论文阅读《LEX-BERT: Enhancing BERT based NER with lexicons》
| key | value |
|---|---|
| 论文名称 | LEX-BERT: Enhancing BERT based NER with lexicons |
| 一作 | Wei Zhu |
| 单位 | 上海华东师范大学; 圣地亚哥AI4ALL |
| 发表 | ICLR 2021 |
| 领域 | 命名实体识别 |
| 主要贡献 | 提出一种将词信息融入到字嵌入的方法 |
| 基础模型 | Chinese BERT-wwm-ext |
| 优化器 | AdamW |
| 数据集 | Chinese Ontonotes 4.0; ZhCrossNER |
| 最终成绩 | 成绩超过BERT和FLAT; 推理时间更短 |
| 摘要 | In this work, we represent Lex-BERT, which incorporates the lexicon information into Chinese BERT for named entity recognition (NER) tasks in a natural manner. Instead of using word embeddings and a newly designed transformer layer as in FLAT, we identify the boundary of words in the sentences using special tokens, and the modified sentence will be encoded directly by BERT. Our model does not introduce any new parameters and are more efficient than FLAT. In addition, we do not require any word embeddings accompanying the lexicon collection. Experiments on MSRA and ZhCrossNER show that our model outperforms FLAT and other baselines. |
| 论文链接 | https://arxiv.org/pdf/2101.00396.pdf |
| 源码链接 | 无 |
主要内容
本文提出一种更加优雅的方法,将词信息融入到字嵌入中去,如下图,在每个词第一个字对应的位置上,加上词的词性标签(文中称为marker),且和text中的token共享位置id

另外在attention mask上,text tokens只能看到彼此,看不到marker,而marker是可以看到所有的。注意力掩码如下图所示:
成绩

成绩比FLAT更好,虽然领先不多。
推理速度
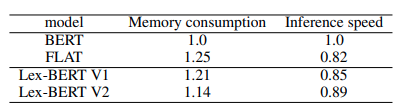
本文的做法非常优雅,相比FLAT,确实达到了简单且高效,只可惜数据集太少(只有两个且其中一个还是作者自己的数据集),需要补充在其他数据集上的成绩,才能得出更具有说服力的结论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号