

细粒度图像分类(FGVC)理解与探究
细粒度图像分类(FGVC)理解与探究
细粒度图像分类与传统图像分类而言,细粒度图像分类中所需要进行分类的图像中的可判别区域(discriminative parts)往往只是在图像中很小的一块区域内。
在传统的图像分类网络中,无论图像中的重要判别区域占整个图像的比重有多大,都只会对整张图片一视同仁的提取特征。因此,在一些判别区域占图像比重较小的一些图片,进行同样的特征提取及处理,大量不关注的background信息会被训练进去,增加了图像分类的难度,降低分类的准确度。
引入细粒度图像分类这一概念,就是为了解决这样的问题,关注图像中细小的差别,实现更精确的图像分类:如蔬果中更细小的品种分类,草木的病虫害分类等。目前常规的细粒度图像分类的方法为,先得到关注目标的区域,再对该目标进行细分类,从而使网络更了解分类物体。
目前针对细粒度图像分类的训练方法主要有两类:强监督学习和无监督学习。
强监督学习
额外添加更多的bounding-box标注信息加入网络进行强监督学习,使网络能学习到目标的位置信息。
不足:(1)需要大量人力资源进行图像的标注。(2)人力标注的信息并不一定准确就是目标真正需要关注的区域。
(个人观点:添加了了更多的bounding-box标注信息进行图像的细节分类,方法上已经和目标检测很像,超出了图像分类的初衷)
弱监督学习
弱监督并不是无监督学习,而只是根据基本图像分类网络一样,只需要给出图像的类别即可。由网络通过无监督学习出判别区域的位置,再特别关注此区域的特征差异,识别出目标的类别。
常用方法有:
基于注意力(Attention)机制的图像分类,通过分析特征图中最突出的部分得到判别区域的位置。
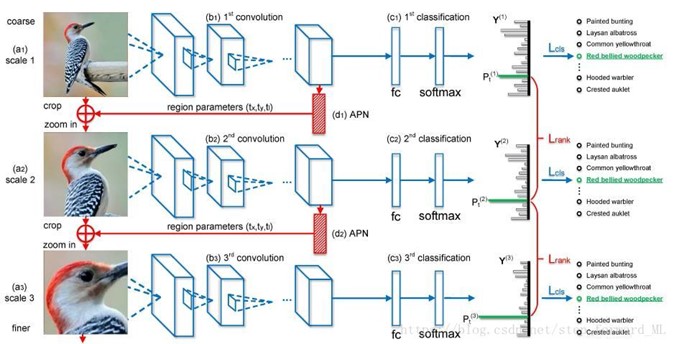
RA-CNN (Recurrent Attention Convolutional Neural Network):
算法分为两个部分,分类网络和注意力提取网络(APN, Attention Proposal Network),将图片进行三次注意力提取,得到最关注的区域,再通过三个通过不同尺度的feature map进行特征融合,再接入softmax进行分类。
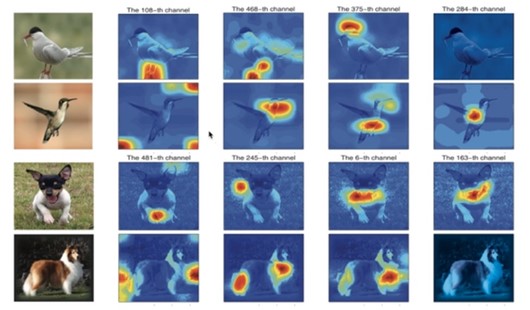
SENet: Squeeze-And-Excitation Networks
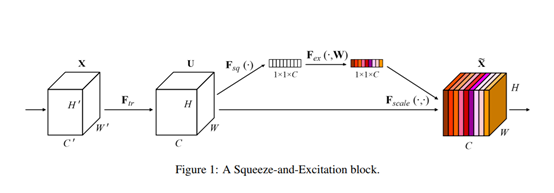
SENet通过注意力机制对卷积后的feature map的每个channel进行加权,提高关键特征的明显度,降低不必要特征的影响。可以嵌入到各类基础分类网络当中。
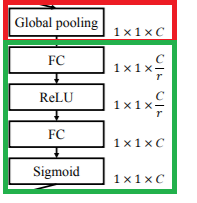
主要实现为:Squeeze通过global average pooling对feature map进行降维,将H*W降到1;Excitation通过一个bottleneck(结构为绿框),捕捉到不同channel的相关性,从而学习到channel间的注意力因子(attention factor)。
MAMC (Multi-Attention Multi-Class Constraint)
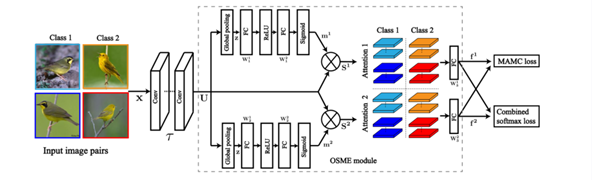
MAMC算法借鉴了SENet的注意力机制与度量学习的方法,改进了正负样本之间的关系,将正样本之间的距离更加接近,并稀疏了负样本之间的距离。这种方法改进了以上RA-CNN的多次多层的注意力提取融合的过程,改善RA-CNN引入噪声的影响,
该算法主要分为两个模块:OSME module和MAMC module
OSME:One-Squeeze Multi-Excitation
OSME主要借鉴了SENet的思想,不同的是采用了多层Excitation结构,产生了多种注意力结构,也就代表提取多个注意力区域传入后期的MAMC module进行分析。
MAMC: Multi-Attention Multi-Class Constraint
MAMC借鉴度量学习的方法,将OSME产生的多种注意力区域进行划分,拉近正样本之间的距离。此方法改进了RA-CNN中循环注意力的方法,防止了初次注意力检测就引入噪声而带来的后期的噪声不断放大带来的缺陷。并且整个过程为one-stage的过程,便以进行端到端的训练。
※SCDA(Selective Convolutional Descriptor Aggregation)
SCDA主题上不算是细粒度的图像分类,而应用在图像检索方向,但与FGVC有相似之处,SCDA是一种无监督检测算法,连图像级别的标注都不需要,自行分类图像的类别。通过对图像中主要物体的提取,对数据的图片进行聚类匹配,从而对数据中的图片进行相似检索,达到分类效果。
其具体流程为:通过预训练好的特征提取网络进行基础的特征提取,如(基于ImageNet预训练的VGG网络)取最后一层网络进行特征匹配。
将feature map进行堆叠求和,得到最突出的物体区域,随后滤除较小的噪声,只保留主体区域。
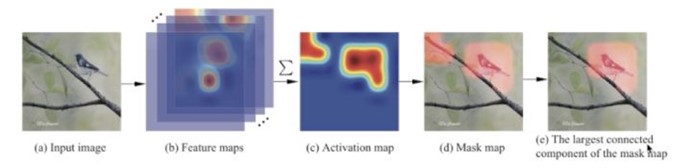
再将图片与其他图片提取出来的特征进行距离分析(度量学习?k-means?),分出图片类别。
※Meta-Reinforced Synthetic Data for One-Shot Fine-Grained Visual Recognition
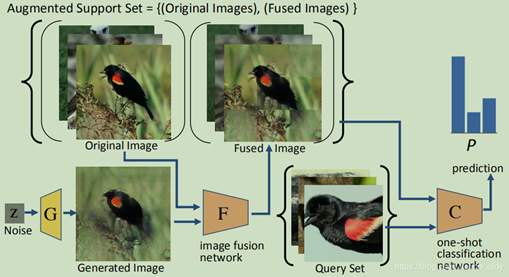
这篇论文讨论了GAN生成图像在细粒度图像分类中的作用及局限性。细粒度图像分类的特点为区分图像中细小的差别,而GAN网络生成的图像特征通常较为模糊,并且可能并没有很好生成可区分的判断区域。所以来说,如果直接将GAN网络生成的图像直接仍入FGVC网络中,会造成网络的模糊与抖动,从而造成精度的下降。所以,paper中为了使GAN生成的图像能适用细粒度图像分类,提出了用真实图像强化GAN生成的图像的方法,尽可能的保留原图的细粒度特征,从而使GAN能在细粒度图像识别中取得一定作用。(但是生成样本不能过多,会造成网络倾斜于生成图像,对真实图像检测精度降低)
