
Apache PredictionIO在Docker上的搭建及使用
1、Apache PredictionIO介绍
Apache PredictionIO 是一个孵化中的机器学习服务器,它可以为为开发人员和数据科学家创建任何机器学习任务的预测引擎。官方原文:
Apache PredictionIO (incubating) is an open source Machine Learning Server built on top of a state-of-the-art open source stack for developers and data scientists to create predictive engines for any machine learning task.
PredictionIO以Spark为计算引擎,mysql or HBase+Elasticsearch or PostgreSql 为数据存储,并提供了常用的模板引擎:
1、Recommenders推荐引擎。集成了Spark MLlib的协同过滤算法,可以作为电子商务、新闻、视频方面的个性化推荐。2、Classification分类引擎。集成了Spark MLlib的朴素贝叶斯算法,提供文本内容分类、预测用户在当前会话中转化概率、(用户)流失预测等服务。3、NPL引擎。主要做情绪分析。4、还提供回归、聚类等其他引擎。
2、Apache PredictionIO 服务搭建
2.1 前提条件
这是非常重要的,满足下列软件要求,PredictionIO®的最低版本。
- Apache Hadoop 2.6.5(可选,仅在需要YARN和HDFS时才需要)
- 适用于Hadoop 2.6的Apache Spark 1.6.3
- Java SE开发工具包8
以及下列其中一组:
- PostgreSQL 9.1
要么
- MySQL 5.1
要么
- Apache HBase 0.98.5
- Elasticsearch 1.7.6
如果您在一台计算机上运行,我们建议至少2GB内存。
2.2 PredictionIO的安装
PredictionIO提供了两种方式的安装:
- 在本机搭建环境,安装PredictionIO的依赖包,进而安装使用PredictionIO,这种方法繁琐。
- 使用Docker安装PredictionIO,依赖包和配置全部打包好,这种方法易上手。
3、Apache PredictionIO 在Docker上搭建
这里先选择在Docker上搭建作为上手,快速熟悉这个软件。下图是Docker的版本
3.1 Docker的安装
配置开发环境是目前我们开发团队在进行开发工作之前的重要工作,对于需要使用我们自己封装的开发框架的java web程序员来说更是如此,一般来说需要配置jdk、mysql、tomcat、maven等一系列基础环境,如果需要使用我们现有的开发框架,还需要配置开发工程的模板、基础服务的访问地址、统一的环境参数等等。这些工作做起来比较繁琐,即使按照开发文档一步一步进行也容易出现差错,而且较为耗费时间。
Docker容器技术的出现使得这一工作得以改进,通过一段时间的研究,我们的底层框架开发人员将以上环境全部使用Docker容器技术制作成为完整的镜像,使得业务开发人员不必再关心这些琐碎工作,只需通过git下载我们的工程模板,通过执行Docker命令自动在本地完成开发环境的构建。
然而由于docker是一个较新的技术,仍有很多开发人员没有接触过,上这次专门针对windows下的开发者如何配置docker环境做一次讲解。
首先,我们需要安装Docker作为容器来运行PredictionIO,Docker的安装也是较为麻烦,你需要确定你是在什么环境下安装docker,由于本人旨在windows下实践过,所以这篇文章主要讲述在windows下的安装,如果有人在Linux和MacOS环境下实践过,请补充在此小节。
3.1.1 CentOS Docker
3.1.2 MacOS Docker
3.1.3 Ubuntu Docker
3.1.4 windows10 64 pro 下安装Docker
如果是在Linux系统下干活,则比较简单,因为Linux已经实现对Docker技术的内核级支持,CentOS的软件仓库自带了Docker最新版,可以直接通过命令安装使用。
对于Windows来说,稍有些困难,但是目前也不是问题了。首先需要看一下你的Windows环境,分两种情况,一种是Windows 10 64位专业版,一种是其他版本(比如很多人仍然推崇的Win 7)。前者可以直接支持安装Docker原生版,性能最好,体验最佳,后者只能使用Docker官方提供的一种过度技术(Docker ToolBox),这种技术不得不依赖Oracle的Virtualbox以在你的系统里创建一个虚拟机用以模拟Linux运行环境,好在封装的比较好,基本可以忽略这个虚拟机的存在,只需专心使用Docker即可。
(1)windows10 64 pro 下安装Docker 比较简单,需要确定基础环境:
- Docker Toolbox和Docker Machine用户的README FIRST:Docker for Windows需要运行Microsoft Hyper-V。Docker for Windows安装程序会根据需要为您启用Hyper-V,然后重新启动计算机。启用Hyper-V后,VirtualBox不再起作用,但仍保留任何VirtualBox VM映像。使用
docker-machine(包括default通常在Toolbox安装期间创建的VM)创建的VirtualBox VM 不再启动。这些VM不能与Docker for Windows并排使用。但是,您仍可以使用它docker-machine来管理远程VM。 - 必须在BIOS和支持CPU SLAT的情况下启用虚拟化。通常,默认情况下启用虚拟化。这与启用Hyper-V不同。有关详细信息,请参阅故障排除中必须启用虚拟化。
- 当前版本的Docker for Windows在64位Windows 10 Pro,Enterprise和Education(1607周年更新,Build 14393或更高版本)上运行。
- 使用Docker for Windows创建的容器和映像在安装它的计算机上的所有用户帐户之间共享。这是因为所有Windows帐户都使用相同的VM来构建和运行容器。
- 嵌套的虚拟化方案(例如在VMWare或Parallels实例上运行Docker for Windows)可能会起作用,但无法保证。有关更多信息,请参阅 嵌套虚拟化方案中的运行Docker for Windows
- Docker for Windows安装包括:安装提供Docker Engine,Docker CLI客户端,Docker Compose,Docker Machine和Kitematic。
(2)安装Docker for Windows桌面应用程序
- Docker for Windows是 Docker for Microsoft Windows 的 Community Edition(CE)。要下载Docker for Windows,请前往Docker Store。
- 双击Docker for Windows Installer.exe以运行安装程序。
如果您尚未下载安装程序(Docker for Windows Installer.exe),则可以从download.docker.com获取 。它通常会下载到您的Downloads folder,或者您可以从Web浏览器底部的最新下载栏运行它。
- 按照安装向导接受许可,授权安装程序,然后继续安装。
Docker.app系统会要求您在安装过程中使用系统密码进行授权。需要特权访问才能安装网络组件,指向Docker应用程序的链接以及管理Hyper-V VM。
- 在安装完成对话框中单击完成以启动Docker。
(3)启动Docker for Windows
安装后Docker不会自动启动。要启动它,请搜索Docker,在搜索结果中选择Docker for Windows,然后单击它(或按Enter键)。
当状态栏中的鲸鱼保持稳定时,Docker正在运行,并且可以从任何终端窗口访问。

如果鲸鱼隐藏在通知区域中,请单击任务栏上的向上箭头以显示它。有关详细信息,请参阅Docker设置。
如果您刚刚安装了该应用程序,您还会收到一条弹出式成功消息,其中包含建议的后续步骤以及此文档的链接。
初始化完成后,从通知区域图标中选择关于Docker以验证您是否具有最新版本。
恭喜!您已启动并运行Docker for Windows。
3.1.5 windows10 64 home 下安装Docker
(1)安装前准备
这个稍微麻烦,也需要确定两个基础环境:
- 你的CPU支持虚拟化
- 你的操作系统需要关闭(注意是关闭!)Hyper-V
然后到官方网站下载安装包,如果网站被墙,可以访问这个地址,也可以到我上传的网盘里下载,链接在此https://yunpan.cn/cMSaWneaYPE5K 访问密码 c8fa
原生的Docker配置比较简单,官方还提供了可视化的配置界面,操作步骤如下:
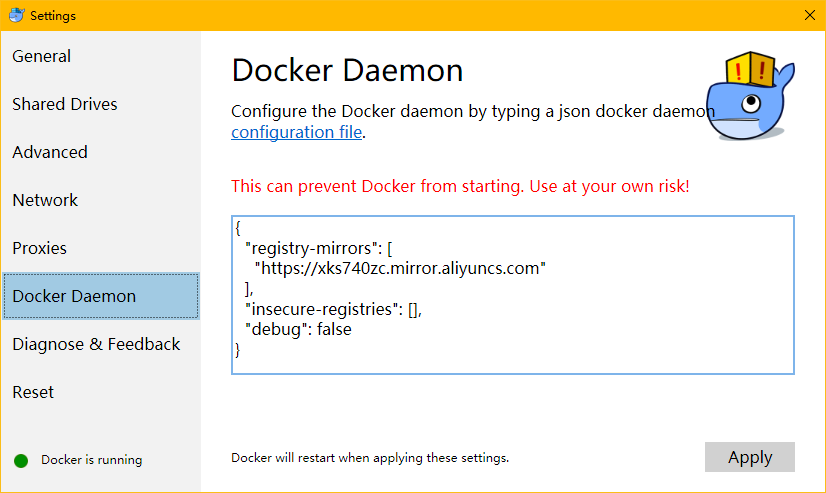
- 右键点击系统托盘的Dcoker图标,选择Settings
- 进入Docker Daemon选项,在右侧窗口填入镜像仓库的地址(可以自行去阿里云申请,我这里有一个示例)
-
示例如图
- 配置完成后,在命令行窗口执行一个拉取镜像的命令(
docker pull tomcat)试试看,会发现速度杠杠的。
(4)DockerToolbox镜像仓库的配置
这个略微麻烦一些,不过还可以接受,需要在命令行进行操作:
- 先执行这个命令(镜像地址可以自行替换)
docker-machine ssh default "echo 'EXTRA_ARGS=\"--registry-mirror=https://xks740zc.mirror.aliyuncs.com\"' | sudo tee -a /var/lib/boot2docker/profile"
- 再执行这个命令
docker-machine restart default会重启Docker虚拟机 - 然后执行命令
docker-machine ssh default即可进入docker命令行环境了
- 在容器中暴露的应用端口,需要注意,他的访问地址不是你的主机localhost,而是一个虚拟机的ip地址,一般为192.168.99.100,如果你在容器中跑起来一个web程序并且暴露了8080端口,那么想在外面访问的话,地址为http://192.168.99.100:8080 ,如果是win10下的原生docker就会没有这个迷惑,直接localhost了。
-
共享宿主机的文件给容器,需要注意,我们在使用容器时,一般会通过挂载卷的形式将系统的文件共享给容器使用,对于DockerToolbox来说,它默认给你设置了系统盘的User文件夹具有可以挂载共享文件的能力,也就是说,你需要使用挂载卷的时候,必须确保文件在这个根目录之下(比如放在C:/Users/xxx/Dcouments/xxxx)。具体的解决参照:Docker Toolbox在window 10 home 下挂载宿主机目录到容器的正确操作 - 知-青 - 博客园
如果是window10系统的原生docker技术则可通过图形设置界面完成,如图
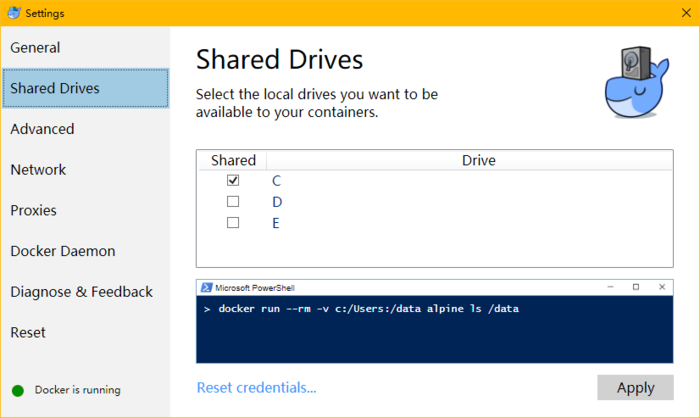
3.2 使用Docker安装Apache PredictionIO
Docker(已经安装好了,下面正式开始搭建Apache PredictionIO(0.12.0),注意版本号哦,可以及时更新。
(1)拉取及安装PredictionIO镜像,以及安装所有依赖包
# 对于PredictionIO 0.12.0 # 1、Windows10 64 pro $ docker run -it -p 8000:8000 steveny/predictionio:0.12.0 /bin/bash # 2、Windows10 64 home # 不映射文件夹 $ docker run -it -p 8000:8000 steveny/predictionio:0.12.0 /bin/bash # 映射文件夹 docker run -it -v /c/Users/T480S/work/Engine:/Engine -p 8000:8000 steveny/predictionio:0.12.0 /bin/bash
# 参考:https://www.cnblogs.com/Yuanjing-Liu/p/9447314.html
(2)Docker命令熟悉
$ docker images————展示当前镜像
$ docker ps————查找当前容器
$ docker ps -a ——展现所有容器
$ docker start 5f62————开始一个容器/镜像
$ docker rm aaad ————删除容器
$ docker attach 5f62 ————链接镜像
$ docker rmi hello-world ————删除镜像(报错,先删除容器
$ docker rmi -f hello-world ————强制删除镜像,镜像+容器一起删除
(3)首先查看当前的镜像,经过第一步之后,已经安装了一个PredictionIO镜像,可以通过如下命令查看:

(4)再查看容器,经过第一步,同时新建了一个容器

由于没有开始容器,运行$docker ps$没有任何返回;运行$docker ps -a$查看所有的容器,就可以看见刚刚新建的容器,ID为514b,还可以看见端口等其他信息
(5)开始运行容器

再Docker ps

发现容器已经开始运行
(6)进入容器里面

已经进入predictionIO容器里面
3.3 实例 —— 使用PredictionIO搭建分类引擎
此实例的官方文档:快速入门 - 分类引擎模板
这一小节包含了整个流程,PredictionIO的分类引擎模板默认集成了Apache Spark MLlib的朴素贝叶斯算法。分类引擎模板的默认用例是预测用户将根据其3个属性订阅的服务计划:attr0,attr1和attr2。这里将向您展示如何基于此模板创建自己的分类引擎以供生产使用。
(1)安装并运行PredictionIO
首先,您需要安装PredictionIO 0.12.1(如果您还没有安装)。我们经过上一小节,都已经安装了。
假设您已安装PredictionIO /home/yourname/PredictionIO/。为方便起见,将PredictionIO的二进制命令路径添加到您的PATH,即/home/yourname/PredictionIO/bin:
$ PATH=$PATH:/home/yourname/PredictionIO/bin; export PATH
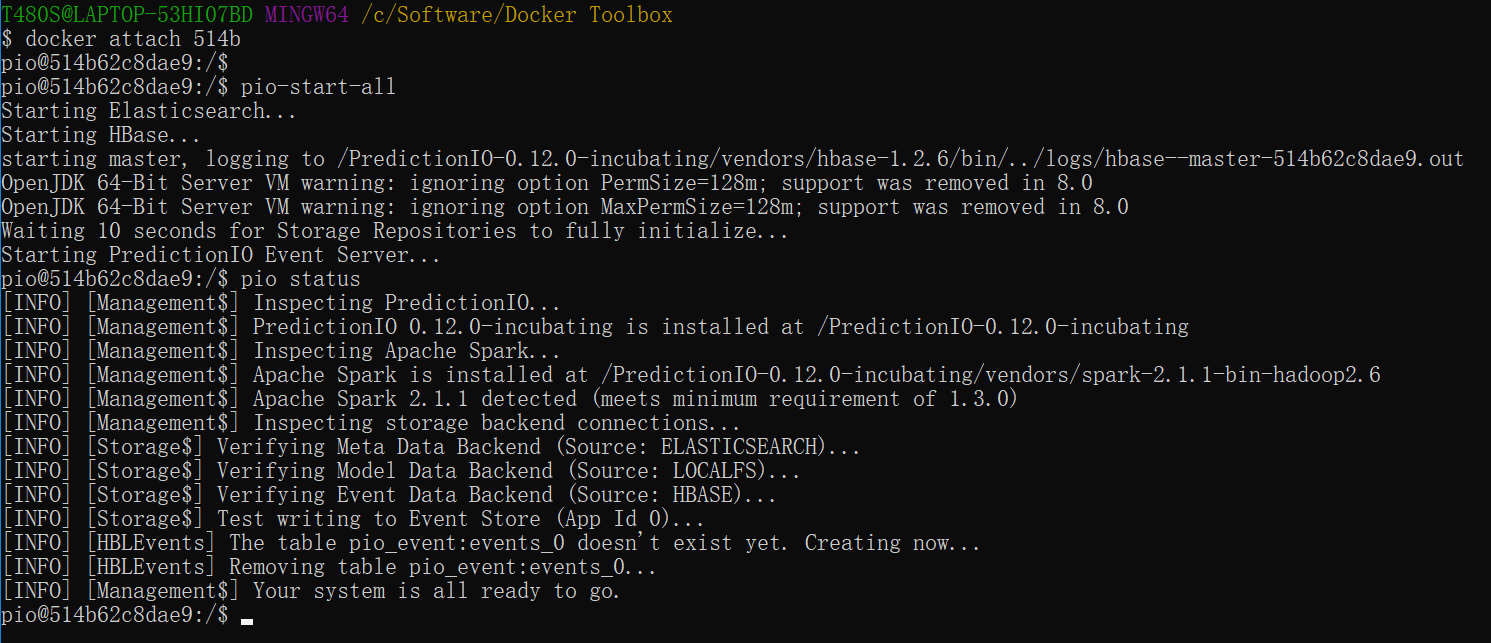
启动所有PredictionIO事件服务器,HBase和Elasticsearch:
$ pio-start-all
您可以通过运行下面命令来检查状态
$ pio status
如果一切正常,您应该看到以下输出:
(2)从引擎模板创建新引擎
现在让我们通过下载分类引擎模板来创建一个名为MyClassification的新引擎。转到要放置引擎的目录并运行以下命令:
$ git clone https://github.com/apache/predictionio-template-attribute-based-classifier.git MyClassification
$ cd MyClassification
创建一个新目录MyClassification,您可以在其中找到下载的引擎模板。
(3)生成应用程序ID和访问密钥
您需要在PredictionIO中创建一个新应用程序来存储应用程序的所有数据。收集的数据将用于机器学习建模。假设您要在名为“MyApp1”的应用程序中使用此引擎。运行以下命令以创建新应用程序“MyApp1”:
$ pio app new MyApp1
您应该在控制台输出中找到以下内容:

请注意,为此应用程序“MyApp1”创建了App ID ,** Access Key *。使用此应用程序的EventServer收集数据时,您将需要访问密钥。
您可以通过运行以下命令列出创建其相应ID和访问密钥的所有应用程序:
$ pio app list
你应该会看到你创建的应用列表,例如:

这里我的应用是MyApp_classify。
(4)收集数据
接下来,让我们收集一些培训数据。默认情况下,分类引擎模板读取用户记录的4个属性:attr0,attr1,attr2和plan。此模板需要“$ set”用户事件。官方文档提供了更具体的说明,这一段建议返回官方文档的$4. Collecting Data$查看。
我们往下走,为方便起见,将访问密钥设置为shell变量,运行:
$ ACCESS_KEY=<ACCESS_KEY>
查询事件服务器
现在让我们查询EventServer,看看是否成功导入了这些事件。
使用浏览器转到以下URL:
http://localhost:7070/events.json?accessKey=<YOUR_ACCESS_KEY>
或者在终端中运行以下命令:
$ curl -i -X GET "http://localhost:7070/events.json?accessKey=$ACCESS_KEY"
请注意,在运行curl命令时,应使用单引号或双引号引用整个URL 。
导入数据
该引擎需要更多数据才能训练有用的模型。为了快速启动演示,我们不是一个接一个地实时发送更多事件,而是使用脚本批量导入更多事件。
提供了一个Python导入脚本import_eventserver.py,用于使用Python SDK将数据导入Event Server。请先升级到最新的Python SDK。
首先,您需要安装Python SDK才能运行示例数据导入脚本。要安装Python SDK,请运行:
$ pip install predictionio
或者
$ easy_install predictionio
注意:如果您有权限问题,则可能需要访问权限。使用sudo pip install predictionio
导入数据时,先确保您在MyClassification目录下,执行以下操作:
$ cd MyClassification
$ python data/import_eventserver.py --access_key $ACCESS_KEY
您应该看到以下输出:

现在,训练数据存储在事件存储中。
如果你看到提示错误“TypeError: init() got an unexpected keyword argument 'access_key' ”请把Python SDK升级到最新版本
您可以如前所述再次查询事件服务器以检查导入的事件。
(5)部署引擎即服务
现在,您可以构建,训练和部署引擎。首先,确保您在MyClassification目录下。
$ cd MyClassification
- Engine.json
在目录下,您应该找到一个engine.json文件; 这是您为引擎指定参数的位置。
修改此文件以确保appName参数与您之前创建的App Name相匹配(例如,如果您按照本文,则为“MyApp1”)。

您可能会在engine.json中看到appId,这意味着您正在使用旧模板。在这种情况下,请确保appId文件中定义的内容与您的App ID相匹配。或者,您可以下载最新版本的模板或按照我们的升级说明修改模板以appName用作参数。
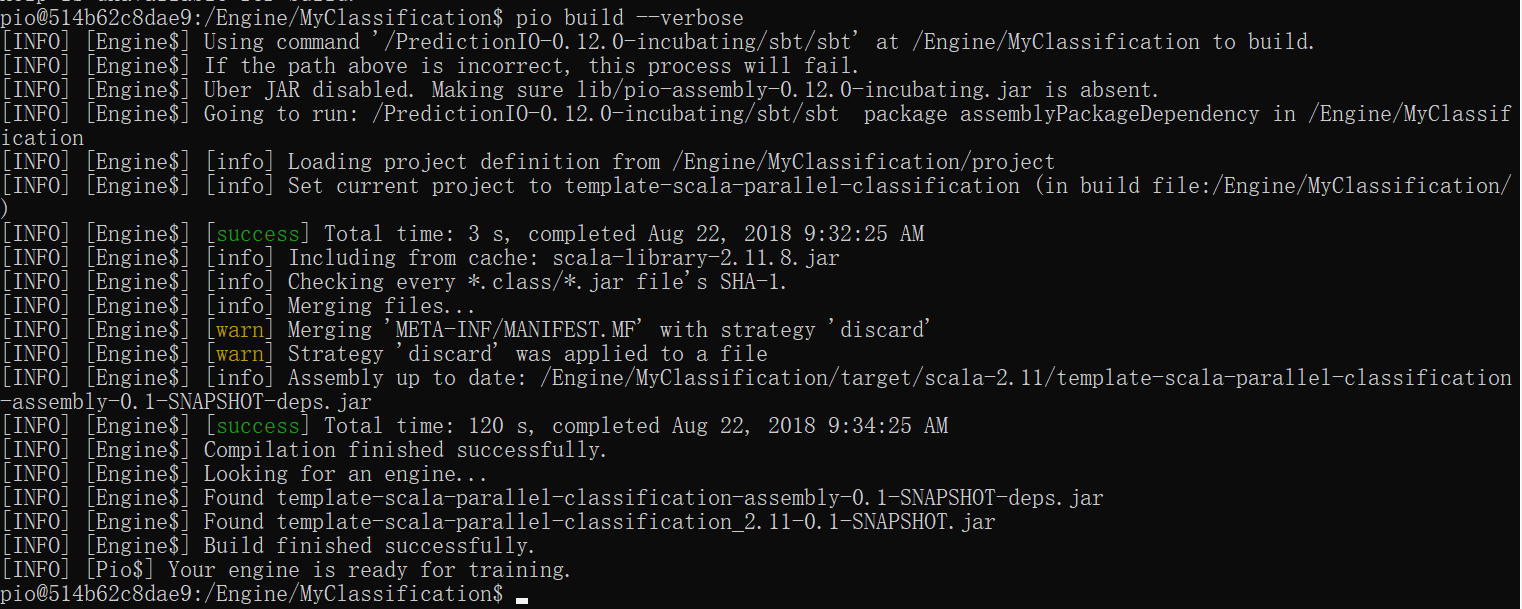
这个命令第一次需要几分钟; 所有后续构建应该不到一分钟。--verbose如果您不想查看所有日志消息,也可以在不运行的情况下运行它。
成功构建后,您应该看到以下内容的控制台消息。
- 训练预测模型
要训练引擎,请运行以下命令:
$ pio train
成功训练引擎后,您应该看到类似于以下内容的控制台消息。

- 部署引擎
现在您的引擎已准备好部署。运行:
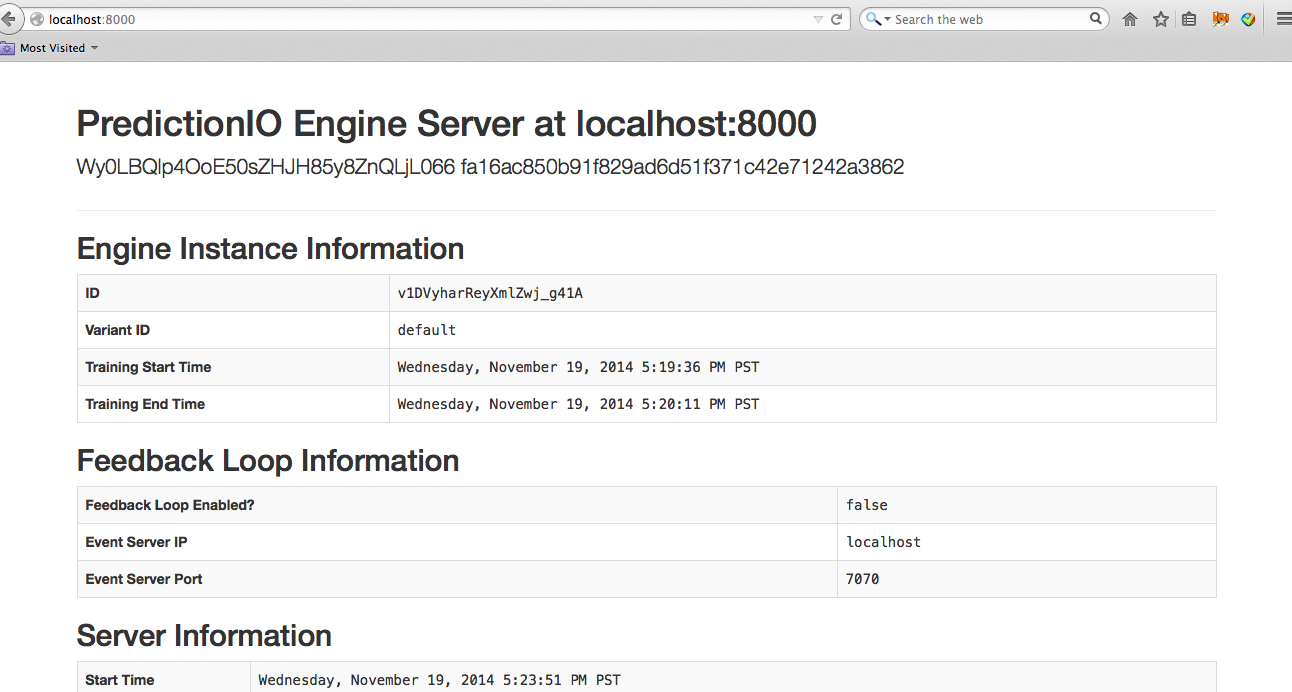
$ pio deploy
成功部署并运行引擎后,您应该看到类似于以下内容的控制台消息:

不要杀死已部署的引擎进程。
默认情况下,已部署的引擎绑定到http://localhost:8000。您可以在Web浏览器中访问该页面以检查其状态。
(6)使用引擎
现在,您可以尝试检索预测结果。例如,要预测attr0 = 2,attr1 = 0和attr2 = 0的用户的标签,您将此JSON发送{ "attr0":2, "attr1":0, "attr2":0 }到已部署的引擎,它将返回预测计划的JSON。只需通过发出HTTP请求或通过EngineClient SDK 发送查询。部署的引擎运行后,打开另一个终端并运行以下curl命令或使用SDK发送查询:
Docker 终端执行:
$ curl -H "Content-Type: application/json" \
-d '{ "attr0":2, "attr1":0, "attr2":0 }' http://localhost:8000/queries.json
或者,使用python
import predictionio
engine_client = predictionio.EngineClient(url="http://localhost:8000")
print engine_client.send_query({"attr0":2, "attr1":0, "attr2":0})
返回结果

在输入三个特征之后,返回类别label为1,服务可以正常使用。
(7)注意问题(欢迎完善)
- 导入数据
$ cd MyClassification
$ python data/import_eventserver.py --access_key $ACCESS_KEY
就是上面两行,在Docker终端运行时候,需要在docker容器安装好所需插件,比如pip和easy_install任选一个,然后是python的版本不能太高,最好的是python 2.7
第一,先检查你是不是不是windows10 pro版本,如果不是,请看3.4小节
第二,你是否开了VPN,如果开了你要注意,把系统代理模式调成PAC模式,如还有问题,也可尝试把VPN关掉,调回国内正常网络。
3.4 windows10 64 home版的独特之处
Windows10 64 home版与pro有些许不一样,这一类都可以统称为非Windows10 pro版
(1)启动容器需要提前映射文件夹
由于在home版本下,不是docker原生环境,并且不提供可视化界面,所以当我们从引擎库下载引擎时,需要在容器和宿主机共享文件夹,也称为映射。所以一开始启动容器的时候,就需要映射好文件夹,这一点官网也没有指出,命令行与官网和上文种的不一样,具体原理参考:Docker Toolbox在window 10 home 下挂载宿主机目录到容器的正确操作 - 知-青 - 博客园,下面直接给出正确启动容器命令行。
docker run -it -v /c/Users/T480S/work/Engine:/Engine -p 8000:8000 steveny/predictionio:0.12.0 /bin/bash
不可照搬,参照原理,改变自己的路径。
(2)不能链接http://localhost:8000
在容器中暴露的应用端口,需要注意,他的访问地址不是你的主机localhost,而是一个虚拟机的ip地址,一般为192.168.99.100,如果你在容器中跑起来一个web程序并且暴露了8000端口,那么想在外面访问的话,地址为http://192.168.99.100:8000 ,如果是win10下的原生docker就会没有这个迷惑,直接localhost了。
(3)发出请求
既然返回url不一样,同样的发出请求里面的url,也是官网的或pro版不一样。请参照下面的命令行,进行能动性的使用。
$ curl -H "Content-Type: application/json" -d '{ "attr0":2, "attr1":0, "attr2":0 }' http://192.168.99.100:8000/queries.json

