
【模版】离散化
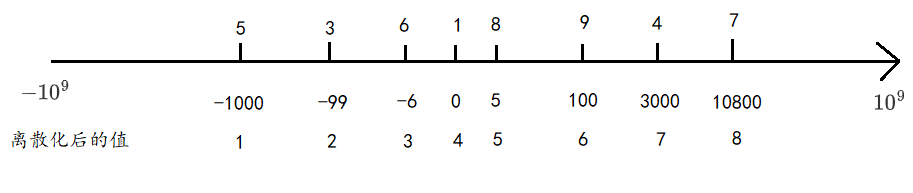
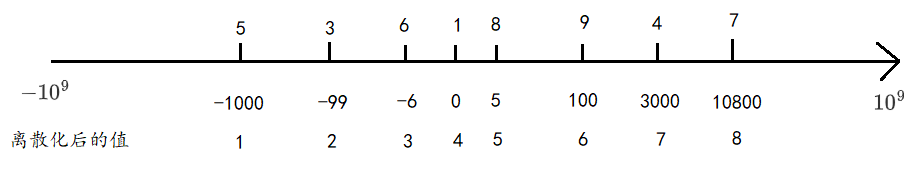
在一些场景或题目中,常常会遇到数据跨度较大的一堆数据。如果需要用连续空间存储,则会有大量空闲的空间,并且遍历的时间复杂取决于最大和最小值的间距。
如果不关系数据的具体大小,只关心数据的相对顺序。离散化,就是当我们只关心数据的大小关系时,用排名代替原数据进行处理的一种预处理方法。离散化本质上是一种哈希,它在保持原序列大小关系的前提下把其映射成正整数。当原数据很大或含有负数、小数时,难以表示为数组下标。
离散化的本质,是映射,将间隔很大的点,映射到相邻的数组元素中。减少对空间的需求,也减少计算量。映射最大的难点是前后的映射关系,如何能够将不连续的点映射到连续的数组的下标。一般解决办法就是开辟额外的数组存放原来的数组下标,或者说下标标志。
例题:
为什么要离散化:因为我们无法开辟2*109长度的数组,并且实际用到的数据又很少。
(虽然叫离散化,但是我的感觉确实把离散的数据变得连续起来ww有点疑惑)
思路
1、读入所有操作数据
2、离散化数据。将 n 次操作的坐标,m 次查询的 [l, r] 进行离散化
3、求离散化后数据前缀和
4、将 m 次查询的区间和输出。注意 l 和 r 都需要对应到离散化数据
AC代码如下,直接看注释吧qwq
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 300010; //n次插入和m次查询相关数据量的上界,看看n和m的数据范围,最多输出三组坐标,故上界为3*1e5
int n, m;
int a[N];//存储坐标插入的值
int s[N];//存储数组a的前缀和
vector<int> alls; //存储(所有与插入和查询有关的)坐标
vector<pair<int, int>> add, query; //存储插入和询问操作的数据
int find(int x) { //返回的是输入的坐标的离散化下标
int l = 0, r = alls.size() - 1;
while (l < r) {
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1; //为什么返回r+1呢?因为我们希望数组离散化后从1开始
}
//其实可以直接用lower_bound()替代,需不需要手写二分看情况吧
int main() {
scanf("%d%d", &n, &m);
for (int i = 1; i <= n; i++) {
int x, c;
scanf("%d%d", &x, &c);
add.push_back({x, c});
alls.push_back(x);
}
for (int i = 1; i <= m; i++) {
int l , r;
scanf("%d%d", &l, &r);
query.push_back({l, r});
alls.push_back(l);
alls.push_back(r); //这里就体现了用vector的好处,直接往后插入就行,不用vector的话循环次数是2*m,并且要考虑下标赋值,还浪费空间
}
//排序,去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls.begin(), alls.end()), alls.end()); //非常重要的操作x(unique()返回的是指针)
//执行前n次插入操作
for (auto item : add) {
int x = find(item.first); //离散化坐标,以数组下标为映射结果
a[x] += item.second;
}
//前缀和
for (int i = 1; i <= alls.size(); i++) s[i] = s[i-1] + a[i];
//处理后m次询问操作
for (vector<pair<int, int>>::iterator item = query.begin();item != query.end();item++) { //直接用增强for循环,就像42行一样
int l = (lower_bound(alls.begin(),alls.end(),item->first) - alls.begin())+1;//映射后的位置,+1是为了让映射结果从1开始
int r = (lower_bound(alls.begin(),alls.end(),item->second) - alls.begin())+1;
printf("%d\n", s[r]-s[l-1]);
}
return 0;
}
这边提一嘴一两个月前令我疑惑的vector<pair<int, int>>吧,不过现在其实脑子里其实已经知道是啥玩意了x记下来防止以后懵逼
vector<pair<int,int>>用法:
vector的这种用法有点类似于map。
与map不同的是:
map会对插入的元素按键自动排序,而且不允许键重复。
vector的这种用法不会自动排序,而且允许重复。
其实也可以用map离散化哦ww下面是这个题的map版本题解
#include<bits/stdc++.h>
using namespace std;
typedef pair<int, int> PII;
const int N = 3e5 + 10;
int n, m, x, c, l, r;
vector<PII> add, query;
int a[N], s[N];
map<int, int> h; // 哈希表存储离散关系
int main() {
ios::sync_with_stdio(false); //cin读入优化
cin.tie(0);
cin >> n >> m;
// n次插入
for (int i = 1; i <= n; i++) {
cin >> x >> c;
add.push_back({x, c});
h[x] = 1; // 将当前下标加入哈希表中
}
// m次查询
for (int i = 1; i <= m; i++) {
cin >> l >> r;
query.push_back({l, r});
h[l] = 1, h[r] = 1; // 将当前下标加入哈希表中;
}
// 更新哈希表
// 哈希表中的first为原下标
// second值为离散化后的坐标(从1开始)
// PS: map默认按照key值从小到大排序(unordered_map不会自动排序),且自动去重
int idx = 1;
for (auto &t: h) { // 使用auto修改map值时,需要添加引用符号&
t.second = idx; //t.second = idx++也行
idx++;
}
// 哈希表更新后,原坐标x的离散化坐标即为h[x]
// 更新a数组
for (auto t: add) {
x = t.first, c = t.second;
a[h[x]] += c;
}
// 计算前缀和数组
for (int i = 1; i <= h.size(); i++) s[i] = s[i - 1] + a[i];
// 查询
for (auto t: query) {
l = h[t.first], r = h[t.second];
cout << s[r] - s[l - 1] << endl;
}
return 0;
}

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】