
Skip-Gram的改进工作——SSG和DSG
回顾Skip-Gram[1]
Skip-Gram根据中心词来预测上下文词,其损失函数为:
其中
Structured Skip-Gram Model, SSG[2]
由(2)式可知,SG在预测上下文词的时候没有考虑位置信息。基于此,SSG提出上下文词不再由一个预测器生成,而是由2c个预测器共同决定生成。具体地,对于任意一个词\(w_{t+i}\)都会计算它出现在中心词\(w_t\)每个上下文位置上的概率,然后全部相乘作为\(w_{t+i}\)的预测概率,计算过程如下:
其中\({v'}_{r, w_{t+i}}\)是\(w_{t+i}\)在\(w_t\)每一个相对位置\(r\)上的输出表征。
下图是SSG这种改进思路得到的词向量在依存分析任务上的提升:

Directional Skip-Gram Model, DSG[3]
在DSG中,一个词的词嵌入不仅仅受到词共现的影响,还受到其上下文词的方向的影响。举个例子,"merry"和"eve"都是"Christmas"的高频共现词,给定"Christmas",识别要预测的词在左侧还是右侧对学习"merry"和"eve"的词嵌入非常重要。
于是DSG提出如下softmax函数:
函数g度量了上下文词\(w_{t+i}\)在\(w_t\)左边或者右侧上下文或者左侧上下文时与\(w_t\)的关联,每个\(w_{t+i}\)的\(\delta\)向量表明了它对着\(w_t\)的相对方向。
g的更新规则为:
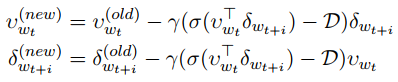
其中\(\sigma\)表示一个sigmoid函数,\(\gamma\)表示衰减的学习率,\(D\)表示给定\(w_t\)条件下指定\(w_{t+i}\)相对方向的目标标签。当i小于0是,D=1,否则等于0;
DSG最终将二者综合作为损失函数:
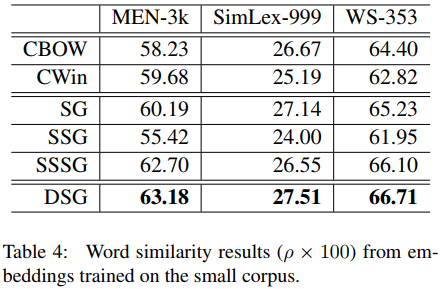
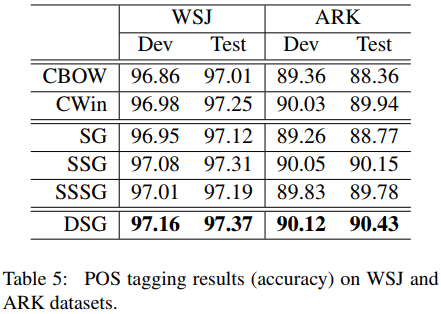
DSG在下游的成绩有了明显的提升,而且计算量不大,如下图所示。
总结
SSG的提升不是很大,计算量反而大了很多;DSG相比,既有明显的提升,而且计算量也不是很大。
Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. ICLR Workshop, 2013. ↩︎
Ling W, Dyer C, Black AW, Trancoso I. Two/too simple adaptations of word2vec for syntax problems. InProceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies 2015 (pp. 1299-1304). ↩︎
Song Y, Shi S, Li J, Zhang H. Directional skip-gram: Explicitly distinguishing left and right context for word embeddings. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) 2018 Jun (pp. 175-180). ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号