属于“电视剧”概念,它们都可以聚类成为“电视剧”这个概念类别。同理” 黄玉郎改编的漫画”和”腾讯动漫的漫画”也可以聚类成为“漫画”这个概念类别。因此对属于同一个概念的含义可以进行归并操作,即” 97黄日华版电视剧”、“03内地胡军版电视剧”和” 82版香港电视剧”可以,可得如下的概念归并后的

图3 概念归并后的词组
2.4 概念消歧
文本概念消歧分为两个步骤,第一步获得含义的文本向量,第二步是计算文本向量间余弦相似度来判断目标文本中命名实体属于哪个概念 (余弦相似度概念见术语解释)。
首先介绍第一步获得概念文本向量和目标文本向量。“电视剧”概念对应的关键词词组为["1997", "李添胜", "天龙八部", "黄日华", "樊少皇", "张国强", "陈浩民", "李若彤",……],假设"1997"对应的词向量为w1, "李添胜"对应的词向量为w2, "天龙八部"对应的词向量为w3,……。那么我们可以定义“97黄日华版电视剧”的概念文本向量T1 =(w1+w2+…wn)/n。对目标文本“港版天龙八部还是经典啊,黄日华才演出萧峰的气质”先进行jieba分词处理得到关键词,然后按上述步骤处理可获得目标文本向量。
通过余弦相似度计算你会发现目标文本向量和”电视剧”概念向量文本余弦相似度最大,所以目标文本中的概念应该对应“电视剧”这个概念。本文使用某开源的中文词向量进行文本到向量数值的映射,此开源的中文词向量的维度为200维度,包含几乎所有的中文词语和流行术语。
3 术语解释
3.1 命名实体
命名实体(英语:Named Entity),主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。指的是可以用专有名词(名称)标识的事物,一个命名实体一般代表唯一一个具体事物个体,包括人名、地名等。例如人名“爱因斯坦”、“牛顿”,地名“北京、“纽约”,机构名“好未来”,“清华大学”等都算一个命名实体。对命名实体的处理是NLP(英语Natural Language Processing,自然语言处理)领域一个重要的研究方向。
3.2 词向量
词向量(Word embedding),又叫Word嵌入式自然语言处理(NLP)中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。 从概念上讲,它涉及从每个单词一维的空间到具有更低维度的连续向量空间的数学嵌入。
3.3 余弦相似度
余弦相似度通过测量两个向量内积空间的夹角的余弦值来度量它们之间的相似性。0度角的余弦值是1,而其他任何角度的余弦值都不大于1。用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量,也就是衡量两个向量在方向上的差别。
结束语
当然在词类归并计算的时候还存在概念重复的情况,例如天龙八部词条中出现“1977年香港电视剧”、“2013年大陆影视剧”这时候按本文方法找到两个“不同”的概念,即“电视剧“和”影视剧“,显然这样数据出现冗余。当然这个文本也是有解决方案的,可以通过概念相似度计算、或者关键词聚类来进一步优化得到的概念数据,使得我们得到的概念数据中不出现上述的问题。最后希望本文能帮助到广大的NLPer在文本处理。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号