

【数据结构】线性表—(静态)链表
本来要先讲数组的,介于之前已经总结过可变数组vector了,故不再开一个专题去介绍用法和原理。但是要提一嘴:
数组作为数据结构可以高效地存储和查询给定索引(下标)的数据,其时间复杂度均为O(1),因为这个性质,数组可以用来模拟其他很多数据结构,但是如果要将整个数组进行移位操作,例如在中间插入和删除数据,或者在没排序的情况下搜索指定元素,那么时间复杂度可达到O(n),效率很低的。
那么,我们就从链表开始学习数据结构吧!
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。但是我们这里先介绍静态链表(由数组模拟链表)以先了解链表的各项操作。简单来说:链表能知道每个元素之前/之后是谁,这样能恢复整个表的排列顺序。利用这种方式,来存储元素排列顺序的表,称为链表。
![]()
单链表由三个重要部分组成,next指针,value,idx指针,head指针分别用来记录后续节点的下标,当前节点的值,标明使用节点的指针,头指针。
struct ListNode {
int next;
int val;
ListNode(int _val=0,int _next=0) //初始化
{next=_next;val=_val;}
};
ListNode Node[MAXSIZE];
int idx; //当前用的元素的指针
//idx在我看来扮演两个角色,第一个是在一开始的时候,作为链表的下标,让我们好找
//第二在链表进行各种插入,删除等操作的时候,作为一个临时的辅助性的所要操作的元素的下
//标来帮助操作。并且是在每一次插入操作的时候,给插入元素一个下标,给他一个窝,感动!
/*
再次插句话,虽然我们在进行各种操作的时候,元素所在的下标看上去很乱,但是当我们访问的
时候,是靠着指针,也就是靠Node[].next来访问的,这样下标乱,也就我们要做的事不相关了。
另外,我们遍历链表的时候也是这样,靠的是Node[].next
*/
int head=-1; //初始化头指针,头指针初始时指向-1,之后指向插入的第一个元素现在,我们来学习链表的基本操作:
首先,如何把一个元素插入头节点后面呢?
1.头结点后面添加元素:
- 在val的idx处存储元素val[idx] = x;
- 该元素插入到头结点后面 next[idx] = head;
- 头结点指向该元素 head = idx;
- idx 指向下一个可存储元素的位置 idx++。
翻译成代码
void add_to_head (int x) {
Node[idx].val=x,Node[idx].next=head,head=idx++;
}//插入头节点的操作
//如何理解Node[idx].next=head呢?首先初始时head指向-1,我们插入一个新的元素,下一个元素也要指向-1,然后head指向idx的元素图解:

2.在索引k的数字后插入元素
- 在e的idx处存储元素val[idx] = x
- 该元素插入到第k个插入的数后面 next[idx] = next[k];
- 第k个插入的数指向该元素 next[k] = idx;
- idx 指向下一个可存储元素的位置 idx++。
代码实现如下
void add(int k,int x) {
Node[idx].val=x,Node[idx].next=Node[k].next,Node[k].next=idx++;
}//插入第k个节点的操作图解:
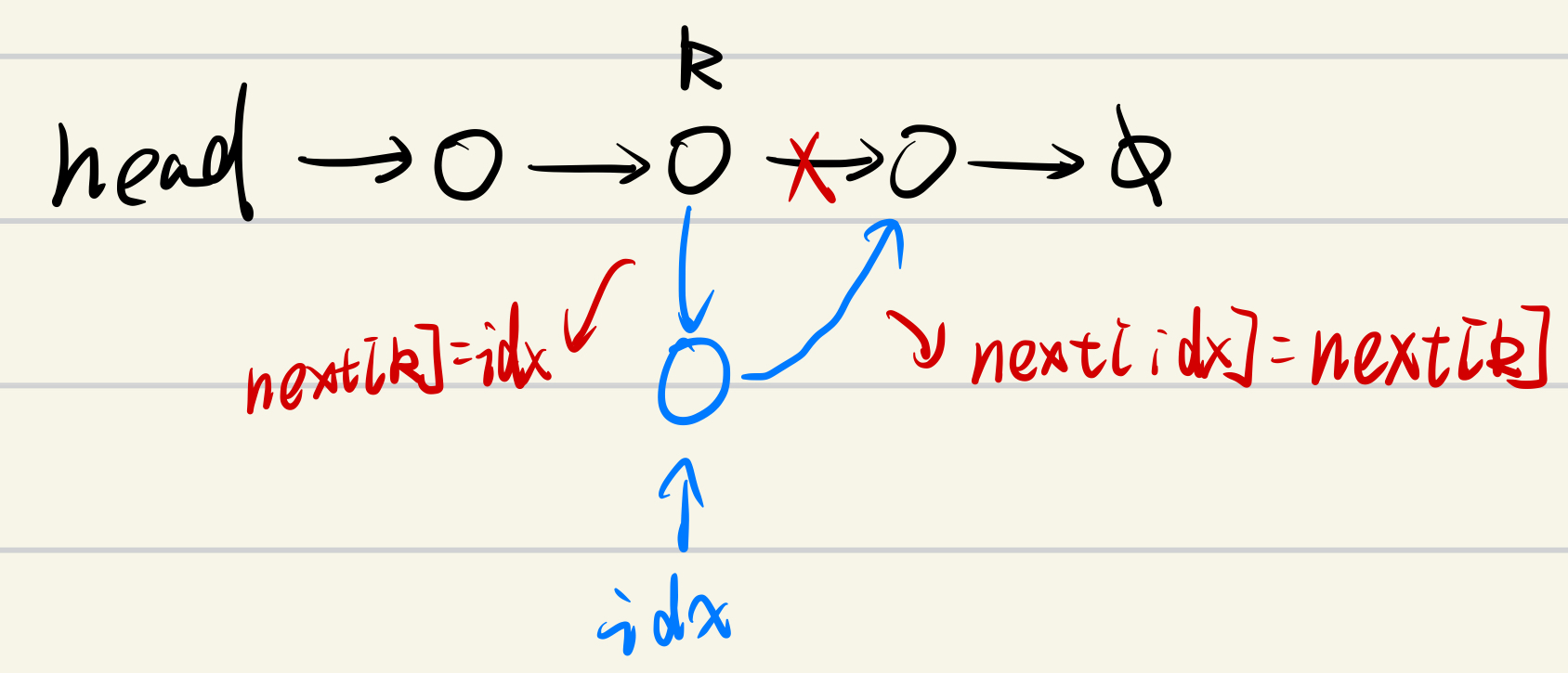
3.删除索引为k的元素后的元素
- next[k] 的值更新为 next[next[k]]
代码实现
void del(int k) {
Node[k].next = Node[Node[k].next].next;
}//删除操作图解:
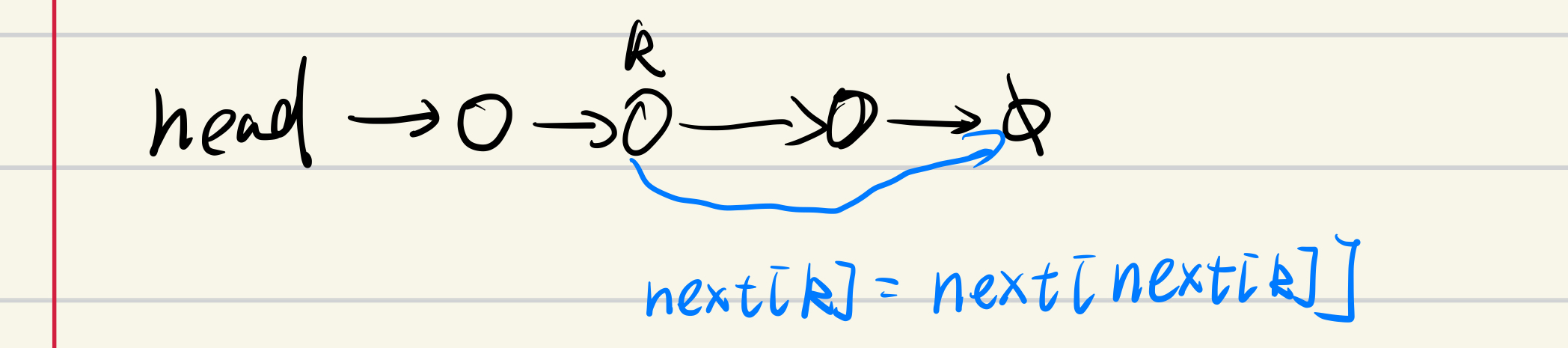
现在就来附上这道题的AC代码了:
https://www.acwing.com/file_system/file/content/whole/index/content/4008335/
#include<iostream>
using namespace std;
struct ListNode {
int next;
int val;
ListNode(int _val=0,int _next=0) //初始化
{next=_next;val=_val;}
};
ListNode Node[100010];
int idx; //当前用的元素的指针
int head=-1; //初始化头指针
void add_to_head (int x) {
Node[idx].val=x,Node[idx].next=head,head=idx++;
}//插入头节点的操作
void add(int k,int x) {
Node[idx].val=x,Node[idx].next=Node[k].next,Node[k].next=idx++;
}//插入第k个节点的操作
void del(int k) {
Node[k].next = Node[Node[k].next].next;
}//删除操作
int main() {
int m;
cin >> m;
for (int i = 0; i < m; i++) {
char g;
cin >> g;
if (g == 'H') {
int x;
cin >> x;
add_to_head(x);
}
else if (g == 'D') {
int k;
cin >> k;
if (!k) head = Node[head].next;
else del(k - 1); //为什么k-1呢,因为idx初始化为0
}
else if (g == 'I') {
int k, x;
cin >> k >> x;
add(k - 1, x);
}
}
for(int i=head;i!=-1;i=Node[i].next) cout << Node[i].val << " "; //遍历操作
return 0;
}某些令人疑惑的问题
1、对于删除头节点:head=Node[head].next的操作?
删除头结点是head指向的结点,也就是链表中的第一个结点,【head指向可能是一个空结点(val数组不存值),或者是非空结点。指向的空结点叫头结点,指向的非空结点叫首元结点,即后者并没有头结点这种概念】(这句只针对学过单链表的同学,没学过的同学不用理会这句话)。但是y总并没有区分这个概念,所以删除头结点就是删除链表的第一个有值的结点,即首元结点,head指向Node[head].next是因为head本来就指向它的下一个结点,所以next[head]就是头结点的下一个结点。
2、为什么最后一个节点的Node[idx].next一定等于-1?
首先这个head指的是链表中头节点的下标,当链表中没有节点时head = -1,但当链表中有值插到头节点的时候,head储存的就是这个值的idx1,通过val[idx1]可以求出这个节点的值。而next[idx1]就等于head之前的值,即-1。如果再在头节点插入一个元素,则head指向这个元素的idx2,而next[idx2]就等于上一次插入的head值,即idx1。此时,head = idx2,next[idx2] = idx1,next[idx1] = -1.
比如:因为初始化head=-1,head指向链表的头节点地址;例如输入H 9后,则有val[0] = 9; next[0] = -1;head=0;之后无论进行什么操作,链表最后一个节点,其对应的next数组值一定为-1。
双链表:
每个结点记录自己的前驱和后驱,与单链表只能往后走相比,它的好处是可以往前走和向后走,增加了前缀结点,一定程度上提升了查找元素的速度 在查找元素时,可以反向查找前缀结点。
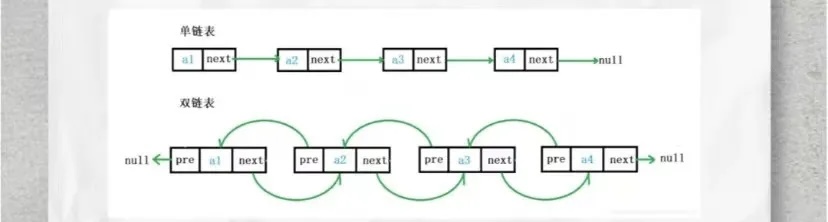
const int MAXSIZE = 1e5;
struct ListNode {
int pre,next;
int val;
ListNode (int _val=0,int _pre=0,int _next=0)
{pre=_pre;next=_next;val=_val;}
};
ListNode Node[MAXSIZE];
int head=0;
int tail=MAXSIZE-1;
int idx;首先先初始化双链表:
void init(){
Node[head].next = tail;
Node[tail].pre = head;
//这两个点是假想出来的,是为了方便边界处理,要不然又要写一个函数专门处理头和尾
//因为头和尾只有一边链子
idx=1;// 0地址已经被用过,从1开
}现在来介绍双链表的一些基本操作
1.往索引为k的右边插入新结点
直接上图解吧:
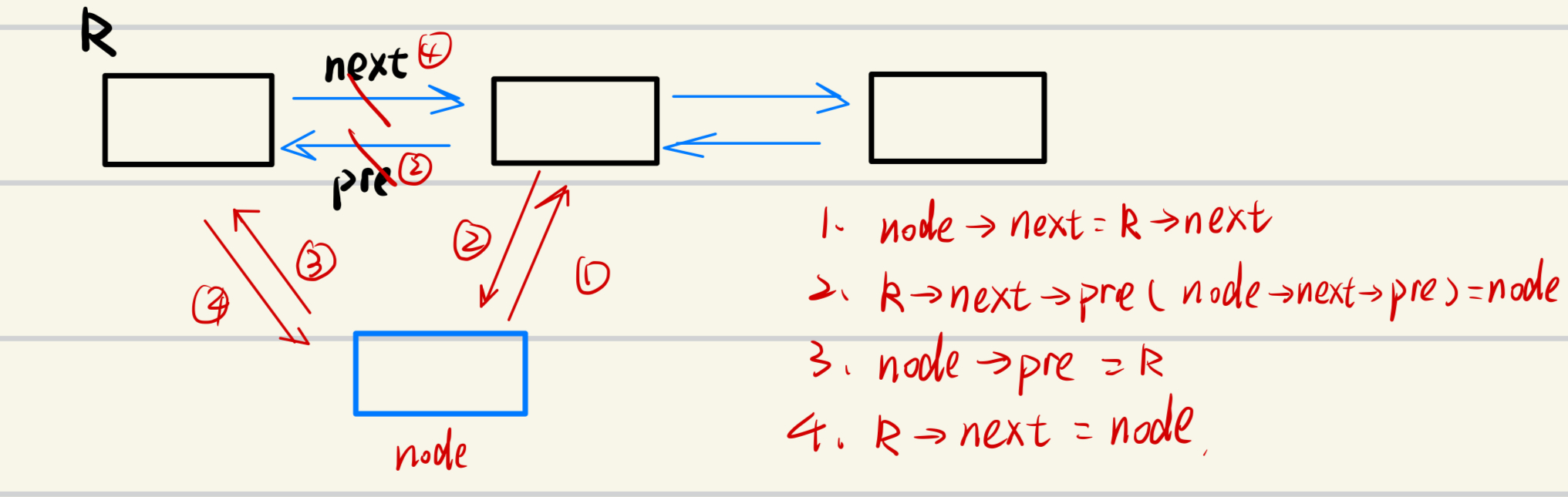
这四个步骤的顺序可调整,但是必须要保证需要的链不断!!比如,如果先做④再做①,画红叉的链断了,p->next为新的结点node了,那么node又怎么和后面的接结点连上呢?后面的结点已经不能通过p来找到了。
代码实现如下:
void rightInsert(int k, int x){
Node[idx].val = x;
Node[idx].next = Node[k].next;
Node[idx].pre = k;
Node[Node[k].next].pre = idx;
Node[k].next = idx;
idx++;
}
2.在索引为k的左边插入新结点
可以不用重新写一个函数,直接在k左边的结点进行往右边的插入就可以了
rightInsert(Node[k].pre,x)当然,为了锻炼代码能力,我也写一个leftInsert函数吧
图解如下: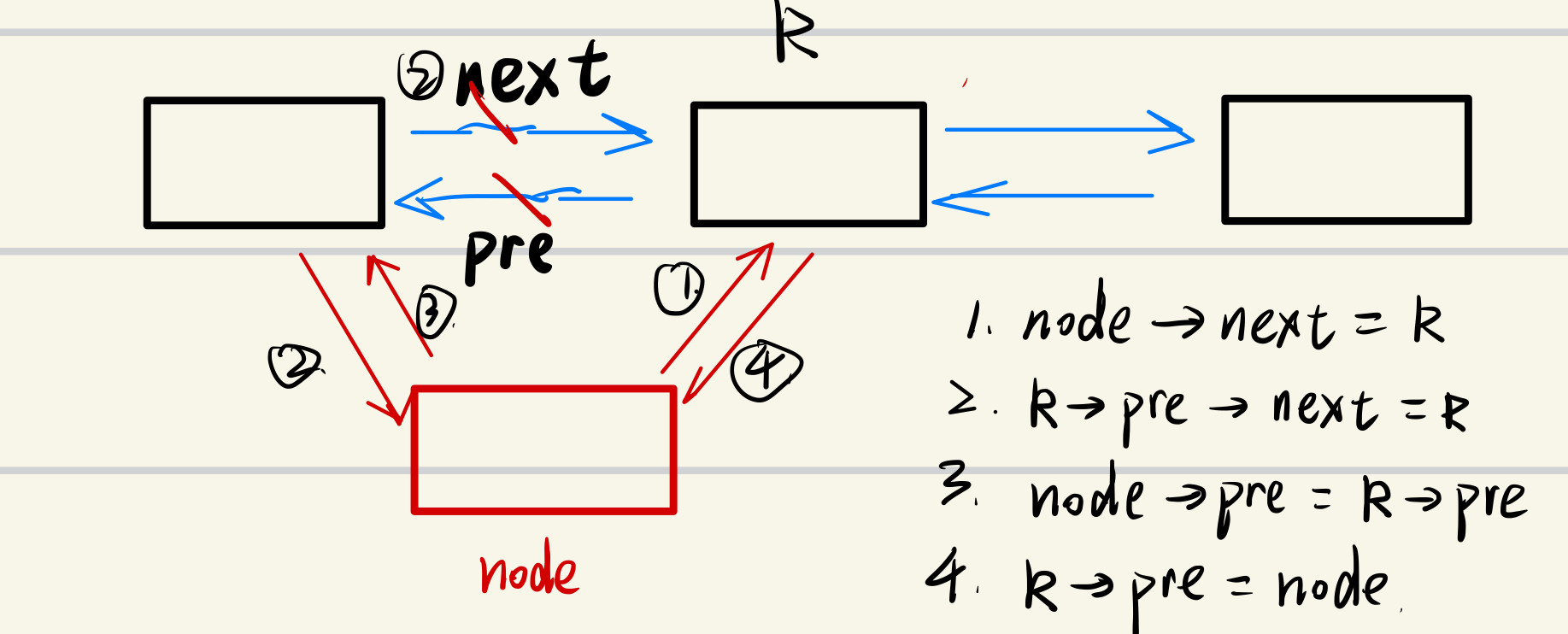
代码实现如下:
void leftInsert(int k,int x) {
Node[idx].val=x;
Node[idx].next = k;
Node[Node[k].pre].next=k;
Node[idx].pre=Node[k].pre;
Node[k].pre=idx;
idx++;
}
3.删除操作
图解如下: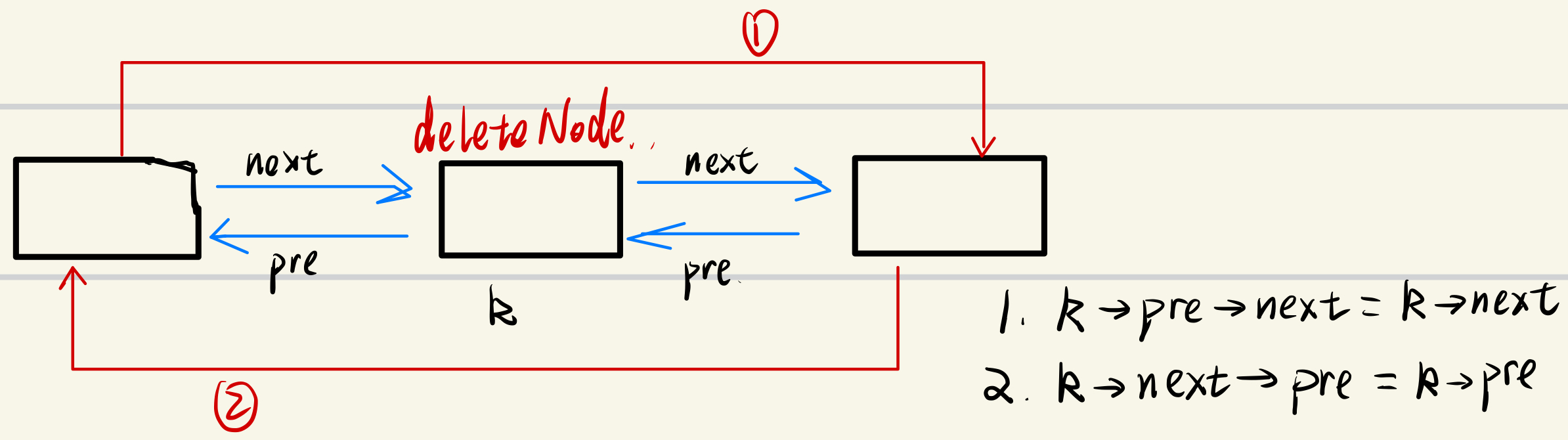
代码实现如下:
void del(int k) {
Node[Node[k].pre].next=Node[k].next;
Node[Node[k].next].pre=Node[k].pre;
}
现在我们给出这一题的AC代码:
#include<iostream>
using namespace std;
const int MAXSIZE = 1e5+10;
struct ListNode {
int pre,next;
int val;
ListNode (int _val=0,int _pre=0,int _next=0)
{pre=_pre;next=_next;val=_val;}
};
ListNode Node[MAXSIZE];
int head=0;
int tail=MAXSIZE-1;
int idx;
void init(){
Node[head].next = tail;
Node[tail].pre = head;
//这两个点是假想出来的,是为了方便边界处理,要不然又要写一个函数专门处理头和尾
//因为头和尾只有一边链子
idx=1;// 0地址已经被用过,从1开
}
void rightInsert(int k, int x){
Node[idx].val = x;
Node[idx].next = Node[k].next;
Node[idx].pre = k;
Node[Node[k].next].pre = idx;
Node[k].next = idx;
idx++;
}
void remove(int k) {
Node[Node[k].pre].next=Node[k].next;
Node[Node[k].next].pre=Node[k].pre;
}
int main(){
int m;
char op[5];
int k, num;
init();
cin>>m;
while(m--){
scanf("%s", op);
if(string(op) == "R"){
cin>>num;
rightInsert(Node[tail].pre, num);
}else if(string(op) == "D"){
cin>>k;
remove(k);
}else if(string(op) == "L"){
cin>>num;
rightInsert(head, num);
}else if(string(op) == "IL"){
cin>>k>>num;
rightInsert(Node[k].pre, num);
}else if(string(op) == "IR"){
cin>>k>>num;
rightInsert(k, num);
}
}
int p = Node[head].next;
while(p != tail){
cout<<Node[p].val<<" ";
p = Node[p].next;
}
return 0;
}
一些链表的常见操作补充:
(找个时间来写) 鸽鸽鸽~ Dec 27,2023
STL中的链表
链表一样可以使用STL来简化操作,只需要#include<list>
以下是一些常用的方法
1)list<int>a;:定义一个int类型的链表a
2)int arr[5]={1,2,3};list<int> a(arr,arr+3);;从数组arr中的前三个元素作为链表a的初始值
3)a.size();:返回链表的结点数量
4)list<int>::iterator it;:定义名字为it的迭代器
5)a.begin();a.end();:链表开始和末尾的迭代器指针
6)it++;it--;:迭代器分别指向后一个元素和前一个元素
7)a.pop_front();a.pop_back();:在链表开头或者末尾删除元素
8)a.insert(it,x);:在迭代器it前插入元素x
9)a.push_front(x);a.push_back(x);:在链表开头或者末尾插入元素x
10)a.erase(it);:删除迭代器it所指向的元素
11)for (it=a.begin();i!=a.end();i++):遍历链表
为什么不用课本上学的结构体来构造链表??
学过数据结构课的人,对链表的第一反应就是:
链表由节点构成,每个节点保存了 值 和 下一个元素的位置 这两个信息。节点的表示形式如下:
class Node{
public:
int val;
Node* next;
};这样构造出链表节点的是一个好方法,也是许多人一开始就学到的。
使用这种方法,在创建一个值为 x 新节点的时候,语法是:
Node* node = new Node();
node->val = x
看一下创建新节点的代码的第一行:
Node* node = new Node();,中间有一个 new 关键字来为新对象分配空间。
new的底层涉及内存分配,调用构造函数,指针转换等多种复杂且费时的操作。一秒大概能new1w次左右。
在平时的工程代码中,不会涉及上万次的new操作,所以这种结构是一种 见代码知意 的好结构。
但是在算法比赛中,经常碰到操作在10w级别的链表操作,如果使用结构体这种操作,是无法在算法规定时间完成的。
所以,在算法比赛这种有严格的时间要求的环境中,不能频繁使用new操作。也就不能使用结构体来实现数组。
当然,有时间我也会把动态链表学一遍的


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构