ptotocol buffer的一些注意点
[default=value],default表示默认值,
[packed=true],改变repeated字段编码,建议尽量使用,不带的话,采用T-V对存储,浪费了空间,使用后可以省去多个Tag
[deprecated=true],原来的有些字段不需要的时候,考虑到兼容老数据,使用这个参数来标志
字段标志号Field_Number尽量用1-15,如果超过的话,Field_Number编码就会占用两个字节,Tag也会占用更多字节
如果使用字段出现负数,尽量使用sint32 / sint64,不要使用int32 / int64
| Proto类型 | C++类型 | 备注 |
| double | double | |
| int32 | int32 | 使用可变长编码,有负数时不够高效,在有负数的情况下建议使用sint32 |
| int64 | int64 | 同上,建议sint64 |
| uint32 | uint32 | |
| uint64 | uint64 | |
| sint32 | int32 | 使用可变长编码,有符号整型,先采用Zigzag编码再用Variant编码,更有效压缩数据 |
| sint64 | int64 | 同上 |
| fixed64 | uint64 | 总是8个字节,如果值总是大于456的话,这个类型比uint64高效 |
| sfixed64 | uint64 | 总是8个字节 |
| fixed32 | uint32 | 总是4个字节,如果值总是大于228的话,这个类型比uint32高效 |
| sfixed32 | int32 | 总是4个字节 |
| bytes | string | 可能包含任意顺序的字节数据 |
| string | string |
对int32 / int64类型,如果值大于等于0,直接采用可变长编码,否则采用64位可变长编码,所以其编码结果永远是10个字节,所以在负数情况下效率很低
对sint32 / sint64类型,首先对值采用ZigZag编码,然后将结果再用可变长编码。
ZigZag编码:将负数变成正数,而所有正数乘2,比如:0-》0,-1-》1,1-》2,-2-》3,所以对负数的编码保持比较高的效率,
代码实现:编码:对32位:(n << 1 ) ^ (n >> 31)
对64位:(n << 1) ^ (n >> 63)
解码:对32位:(n >> 1) ^ -(n & 1)
对fixed32 / sfixed32 / fixed64 / sfixed64类型,将值以小端模式的固定长度编码
对int32 / int64这些可变长编码,Google使用Base128 Varints
方式:
1.前面的byte表示数值低位,后面的是高位
2.每个byte,第1位表示是否还有另一个byte,后7位表示数值
例子:267的2进制编码为0001 0000 1011-》高低位互换,后7位 0000 1011 作为放前面,最高位为1,即:1000 1011,其余的0001,最高位为0,即:0000 0001,拼起来-》1000 1011 0000 0001
proto序列化:https://www.jianshu.com/p/30ef9b3780d9
数据存储方式:T-L-V,Tag-Length-Value,标识-长度-字段值

序列化 = 对数据编码 + 存储
protocol buffer对不同的数据类型有不同的编码,也会导致存储方式的不同
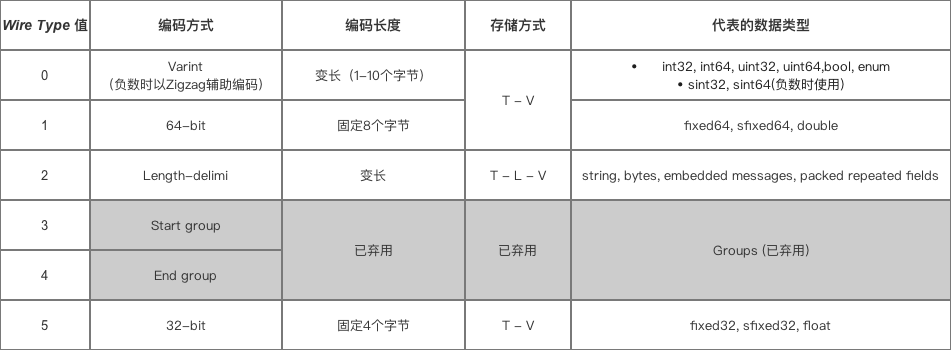
对 0 ,1,5这几种类型,都是用小端模式,即低位在前,高位在后


 浙公网安备 33010602011771号
浙公网安备 33010602011771号