
吴恩达 — 神经网络与深度学习 — L1W2编程作业
第二周编程作业
import numpy as np
import matplotlib.pyplot as plt
import h5py
def load_dataset():
# 读入训练数据
train_datasets = h5py.File('./datasets/train_catvnoncat.h5')
train_x = np.array(train_datasets['train_set_x'][:])
train_y = np.array(train_datasets['train_set_y'][:])
# 读入测试数据
test_datasets = h5py.File('./datasets/test_catvnoncat.h5')
test_x = np.array(test_datasets['test_set_x'][:])
test_y = np.array(test_datasets['test_set_y'][:])
# 读入类别
classes = np.array(test_datasets['list_classes'][:])
# 改变标签的维度,避免rank1数据结构
print(train_y.shape)
train_y = train_y.reshape((1, train_y.shape[0]))
test_y = test_y.reshape((1, test_y.shape[0]))
print(train_y.shape)
return train_x, train_y, test_x, test_y, classes
# 读取数据
train_x, train_y, test_x, test_y, classes = load_dataset()
# index属于[0, 209)
index = int(np.random.rand()*train_x.shape[0])
print("index = {0:d}".format(index))
plt.title(classes[train_y[0][index]])
plt.imshow(train_x[index])

# np.squeeze(train_y[:,index])是为了压缩维度,未压缩前为[1],压缩后为1
print("y=" + str(train_y[:,index]) + ", it's a " + classes[np.squeeze(train_y[:,index])].decode("utf-8") + "' picture")
m_train: 训练集里面的图片数量
m_test: 测试集里面的图片数量
num_px: 训练,测试集里面图形的高度和宽度(64*64)
train_x维度: (m_train, num_px, num_px, 3)
test_x维度: (m_test, num_px, num_px, 3)
train_y维度: (1, m_train)
test_y维度: (1, m_test)
m_train = train_x.shape[0]
m_test = test_y.shape[0]
num_px = train_x.shape[1]
print('训练集的数量: m_train={:d}'.format(m_train))
print('测试集的数量: m_test={:d}'.format(m_test))
print('图片的像素点宽高: num_px={:d}'.format(num_px))
print('每张图片大小({0:d},{1:d},{2:d})'.format(num_px, num_px, 3))
print('训练数据图片维度: train_x={:}'.format(train_x.shape))
print('训练数据标签维度: train_y={:}'.format(train_y.shape))
print('测试数据图片维度: train_x={:}'.format(test_x.shape))
print('测试数据标签维度: train_y={:}'.format(test_y.shape))
为了方便起见,我们将维度(64,64,3)的numpy数组转变为(64643,1)的数组 乘3的原因是因为每张图片由64*64的像素点构成,每个像素点由RGB三通道构成 所以要乘3。之后训练集和测试集得到了两个numpy数组,每列代表一个平坦的图形 应该由m_train列,m_test列
# .T表示矩阵的转置
# reshape中的-1表示让计算机计算这个维度,但只可以有一个-1,比如(209,64,64,3)reshape为(209,-1),计算机会计算-1为64*64*3=12288
# 加上转置后,每一列相当于一个平坦的图像
train_x_flat = train_x.reshape(train_x.shape[0], -1).T
test_x_flat = test_x.reshape(test_x.shape[0], -1).T
print('训练数据降维后的维度: train_x={:}'.format(train_x_flat.shape))
print('训练数据标签维度: train_y={:}'.format(train_y.shape))
print('测试数据降维后的维度: train_x={:}'.format(test_x_flat.shape))
print('测试数据标签维度: train_y={:}'.format(test_y.shape))
为了表示彩色图像,必须为每个像素指定红色,绿色和蓝色通道(RGB),因此像素值实际上是从0到255范围内的三个数字的向量。机器学习中一个常见的预处理步骤是对数据集进行居中和标准化,这意味着可以减去每个示例中整个numpy数组的平均值,然后将每个示例除以整个numpy数组的标准偏差。但对于图片数据集,它更简单,更方便,几乎可以将数据集的每一行除以255(像素通道的最大值),因为在RGB中不存在比255大的数据,所以我们可以放心的除以255,让标准化的数据位于[0,1]之间,现在标准化我们的数据集:
# 数据标准化
train_x = train_x_flat/255
test_x = test_x_flat/255
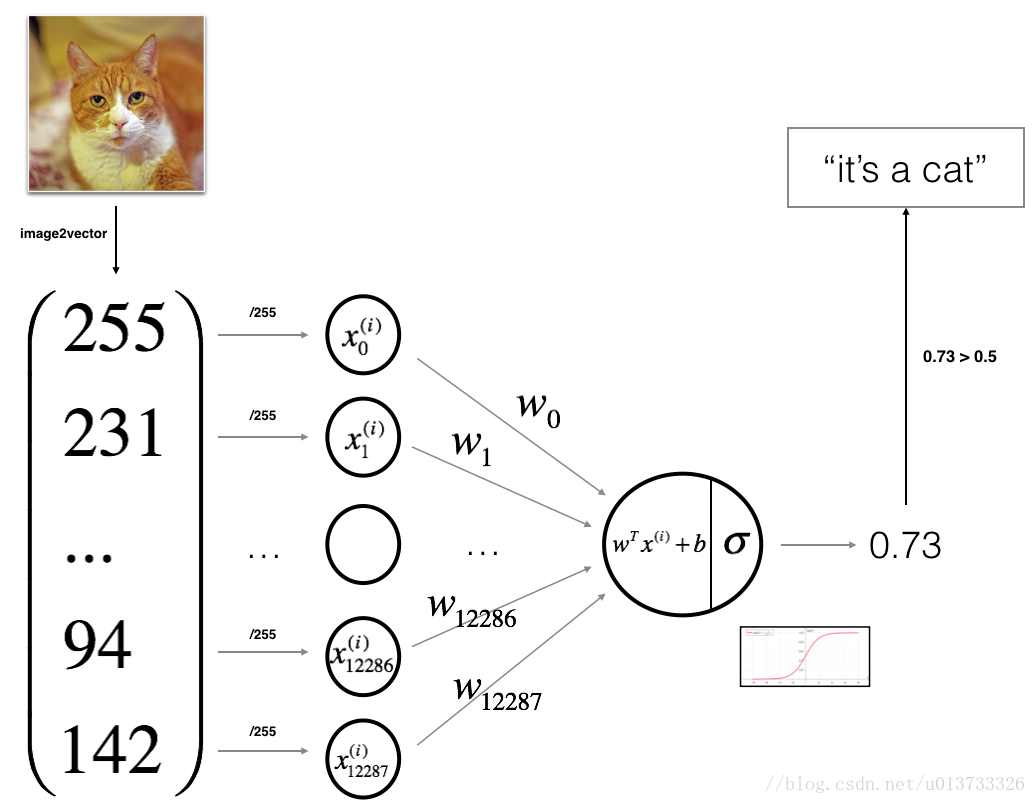

建立神经网络步骤
1.定义好模型结构,如输入特征数量,权值数组,偏置
2.初始化模型参数
3.循环
3.1 计算当前损失(forward propagation)
3.2 计算当前梯度(backward propagation)
3.3 更新参数(gradient descent)
activation function:sigmoid()函数
要使用sigmoid计算预测值
def sigmoid(z):
'''
参数:
z - 任意numpy数组
返回:
return - sigmoid(z)
'''
return 1/(1+np.exp(-z))
# 测试sigmoid函数
# 可以看出值越大,或者越小,梯度越小
print('sigmoid(0) = {:.3}, g\'(0) = {:.3}'.format(sigmoid(0), sigmoid(0)*(1-sigmoid(0))))
print('sigmoid(10) = {:.3}, g\'(5) = {:.3}'.format(sigmoid(5), sigmoid(5)*(1-sigmoid(5))))
print('sigmoid(-10) = {:.3}, g\'(-5) = {:.3}'.format(sigmoid(-5), sigmoid(-5)*(1-sigmoid(-5))))
sigmoid函数定义好了,接下来定义初始化权值参数w和偏置b
def initialize_with_zero(dim):
'''
此函数为w创建一个维度为(dim,1)的0向量,b初始化为0
参数:
dim - 表示w的维度
返回
w - 维度为(dim, 1)的列向量
b - 偏置,值为0
'''
w = np.zeros((dim, 1))
b = 0
# 用断言来判断数据是否符合条件
assert(w.shape == (dim, 1)) #判断w维度是否是(dim,1)
assert(isinstance(b, float) or isinstance(b, int))#判断b是否是浮点型或者整形
return w, b
初始化参数的函数已经定义好了
现在我们定义'前向'和'反向传播',来学习参数
def propagate(w, b, X, Y):
'''
实现前向和反向传播计算成本函数和梯度
参数:
w - 权值,一个维度为(num_px*num_px*3,1)的数据
b - 偏置,一个标量
X - 训练数据,维度为(num_px*num_px*3, m_train)
Y - 训练数据标签,维度为(1, m_train)
返回:
cost - 逻辑回归的负对数最大似然成本
dw - 权值数组w的损失梯度,与w的shape一致
db - b的损失梯度,与b的shape一致
'''
epsilon = 1e-5
m = X.shape[1]
# 正向传播
# w.T.shape=(1, num_px*num_px*3), X.shape=(num_px*num_px*3, m)
Z = np.dot(w.T, X)+b #shape=(1, m)
A = sigmoid(Z)
cost = (-1/m)*np.sum(Y*np.log(A+epsilon)+(1-Y)*np.log(1-A+epsilon))
#反向传播
dz = A-Y #shape(1,m)
dw = (1/m)*np.dot(X, dz.T)
db = (1/m)*np.sum(dz)
#使用断言确保数据正确
assert(dw.shape==w.shape)
assert(db.dtype==float)
cost = np.squeeze(cost)
assert(cost.shape==())
#创建一个字典把dw,db存起来
grads = {
'dw':dw,
'db':db
}
return (grads, cost)
#测试一下propagate
print("------propagate------")
# 初始化一些参数
w, b, X, Y = np.array([[1],[2]]), 1.2, np.array([[1,0],[2,0.5]]), np.array([[1, 0]])
grads, cost = propagate(w, b, X, Y)
print("dw = {:}".format(grads['dw']))
print("db = {:}".format(grads['db']))
print("cost = {:}".format(cost))
目标是通过最小化成本函数J来学习w和b
α为学习率
更新规则为:
w = w-αdw
b = b-αdb
def optimize(w, b, X, Y, num_iterations, learning_rate, print_cost):
'''
此函数使用梯度下降法最小化成本函数J优化参数w和b
参数:
w - 权值参数,维度为(num_px*num_px*3, 1)的数组
b - 偏置,一个标量
X - 训练数据,维度为(num_px*num_px*3, m_train)的数组
Y - 训练数据标签,维度为(1, m_train)的数组
num_iterations - 优化迭代的次数
learning_rate - 学习率
print_cost - 每一百步打印一次损失值
返回:
params - 包含权值w和偏置b的字典
grads - 包含当前成本函数对权值w和b的梯度字典
costs - 优化迭代期间保存的成本损失
提示:
我们需要写下两个步骤来进行迭代优化
1,计算当前参数的成本和梯度,使用propagate()函数
2,使用梯度下降法更新w,b
'''
costs = []
for i in range(num_iterations):
grads, cost = propagate(w, b, X, Y)
dw = grads['dw']
db = grads['db']
#梯度下降法更新参数
w = w-learning_rate*dw
b = b-learning_rate*db
if(i%100==0):
# 记录成本
costs.append(cost)
#print(costs)
if(print_cost) and (i%100==0):
print("迭代次数{:d}, cost={:}".format(i, cost))
params = {
'w':w,
'b':b,
}
grads = {
'dw':dw,
'db':db,
}
return (params, grads, costs)
#测试一下optimize
print("------optimize------")
# 初始化一些参数
w, b, X, Y = np.array([[1],[2]]), 1.2, np.array([[1,0],[2,0.5]]), np.array([[1, 0]])
params, grads, costs = optimize(w, b, X, Y, 10000, 0.01, True)
print("w = {:}".format(params['w']))
print("b = {:}".format(params['b']))
print("dw = {:}".format(grads['dw']))
print("db = {:}".format(grads['db']))
print("costs = {:}".format(costs))
optimize()函数会计算得到优化后的参数w,b,我们可以使用w,b来预测数据集的标签
现在我们编写optimize()函数只要包括两个步骤
1,A = y hat = sigmoid(w.T+b)
2,如果A<=0,A赋值为0,如果A>0.5,A赋值为1
然后将预测值存入:Y_prediction
def predict(w, b, X):
'''
此函数使用参数w,b来预测X的标签为0还是1
参数:
w - 权值参数,维度为(num_px*num_px*3, 1)的数组
b - 偏置,一个标量
X - 预测的样本数据,维度为(num_px*num_px*3, m),m表示样本数量
返回:
Y_prediction - X的预测标签,维度为(1, m)
'''
m = X.shape[1]
Y_prediction = np.zeros((1,m))
w = w.reshape((X.shape[0],1))
# 计算每张图片是cat的概率
A = np.dot(w.T, X)+b
for i in range(A.shape[1]):
# 计算出X对应的标签
Y_prediction[0, i] = 1 if A[0,i]>0.5 else 0
#
assert(Y_prediction.shape == (1,m))
return Y_prediction
#测试一下optimize
print("------optimize------")
# 初始化一些参数
w, b, X, Y = np.array([[1],[2]]), 1.2, np.array([[1,0],[2,0.5]]), np.array([[1, 0]])
params, grads, costs = optimize(w, b, X, Y, 10000, 0.01, True)
Y_prediction = predict(params['w'], params['b'], X)
print('predict = {:}'.format(Y_prediction))
把所有函数整合到一个model函数里面完成
def model(X_train, Y_train, X_test, Y_test, num_iterations=2000, learning_rate=0.01, print_cost=False):
'''
此函数通过调用前面定义的函数完成logistic regession模型构建
参数:
X_train - 训练数据,维度为[num_px*num_px*3, m_train]的数组
Y_train - 训练数据的标签,维度为[1, m_train]的数组
Y_train - 测试数据,维度为[num_px*num_px*3, m_test]的数组
Y_test - 测试数据的标签,维度为[1, m_test]的数组
num_iterations - 优化迭代的轮数,默认值为2000
learning_rat - 学习率,默认值为0.1
print_cost - 每一百轮输出成本损失
返回
d - 包含有关模型信息的字典
'''
# 初始化权值w和偏置
w, b = initialize_with_zero(X_train.shape[0])
# 使用梯度下降法最下化成本损失值,优化得到w,b
params, grads, costs = optimize(w, b, X_train, Y_train, num_iterations, learning_rate, print_cost)
# 取出优化得到的w,b
w = params['w']
b = params['b']
# 使用predict()函数预测训练数据和测试数据的标签
Y_prediction_train = predict(w, b, X_train)
Y_prediction_test = predict(w, b, X_test)
# 计算准确率
acc_train = np.sum(Y_prediction_train==Y_train,dtype=np.float64)/Y_train.shape[1]
acc_test = np.sum(Y_prediction_test==Y_test)/Y_test.shape[1]
# 打印准确率
print("训练集准确率为:{:.3}".format(acc_train))
print("测试集准确率为:{:.3}".format(acc_test))
d = {
'w':w,
'b':b,
'costs':costs,
'Y_prediction_train':Y_prediction_train,
'Y_prediction_test':Y_prediction_test,
'learning_rate':learning_rate,
'num_iterations':num_iterations,
}
return d
print("------测试model------")
# 这里使用真实数据
d = model(train_x, train_y, test_x, test_y,print_cost=True, learning_rate=0.005, num_iterations=2000)
# 绘制图
costs = np.squeeze(d['costs'])
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
plt.title('learning rate = {:}'.format(d['learning_rate']))

进一步探讨学习率的选择对模型训练速度和模型效果的影响
学习率决定我们更新参数的速度
如果学习率过高,我们可能超过最优值
如果学习率过低,学习迭代的次数就过高
我们可以比较一下不太学习率的效果
learning_rates = [0.1, 0.01, 0.001]
models = {}
for i in learning_rates:
print("learning_rate = {:}".format(i))
models[str(i)] = model(train_x, train_y, test_x, test_y, learning_rate=i)
print("\n-------------------------------------\n")
for i in learning_rates:
plt.plot(np.squeeze(models[str(i)]['costs']), label=str(models[str(i)]['learning_rate']))
plt.ylabel('cost')
plt.xlabel('iterations (per hundreds)')
legend = plt.legend(loc='upper center', shadow=True)
frame = legend.get_frame()
frame.set_facecolor('0.90')
plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号