
Word2Vec
Word2Vec是Tomas Mikolov于2013年提出的文本向量化方法[1][2][3],可以在大量文本语料上通过无监督训练学到词的分布式向量表示。和之前的分布式词向量学习模型相比,Word2Vec的模型不仅简单高效(计算量更少),在词相似度和词类比两个评测任务上都取得了更好的成绩,是一个划时代的作品。

Tomas Mikolov
Word2Vec提出CBOW、Skip-Gram两种模型架构,二者都基于窗口内的词共现信息[4]来训练模型,还提出Hierarchical Softmax、Negative Sampling两种优化算法来提高训练效率。
CBOW
CBOW(Continuous Bag-of-Words)根据窗口内的上下文词来预测中心词,其模型结构如下图所示,从左往右依次是输入层、映射层和输出层。
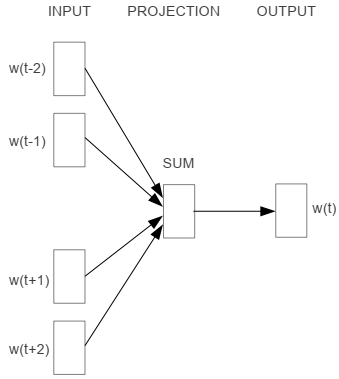
- 输入层:输入one-hot形式的上下文词\((w_{t-c}, ..., w_{t-1}, w_{t+1}, ..., w_{t+c})\),其中\(w_t\)表示中心词,\(c\)为窗口尺寸;
- 映射层:映射层的参数矩阵\(\cal V \in \Bbb R^{d \times |V|}\)包含了各个词对应的input embedding,其中d为词向量的维度,\(|V|\)表示词典的大小。通过映射可以得到各个上下文词的词向量\((v_{t-c}, ..., v_{t-1}, v_{t+1}, ..., v_{t+c})\),求均值:
- 输出层:输出层的参数矩阵\(\cal U \in \Bbb R^{|V| \times d}\)包含了各个词对应的output embedding,通过相乘可以得到每个词的分数,然后对输出进行softmax计算:
目标函数为:
CBOW采用随机梯度下降来对参数进行优化。
Skip-Gram
和CBOW相反,Skip-Gram是根据中心词来预测上下文词,其模型架构如下图所示:
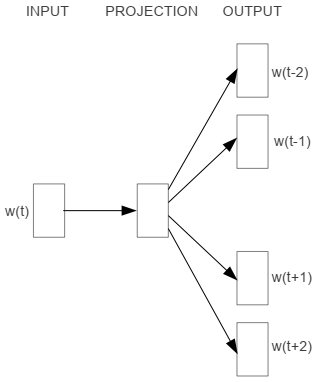
模型同样是三层结构:
- 输入层:输入中心词\(w_t\);
- 映射层:通过\(\cal V\)得到中心词的input embedding \(v_t\);
- 输出层:通过\(\cal U\)得到分数向量,然后进行归一化处理:
由于Skip-Gram预测的是上下文词,所以输出不止一个。Skip-Gram假设给定中心词的条件下,各个上下文词的预测彼此独立,于是目标函数可表示为:
同样Skip-Gram也是采用随机梯度下降来进行参数估计。
Skip-Gram输出层只包含一个参数矩阵\(\cal U\),在训练时,Word2Vec根据中心词预测各个上下词的过程是互相独立的,也就是会分开计算各个正确上下文词对应的损失值来进行反向传播训练。但是,Word2Vec模型不需要测试,输入嵌入对应的矩阵参数\(\cal V\)就是训练得到的词向量,直接基于此计算词向量的性能度量即可。
CBOW和Skip-Gram的计算量都很大,因为要计算一个词典大小的分数向量,然后再进行softmax归一化。当词典很大的时候,分数几乎都接近0。所以为了提高计算效率,Word2Vec提出了下面两种优化算法。
Hierachical Softmax
Hierachical Softmax借助哈夫曼树(Huffman Tree)来提高解码的效率,它把词典中所有的词根据词频排成哈夫曼树,使得高频词靠近树根,低频词远离树根。这样依次计算各个词的分数的过程变成从树根到任意叶子结点的行走过程,计算次数可从\(|V|\)降至\(\log_2 |V|\)(树的高度)。
以下图为例,每个叶子结点对应一个词,每个内部结点(非叶子结点)都包含一个向量。

假设
- \(L(w)\)是从根结点到\(w\)叶子结点路径中所有内部结点的数量,如\(L(w_2)=3\);
- \(n(w, i)\)表示该路径上的第\(i\)个结点,对应的向量为\(v_{n(w,i)},\)如\(n(w, 1)=root\),\(n(w, L(w))\)是\(w\)的父结点;
- 对于任意一个内部结点,\(ch(n)\)表示n的固定方向的子结点(要么一直为左子结点,要么一直为右子结点)。
于是采用Hierachical Softmax的概率计算公式为:
其中
因为有了\([x]\),使得任意一个内部结点上,左右的概率和为1:
并且也不难证明\(\sum_{w=1}^{|V|}P(w|w_i)=1\)。
假如在行走过程中的方向选择分别为左、左、右,那么(*)式具体为:
由此可见,原先\(|V|\)个output embedding变成了哈夫曼树所有内部结点的向量,共计\(\frac{1}{2}n(n-1)\)个。
Negative Sampling
和Hierarchical Softmax不同,Negative Sampling从训练的角度提出优化,对于每个正例数据(w, c),c为中心词,w为上下文词,只引入部分负样例数据来进行对比学习,使得模型具备区分二者的能力。
假设(w, c)为正、负样例的概率分别为:
则根据极大似然估计得到损失函数为:
目标函数为似然函数的负对数形式:
这里的损失函数分两项,对于正例数据,损失值为前一项;对于负例数据,损失值为后一项。
论文[2:1]中给出了negative sampling的另一种表达形式:
其中\(w_I, w_O\)分别表示输入词和输出词,\(v', v\)分别表示output embedding和input embedding。该式子对负样本表达地更加清晰,即负样本服从一个噪声分布P(n)[5]。
高频词下采样
训练集中每个词\(w_i\)被丢弃的概率为:
其中\(t\)表示阈值,一般取\(10^{-5}\)左右;该式子使得模型倾向于丢弃频率大于\(t\)的高频词,因为高频词往往是一些无意义词。
Linguistic Regularities in Continuous Space Word Representations. Tomas Mikolov, Wen-tau Yih, and Geoffrey Zweig. NAACL 2013. ↩︎
Efficient Estimation of Word Representations in Vector Space. Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. ICLR 2013. ↩︎ ↩︎
Distributed Representations of Words and Phrases and their Compositionality. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg Corrado, and Jeffrey Dean. NIPS 2013. ↩︎
假设窗口大小为c,中心词前c个词和后c个词组成该中心词的上下文。 ↩︎
原文对于噪声分布的介绍很少,故不展开。 ↩︎

 浙公网安备 33010602011771号
浙公网安备 33010602011771号