
BGP协议
协议概述-定义
*边界网关协议BGP(Border Gateway Protocol)是一种实现自治系统AS(Autonomous System)之间的路由可达,并选择优选路由的距离矢量路由协议。也称之为“外部网关协议 ”。早期发布的三个版本分别是BGP-1、BGP-2和BGP-3,1994年开始使用BGP-4,2006年之后单播IPv4网络使用的版本是BGP-4,其他网络(如IPv6等)使用的版本是MP-BGP。
*MP-BGP是对BGP-4进行了扩展,来达到在不同网络中应用的目的,BGP-4原有的消息机制和路由机制并没有改变。MP-BGP在IPv6单播网络上的应用称为BGP4+,在IPv4组播网络上的应用称为MBGP(Multicast BGP)。
*BGP本身不产生路由,仅仅用来传递路由
*BGP的路由属性非常丰富,所以使用BGP更多的目的是为了“实现路由的灵活控制”
*BGP协议属于OSI模型的第7层,即应用层。使用的接口号是TCP 179
基本概念:
-AS号:
*任何一个运行BGP协议的路由器,都需要指定一个AS号,AS号就是用来在BGP协议中来表示不同的公司。AS号取值:0-65535
&AS号的空间有限,随着网络的发展有可能会快速的耗尽,为了能够让AS号能够用,所以又有了“私有AS号”
&私有AS:
-这类AS不需要花钱购买,可以随意使用,但是只能在公司内部使用
-取值范围:64512-65535
&公有AS:
-这类AS需要花钱购买,需要找当地的运营商。可以在公网上运行!
-取值范围:0-64511
-route-id
-作用:在BGP网络中标识唯一的路由器
-确定方式:
1.手动指定
2.自动选举
优点
工作原理
-建立邻居表
包含的是BGP的邻居设备
-同步数据库
包含的是自己本地宣告的BGP路由,以及从其他邻居学习过来的BGP路由
-计算路由表
包含的是从数据库中按照一定的BGP选路规则,选举出来的最好的路由。
报文类型
-open报文,用于BGP邻居的建立,通过报文协商很多BGP协议的参数
-update报文:即更新报文,用于在BGP邻居之间同步数据库
-keep-alive报文:用于在BGP邻居之间周期性的发送,维护BGP的邻居关系
-notification报文:通知报文,即在BGP邻居之间传递报错信息和警告信息
-refresh报文:刷新报文。即BGP的路由策略改动之后,为了能够让策略快速生效,需要使用路由器的刷新能力,就会使用该报文。
原理详解
-邻居的类型
1.内部邻居:如果两个BGP协议的路由器,在同一个公司
2.外部邻居:如果两个BGP协议的路由,在不同的公司
-邻居的建立过程
1.首先设备之间建立稳定的TCP连接
&TCP的建立:3次握手
&TCP的断开:4次挥手
2.在TCP连接之上,互相发送open报文,比较open报文中的参数,协商成功后建立BGP邻居关系
-邻居的基本配置命令
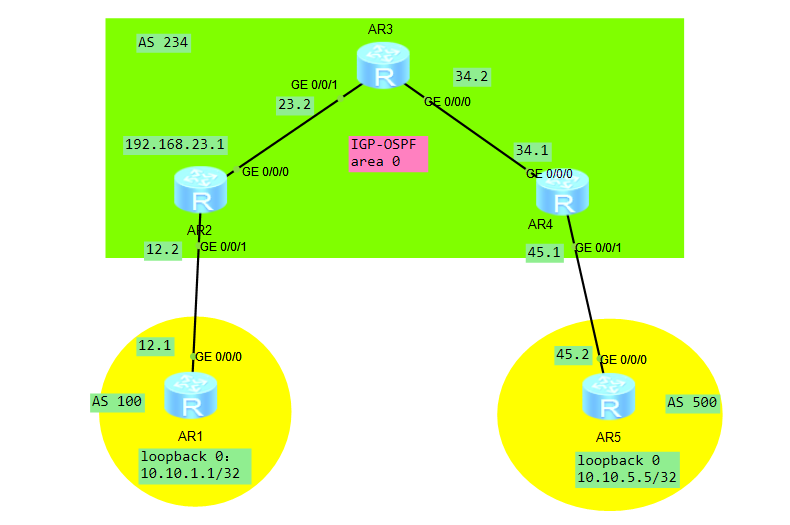
&需求:在R1和R2之间,建立BGP邻居关系(extended BGP)
配置命令:
R1:
int g0/0/0
ip add 19.168.12.1 24
quit
bgp 100
route-id 1.1.1.1
peer 192.168.12.2 as-number 234-->与 AS 号234的路由器建立邻居,邻居接口IP:192.168.12.2
R2:
int g/0/1
ip add 192.168.12.2 24
quit
bgp 234
rout-id 2.2.2.2
peer 192.168.12.1 as-number 100 --->与AS号100的路由器建立邻居,邻居接口IP:192.168.12.1
-邻居表的字段分析
display bgp peer //查看BGP的邻居表


-邻居之间的路由传递
display bgp routing-table //查看BGP的路由和下一跳信息
*根据上面的拓扑图,如果R1上的loopback 0接口能与R5的loopback 0接口进行通信,我们应该怎么做?
1. 在R1和R2之间,通过直连接口,建立EBGP邻居关系;
2.在R1上通过network的方式,宣告路由10.10.1.1/32进入到BGP的数据库
命令:
R1
int loopback 0
ip add 10.10.1.1 32
BGP 100
network 10.10.1.1 32
3.R1通过BGP,将路由发送给R2,放入到R2的BGP数据库,并且认为是最优的路劲
4.在R2/R3之间运行OSPF,确保R2和R4的接口能够互通
5.在R2和R4之间,建立BGP邻居关系(internal bgp,内部邻居关系)
6.之前R1传递给R2的路由,对于R2而言,认为是最好的路由,所以也会发送给自己的邻居R4
7.路由传递到R4上以后,在数据库中,并不是“最好的路由”
&原因:R4无法去往该BGP的下一跳IP地址,即192.168.12.1
&解决办法:
*确保R4上,有去往R1的路由条目(该方法将公司之间的路由放入到了公司内部,非常的不稳定,所以不可取)
1. 在R4上配置去往192.168.12.1(R1)的静态路由
2.在R4上通过OSPF协议学习该下一跳IP地址的路由(通过在R2上宣告192.168.12.0网段的路由)
*确保在R4设备上,该路由的下一跳IP地址变更为R2的接口IP地址
1、 在R2上,针对内部邻居,发送路由时,将外部路由的下一跳地址修改为自己的IP地址
2. 命令:R2
BGP 234
peer 192.168.34.1 next-hop-local
得出结论:
1. EBGP邻居之间传递路由下一跳默认是修改路由的下一条IP地址的
2.IBGP邻居之间传递路由的时候,默认是不修改路由的下一跳地址的
8. 经过“步骤7”的解决方案,我们可以确保R2上的BGP数据库中,该路由是最好的。
9.在R4和R5之间,建立EBGP邻居关系,希望R4将路由发送给R5.
10.R5在和R4建立好邻居之后,可以顺利学习到R4传递的路由条目【因为EBGP邻居之间传递路由的时候,下一跳地址是自动变化的】
11.R5也建立一个回环口,并且通过(import-route direct)宣告进入BGP,然后传递给R4
12.在R4上看到该路由是可用的,并且顺利发送给R2,但是在R2上因为下一跳IP地址不可达,所以R2不能使用该路由。
解决方案:
1.在R4上针对R2,发送路由时,将下一跳ip地址设置为自己的IP
命令:
R4:
BGP 234
peer 192.168.23.1 next-hop-local
13.R2学习到正常的下一跳ip地址后,就可以顺利的发送给R1
14.R1的BGP数据库中就学习到了R5的路由,并且顺利放入到了R1的路由表中
15.测试:在R1上ping -a 10.10.1.1 10.10.5.5看是否能够互通。
结果:不通
原因:因为在R3上没有运行过BGP,所以R3的路由表中没有R1和R5的路由条目。
解决方法:有3种
1. 在R3上添加静态路由
2. 让R3通过IGP(OSPF)学习路由
3.让R3通过BGP学习路由
&bgp全互联
&BGP联盟
&BGP反射器
BGP“源IP地址检测”
通过上诉的案例最终,因为R3上没有通往R1和R5的路由,固R1和R5不能通信。
那么,在R2和R4两个区域边界路由器之间之间增加一条线路。
为了更好的了解BGP的特性,我们将拓扑变更如下:
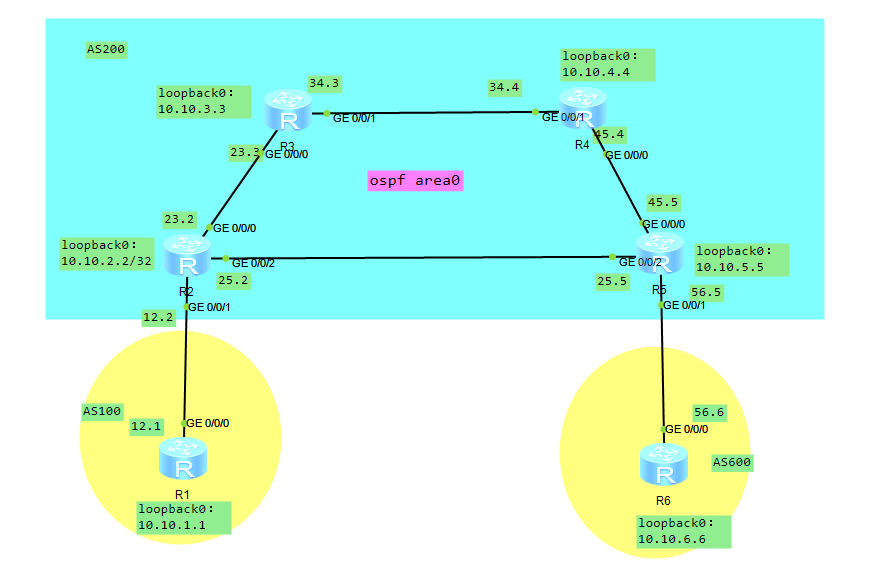
1. 取消原来R2和R4之间建立的BGP邻居,再将R2和R5通过直连线路接口建立BGP邻居关系,为了使拓扑更加稳定,我们使用路由器的loopback0接口地址作为
发送bgp open报文的源地址。然后我们尝试R2和R5之间建立BGP邻居关系。
配置R2和R5建立bgp邻居关系,命令如下:
R2:
bgp 200
route-id 2.2.2.2
peer 10.10.5.5 as-number 200
R5:
bgp 200
route-id 5.5.5.5
peer 10.10.2.2 as-number 200
2. R2和R5配置完后,我们查看R2和R5的bgp邻居关系,但是并未建立bgp邻居关系。
原因:
*R2作为源,主动向10.10.5.5的TCP 179端口,发起一个连接;
【注意】:
-任何一个设备,向特定目标IP地址发送数据包的时候,如果不明确说明“源IP地址”是多少,那么这个数据包的源IP地址就是:
该设备去往特定目标地址时,所使用的那个'出接口”IP地址。
-在该案例中,R2使用的接口时“g0/0/2”,所以源地址:192.168.25.2
此时选择端口的依据是:路由器去往10.10.5.5时,查找路由表来确定的出接口
*R2要求,邻居向自己发送BGP报文时,源IP地址必须是10.10.5.5;
*R2要求,邻居向自己发送BGP报文时,所携带的AS号必须是200;
*R2建立的TCP连接:
192.168.25.2:源端口(随机的)---------->10.10.5.5:179, tcp;
*R5要求,邻居向自己发送BGP报文是,源IP地址必须是10.10.2.2
*R5要求,邻居向自己发送BGP报文时,所携带的AS号必须是200;
*R5建立的TCP 连接:
192.168.25..5:源端口(随机的) ---------->10.10.2.2:179,tcp;
【注意】:
1.在建立TCP连接的过程中,通常会有这种说法“主动建立TCP连接”和“被动建立TCP 连接”;
2.通常情况下。凡是端口是“随机端口”的一端,称之为“主动发起方”
-经过上述分析我们知道:
1.R2发的连接,源IP地址,满足不了R5的要求,所以连接无法建立;
2.R5发的连接,源IP地址,满足不了R2的要求,所以连接无法建立;
最终:R2---R5之间的bgp邻居,就无法建立
那么:上述这个“原则”,就称之为“源IP地址检测”
所以,解决办法:更改“发送的BGP”连接的源IP地址。
修改命令:
R2:
bgp 200
peer 10.10.5.5 connect-interface loopback 0
//即R2向10.10.5.5发送的报文的时候,使用的源IP地址是loopback 0(10.10.2.2)
R5:
bgp 200
peer 10.10.2.2 connect-interface loopback 0
//即R2向10.10.5.5发送的报文的时候,使用的源IP地址是loopback 0(10.10.5.5)
-上述的案例,称之为:更新源检测机制
即:对方BGP设备发送的报文的源IP地址,必须和自己的peer命令后面的IP地址是相同的。
总结:当bgp设备有多个出接口的时候,就必须要开启“源IP地址检测”功能,即:peer x.x.x.x connect-interface loopback x
//建议建立BGP邻居关系时尽量使用loopback接口,运维使用这种口的特点就是:稳定,即:任何时候改端口的状态都是up,不会down。除非设备关机了
直连检测机制
接下来思考:
以上是IBGP之间可以通过“稳定的回环接口”建立邻居关系,那么EBGP是否也可以使用“回环接口”建立邻居关系呢?
答:不可以
案例:
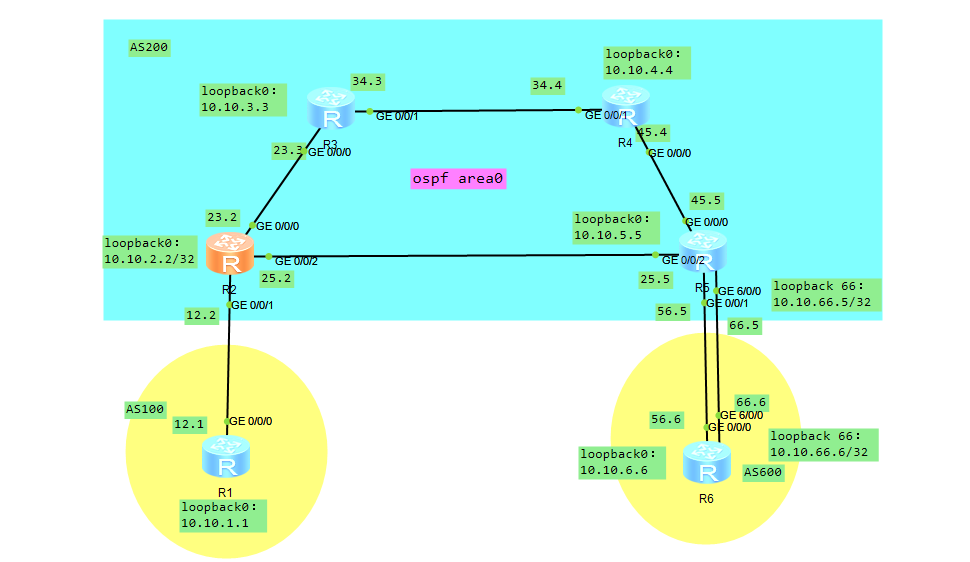
实验环境说明:
1.在R5和R6之间新增一条线路(右),接口IP:192.168.66.0/24。
R5新建loopback 66接口,IP地址:10.10.66.5/32
R6新建loopback 66接口,IP地址:10.10.66.6/32
2.建立邻居关系
命令:
R5:
bgp 200
peer 10.10.66.6 as-number 600
peer 10.10.66.6 connect-interface loopback 66
R6:
BGP 600
peer 10.10.66.5 as-number 200
peer 10.10.65.5 connect-interface loopback 66
3.因为R5的loopback 66接口去往R6的loopback 66接口有两条路径,我们需要分别在R5和R6上创建静态路由指定去往对方的路径:
命令:
R5:
ip router-static 10.10.66.6 32 192.168.56.6
ip router-static 10.10.66.6 32 192.168.66.6
R6:
ip router-static 10.10.66.5 32 192.168.56.5
ip router-static 10.10.66.5 32 192.168.66.5
-在上诉的配置中,我们已经为了满足对方设备上的“更新源检测机制”,修改了自己的源IP地址。
但是,此时R5和R6作为EBGP邻居关系,依然无法建立!
因为,在EBGP邻居之间,还存在着另外一个机制:直连检测机制。
即:
互为EBGP邻居的两个设备,在建立邻居关系的时候,去往对方的接口地址时,所使用的路由必须是“直连路由”
但是:
在该案例中,我们在R5和R6之间是通过loopback 66建立的邻居,并且两者之间的通信是依靠“静态路由”
所以:
此时R5和R6之间的邻居关系,是不满足“直连检测机制”的
解决办法:
* 我们知道:
1. 邻居关系得是“EBGP邻居”
2.两个设备之间发送的BGP报文的TTL必须是1,如果TTL不是1,那么就不检查该机制。
【注意】:
-默认情况下,IBGP邻居之间发送的BGP报文的IP头部中的TTL值是255
-默认情况下,EBGP邻居之间发送的BGP报文的IP头部中的TTL值是 1
*那么,解决“EBGP邻居”之间通过回环口建立邻居关系的方法:修改EBGP邻居之间的BGP报文的TTL值大于1
配置命令:
R5:
bgp 600
peer 10.10.66.6 ebgp-max-hop-->如果不指定任何具体的数值,那么久表示将TTL修改为255
R6:
bgp 200
peer 10.10.66.5 ebgp-max-hop 2
*此时,“非直连接口建立EBGP邻居关系”成功。
----------------------------------------------------------------------------------------------------------------------------------
邻居建立的影响因素
1. 两边的IP地址必须互通
2.两边的IP地址之间的TCP 179 端口流量必须放行
3.两边设备的router-id 不能相同
4.两边设备的AS号,必须是对方期望的
5.两边设备必须满足“更新源检测机制”
6.如果是EBGP邻居,还得满足“直连检测机制”
7.BGP邻居的认证,必须成功
IBGP水平分割机制
*在上面的拓扑中我们的目的是R1能够与R6之间互相通信。
*通过上面的案例我们知道,此拓扑中R3和R4没有去往R1和R6的路由。
*解决办法:
1. 手动添加静态路由,配置太麻烦,且不灵活,不建议用
2.配置动态路由协议-OSPF协议
配置命令:
R2/R5:
ospf 1
import-route bgp //将R2/R5通过BGP协议协议到的路由,引入到ospf协议;这些路由通过5类LSA的形式,在AS200内部进行传递,发送给R3和R4
&缺点:
BGP协议通常传递的是大量的路由条目,但是OSPF协议呢,是为企业内部而开发的;
所以OSPF协议的处理能力,非常有限
所以不建议将BGP协议的路由,引入到OSPF;
【通常,如果非得将bgp引入到ospf,我们必须在import-route后面结合使用route-policy来控制引入的路由数量】
3.通过动态路由协议-BGP学习
1.我们在AS 200内部所有的路由器上,都运行bgp,让每个路由器都能学习到路由。
2.配置:
在R2/R3/R4/R5上都建立邻居关系,让彼此传递路由【注意:IBGP传递时,下一跳不会改变,所以,要修改下一跳地址为自己的地址。peer X.X.X.X nedt-hop-local 】
3.遇见的问题
R1--->R2---->R3,但是R3学习到的路由,虽然是最优的,但是没办法发给自己的邻居R4
原因:
BGP协议在设计的时候,为了防止IBGP邻居之间的路由环路,所以设计了一个“IBGP水平分割机制”;
即,从IBGP邻居路由器学习到的路由,不会再次发送给另外一个IBGP邻居路由器
解决方案:
1. IBGP路由器之间,全互联;
-优点:简单
-缺点:每个BGP路由器。都会和剩余的其他所有路由建立BGP邻居关系;
配置量非常大,管理不灵活,并且每个BGP路由器都需要维护大量的TCP连接。
消耗大量的系统资源。
2.BGP联盟(在AS内部,将原来的内部邻居,想尽一切办法,变成外部邻居)
引用拓扑说明:
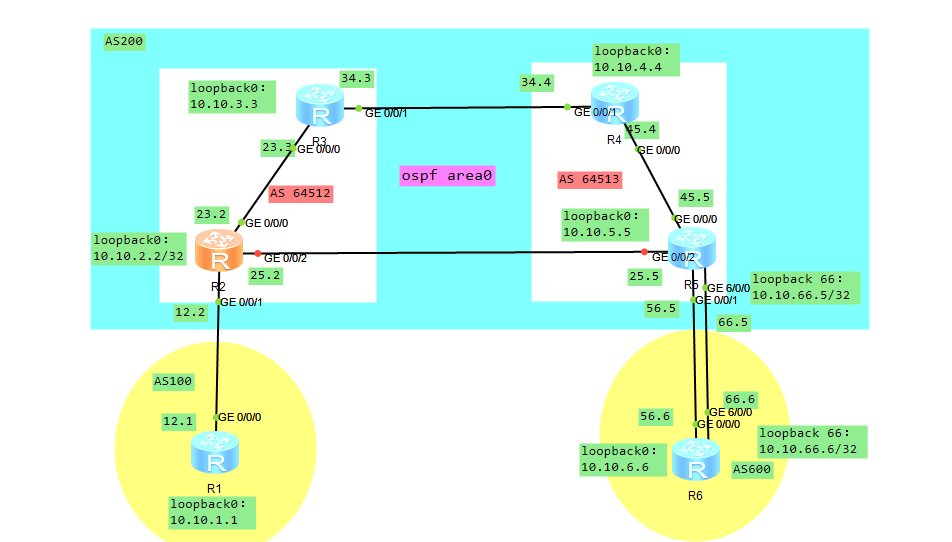
-R1-R6首先配置各接口IP地址,以及loopback接口地址【配置省略】
-R2/R3/R4/R5内部使用OSPF area0互通【配置省略】
-R2/R3组成一个AS 64512; R4/R5组成一个AS 64513【去掉之前的bgp 200】
-将AS 64512和 AS 645组成 联盟, 联盟 AS 200
命令:
R1:
bgp 100
router-id 1.1.1.1
peer 192.168.12.2 as-number 200
entwork 10.10.1.1 32
R2:
undo bgp 200
bgp 64512
route-id 2.2.2.2
confederation id 200
confederation peer-as 64513
peer 192.168.12.1 as-number 100
peer 10.10.3.3 as-number 64512
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 next-hop-local
quit
R3:
undo bgp 200
bgp 64512
router-id 3.3.3.3
confederation id 200
confederation peer-as 64513
peer 10.10.2.2 as-number 64512
peer 10.10.2.2 connect-interface loopback 0
peer 10.10.4.4 as -number 64513
peer 10.10.4.4 connect-interface loopback 0
peer 10.10.4.4 ebgp-max-hop
quit
R4:
undo bgp 200
bgp 64513
route-id 4.4.4.4
confederation id 200
confederation peer-as 64512
peer 10.10.5.5 as-number 64513
peer 10.10.5.5 connect-interface loopback 0
peer 10.10.3.3 as-number 64512
peer 10.10.3.3 connect-interface loopback 0
peer 10.10.3.3 ebgp-max-hop
quit
R5:
undo bgp 200
bgp 64513
router-id 5.5.5.5
confederation id 200
confederation peer-as 64512
peer 10.10.4.4 as-number 64513
peer 10.10.4.4 connect-interface loopback 0
peer 10.10.4.4 next-hop-local
peer 192.168.56.6 as-number 600
peer 192.168.56.6 connect-interface loopback 56
peer 192.168.56.6 ebgp-max-hop
quit
R6:
bgp 600
router-id 6.6.6.6
peer 192.168.56.5 as-number 200
peer 192.168.56.5 ebgp-max-hop
network 10.10.6.6 32 或 import-route direct
测试:
R1---->ping -a 10.10.1.1 10.10.6.6
*R5:
display bgp routing-table peer 10.10.4.4 advertised-routes
//查看10.10.5.5是否将从R6那里获得的外部路由发送给10.10.4.4
问题:
但是,经过上面的“BGP”联盟配置,在AS 200内部,依然容易出现问题。
比如:
当每个小AS内部的路由器的数量超过2的时候,即此案例中AS 64512 或者AS 64513的IBGP中的邻居关系数量超过1个。
在每个小AS内部依然存在“IBGP水平分割”的问题,导致 IBGP 邻居设备之间无法正常传递路由。
所以,此时我们就需要考虑另外一个技术,即:BGP反射器!
3.BGP反射器(route reflector:路由 反射器)
本质:
将一个设备配置成路由反射器以后,这个设备就会临时的针对“反射器客户端”关闭“IBGP水平分割”原则
在“IBGP反射器”的解决方案中,设备分为三种类型:
-路由器反射器
-反射器客户端
-非客户端
BGP路由反射器转发路由的原则:
除了非客户端与非客户端之间的路由不能传递
其他角色的设备之间的路由,都可以传递
比如:
客户端给反射器,反射器可以给客户端, 可以给非客户端。
非客户端给反射器,反射器可以给客户端。
那么,现在我们改变上面的拓扑,将R4移动到AS 64512中,确保AS 64512中存在2个IBGP邻居,
从而让R2的路由不会通过R3传递给R4
R4的路由不会通过R3传递给R2,就是所谓的“IBGP水平分割”
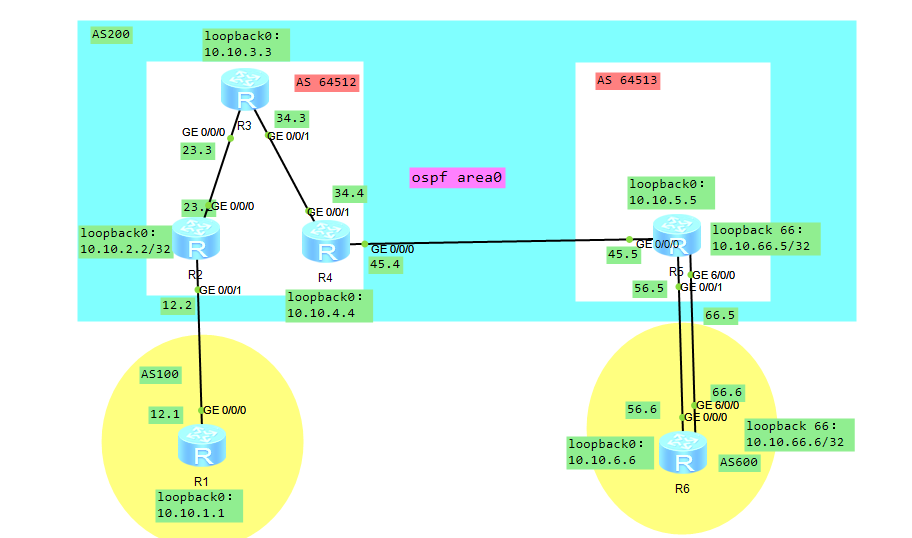
解决办法:
将R3配置为反射器,将R4配置为反射器的客户端。
配置命令:
-取消R4原来的配置,然后加入AS 64512中【配置省略】
R3:
bgp 64512
peer 10.10.4.4 reflect-client
【注意】:做完反射器之后如果出现R3只将R1的外部路由传给了R4,而并未将R6的外部路由传给R2,说明R5在引入R6的外部路由之后,
传给R4时,未将下一跳路径修改为自己的出口IP地址(peer 10.10.4.4 next-hop-local),路径不是最优的,所以R4是不会将路
由传给R3的。
***【扩展】在最开始未创建联盟时的拓扑中,仅仅使用“路由反射器技术”,不配置联盟技术,也是可以的,
1. R3配置为反射器,R4配置为客户端
bgp 200
peer 10.10.4.4 reflect-client
2.R4配置为反射器,R5是客户端/R3是客户端也可以。
R4:
bgp 200
peer 10.10.5.5 reflect-flient
路由管理
-BGP的路由属性:
display bgp routing-table //查看BGP数据库
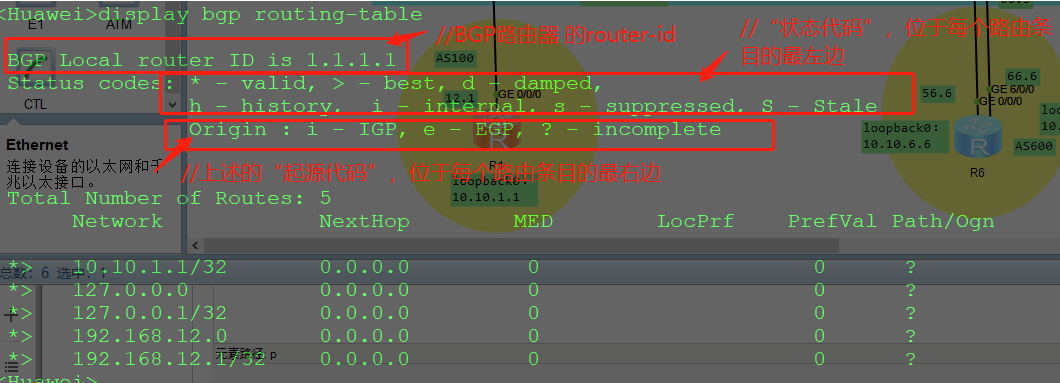
下面路由条目中:
* , 表示路由条目是有效的
> , 表示该路由是最优的
i , 表示该路由条目的类型,是内部的意思
network , 表示路由的前缀和掩码
next-hop , 表示路由条的下一跳是IP地址;
MED , BGP的路由属性,表示的是本地路由器去往该路由的距离
Locprf , BGP的路由属性(local preference) - 本地优先级;数值越大越好;默认是100;
PrefVal , BGP的路由属性(preffered value) - 优选值:数值越大越好;默认是0;但是,是华为的私有属性;
【该属性,只在一个路由器本地起作用,不会随着路由条目传递】
path , BGP的路由属性(as-path)- as路径,该属性包含的as号越少越好;
Ogn , BGP的路由属性(Origin code) - 起源代码 ,表示该路由当年是以怎样的方式进入到BGP协议的(i>e>?)
当一个路由器去往同一个路由条目具有多个路径的时候,此时BGP协议就会依靠自己的“选择原则”
在多个“路径”中,选择出一个“最好的路径”,这个选路原则是:
1. 比较preffered value,数值越大越好;默认值为0;【该属性为华为私有属性,类似思科设备上的weight(权重)】
该属性只能在设备本地起作用(即:该属性不会随着路由进行传递出去)
所以,当我们修改这个属性的时候,只能在设备上使用“入向策略”
2. 比较local preference, 数值越大越好;默认是100;
3.比较该路由是否本地生产的;本地产生的,要比从其他路由器学习过来的,优先级要高
4.比较as-path 属性的长度,越短越好
5. 比较起源属性,i>e>?
6.比较MED,数值越小越好;
7. 比较BGP邻居关系的类型,EBGP路由的优先级高于IBGP路由;
8.比较去往BGP路由的下一跳IP地址时的cost,数值越小越好;
9.比较cluster-list的长度,越小越好;
10.比较router-id,越小越好;
11.比较 peer 后面的IP地址,越小越好;
~~~~~~~~~~~~~~~~~~~~~~~~~~~~路由选路~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
上面的拓扑需求1(preffered-value属性修改):
在R1上,希望去往40走R3;去44走 R2;
配置:
-抓取路由
R1:
acl 2040
rule 10 permit source 10.10.40.40 0.0.0.0
quit
-配置策略
R1:
route-policy R1-R3-IN permit node 10
if-match acl 2040
apply preffered-value 300
quit
route-policy R1-R3-IN permit node 20 //就是 route-policy 中的“允许所有”;
-调用策略
R1:
bgp 100
peer 10.10.3.3 route-policy R1-R3-IN import //当R1从R3收路由的时候,执行该策略
-验证结果


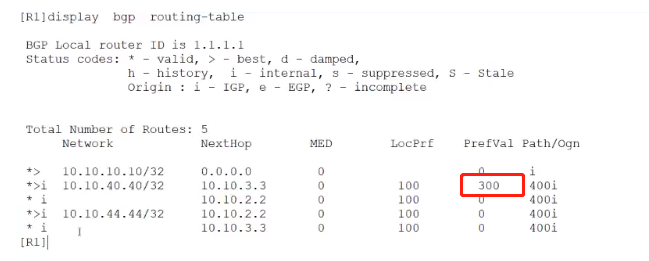
注意:
1.在任何一个常见的路由管理工具中,最后都有一个隐含的拒绝所有的命令
2. 很多场景下,我们需要在工具的最后添加一个“允许所有”
acl **
rule # permit source any---->#表示步长,编号。
ip-prefix:
ip ip-prefix {名字} index # permit 0.0.0.0 0 less-equal 32
route-policy:
route-policy {名字} permit node # --->里面不写任何的if-match,就是“match”所有的意思;
需求2(local-preference属性修改):
希望AS100 的所有内部路由器,
去往10.10.44.44都通过R2转发;
去往10.10.40.40都通过R3转发;
分析:
*如果我们调整BGP路由的preferred-value 属性,那么久必须在AS100的每个路由器配置策略,修改preferred-value属性,非常的麻烦;
所以,我们建议:在 AS100的边界路由上,调整路由的local-preference属性,从而影响AS100 内部的所有路由器。
*同时我们知道:
在IBGP邻居之间,该属性是可以随意传递的
所以,我们只要想尽办法:让R2/R3上面的两个路由的local preference 的属性被修改了,就可以了。
并且,这两个路由针对R2/R3而言,都是从R4接收过来的
所以,我们分析的结果是:
1.要么在R2/R3上,对R4做一个入向策略,修改特定路由的local-preference:方案 YES
2.要么在R4上,对R2/R3做一个出向策略,修改特定路由的local-preference;方案 NO
&该方案无法实施成功,因为:local-preference属性只能在IBGP邻居之间传递
&在EBGP邻居之间传递的时候,该属性就会丢失,但是,该属性在每个BGP路由条目都得有
&所以,针对那些没有或者丢失了local-preference属性的路由,通常都会使用一个路由器本地默认的local-preference取值,
而该数值默认情况下是100.
&但是该属性的默认取值,是可以修改的:bgp 100-->default local-preference ***
&一个路由器本地的默认的local-preference 取值,通常是对“学习过来的EBGP路由”以及本地宣告的路由
&当然,如果我们在宣告的时候,直接跟上route-policy ,也是可以修改该属性的
【总结】:
该属性可以在“宣告路由的时候”,“内部邻居之间”,“外部邻居之间的入向”,都可以通过策略修改
命令:
-抓取路由:
R3:
acl 2001
rule 10 permit source 10.10.40.40 0
quit
acl 2002
rule 10 permit 10.10.44.44 0
quit
R2:
acl 2001
rule 10 permit source 10.10.40.40 0
quit
acl 2002
rule 10 permit 10.10.44.44 0
quit
-配置策略:
R3:
route-policy R3-R4-IN permit node 10
if-math acl 2001
apply local-preffered 300
quit
route-policy R3-R4-IN permit node 20
if-match acl 2002
apply local-preffered 200
quit
route-policy R3-R4-IN permit node 30-->默认允许所有
R2:
route-policy R2-R4-IN permit node 10
if-math acl 2001
apply local-preffered 200
quit
route-policy R3-R4-IN permit node 20
if-match acl 2002
apply local-preffered 300
quit
route-policy R2-R4-IN permit node 30-->默认允许所有路由条目
-应用策略:
R3:
bgp 100
peer 192.168.34.4 route-policy R3-R4-IN import
R2:
bgp 100
peer 192.168.24.4 route-policy R2-R4-IN import
-验证:
通过上述的配置:
在R2:《会将这些路由发送给自己的内部邻居,比如R1》
10.10.40.40/32 ------ 200
10.10.44.44/32 ------ 300
在R3:《会将这些路由发送给自己的内部邻居,比如R1》
10.10.40.40/32 ------ 300
10.10.44.44/32 ------ 200
所以,最终在AS100内部的所有BGP路由器上,比如R1,数据库应该是:
10.10.40.40/32 via 10.10.2.2 , 200
via 10.10.3.3 , 300---->OK
10.10.44.44/32 via 10.10.2.2 , 300--->OK
via 10.10.3.3 , 200
该属性的应用场景:
当一个公司/运营商 有多个出口设备的时候,
为了能够让内网的路由器,选择一个去往外网地址的合适的出口设备。
我们就可以在:
边界设备上,对外网来的路由,修改local-preference 属性
从而,影响内网设备的选路。
案例3:
希望R4去往R1的时候,选择的路径是R3;
并且修改的属性是 BGP 的 as-path属性;
分析 :
1. AS-PATH 属性中,包含的是BGP 路由在传递过程中,前后一次经过的每一个AS的AS号的有序组合。
所以,如果一个AS-PATH 中包含的as号很多,说明这个BGP 路由在传递过程中经过了很多个AS;
2.AS-PATH 的作用,是用于在 EBGP邻居之间放置路由环路的发送
即,当收到一个EBGP邻居的路由时,会检查该路由的AS-PATH中是否包含了自己的AS号;
如果包含了自己的AS号,则说明这个路径曾经穿越过自己的AS,此时拒绝接受该路由;
如果不包含自己的AS号,则允许接收该EBTP邻居的路由条目。
3.该属性的变化默认仅仅是发生在EBGP邻居之间;也就是在EBGP邻居之间“发送”路由的时候;
此时的as-path 属性才会变化,将离开的这个as 号码添加到as-path 中,并且是位于as-path的最左边。
*所以,为了满足上述的需求,我们可以在R2上向R4发送路由的时候,通过策略来增加as-path 的长度。
配置:【在R2上,配置出向策略,增加as-path】
acl 2001
rule 10 permit source 10.10.10.10 0
quit
route-policy R2-R4-OUT permit node 10
if-match acl 2001
apply as-path 11 additive --->将AS号 11,添加到路由的原有的as-path属性中;
quit
route-policy R2-R4-OUT permit node 20--->允许所有路由通过
bgp 100
peer 192.168.24.4 route-policy R2-R4-OUT export
-验证结果:
***<R2> refresh bgp all import //立即刷新从邻居发送进来的路由,不用去等待刷新时间,R4---->R2
***<R4>refresh bgp all export //立即给邻居路由器发送bgp路由表
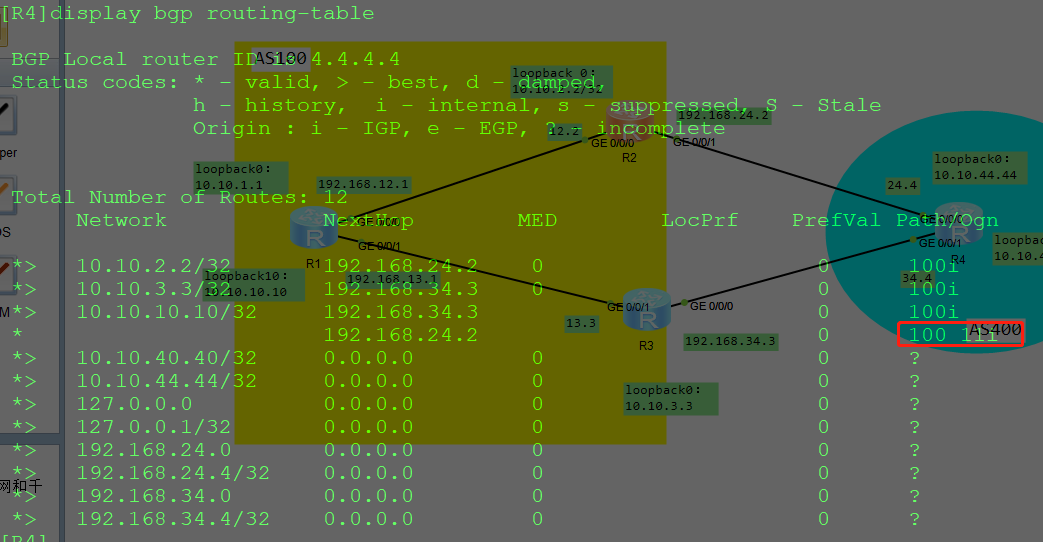
但是,如果我们将同样的策略,配置在R4上,然后对R2进行“入向策略”
最终,在R4上看到的路由的AS-PATH长什么样子呢?
配置:【先删除R2上的配置】
R4:
ACL 2001
rule 10 permit source 10.10.10.10 0
quit
route-policy R4-R2-IN permit node 10
if-match acl 2001
quit
route-policy R4-R2-IN permit node 20
bgp 400
peer 192.168.24.2 route-policy R4-R2-IN import --->R4对R2入向的路由使用此策略
-验证结果:
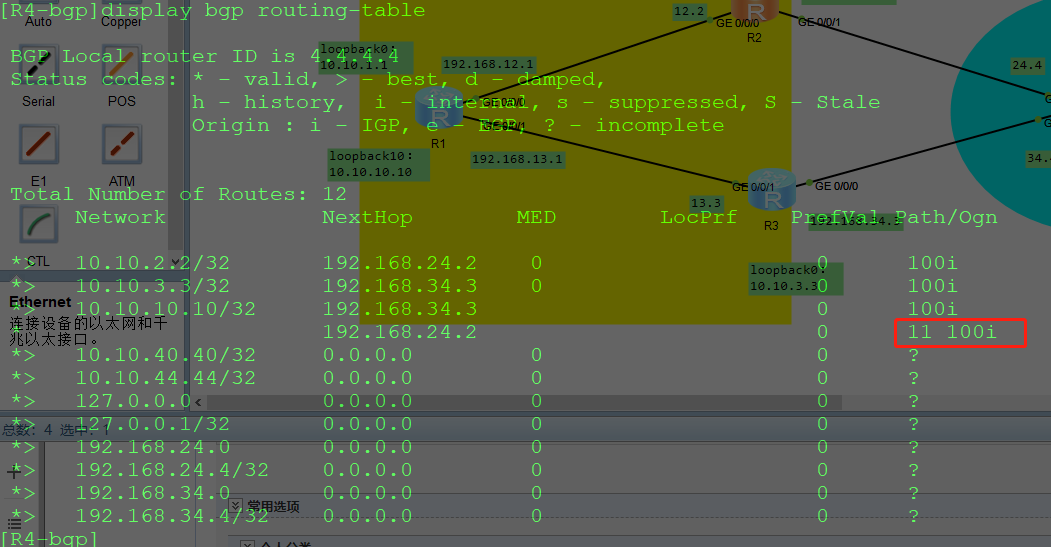
总结:
1.EBGP邻居之间发送路由的时候,一旦离开路由器,就会将自己的AS号添加到as-path 属性中。
2.EBGP邻居之间接收路由的时候,一旦进入路由器,就会检查“as-path”防环机制。
-as-path 中包含了自己的as,则拒接接收该路由;
-as-path 中没有包含自己的as,则接收该路由,进入到“入向缓冲区”
3.EBGP邻居之间,增加AS号,如果是配置出现策略:先执行策略,再执行“系统默认行为”
4.EBGP邻居之间,增加AS号,如果配置入向策略:先执行“系统默认行为”,则执行“策略”
5.无论是入向,还是出向的策略,每次添加AS号的时候,都只能添加“自己的AS号”
6.在IBGP邻居之间传递路由的时候,as-path属性是不会变化的。
案例4:
希望 R4 去往 R1 的时候,选择的路径是 R3;
并且修改的属性是BGP的 origin code 属性。
分析:
在R4上配置,针对R2发送过来的10.10.10.10/32,修改它的属性为 incomplete,
并且其他的路由的属性是不能修改的;
配置:
acl 2010
rule 10 permit source 10.10.10.10 0.0.0.0
quit
route-policy R4-R2-IN permit node 10
if-match acl 2010
apply origin incomplete
quit
route-policy R4-R2-IN permit node 20
quit
bgp 400
peer 192.168.24.2 route-policy R4-R2-IN import
因为,BGP的“起源代码”属性,可以随着路由传递到网络的任何地方。
所以,我们也可以在R2上,对R4配置为一个出向策略
命令:
R2:
ACL 2010
rule 10 permit source 10.10.10.10 0.0.0.0
quit
route-policy R2-R4-OUT permit node 10
if-match acl 2010
apply origin incomplete
quit
route-policy R2-R4-OUT permit node 20
quit
bgp 100
peer 192.168.24.4 route-policy R2-R4-OUT export
案例5:
R4希望通过R3去访问R1;
并且,是通过调整MED 属性来实现
分析:
R4去往R1的时候,可以通过R2和R3;
并且,对于R4而言,R2和R3属于同一个AS
那么此时,R4再去选择路径的时候,就可以比较MED属性
该属性表示的是“去往一个路由的距离”,数值越小越好
但是,我们作为AS 100的网络工程师,是没有资格去修改R4的相关配置的;
所以,我们希望能够通过修改R2和R3的配置,从而影响R4的选路
所以,我们在R2/R3上针对R4配置了一个“出向策略”,修改MED,从而影响/决定R4的选路。
配置:
R2:
acl 2011
rule 10 permit source 10.10.11.11 0.0.0.0
quit
route-policy R2-R4-OUT permit node 10
if-match acl 2011
apply cost 2000
quit
route-policy R2-R4-OUT permit node 20
quit
bgp 100
peer 192.168.24.4 route-policy R2-R4-OUT export
R3:
acl 2011
rule 10 permit source 10.10.11.11 0.0.0.0
quit
route-policy R3-R4-OUT permit node 10
if-match acl 2011
apply cost 300
quit
route-policy R3-R4-OUT permit node 20
bgp 100
peer 192.168.34.4 rout-policy R3-R4-OUT export
最终,我们在R4上看到的结果是:
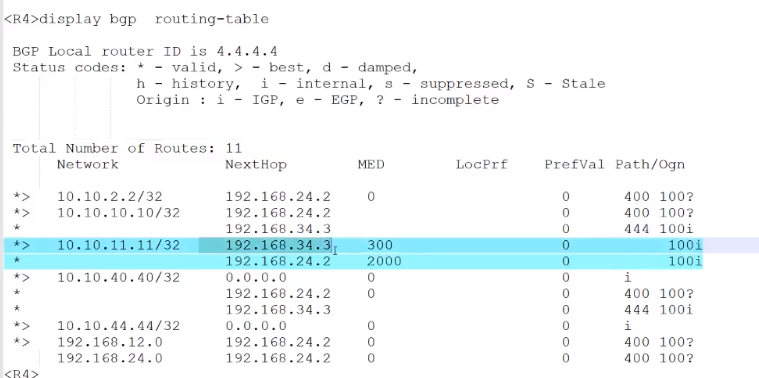
但是,MED属性的比较,是存在一个前提的:
R4认为两个路由条目是来自于同一个“邻居AS”。
即,这两个路由的as-path 属性的最左边这个as号,必须相同
如果as-path的最左边这个as号码不相同的话,就不比较该属性,直接比较下一个“路由属性”
同时,BGP路由的MED属性,只在两个直接相邻的AS之间有作用;
即,BGP路由从AS100传递到AS200,此时他们的MED属性是可以携带的;
但是,该路由条目再次从AS200发送到AS300的时候,
对于AS 300的路由器而言,该路由的MED就丢失了,此时就会分配给该路由一个默认的MED,即 0
cluster:簇
在解决EBGP水平分割时,我们曾经使用了一个解决方案----路由器反射器
该技术中,设备的角色分为路由反射器以及反射器客户端。他们两者组合在一起,就叫做“簇”
* 当BGP路由在传递过程中,经过很多个反射器反射的时候,为了防止这些路由在传递过程中,出现环路。
我们再次引入了一个属性----cluster-list,即“簇列表”。
该表中,包含的是,路由在传递过程中所经过的每一个簇的“簇ID”,默认情况下就等于路由反射器的router-id,
即:
一旦一个反射器接收到一个路由器的时候,就会检查这个路由的簇列表,看看其中是否包含了自己的簇ID,
如果包含了,则说明该路由器在之前的传递过程中,已经经过自己这个簇了,所以为了防止环路,此时就不接收该路由。
*BGP路由在传递过程中,经过的反射器的个数越多,那么cluster-list就越长;反射的次数越少,长度就越短。
---------------------------------------------BGP路由表----------------------------------------------------
-路由类型:
*内部路由,内部邻居之间传递的路由;
*外部路由。外部邻居之间传递的路由;
-路由属性:
*优先级,默认是内部255,外部255,本地产生的也是255:数值越小越好;
*开销值,表示是该设备去往该路由的距离,数值等于MED属性的取值;
-路由过滤
1.进行路由匹配
*acl
*prefix
*as-path-list
2.指定路由过滤策略
*filter-policy {acl}
*ip-prefix {prefix-list}
*as-path-filter {as-path-list}
*route-policy {上述的三个工具都可以调用}
3.调用路由过滤策略
4.验证结果
举例:
在R7干掉那些曾经属于as 400 的路由
分析:
凡是属于as 400的路由,他们的as-path 属性中,最右边的AS号,肯定都是400
方案:
ip as-path-list deny400 dengy _400$ --->表示的是空格:$表示的是结束;^表示的是as-path的开始
ip as-path-list deny400 permit .* --->表示允许所有。【.表示任意字符,*表示前面的字符的任意倍数】
bgp 700
peer 192.168.17.1 as-path-filter deny400 import
或者其他需求【正则表达式】:
1.R7想干掉所有从AS 100发送过来的路由;
deny ^100
2.R7想干掉所有从AS 100发送过来,并且原先属于AS 100的路由:
deny ^100$
3.R7想干掉所有从AS 100发送过来,并且在传输过程中,经过as 9的那些路由;
deny ^100_.*_9_
4..R7想干掉所有从AS 100发送过来,并且在传输过程中,经过as 9,并且曾经属于AS 400的路由:
deny ^100_.*_9_.*_400$
-BGP匹配路由,还可以使用“团体属性”
抓取/匹配路由的时候,我们除了可以抓取路由的网段或者掩码,还可以为路由分配在一个标记。
那么,以后抓取的时候,直接抓取这些标记就可以了
在动态路由协议中,每种协议都支持为路由条目添加标记。
RIPv1-不支持标记
RIPv2-支持标记
OSPFv2-支持标记(仅有外部路由,支持标记,例如5类LSA和7类LSA)
OSPFV3-支持标记(仅有外部路由,支持标记,例如5类LSA和7类LSA)
ISIS-支持标记(协议的cost-tyle 必须配置为wide;但是协议默认情况下使用的narrow)
但是,在BGP协议中,传递路由的时候,是没有标记(tag)的;
但是,有一个属性,它的功能完全和Tag相同,叫:团体属性-community
-BGP团体属性:
类型:
1.私有团体属性,这种类型的团体属性数值,是认为的随意的指定的
2.公有团体属性,这种类型的团体属性,是早就规定好的。任何一个BGP路由器收到这种公有团体属性以后,
都知道该如何处理。
&常见的“公有团体属性”有:
internet ,说明该BGP路由可以随意传递;
no-export ,说明该BGP路由不能传递给EBGP邻居路由器
no-advertise , 说明该BGP路由不能传递给任何BGP邻居路由器
no-export-subconfed , 说明该BGP路由不能传递给联盟内的小AS之间的外部邻居
默认情况下,每个BGP路由,都包含了一个隐含的“internet”团体属性。
关于“团体属性”:
1.该属性可以在“宣告路由”,“发送路由”,“接收路由”的时候,进行添加,修改;
2.一个BGP路由,可以同时拥有多个“团体属性”;并且他们之间是“或”的关系;
-如果同时包含了多个“公有团体属性”;那么此时的路由传递范围是按照“最小范围”来进行传输;
3.匹配团体属性的时候,使用的工具叫做:团体属性列表,即 ip community-filter
分配两种类型的团体属性列表:
&基本的团体属性列表,在匹配的时候,是逐个匹配;表示的方法是:ID的取值范围是1-99;
&高级的团体属性列表,在匹配的时候,是通过“正则表达式”来表示“团体属性”的;表示方法是:ID取值范围是100-199
4.在创建团体属性列表时:
&如果同一个列表中的多个团体属性是一次性写完,那么他们之间的关系是“与”的关系,
即,所陪陪的路由,必须同时包含列表中写的多个“团体属性”
&如果同一个列表中的多个团体属性,是分别通过多次写的,那么他们之间的关系是“或”的关系;
即,所匹配的路由,只要满足其中任何一个条件都可以;
例如:
ip community-filter 5 permit 500:5
ip community-filter 5 permit 500:50
5.在团体属性列表这个工具中,和其他匹配路由的工具是类似的:最后都包含一个隐含的拒绝所有。
表示“允许所有”的方法如下:
-ip community {ID} permit internet --->允许所有
-ip community {ID} permit --->允许所有
6.最最重要的是:
团体属性的传递,是有方向的
即,默认情况下,一个路由的团体属性,不会随着路由在BGP邻居之间传递
我们必须得在邻居之间使用命令:peer x.x.x.x advertise-community
【互为邻居的两个设备,都得互相配置:advertise-community】
案例:


团体属性的应用:
案例1:
1.给路由添加团体属性
2.创建团体属性列表,并写上抓取团体属性的条件,
3.创建策略,if-match绑定团体属性列表,执行动作(允许/拒绝)
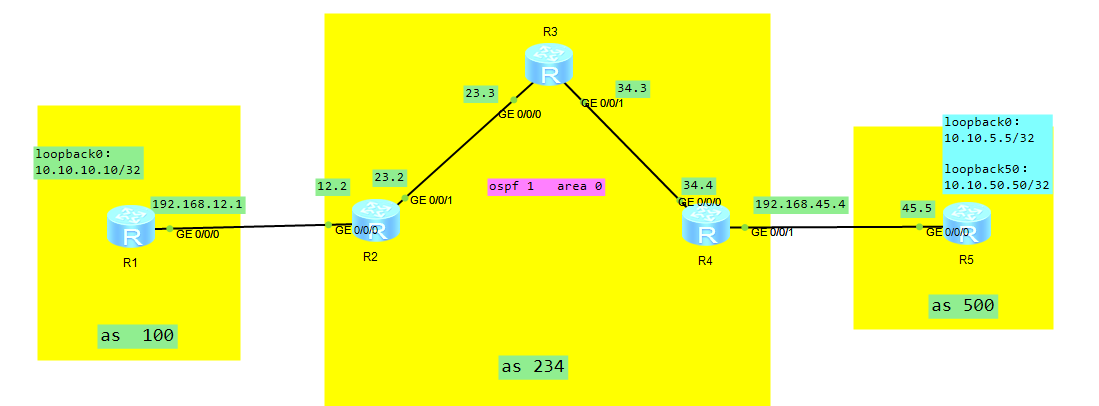
*在R5上添加两个loopback接口
1.loopback 0:10.10.5.5/32
2.loopback 50::1.10.50.50/32
3.宣告路由
命令:
btp 500
network 10.10.5.5 32
network 10.10.50.50
给路由添加团体属性
*R5 loopback接口宣告后是没有团体属性的,那么如何给他们添加团体属性
*命令:R5
route-policy L50 permit node 10
apply community 500:50
bgp 500
network 10.10.50.50 route-policy L50
*现在查看R5上的10.10.50.50就有团体属性了
*但是在传递给R4后,R4在传递给R2的时候也需要在R4上通告团体属性
*命令:R4
BGP 234
peer 10.10.2.2 advertise-community
*然后快速更新,在R2上查看10.10.50.50的团体属性,就有了。
利用团体属性抓取路由
*要求1:
抓取10.10.50.50的路由,也就是团体属性为:500:50,不让R2将这个路由传给R1。
*方法:
1.在R2上抓取团体属性列表:
[R2]ip commnuity-filter 50 permit 500:50 -->抓取团体属性为500:50的列表。这里的50是基本的团体属性列表;
【1-99为基本团体属性列表,100-199为高级团体属性列表】
2.创建一个策略,调用团体属性列表,动作为拒绝。
R2:
route-policy R2-R1-OUT deny node 10
if-match community-filter 50
route-policy R2-R1-OUT permit node 20-->允许其他的路由。
3.应用策略:
R2:
BGP 234
peer 192.168.12.1 route-policy R2-R1-OUT export
4.验证:
在R1上快速刷新,然后查看是否还有10.10.50.50的路由。
要求2:
1.抓取R4传给R2的BGP路由,然后再给10.10.50.50加一个团体属性。
*命令:R2
ip ip-prefix 50 permit 10.10.50.50 32
route-policy R4-R2-IN permit node 10
if-match ip-prefix 50
apply community 234:2 additive
quit
route-policy R4-R2-IN permit node 20
bgp 234
peer 10.10.4.4 route-filter R4-R2-IN import
2.在R4上:refresh bgp all import 出向刷新路由。
3.验证:
在R2上查看团体属性:display bgp routing-table 10.10.50.50.是否有234:2的团体属性,应该如下。
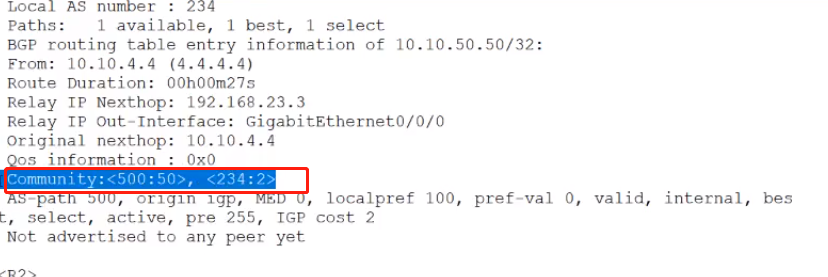
*那么思考:
10.10.50.50现在有两个团体属性, 即,500:50 ; 234:2
那么,这两个团体属性的关系是什么?
*我们现在只抓取一个团体属性,看一下是否能够有效?
1.上面已经在R2上已经做了拒绝团体属性500:50的路由10.10.50.50,我们去R1上看R2是否将10.10.50.50的路由给R1了。
2.结果,R1上是看不到10.10.50.50的路由的。
所以,他们之间是“或”的关系
*那么我们改变策略:
1.我们再给这个团体属性列表 添加一个团体属性的条件,如下:
ip community-filter 50 permit 500:555

2. 如果两个条件同时写在一行
ip community-filter 50 permit 500:50 500:555

*那么以上这两个写法有什么区别?
1.如果团体属性列表的两个属性分开两次写,那么他们之间是“或”的关系,
即,匹配一个就可以
2. 如果团体属性列表的两个属性写在一行,那么他们之间是“与”的关系,
即,需要同时匹配这两个团体属性才可以。
*那么我们如何匹配到所有的团体属性路由
方法1:
ip community-filter 5 permit --->后面什么都不写,表示包括所有属性
route-policy R2-R1-OUT deny node 10
if-match community-filter 5
quit
route-policy R2-R1-OUT permit node 20
bgp 234
peer 192.168.12.1 route-policy R2-R1-OUT export
方法2:
ip community-filter 5 permit internet -->因为任何路由都有internet属性,所以匹配internet就可以匹配所有路由
route-policy R2-R1-OUT deny node 10
if-match community-filter 5
quit
route-policy R2-R1-OUT permit node 20 ---->如果第一条匹配则拒绝,如果第一条没有匹配则执行第二条允许。
bgp 192.168.12.1 route-policy R2-R1-OUT export
BGP的默认路由
-针对所有邻居产生默认路由
步骤:
1.确保本地设备上存在默认路由{即前提条件}
2.将默认路由,宣告进入到BGP数据
-针对特定邻居产生默认路由
步骤:
1.确保自己本地存在“条件路由”{条件路由:可以是默认路由,也可以是其他类型的路由}
2.针对特定的邻居使用下面的命令
peer x.x.x.x default-route-advertise conditional-route-match-any {条件路由1}...{条件路由n} --->满足一个就可以
conditional-route-match-all {条件路由1}...{条件路由n} --->完全匹配
举例:R4
&peer 192.168.45.5 adfault-route-advertise conditional-route-match-all 10.10.3.0 24
//R4向邻居R5产生一个默认路由,前提条件是:R4本地有一个10.10.3.0/24的路由。
BGP的路由汇总
-作用
和其他协议中的“路由汇总的作用”是相同的。比如节省系统/链路的资源:提高网络的稳定性
-本地:
1. 发送路由的时候,一旦汇总了,就:只发汇总,不发明细
2.但是,在IGP协议中,一旦汇总了,就:只发汇总,不发明细:
在BGP协议中,一旦汇总了,就:即发汇总,也发明细:
但是,我们可以认为的灵活控制BGP发送路由的条目的多少【哪些IP能汇总,哪些IP不能汇总】;
-举例:R5
BGP 500
1、 aggregate 10.10.0.0 255.255.0.0
------>直接回车那么他的邻居就会得到一个10.10.0.0的汇总路由,但是,其他的明细路由还都存在,没有达到汇总的效果。
那么,在后面加一个参数 aggregate 10.10.0.0 255.255.0.0 detail-supressed,然后再查看邻居的bgp路由,就没有明细路由了。
而,R5本身的明细路由后面有的条目会带一个S,表示汇总被抑制的路由,也就是不会发送给邻居的路由。
2. aggregate 10.10.0.0 255.255.0.0 detail-suppressed suppress-policy ABC
------>后面再跟一个 suppress-policy 参数,可以控制被汇总的路由添加条件,允许哪些路由被抑制汇总,ABC表示策略名称。
那,我们再来创建一个策略来抓取路由。
route-policy ABC permit node 10
if-match ip-prefix 53
quit
ip ip-prefix 53 permit 10.10.53.0 24
------>最后被抑制的就是10.10.53.0 24这些路由,汇总为10.10.0.0/16 的路由了。
3.路由被汇总后路由的优先级默认是255,但是也是可以修改的
R5
BGP 500
preference x x x
---->这里的三个参数分别依次表示 EBGP路由的优先级 IBGP路由的优先级 本地产生的(local created)路由优先级。
4. as-set :
R4
bgp 234
aggregate 10.0.0.0 255.0.0.0
--->回车后在本地形成一个路由如下:
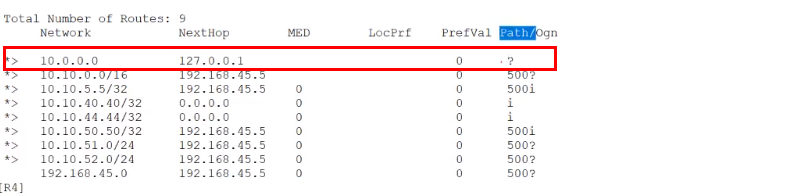
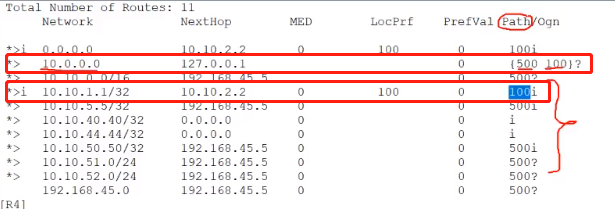
---->在path中是一个 ?,并没有显示被汇总路由的AS号,那再加上as-set参数,
aggregate 10.0.0.0 255.0.0.0 as-set
------>表示的是形成汇总的路由时,那些明细路由的AS号,都会放到本地BGP的AS-path属性中,并且放在大括号中
扩展命令;
1. 查看邻居是否接收到邻居的发送过来的路由
display bgp routing-table peer x.x.x.x received-routes
2.在本地路由上常看是否将路由发送给对等体。
display bgp routing-table peer x.x.x.x vdvertised-routes

