CheckList:ACL 2020 Best Paper
Beyond Accuracy: Behavior Testing of NLP Models with CheckList. Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, Sameer Singh. ACL 2020
摘要
在测试集上评估模型,会高估模型;而其他的一些方法又只聚焦于单个任务或者模型的单个行为。
受到软件工程行为测试的一些原理的启发,本文提出checklist,一种任务不可知的NLP模型测试方法。它包含两个部分:(1)一个由通用语言学能力(capabilities)和测试类型(test type)构成的矩阵,有助于形成综合测试思维;(2)一个可以快速生成大量具有多样性的测试用例的软件工具。
本文在三个任务上通过测试来阐述checklist的效用,无论是学术界还是工业界SOTA模型,checklist都可以发现它们的致命错误。另外,本文还做了两个用户研究:(1)帮助商用情绪分析模型的负责团队(其实就是微软自家的团队)发现了他们之前没有发现的bug;(2)使用checklist的NLP从业人员创建的测试用例数量是没有使用checklist的两倍,发现的bug数量几乎是没有使用checklist的3倍。
测评矩阵
测评的过程就是填矩阵的各个单元格。矩阵的每一行对应一项能力,每一列对应一个测试类型。
作者列举了一些能力,当然使用者也可以继续添加:
- Vocabulary+POS能力:识别任务中那些重要的词或者重要的词类型
- Taxonomy
- Robustness: 能够不受一些无关的改变的影响
- NER:能够理解命名实体,即改变地名不会影响句子的情绪
- Fairness
- Temporal:改变事件的顺序
- 否定(Negation):能够搞懂否定词带来的否定语义效果
- Coreference:能够搞清楚共指/指代关系
- 语义角色标注(Semantic Role Labeling)
- 逻辑(Logic)
而在矩阵的列上,就是测试类型了。主要分为三大类:最小功能测试(Minimum Functionality test, MFT)、不变性测试(Invariance test, INV)和方向期望测试(Directional Expectation test, DIR)。
最小功能测试MFT
MFT来自于单元测试,对于复杂的输入,模型可能是走捷径处理了,实际上并没有掌握该能力。所以可以弄一些模板和词典来生成更多的样例,看看那些模型是否能够get到那些不变的核心词。vocabulary+POS就全是MFT。
INV和DIR测试
INV和DIR都是来自于软件变形测试(software metamorphic tests),INV是希望做一些小的扰动,但是标签应该保持不变,比如对于句子情绪分类,把其中的一个地名改成另一个地名,情绪的类别应该不变。而DIR则相反,通过制造一些扰动,希望模型预测的标签按照某个确定的方向改变。比如我们希望加了you are lame的句子的情绪不再是positive;再比如,如果有个句子对how many people are there in england和what is the population of england在改变后一个句子的地名为turkey后,句子对应该变成不再是duplicative。
INV和DIR都可以在无监督的数据上对模型进行测试。
总结:capababilities就是测试的内容,即回答了what to test,考查的就是模型的某种行为,它可以用在任何任务上;test type就是测试的方法了,回答了how to test。
接下来看一张图,看看这个矩阵到底长啥样以及这个矩阵是怎么填的:
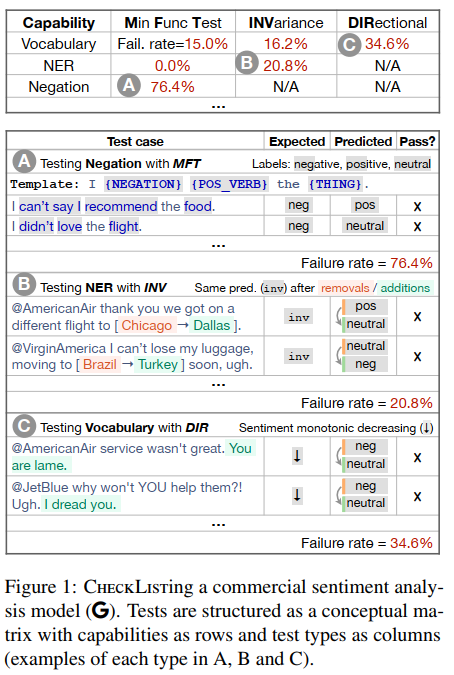
每个单元格都要填写,每一行测试模型的一个能力。每一列都是一种测评方法。图下面是测试用例,A对应上面表格的A,negation是测试否定,按照模板来测试;B是测试NER,把地名更改,应该不会影响情绪,然而实际上都变了;C测试词汇,改了一些词,情绪应该变消极,但是实际上却从负面变成中立了。
打叉,说明当前测试样例不通过。
接下来看下直接在microsoft text analytics, google cloud's natrual language, amazon's comprehend三个工业模型以及bert, roberta两个学术模型上测试。在此之前请记住:Bert和roberta在SST-2数据集上的准确率分别是92.7%和94.8%,在QQP数据集上的准确率分别是91.1%和91.3%,在SQuAD上,本文测评了bert-large,它的F1是93.2%
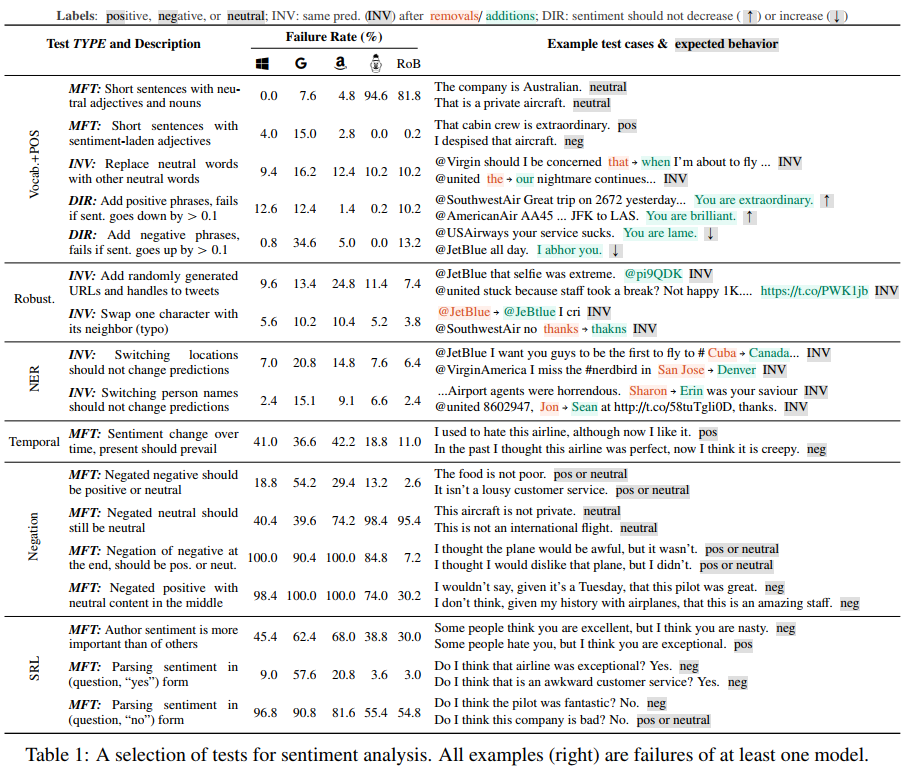
通过这张图可以看到,在情绪分析任务上,negation的成绩很差。第一个是通过否定负面来达到积极或者中立,实现的方式是MFT,走的是模板,错误率还好;但是第三个,在结尾处否定负面来达到中立或者积极,结果错了很多;第四个,在句子中间加入中心的内容来否定积极,结果错的很明显,达到了100%的错误率。
再来看一张,另一个任务的,相同问题QQP任务

主动和被动的切换(active and passive),出错率也是挺高的。
再来看最后一个任务,阅读理解:

共指/指代关系那个功能,基本上预训练表现的很差。
软件工具
关于如何快速生成测试用例,这个暂时用不到,不展开陈述了,以后有兴趣再深入研究。
总结
本文被评为ACL2020 best paper,提出的checklist是一种新的NLP模型测试方法,第一次读起来感觉没有太多技术含量,但是它直面挑战了工业界和学术界的SOTA预训练模型并找出了他们的致命bug,在有些行为测试方面错误率甚至达到了100%,暴露出了算法的一些偏见和歧视(性别歧视、种族歧视等)
如果出现某个地名算法就更容易预测出某种情绪,如果出现某个肤色或者性别,就更容易出现某种结果,这就是一种歧视,也是算法的一种偏见。由于是大数据驱动的,所以这种问题再所难免。
所以checklist的意义不仅仅提出了新的模型测评范式,它还给未来的预训练研究指明了新的方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号