微服务之分布式搜索引擎elasticsearch
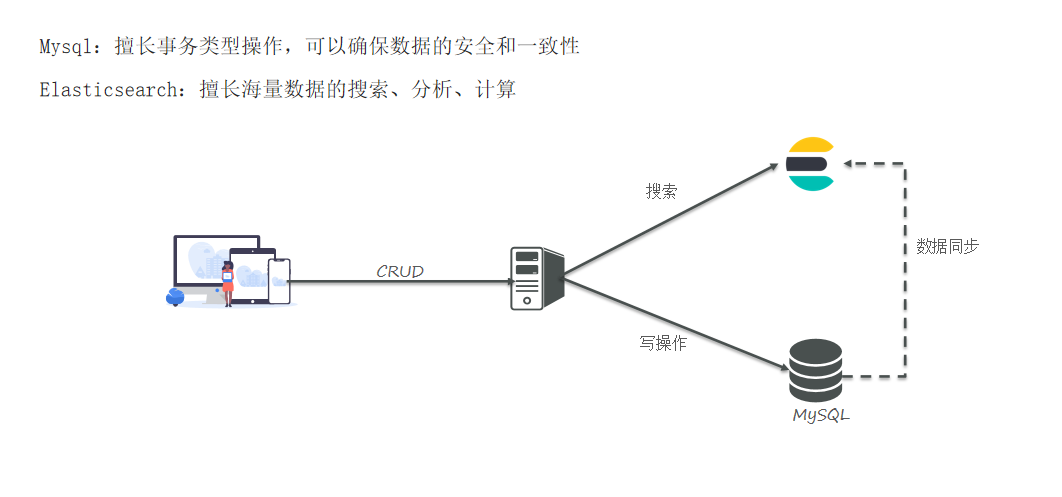
什么是elasticsearch
elasticsearch是一款非常强大的开源搜索引擎,可以帮助我们从海量数据中快速找到需要的内容。
elasticsearch结合kibana、Logstash、Beats,也就是elastic stack(ELK)。被广泛应用在日志数据分析、实时监控等领域。
elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。


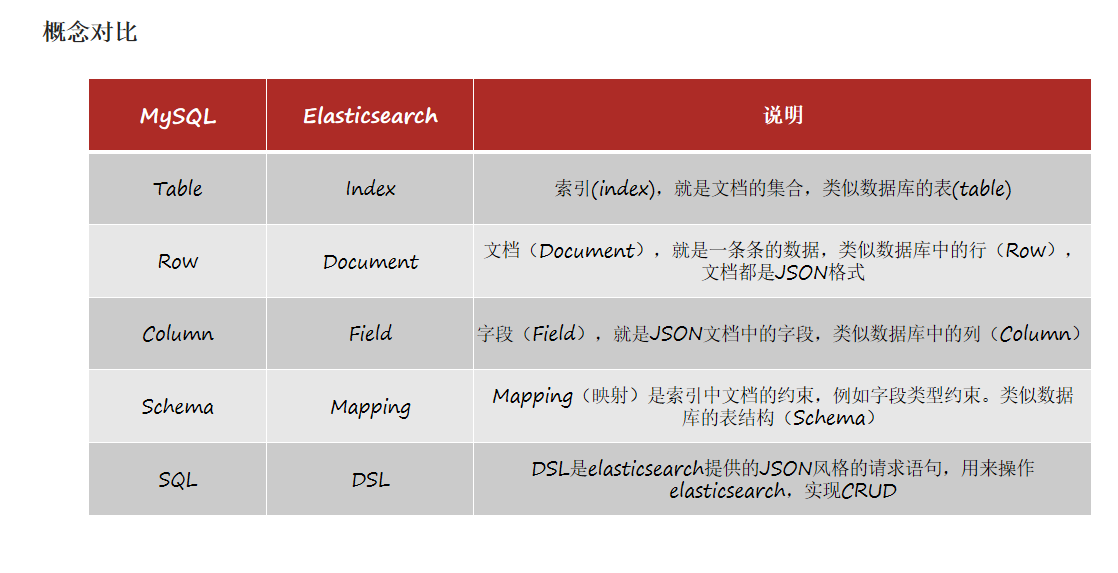
正向索引和倒排索引
传统数据库(如MySQL)采用正向索引
elasticsearch采用倒排索引: 文档(document):每条数据就是一个文档 词条(term):文档按照语义分成的词语
倒排索引中包含两部分内容:
词条词典(Term Dictionary):记录所有词条,以及词条与倒排列表(Posting List)之间的关系,会给词条创建索引,提高查询和插入效率
倒排列表(Posting List):记录词条所在的文档id、词条出现频率 、词条在文档中的位置等信息
文档id:用于快速获取文档 词条频率(TF):文档在词条出现的次数,用于评分

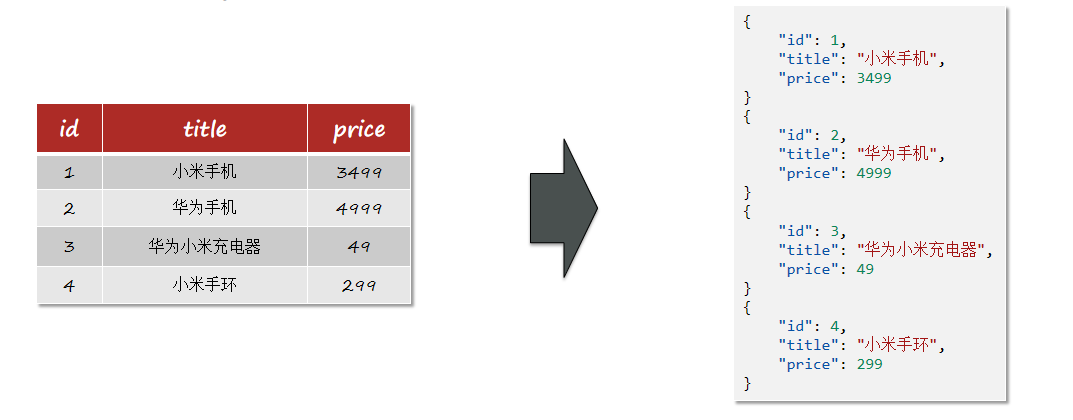
文档
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。 文档数据会被序列化为json格式后存储在elasticsearch中。


架构

安装elasticsearch
docker network create es-net
docker pull elasticsearch

docker run -d \ --name es \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network es-net \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:7.12.1
docker pull kibana //版本应该与es一致
docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://es:9200 \ --network=es-net \ -p 5601:5601 \ kibana:7.12.1
# 进入容器内部 docker exec -it elasticsearch /bin/bash # 在线下载并安装 ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zip #退出 exit #重启容器 docker restart elasticsearch

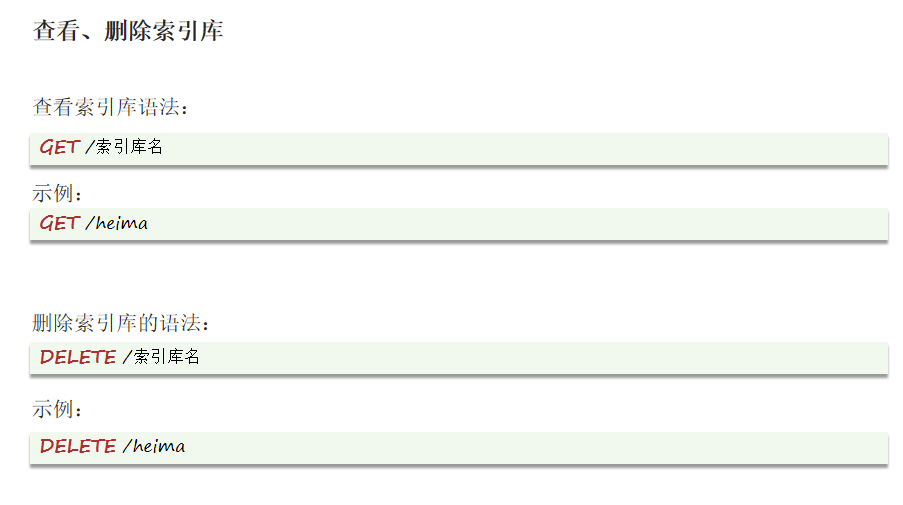
索引操作
mapping属性


创建索引库



文档操作




RestClient操作索引库
什么是RestClient


初始化JavaRestClient
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
2.因为SpringBoot默认的ES版本是7.6.2,所以我们需要覆盖默认的ES版本:
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
3.初始化RestHighLevelClient:
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200") ));
4:创建索引库
@Test void testCreateHotelIndex() throws IOException { // 1.创建Request对象 CreateIndexRequest request = new CreateIndexRequest("hotel"); // 2.请求参数,MAPPING_TEMPLATE是静态常量字符串,内容是创建索引库的DSL语句 request.source(MAPPING_TEMPLATE, XContentType.JSON); // 3.发起请求 client.indices().create(request, RequestOptions.DEFAULT); }
步骤5:删除索引库、判断索引库是否存在
@Test void testDeleteHotelIndex() throws IOException { // 1.创建Request对象 DeleteIndexRequest request = new DeleteIndexRequest("hotel"); // 2.发起请求 client.indices().delete(request, RequestOptions.DEFAULT); }
判断索引库是否存在
@Test void testExistsHotelIndex() throws IOException { // 1.创建Request对象 GetIndexRequest request = new GetIndexRequest("hotel"); // 2.发起请求 boolean exists = client.indices().exists(request, RequestOptions.DEFAULT); // 3.输出 System.out.println(exists); }

RestClient操作文档

步骤1:初始化JavaRestClient
public class ElasticsearchDocumentTest { // 客户端 private RestHighLevelClient client; @BeforeEach void setUp() { client = new RestHighLevelClient(RestClient.builder( HttpHost.create("http://192.168.150.101:9200") )); } @AfterEach void tearDown() throws IOException { client.close(); } }
步骤2:添加酒店数据到索引库
//先查询酒店数据,然后给这条数据创建倒排索引,即可完成添加: @Test void testIndexDocument() throws IOException { // 1.创建request对象 IndexRequest request = new IndexRequest("indexName").id("1"); // 2.准备JSON文档 request.source("{\"name\": \"Jack\", \"age\": 21}", XContentType.JSON); // 3.发送请求 client.index(request, RequestOptions.DEFAULT); }
步骤3:根据id查询酒店数据
@Test void testGetDocumentById() throws IOException { // 1.创建request对象 GetRequest request = new GetRequest("indexName", "1"); // 2.发送请求,得到结果 GetResponse response = client.get(request, RequestOptions.DEFAULT); // 3.解析结果 String json = response.getSourceAsString(); System.out.println(json); }
步骤4:根据id修改酒店数据
@Test void testUpdateDocumentById() throws IOException { // 1.创建request对象 UpdateRequest request = new UpdateRequest("indexName", "1"); // 2.准备参数,每2个参数为一对 key value request.doc( "age", 18, "name", "Rose" ); // 3.更新文档 client.update(request, RequestOptions.DEFAULT); }
步骤5:根据id删除文档数据
@Test void testDeleteDocumentById() throws IOException { // 1.创建request对象 DeleteRequest request = new DeleteRequest("indexName", "1"); // 2.删除文档 client.delete(request, RequestOptions.DEFAULT); }

利用JavaRestClient批量导入酒店数据到ES
void testBulkRequest() throws IOException { //批量查询酒店数据 List<Hotel> hotels = service.list(); //转换为文档类型 // 创建Request BulkRequest request = new BulkRequest(); //准备参数 ,添加多个新增的request for (Hotel hotel : hotels) { HotelDoc hotelDoc = new HotelDoc(hotel); //创建新增文档的request对象 request.add(new IndexRequest("hotel") .id(hotelDoc.getId().toString()) .source(JSON.toJSONString(hotelDoc),XContentType.JSON)); } //发送请求 client.bulk(request,RequestOptions.DEFAULT); }



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· C#/.NET/.NET Core优秀项目和框架2025年2月简报