Celery的使用
celery是什么
Celery是一个简单、灵活且可靠的,处理大量消息的分布式系统,专注于实时处理的异步任务队列,同时也支持任务调度。
Celery的架构由三部分组成,消息中间件(message broker),任务执行单元(worker)和任务执行结果存储(task result store)组成。
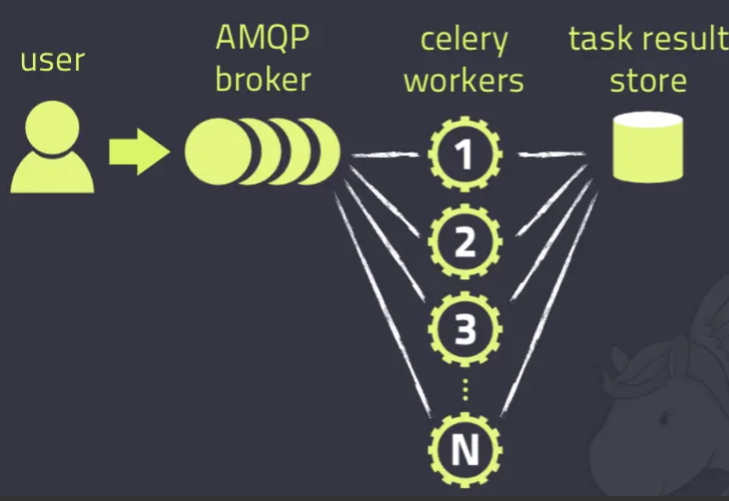
消息中间件
Celery本身不提供消息服务,但是可以方便的和第三方提供的消息中间件集成。包括,RabbitMQ, Redis等等
任务执行单元
Worker是Celery提供的任务执行的单元,worker并发的运行在分布式的系统节点中。
任务结果存储
Task result store用来存储Worker执行的任务的结果,Celery支持以不同方式存储任务的结果,包括AMQP, redis等
另外, Celery还支持不同的并发和序列化的手段
并发:Prefork, Eventlet, gevent, threads/single threaded
序列化:pickle, json, yaml, msgpack. zlib, bzip2 compression, Cryptographic message signing 等等
使用场景
celery是一个强大的 分布式任务队列的异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。我们通常使用它来实现异步任务(async task)和定时任务(crontab)。
异步任务:将耗时操作任务提交给Celery去异步执行,比如发送短信/邮件、消息推送、音视频处理等等
定时任务:定时执行某件事情,比如每天数据统计
celery通过消息(任务)进行通信,
celery通常使用一个叫Broker(中间人/消息中间件/消息队列/任务队列)来协助clients(任务的发出者/客户端)和worker(任务的处理者/工作进程)进行通信的.
clients发出消息到任务队列中,broker将任务队列中的信息派发给worker来处理。
client ---> 消息 --> Broker(消息队列) -----> 消息 ---> worker(celery运行起来的工作进程)
消息队列(Message Queue),也叫消息队列中间件,简称消息中间件,它是一个独立运行的程序,表示在消息的传输过程中临时保存消息的容器。
所谓的消息,是指代在两台计算机或2个应用程序之间传送的数据。消息可以非常简单,例如文本字符串或者数字,也可以是更复杂的json数据或hash数据等。
所谓的队列,是一种先进先出、后进呼后出的数据结构,python中的list数据类型就可以很方便地用来实现队列结构。
目前开发中,使用较多的消息队列有RabbitMQ,Kafka,RocketMQ,MetaMQ,ZeroMQ,ActiveMQ等,当然,像redis、mysql、MongoDB,也可以充当消息中间件,但是相对而言,没有上面那么专业和性能稳定。
并发任务10k以下的,直接使用redis
并发任务10k以上,1000k以下的,直接使用RabbitMQ
并发任务1000k以上的,直接使用RocketMQ
安装
pip install -U Celery
或着:
sudo easy_install Celery
Celery不建议在windows系统下使用,Celery在4.0版本以后不再支持windows系统,所以如果要在windows下使用只能安装4.0以前的版本,而且即便是4.0之前的版本,在windows系统下也是不能单独使用的,需要安装gevent、geventlet或eventlet协程模块
基本使用
遇到的坑
数据库的数据类型格式
celery我尝试将返回数据存储到了数据库,下面是数据库的几个数据类型介绍
MySQL 文本数据类型概览
TINYTEXT: 最多存储 255 字节。
TEXT: 最多存储 65,535 字节,约 64KB。
MEDIUMTEXT: 最多存储 16,777,215 字节,约 16MB。
LONGTEXT: 最多存储 4,294,967,295 字节,约 4GB。
TINYBLOB: 存储容量: 最多存储 255 字节。 用途: 用于存储非常小的二进制数据。
BLOB:存储容量: 最多存储 65,535 字节(约 64KB)。用途: 一般用于中等大小的二进制数据,如小型图像文件或文档。
MEDIUMBLOB:存储容量: 最多存储 16,777,215 字节(约 16MB)。用途: 适合存储较大的二进制数据,比如音频和视频文件。
LONGBLOB:存储容量: 最多存储 4,294,967,295 字节(约 4GB)。用途: 用于存储非常大的二进制数据,例如完整的电影或数据库备份。
数据库自身创建的result字段为text,所以后端接口的数据超过了64kb就异常报错了,需要改成LONGBLOB,
为什么不改成LONGTEXT呢,是因为我Python的celery即使在celery中设置了json,实际存储再数据库的还是二进制格式,因此需要使用LONGBLOB,并且数据库的字段最好默认使用UTF8或者utf8mb4
celery发送,返回,存储的数据格式设置
# 设置task的序列化和反序列化方式,如json、pickle、msgpack等
app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json', 'pickle'], # 设置接收的格式
)
json和pickle区别在于
json适合存储为字符串,便于人读取,同时具有较好的兼容性。
pickle可以存储复杂的 Python 对象,但是有安全风险,因为 pickle 文件可以在反序列化时执行任意代码,可能被用以植入恶意代码,因此在仅信任的环境下使用这种序列化格式。
celery定时延时的坑
celery中如果要使用定时功能,预约功能的话,必须要把时区设置好,并且关闭UTC,设置参数参考下面(延时功能不需要,使用countdown参数实现倒计时)
app.conf.update(timezone='Asia/Shanghai',enable_utc=False)
在几种功能中如果使用到了eta这个属性,因为传入的必须是datetime实例对象,而该对象也需要配置时区,不然eta会因为传入的datetime没有时区而无法正确执行
在 Celery 中,支持多种用于任务调度的时间相关功能,包括定时任务(周期性任务)、预约任务(定时执行一次)以及延时任务。虽然它们都涉及时间概念,但不一定总是需要传入 datetime 的实例对象。
1. 延时任务
对于延时任务,你可以直接使用 countdown 参数,而无需 datetime 对象:
# 延时 10 秒执行任务
task_1.apply_async(countdown=10)
或者可以使用 eta 参数,传入一个 datetime 对象,指定任务应该执行的确切时间:
from datetime import datetime, timedelta
# 设置任务将在5秒后执行
eta = datetime.now() + timedelta(seconds=5)
task_1.apply_async(eta=eta)
2. 预约任务
预约任务需要在特定时间执行一次,通常使用 eta 参数,它需要一个包含时区的 datetime 对象:
from datetime import datetime, timedelta
import pytz
# 使用具有时区信息的 `datetime` 对象
eta = datetime.now(pytz.timezone('Asia/Shanghai')) + timedelta(seconds=30)
task_1.apply_async(eta=eta)
3. 定时任务(周期性任务)
周期性任务通过 Celery 的 beat 调度器来实现,不需要 datetime 实例,而是使用时间表(如 crontab 或 timedelta)。
from celery.schedules import crontab
# 每天上午7点执行
app.conf.beat_schedule = {
'morning_task': {
'task': 'task_1',
'schedule': crontab(hour=7, minute=0), # 使用 crontab 表达式
}
}
# 每10分钟执行一次
app.conf.beat_schedule['periodic_task'] = {
'task': 'task_1',
'schedule': timedelta(minutes=10) # 使用 timedelta 指定频率
}
beat_schedule 需要用beat参数 celery -A MyCelery.main beat -l info 这里beat参数会读取beat_schedule里的配置参数,定时执行插入任务.
此时如果没有执行这条命令celery -A celery_tasks.mycelery worker -l info开启worker进行监听,beat_schedule里的任务会存放到队列中,会形成任务堆积,
虽然在早期版本的 Celery 中可以使用 -B 参数 celery -A MyCelery.main worker -B -l info来同时启动 Worker 和 Beat,但是在 5.4.0 及以后的版本中建议各自运行,以提升应用的可靠性和管理性。
总结:
beat_schedule 只是将任务存放队列中,如果worker不执行 会堆积
worker开启监听后会执行队列中的任务,两个线程各司其职.
总结
- 延时:可以使用
countdown(秒数)或eta(datetime对象),其中eta需要考虑时区。 - 预约:使用
eta,需提供具体的datetime实例。 - 定时:通过 Celery beat 结合
crontab和timedelta来设定,不需要datetime对象。
不同的调度需求根据具体用例选择对应的配置方式。特别是在涉及具体时间的预约任务时,确保 datetime 对象的时区信息明确,这对于准确执行计划至关重要。
celery使用pickle的安全告警
当你使用accepte_content=['pickle']的时候并且还是用root账号运行的情况下,会有告警如下
worker accepts messages serialized with pickle is a very bad idea!
If you really want to continue then you have to set the C_FORCE_ROOT
environment variable (but please think about this before you do).
User information: uid=0 euid=0 gid=0 egid=0
在运行 Celery worker 时遇到的这个警告是因为你正在以超级用户(root 用户)权限运行,并且 Celery 的 accept_content 中包含了 pickle。由于 pickle 序列化具有安全风险(它可以在反序列化时执行任意代码),因此以 root 用户运行并接受 pickle 格式存在严重的安全隐患。
处理建议
避免以 root 用户运行 Celery worker
最佳实践是避免以 root 用户运行 Celery worker,以降低出于安全漏洞或代码注入而导致系统全盘崩溃的风险。可以创建一个专用的非特权用户专用于运行 Celery,并调整该用户的权限以获得所需的最小权限。
你可以如下方式创建一个非特权用户并运行 Celery:
sudo adduser celeryuser
sudo su celeryuser
celery -A tasks worker -l info
移除 pickle 序列化格式
如果可能,考虑改用更安全的序列化形式,例如 json。更新 Celery 配置使其不接受 pickle 格式,并仅使用 json:
app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json'], # 只接受JSON格式
)
确有必要时使用 C_FORCE_ROOT (不推荐)
如警告信息所建议的,如果 确有必要 必须以 root 用户运行,并且希望继续接受 pickle,可以设置环境变量 C_FORCE_ROOT=1 来绕过阻止。这种方式极其不安全,容易造成系统的安全问题,所以一般不推荐。
在 shell 中设置环境变量:
export C_FORCE_ROOT=1
celery -A tasks worker -l info
注意: 使用此选项前仔细考虑潜在风险。仅当完全理解并能控制风险的场合下使用。
总结
避免以 root 用户权限运行 Celery,选择安全的序列化方式是保护系统安全的重要措施。当开发和部署应用时,应坚持最小权限原则和安全优先的策略。
celery的常用配置参数
@app.task() 装饰器中的常用配置参数
name:
用途:指定任务的名称。如果不设置,将使用函数的模块路径加函数名作为任务名称。
示例:@app.task(name='my_custom_task_name')
ignore_result:
用途:如果设置为 True,任务执行结果将不会被存储。这在不需要后期使用任务结果时可以节省存储空间。
示例:@app.task(ignore_result=True)
bind:
用途:如果设置为 True,任务将会绑定到方法,使得它可以访问任务实例:可以通过 self 访问实例以及任务上下文。这里的self就是Task的实例对象,还可以设置错误重试
示例:
@app.task(bind=True, name='cve_vul')
def cve_vul(self, *args, **kwargs):
try:
# Your task logic here
pass
except Exception as e:
logger.error(f"cve_vul task failed with error: {str(e)}")
# Optional: Add custom retry logic or further trace information
raise self.retry(exc=e,countdown=60, max_retries=self.max_retries, retry_backoff=True)
retry 常用参数
exc:指定引发重试的异常(通常是你捕捉到的异常)。
countdown:指定重试前等待的秒数。例如,countdown=60 表示等候 60 秒后重试。
eta:指定一个具体的时间点来安排下一个重试(一个 datetime 对象)。
max_retries:设置最大重试次数。如果重试次数超过这个值,任务会失败并且不会再尝试。
retry_backoff:如果设为 True,则适用指数回退策略进行重试,后续重试会间隔更长时间。
retry_backoff_max:设置最大回退时间,单位为秒。
retry_jitter:在重试等候时间上增加随机抖动,避免所有失败任务在同一时间重试。
max_retries:
用途:设置任务的最大重试次数。
示例:@app.task(max_retries=3)
default_retry_delay:
用途:重试任务时的默认延迟时间,单位为秒。
示例:@app.task(default_retry_delay=60)
serializer:
用途:定义任务序列化使用的格式,常用的有 json, pickle, yaml。
示例:@app.task(serializer='json')
app.conf.update() 中的常用配置参数
broker_url:
用途:指定消息代理的 URL 地址,如 RabbitMQ、Redis 等。
示例:app.conf.update(broker_url='redis://localhost:6379/0')
result_backend:
用途:指定任务结果存储的后端,可以是 Redis、数据库等。
示例:app.conf.update(result_backend='redis://localhost:6379/0')
task_routes:
用途:定义任务路由规则,将任务发送到不同的队列。
示例:app.conf.update(task_routes={'myapp.tasks.add': {'queue': 'hipri'}})
task_serializer:
用途:设置所有任务的默认序列化方法。
示例:app.conf.update(task_serializer='json')
result_serializer:
用途:设置返回结果的序列化方法。
示例:app.conf.update(result_serializer='json')
accept_content:
用途:接受的内容类型列表,主要用于安全目的。
示例:app.conf.update(accept_content=['json', 'application/text'])
timezone:
用途:设置时区信息。
示例:app.conf.update(timezone='UTC')
enable_utc:
用途:如果为 True,则会使用 UTC 时间。
示例:app.conf.update(enable_utc=True)
task_acks_late:
用途:如果设置为 True,任务只在成功完成后确认。如果任务失败或重启,任务将重新排队。
示例:app.conf.update(task_acks_late=True)
worker_concurrency:
用途:设置 worker 的并发数量,通常与 CPU 核心数量匹配。
示例:app.conf.update(worker_concurrency=4)
这些配置配置参数帮助您微调 Celery 的运行时行为,以满足应用程序需求。根据具体的场景和性能要求,您可以选择性地应用这些配置。
调用异步celery任务的几种方法
这三种方法都是来自Task类from celery import Task
结论
- delay():适合简单的任务调用。
- apply_async():用于需要定制任务行为的高级调用。
- send_task():适用于通过任务名称调用的场景,常在任务解耦/分布式系统中使用。
delay() 是一种简单方便的调用方式,仅支持提供任务参数,不支持高级选项。它基于 apply_async(),但对于不需要额外配置的任务调用是最简洁的。
@app.task
def add(x, y):
return x + y
# 使用 delay() 调用任务
result = add.delay(4, 6)
print("Task result:", result.get()) # Outputs: 10
apply_async() 提供了最强大的配置选项,允许对任务的执行进行精细控制。
常用参数:
args: 传递给任务的参数,以列表形式提供。
kwargs: 传递给任务的关键字参数,以字典形式提供。 有个注意点看下面kwargs的注意事项
countdown: 指定延迟执行时间(以秒为单位)。
eta: 指定一个未来的执行时间。
queue: 任务队列名。
exchange, routing_key: 用于自定义任务路由。
retry: 控制失败任务是否自动重试。
expires: 设置任务的过期时间。
# 使用 apply_async() 调用任务
result = add.apply_async(args=(4, 6), countdown=10) # 延迟 10 秒执行
print("Task will execute after 10 seconds.")
print("Task result:", result.get()) # 获取执行结果
send_task() 通过任务名称来调用任务,这使得它特别适合需要通过配置文件或其他不直接依赖 Python 代码的方式运行任务。
常用参数:
name: 指定要调用的任务名称。
args 和 kwargs: 同上,传递给任务执行的参数。 有个注意点看下面kwargs的注意事项
其他参数(同 apply_async()): 包括 countdown, eta, queue, exchange, routing_key, retry, expires 等。
示例:
# 使用 send_task() 调用任务
result = app.send_task('my_module.add', args=(4, 6))
print("Task result using send_task:", result.get())
特点:
灵活性:通过任务名称调用,适合于动态任务执行。
解耦友好:任务执行与具体代码实现解耦。
kwargs的注意事项
kwargs在传参的时候其实是**kwargs这种解构传入的
from celery import Celery
import json
app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
@app.task(rate_limit='2/m', name="send_message")
def my_task(age, name, extra):
# 任务逻辑
print("Task executed")
print(f"Age: {age}, Name: {name}, Extra: {extra}")
return f"返回的内容是{age}, 完整的{json.dumps({'age': age, 'name': name, 'extra': extra})}"
# 调用 send_task 时
ret = app.send_task(name="send_message", kwargs={"age": 19, "name": "alex", "extra": {"Dada": "@23"}})
try:
result = ret.get(timeout=10)
print("Result:", result)
except Exception as e:
print(f"An error occurred: {e}")
如果不想解构传入,想以一个dict形式传入的话就需要指定一个key值 代码示例如下
from celery import Celery
import json
app = Celery('tasks', broker='redis://localhost:6379/0', backend='redis://localhost:6379/0')
@app.task(rate_limit='2/m', name="send_message")
def my_task(data):
# 任务逻辑
print("Task executed")
age = data.get("age")
print(data)
return f"返回的内容是{age}, 完整的{json.dumps(data)}"
# 确保发送任务时构建符合需求的参数
ret = app.send_task(name="send_message", kwargs={"data": {"age": 19, "name": "alex", "extra": {"Dada": "@23"}}})
try:
result = ret.get(timeout=10)
print("Result:", result)
except Exception as e:
print(f"An error occurred: {e}")
单文件夹下使用
创建celery_test文件夹,pro写生产端,tasks写消费端,result用来获取请求结果
- 创建消费端代码 tasks.py
import celery
import time
#backend 是存储任务结果的后端。这是一个可选项,只有当你需要检查任务结果或利用结果链将任务的结果传递给其他任务时才需要。
backend = "redis://:密码@ip:port/14"
# broker 是用于传递任务的消息中间件。Celery 使用消息中间件将任务从生产者传递到工作者。
broker = "redis://:密码@ip:port/15"
# 'test' 是应用程序的名称。
cel = celery.Celery('test', backend=backend, broker=broker)
# 使用装饰器 加载任务
@cel.task()
def send_sms(name):
print("开始发送")
time.sleep(3)
return "发送成功%s" % name
在tasks.py的当前目录运行celery的worker
celery -A tasks worker -l info 5版本命令和之前略有不同
出现下面信息表示成功运行
- 创建生产端代码 Pro.py
运行后返回一个id值
from tasks import send_sms
ret = send_sms.delay("hahaha ")
print(ret)
- 创建异步获取结果 result.py
from celery.result import AsyncResult
from my_celery_app import app
asyncresult = AsyncResult(id=id, app=app)
if asyncresult.status == 'SUCCESS':
try:
result = asyncresult.get()
print("Task result is:", result)
except Exception as e:
print("Error while getting result:", str(e))
elif asyncresult.status == 'FAILURE':
error = asyncresult.result
print(f"Task failed with error: {error}")
traceback = asyncresult.traceback
print(f"Traceback: {traceback}")
elif asyncresult.status in ('PENDING', 'STARTED', 'RETRY'):
print(f"Task is currently in {asyncresult.status} status.")
elif asyncresult.status == 'REVOKED':
print("Task was revoked.")
- 异步任务结果的多种处理方式
asyncresult.get() # 获取结果
asyncresult.forget() #删除结果, 默认执行完成不会自动删除
asyncresult.revoke(terminate=True) # 无论任务什么状态,都要终止
asyncresult.revoke(terminate=False) # 如果任务还没开始执行,则终止
asyncresult.failed() #如果任务执行失败 返回true
还可以查看任务状态
asyncresult.status会输出任务状态
比如 ok PENDING,RETRY STARTED
多文件夹下使用
文件结构如下, mycelery用来保存celery实例的配置

- mycelery.py 注意此时需要用include关键字,指定异步的任务路径
import celery
backend='redis://:password@ip:port/14'
broker='redis://:password@ip:port/15'
cel=celery.Celery('test',backend=backend,broker=broker,include=[
'celery_tasks.task01',
'celery_tasks.task02'
])
# 时区
cel.conf.timezone = 'Asia/Shanghai'
# 是否使用UTC
cel.conf.enable_utc = False
- task01/02.py
写入任务函数,注意导包路径
from celery_tasks.mycelery import cel
import time
# 使用装饰器 加载任务
@cel.task()
def send_sms(name):
print("短信开始发送")
time.sleep(3)
return "短信发送成功%s" % name
- 启动worker,注意启动路径和参数里包含的相对路径
celery_tasks.mycelery
建议后续都从根路径启动workder,并用相对路径指定配置文件的位置,
这里是在celery_test2的根路径下启动的worker
young_shi@MacBook-Air-2 celery_test2 % ls
celery_tasks pro.py result.py
young_shi@MacBook-Air-2 celery_test2 % celery -A celery_tasks.mycelery worker -l info
- 生产端代码
from celery_tasks.task01 import send_sms
result = send_sms.delay("yuan")
print(result.id)
result2 = send_sms.delay("alex")
print(result2.id)
任务的终止
在使用 Celery 终止任务时,从代码的健壮性和正确性考虑,有几点需要注意。通过 AsyncResult 的状态去判断任务是否可以终止,然后决定是否调用 revoke 是一种可行的方法。但需要注意一些使用情境和潜在的风险。
终止任务的步骤
- 获取任务状态: 通过
AsyncResult获取任务的当前状态。 - 检查状态并决定:
- 如果状态是
PENDING或RECEIVED(任务还未被 worker 执行),则可以安全地调用revoke。 - 如果状态是
STARTED,表示任务已经在执行,直接调用revoke并设置terminate=True可能影响任务的安全终止。
- 如果状态是
潜在的风险
-
时效性与竞争条件:
- 状态可能很快变化,检查后到执行 revoke 之间若有状态变化,可能由于时效性错过终止时机。
-
任务的幂等性:
- 直接终止已经开始的任务,可能留下不完整的操作,尤其是没有实现幂等的任务逻辑。
-
信号安全:
- 使用信号终止任务(如
SIGTERM)时,要确保任务能处理终止信号并进行必要的清理。
- 使用信号终止任务(如
可执行的代码方案
from celery.result import AsyncResult
from celery.task.control import revoke
def cancel_task(app, task_id):
"""尝试取消指定任务ID的任务"""
result = AsyncResult(task_id, app=app)
task_status = result.status
# 检查任务的当前状态
if task_status == 'PENDING':
# 任务还未开始执行,安全撤销
print(f"Cancelling task {task_id} that is in PENDING state.")
revoke(task_id, terminate=False)
elif task_status == 'RECEIVED':
# 任务已经收到但未开始执行,撤销
print(f"Cancelling task {task_id} that is RECEIVED.")
revoke(task_id, terminate=False)
elif task_status == 'STARTED':
# 任务正在执行,尝试终止
print(f"Task {task_id} is STARTED, attempting to terminate.")
# 提醒:使用 terminate=True 和 ensure tasks are designed to safely terminate
revoke(task_id, terminate=True, signal='SIGTERM')
else:
print(f"Task {task_id} is in state {task_status} and cannot be cancelled at this time.")
return f"Action executed for task {task_id}; status was {task_status}."
# 使用示例
app = YourCeleryAppHere # This should be your actual Celery app instance
task_id = 'example-task-id'
cancel_task(app, task_id)
总结注意事项
-
事务与持久化:
- 确保任务终止后不会引发事务不一致问题,尤其是在操作数据库时。
-
重试与补偿逻辑:
- 在设计任务过程中,考虑是否需要附加重试机制或补偿来应对意外终止任务带来的影响。
-
资源释放:
- 使用
terminate=True时,实现任务中相应的资源释放和退出操作以保持系统稳定。
- 使用
通过这种方式,你为取消 Celery 任务实现了一个基本且健壮的逻辑框架,注意保护数据一致性和系统稳定性以减少不必要的副作用。
在 Celery 中,使用终止信号(signals)来取消任务可以控制进程或线程的终止行为。信号可以用来通知任务进程暂停或终止任务。在使用 revoke 方法时,你可以指定信号来尝试终止正在执行的任务。
常用信号参数
下面是一些常用的信号,它们在终止任务时有不同的效果:
-
SIGTERM(Signal Terminate):- 这是一个请求程序终止进程的信号。
- 是一种优雅的关闭信号,允许程序有机会进行清理操作和保存状态。
- 适合用在程序需要在关闭前释放资源或完成某些事务的场合。
- 大部分情况下,最好使用
SIGTERM来安全停止任务。
-
SIGKILL(Signal Kill):- 用于强制中止进程。
- 进程无法捕获或忽略此信号,所以不进行任何清理工作就会立即终止。
- 在某些情况下可用于快速终止进程,但极不安全,因为它可能导致数据损坏或资源泄露。
-
SIGINT(Signal Interrupt):- 表示中断进程(通常是来自 Ctrl+C)。
- 如果你希望模拟手动终止任务的行为,这个信号也可以是一个选择。
-
SIGQUIT(Signal Quit):- 类似于
SIGTERM,但是生成进程转储(coredump)。 - 可用于调试崩溃和查看程序在终止时的状态。
- 类似于
-
SIGHUP(Signal Hang Up):- 常用于重新加载配置或重启服务。
- 在某些情况下可用作通知任务需要重新激活而非终止。
使用信号终止任务的不同效果
-
使用
SIGTERM时,确保任务代码能够捕获此信号并执行合适的 clean up 动作。使用此信号通常较为安全,因为它给任务一个清理状态的机会。 -
使用
SIGKILL时,强制中止,不考虑清理。故应在无其他处理手段或紧急情况下采用,使用后可能导致不可用数据或系统资源无法被正确释放。 -
SIGINT和SIGQUIT则更多适用于开发过程中的调试用途,尤其是中断和捕获程序状态以供检查的场合。
值得注意的是,使用不同信号可能还需考虑操作系统的具体实现和任务进程的行为处理。保证在任务代码实现中处理信号的逻辑,以提供资源清理、数据安全或执行日志记录等操作,确保任务取消的安全性和系统的稳定性。
celery执行定时任务
celey的delay方法可以异步执行,而定时任务要用到apply_async方法
异步任务名.apply_async((arg,), {'kwarg': value}, countdown=60, expires=120)
- 简单结构下的定时任务 在pro文件给apply_async添加延时
from celery_task import send_email
from datetime import datetime
# 方式一
# v1 = datetime(2020, 3, 11, 16, 19, 00)
# print(v1)
# v2 = datetime.utcfromtimestamp(v1.timestamp())
# print(v2)
# result = send_email.apply_async(args=["egon",], eta=v2)
# print(result.id)
# 方式二
ctime = datetime.now()
# 默认用utc时间
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp())
from datetime import timedelta
time_delay = timedelta(seconds=10)
task_time = utc_ctime + time_delay
# 使用apply_async并设定时间
result = send_email.apply_async(args=["egon"], eta=task_time)
print(result.id)
- 多任务结构中
代码结构和上面一样.这里展示2中定时任务写法
生产模型延时执行
mycelery的代码不变,pro.py代码如下, delay方法改成apply_async方法,并加上延时的datetime对象
- pro.py代码修改如下
from datetime import datetime
from celery_tasks.task01 import send_sms
# 方式一
# v1 = datetime(2020, 3, 11, 16, 19, 00)
# print(v1)
# v2 = datetime.utcfromtimestamp(v1.timestamp())
# print(v2)
# result = send_sms.apply_async(args=["egon",], eta=v2)
# print(result.id)
# 方式二
ctime = datetime.now()
# 默认用utc时间
utc_ctime = datetime.utcfromtimestamp(ctime.timestamp())
from datetime import timedelta
time_delay = timedelta(seconds=10)
task_time = utc_ctime + time_delay
# 使用apply_async并设定时间
result = send_sms.apply_async(args=["egon"], eta=task_time)
print(result.id)
配置文件中添加定时执行
这种模式和生产消费模型关系不大,在mycelery.py添加beat_schedule配置
from datetime import timedelta
import celery
from celery.schedules import crontab
backend='redis://:密码@ip:port/14'
broker='redis://:密码@ip:port/15'
cel=celery.Celery('test',backend=backend,broker=broker,include=[
'celery_tasks.task01',
'celery_tasks.task02'
])
# 时区
cel.conf.timezone = 'Asia/Shanghai'
cel.conf.enable_utc = False
# 新增了下面部分
cel.conf.beat_schedule = {
# 名字随意命名
'add-every-10-seconds': {
# 执行tasks1下的test_celery函数
'task': 'celery_tasks.task01.send_sms',
# 每隔2秒执行一次
# 'schedule': 1.0,
# 'schedule': crontab(minute="*/1"),
'schedule': timedelta(seconds=6),
# 传递参数
'args': ('张三',),
#'kwargs': {'data': {'key1': 'value1', 'key2': 'value2'}}, # 传递字典参数
},
# 'add-every-12-seconds': {
# 'task': 'celery_tasks.task01.send_email',
# 每年4月11号,8点42分执行
# 'schedule': crontab(minute=42, hour=8, day_of_month=11, month_of_year=4),
# 'args': ('张三',)
# 'kwargs': {'data': {'key1': 'value1', 'key2': 'value2'}}, # 传递字典参数
# },
}
用celery -A celery_tasks.mycelery worker -l info开启worker进行监听
用celery -A celery_tasks.mycelery worker -B -l info 这里-B参数会读取beat_schedule里的配置参数,定时执行.
虽然在早期版本的 Celery 中可以使用 -B 参数 celery -A MyCelery.main worker -B -l info来同时启动 Worker 和 Beat,但是在 5.4.0 及以后的版本中建议各自运行,以提升应用的可靠性和管理性。
这里beat命令用的5.0版本,和4.0版本有点不一样 4.0命令格式 celery beat -A proj -l info 5.0命令格式 celery -A proj beat -l info,然后开启worker celery -A celery_tasks.mycelery worker -l info
Celery Beat进程会读取配置文件的内容,周期性的将配置中到期需要执行的任务发送给任务队列
celery的常见方法和属性总结
# 调用celery执行异步任务
from mycelery.sms.tasks import send_sms1,send_sms2,send_sms3,send_sms4
mobile = "13312345656"
code = "666666"
# delay 表示马上按顺序来执行异步任务,在celrey的worker工作进程有空闲的就立刻执行
# 可以通过delay异步调用任务,可以没有参数
ret1 = send_sms1.delay()
# 可以通过delay传递异步任务的参数,可以按位置传递参数,也可以使用命名参数
# ret2 = send_sms.delay(mobile=mobile,code=code)
ret2 = send_sms2.delay(mobile,code)
# apply_async 让任务在后面指定时间后执行,时间单位:秒/s
# 任务名.apply_async(args=(参数1,参数2), countdown=定时时间)
ret4 = send_sms4.apply_async(kwargs={"x":10,"y":20},countdown=30)
# 根据返回结果,不管delay,还是apply_async的返回结果都一样的。
ret4.id # 返回一个UUID格式的任务唯一标志符,78fb827e-66f0-40fb-a81e-5faa4dbb3505
ret4.status # 查看当前任务的状态 SUCCESS表示成功! PENDING任务等待
ret4.get() # 获取任务执行的结果[如果任务函数中没有return,则没有结果,如果结果没有出现则会导致阻塞] 重要!!!
if ret4.status == "SUCCESS":
print(ret4.get())
celery的任务组合
Celery 任务组合
- Chain(链式调用)
chain 用于顺序地执行一系列任务,每个任务都将前一个任务的结果作为输入传递给下一个任务。
示例:
from celery import Celery, chain
app = Celery('tasks', broker='pyamqp://guest@localhost//')
@app.task(name="no1")
def task_a(x):
return x + 1
@app.task
def task_b(x):
return x * 2
@app.task
def task_c(x):
return x - 3
from celery import chain
from tasks import task_a, task_b, task_c
# 这个是示例不传参的情况下,通过链式调用挨个执行
result = chain(
task_a.s(10),
task_b.s(),
task_c.s()
)()
# 通过task名字执行,这里的tasks.task_a可以用"no1"代替
result = chain(
# 这里可以在s传参,下面2个task_b和task_c会通过s语法糖隐式的获取上一个函数的返回值
app.tasks['tasks.task_a'].s(10),
app.tasks['tasks.task_b'].s(),
app.tasks['tasks.task_c'].s(3)
)()
# 最后这个result也可以用apply_async,等方式运行
比如result.apply_async()
解释:
- task_a 接受一个参数 x,返回 x + 1。
- 任务按顺序执行,结果依次被传递到下一个任务。
- 最终 task_c 在 task_b 的结果基础上减去 3。
- Group(并行执行)
group 用来并行执行一组任务,所有任务的执行是独立的。
示例:
from celery import group
@app.task
def task(x):
return x * 2
# Group usage
group_result = group(task.s(i) for i in range(5))()
print("Group Results:", group_result.get()) # Outputs [0, 2, 4, 6, 8]
解释:
各个任务并行执行,互不干扰。
所有任务的结果是列表形式返回。
group 中的所有任务都是并行执行的,但最终结果会在所有任务都完成后一起返回。
在调用 get() 方法之前,所有任务需要已经完成,否则 get() 会阻塞一直到所有结果可用为止。
下面的代码示例 解释了如何先获取task1的结果,然后传参给task2 task3并行执行
tasks.py代码
from celery import Celery, Task, shared_task
import pymysql # 如果使用 pymysql
pymysql.install_as_MySQLdb()
# db+scheme://user:password@host:port/dbname'
# 配置 Celery
result_backend = 'db+mysql://用户名:密码@localhost:3306/celery'
# broker_url = 'memory://' # 使用内存 broker
broker_url = 'redis://:@127.0.0.1:6379/0'
app = Celery('celery_demo', backend=result_backend, broker=broker_url)
app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json'], # 只接受JSON格式
)
class abc():
def __init__(self, age, gender):
self.age = age
self.gender = gender
def to_dict(self):
return {'age': self.age, 'gender': self.gender}
@app.task
def task_1():
rnd_num = random.randint(1, 100)
ac = abc(rnd_num, "南")
return rnd_num, ac.to_dict()
@app.task
def task_2(rnd_num, x, extra_param):
print("from task_2 rnd_num", rnd_num, "x", x, "extra_param", extra_param)
print("from task_2 ", "age和gender", x)
return 3
@app.task
def task_3(rnd_num, x, extra_param):
print("from task_3 rnd_num", rnd_num, "x", x, "extra_param", extra_param)
print("from task_3 ", "age和gender", x)
return 3
pro.py代码
result_1 = task_1.apply_async().get()
print("result_1",result_1)
result_2_and_3 = group(
task_2.s(*result_1,"tesk2wahwahwa"),
task_3.s(*result_1,"tesk3wahwahwa")
)().get()
print("result_2_and_3",result_2_and_3)
# 输出结果如下图

- Chord(和弦)
chord 是一种特殊的 group,它在所有组任务执行完毕后执行一个回调任务。
from celery import chord
@app.task
def callback(results):
return sum(results)
# Chord usage
chord_result = chord((task.s(i) for i in range(5)), callback.s())()
print("Chord Result:", chord_result.get()) # Outputs 20
解释:
task 任务并行执行,callback 任务在所有任务完成后执行,并接收组内任务的结果。
callback 汇总了所有任务的结果。
总结
chain:顺序执行任务,前一个任务的输出作为后一个任务的输入。
group:并行执行任务,互不依赖,返回所有任务的结果列表。
chord:在 group 的基础上增加一个回调任务,等所有并行任务完成后调用。
项目中使用celery
celery作为一个单独项目运行
app01
mycelery/ 1.新建一个package
├── config.py 2. 添加配置文件用`config_from_object`加载
├── __init__.py
├── main.py 5. 这里生成celery实例对象,加载celery的配置和任务
└── sms/ 3. 对异步功能单独创建一个package, 但是必须要有tasks.py文件,文件名不能取别的
├── __init__.py
├── tasks.py 4. 文件名必须叫tasks,用来编写异步执行的函数
└── email/
├── __init__.py
├── tasks.py
config代码
# CELERY_ENABLE_UTC = False 这两个参数可能celery 5.0格式不对
# CELERY_TIMEZONE = "Asia/Shanghai"
broker_url = "redis://:密码@ip:port/14"
result_backend = 'redis://:密码@ip:port/15'
sms下的tasks
from mycelery.main import app
# from mycelerys.main import app
import time
@app.task # name表示设置任务的名称,如果不填写,则默认使用函数名做为任务名
def send_sms(mobile):
"""发送短信"""
print("向手机号%s发送短信成功!"%mobile)
time.sleep(5)
return "send_sms OK"
main代码
# 主程序
import os
from celery import Celery
# 创建celery实例对象
app = Celery("sms")
# 把celery和django进行组合,识别和加载django的配置文件
# os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'celeryPros.settings.dev')
# 通过app对象加载配置
app.config_from_object("mycelery.config")
# 加载任务
# 参数必须必须是一个列表,里面的每一个任务都是任务的路径名称
# app.autodiscover_tasks(["任务1","任务2"])
app.autodiscover_tasks(["mycelery.sms",])
# 启动Celery的命令
# 强烈建议切换目录到mycelery根目录下启动
# celery -A mycelery.main worker --loglevel=info
django视图代码
from mycelery.sms.tasks import send_sms
def celery_test(request):
send_sms.delay("15867416745")
return HttpResponse("555")
Celery不建议在windows系统下使用,Celery在4.0版本以后不再支持windows系统,所以如果要在windows下使用只能安装4.0以前的版本,而且即便是4.0之前的版本,在windows系统下也是不能单独使用的,需要安装gevent、geventlet或eventlet协程模块
并且运行参数要加-P
celery -A celery_task worker -l info -P eventlet
celery调度其他模块
这里以调度django里项目里的应用举例
- 对django导包引入
在main.py主程序中对django进行导包引入,并设置django的配置文件进行django的初始化。
import os,django
from celery import Celery
# 初始化django 这2步django项目里初始化2步就是这么处理的 如果manage.py文件已经有加载,这个初始化步骤可以省略!!!
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffycityapi.settings.dev') #在manage.py文件中 和wsgi文件中
django.setup() #在wsgi文件中
# 初始化celery对象
app = Celery("luffycity")
# 加载配置
app.config_from_object("mycelery.config")
# 自动注册任务
app.autodiscover_tasks(["mycelery.sms","mycelery.email"])
# 运行celery
# 终端下: celery -A mycelery.main worker -l info
- 这里注意练习过程中发现的2个低级错误
- celery.py最好改个名字,容易和模块celery名字冲突
- 其他文件导包的模块必须从
luffycityapi/ # 服务端项目根目录开始导入,否则celery作为第三方模块加载时候 无法从根目录找到响应的路径
luffycityapi/ # 服务端项目根目录
└── luffycityapi/ # 主应用目录
├── apps/ # 子应用存储目录
├ └── Home/ # django的home子应用
├ └── users/ # django的users子应用
├ └── tasks.py # [新增]分散在各个子应用下的异步任务模块
├── settings/ # [修改]django的配置文件存储目录[celery的配置信息填写在django配置中即可]
├── __init__.py # [修改]设置当前包目录下允许外界调用celery应用实例对象
└── Mycelery.py # [新增]celery入口程序,相当于上一种用法的main.py,不要起名celery,会冲突!!!
- luffycityapi/Mycelery.py,主应用目录下创建cerley入口程序,创建celery对象并加载配置和异步任务,代码:
import os
from celery import Celery
# 必须在实例化celery应用对象之前执行
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'luffycityapi.settings.dev')
# 实例化celery应用对象
app = Celery('luffycityapi')
# 指定任务的队列名称
app.conf.task_default_queue = 'Celery'
# 也可以把配置写在django的项目配置中
app.config_from_object('django.conf:settings', namespace='CELERY') # 设置django中配置信息以 "CELERY_"开头为celery的配置信息
# 自动根据配置查找django的所有子应用下的tasks任务文件
app.autodiscover_tasks()
- settings 这里将celery的配置信息集中写到django的配置文件中了, settings/dev.py,代码:
# Celery异步任务队列框架的配置项[注意:django的配置项必须大写,所以这里的所有配置项必须全部大写]
# 任务队列
CELERY_BROKER_URL = 'redis://:123456@127.0.0.1:6379/14'
# 结果队列
CELERY_RESULT_BACKEND = 'redis://:123456@127.0.0.1:6379/15'
# 时区,与django的时区同步
CELERY_TIMEZONE = TIME_ZONE
# 防止死锁
CELERY_FORCE_EXECV = True
# 设置并发的worker数量
CELERYD_CONCURRENCY = 200
# 设置失败允许重试[这个慎用,如果失败任务无法再次执行成功,会产生指数级别的失败记录]
CELERY_ACKS_LATE = True
# 每个worker工作进程最多执行500个任务被销毁,可以防止内存泄漏,500是举例,根据自己的服务器的性能可以调整数值
CELERYD_MAX_TASKS_PER_CHILD = 500
# 单个任务的最大运行时间,超时会被杀死[慎用,有大文件操作、长时间上传、下载任务时,需要关闭这个选项,或者设置更长时间]
CELERYD_TIME_LIMIT = 10 * 60
# 任务发出后,经过一段时间还未收到acknowledge, 就将任务重新交给其他worker执行
CELERY_DISABLE_RATE_LIMITS = True
# celery的任务结果内容格式
CELERY_ACCEPT_CONTENT = ['json', 'pickle']
# Celery结果过期时间设为1小时
from datetime import timedelta
CELERY_RESULT_EXPIRES = timedelta(hours=1)
# 之前定时任务(定时一次调用),使用了apply_async({}, countdown=30);
# 设置定时任务(定时多次调用)的调用列表,需要单独运行SCHEDULE命令才能让celery执行定时任务:celery -A mycelery.main beat,当然worker还是要启动的
# https://docs.celeryproject.org/en/stable/userguide/periodic-tasks.html
from celery.schedules import crontab
CELERY_BEAT_SCHEDULE = {
"user-add": { # 定时任务的注册标记符[必须唯一的]
"task": "add", # 定时任务的任务名称
"schedule": 10, # 定时任务的调用时间,10表示每隔10秒调用一次add任务
# "schedule": crontab(hour=7, minute=30, day_of_week=1),, # 定时任务的调用时间,每周一早上7点30分调用一次add任务
}
}
- 如果后端存储使用了mysql可能存在报错信息
No module named 'MySQLdb'
可以在Mycelery.py文件这层的__init__.py文件中填入下面代码


原理如下:
需要确保在项目启动时配置 pymysql.install_as_MySQLdb()。一般来说,这种配置通常放在 Django 项目的 init.py 文件里,以确保在任何模块导入数据库连接之前已经正确配置好 pymysql。
这个调用会让 pymysql 模块替代 MySQLdb,以便兼容使用了 MySQLdb 的老代码。
代码:
import pymysql
from .Mycelery import app as celery_app
pymysql.install_as_MySQLdb()
__all__ = ['celery_app']
- users/tasks.py,代码:
from celery import shared_task
from ronglianyunapi import send_sms as sms
# 记录日志:
import logging
logger = logging.getLogger("django")
@shared_task(name="send_sms")
def send_sms(tid, mobile, datas):
"""异步发送短信"""
try:
return sms(tid, mobile, datas)
except Exception as e:
logger.error(f"手机号:{mobile},发送短信失败错误: {e}")
@shared_task(name="send_sms1")
def send_sms1():
print("send_sms1执行了!!!")
- django中的用户发送短信,就可以改成异步发送短信了。
users/views,视图中调用异步发送短信的任务,代码:
from .tasks import send_sms
send_sms.delay(settings.RONGLIANYUN.get("reg_tid"),mobile, datas=(code, time // 60))
#完整代码
import random
from django_redis import get_redis_connection
from django.conf import settings
# from ronglianyunapi import send_sms
# from mycelery.sms.tasks import send_sms
from .tasks import send_sms
"""
/users/sms/(?P<mobile>1[3-9]\d{9})
"""
class SMSAPIView(APIView):
"""
SMS短信接口视图
"""
def get(self, request, mobile):
"""发送短信验证码"""
redis = get_redis_connection("sms_code")
# 判断手机短信是否处于发送冷却中[60秒只能发送一条]
interval = redis.ttl(f"interval_{mobile}") # 通过ttl方法可以获取保存在redis中的变量的剩余有效期
if interval != -2:
return Response({"errmsg": f"短信发送过于频繁,请{interval}秒后再次点击获取!", "interval": interval},status=status.HTTP_400_BAD_REQUEST)
# 基于随机数生成短信验证码
# code = "%06d" % random.randint(0, 999999)
code = f"{random.randint(0, 999999):06d}"
# 获取短信有效期的时间
time = settings.RONGLIANYUN.get("sms_expire")
# 短信发送间隔时间
sms_interval = settings.RONGLIANYUN["sms_interval"]
# 调用第三方sdk发送短信
# send_sms(settings.RONGLIANYUN.get("reg_tid"), mobile, datas=(code, time // 60))
# 异步发送短信
send_sms.delay(settings.RONGLIANYUN.get("reg_tid"), mobile, datas=(code, time // 60))
# 记录code到redis中,并以time作为有效期
# 使用redis提供的管道对象pipeline来优化redis的写入操作[添加/修改/删除]
pipe = redis.pipeline()
pipe.multi() # 开启事务
pipe.setex(f"sms_{mobile}", time, code)
pipe.setex(f"interval_{mobile}", sms_interval, "_")
pipe.execute() # 提交事务,同时把暂存在pipeline的数据一次性提交给redis
return Response({"errmsg": "OK"}, status=status.HTTP_200_OK)
- 终端下先启动celery,在django项目根目录下启动。
cd ~/Desktop/luffycity/luffycityapi
# 1. 普通运行模式,关闭终端以后,celery就会停止运行
celery -A luffycityapi worker -l INFO
# 2. 启动多worker进程模式,以守护进程的方式运行,不需要在意终端。但是这种运行模型,一旦停止,需要手动启动。
celery multi start worker -A luffycityapi -E --pidfile="/home/moluo/Desktop/luffycity/luffycityapi/logs/worker1.pid" --logfile="/home/moluo/Desktop/luffycity/luffycityapi/logs/celery.log" -l info -n worker1
# 3. 启动多worker进程模式
celery multi stop worker -A luffycityapi --pidfile="/home/moluo/Desktop/luffycity/luffycityapi/logs/worker1.pid"
- 还是可以在django终端下调用celery的
$ python manage.py shell
>>> from users.tasks import send_sms1
>>> res = send_sms1.delay()
>>> res = send_sms1.apply_async(countdown=15)
>>> res.id
'893c31ab-e32f-44ee-a321-8b07e9483063'
>>> res.state
'SUCCESS'
>>> res.result
celery work的参数
Usage: celery worker [OPTIONS]
Start worker instance.
Examples
--------
$ celery --app=proj worker -l INFO
$ celery -A proj worker -l INFO -Q hipri,lopri
$ celery -A proj worker --concurrency=4
$ celery -A proj worker --concurrency=1000 -P eventlet
$ celery worker --autoscale=10,0
Worker Options:
-n, --hostname HOSTNAME 用于在多个 worker 进程中区分。如果不指定该参数,则会自动生成一个唯一的名称。
-D, --detach Start worker as a background process.
-S, --statedb PATH Path to the state database. The extension
'.db' may be appended to the filename.
-l, --loglevel [DEBUG|INFO|WARNING|ERROR|CRITICAL|FATAL] 日志级别
Logging level.
-O, --optimization [default|fair]
Apply optimization profile.
--prefetch-multiplier <prefetch multiplier>
Set custom prefetch multiplier value for
this worker instance.
Pool Options:
-c, --concurrency <concurrency> 并发数,即同时处理的任务数。默认为服务器 CPU 核数的 2 倍。
-P, --pool [prefork|eventlet|gevent|solo|processes|threads|custom]
数用于指定 celery worker 进程池的类型,即使用哪种方式来管理 worker 进程。该参数接受一个字符串值,可选值包括:
prefork:使用 prefork 进程池,即每个 worker 进程在启动时就会预先创建好,并在需要时直接使用。这种方式可以提高启动速度,但会占用较多的内存。
eventlet:使用 eventlet 协程池,即将每个 worker 进程变成一个协程,通过事件循环机制来实现并发处理。这种方式可以大幅降低内存占用,但可能会影响性能。
gevent:使用 gevent 协程池,与 eventlet 类似,但使用 gevent 库来实现协程,性能更高。
solo:不使用进程池,每个任务都在主进程中运行。这种方式适用于只有少量任务的场景,但不适合高并发场景。
-E, --task-events, --events Send task-related events that can be
captured by monitors like celery events,
celerymon, and others.
--time-limit FLOAT 单个任务的最大执行时间,超过该时间则会被 worker 强制终止。
--soft-time-limit FLOAT 单个任务的软时间限制,当任务超过该时间时,worker 会发出警告,但仍会让任务继续执行
--max-tasks-per-child INTEGER 每个 worker 进程最多处理多少个任务后重启,防止因为内存泄漏等问题导致的进程异常。
--max-memory-per-child INTEGER 参数用于限制每个 worker 进程最大占用的内存大小,一旦超过该限制,worker 进程会被强制重启,以避免内存泄漏等问题导致的进程崩溃。
该参数接受一个整数值,表示每个 worker 进程可以占用的最大内存大小,单位为 MB。
Queue Options:
--purge, --discard
-Q, --queues COMMA SEPARATED LIST
-X, --exclude-queues COMMA SEPARATED LIST
-I, --include COMMA SEPARATED LIST
Features:
--without-gossip
--without-mingle
--without-heartbeat
--heartbeat-interval INTEGER
--autoscale <MIN WORKERS>, <MAX WORKERS>
Embedded Beat Options:
-B, --beat
-s, --schedule-filename, --schedule TEXT
--scheduler TEXT
Daemonization Options:
-f, --logfile TEXT Log destination; defaults to stderr
--pidfile TEXT
--uid TEXT
--gid TEXT
--umask TEXT
--executable TEXT
不同云区部署和配置Celery
这个案例讲解了1,2,3不同云区的celery,通过把broker,backend集中设置在第一个云区,然后通过云区1对2 ,3 云区进行任务单独下发的部署和代码编写
以下是一个完整的 Markdown 文档,介绍如何通过某一个云区集中调度和任务下发,并汇总任务结果。
## Celery 多云区集中调度与任务下发指南
本文档介绍如何在一个 Django 项目中配置多个 Celery 实例,以支持在不同云区的任务调度与执行,并汇总任务结果。
### 项目结构
为了实现多云区的 Celery 集中调度与任务下发,项目结构可以设计如下:
```plaintext
Apps
├── MyCelery
│ ├── __init__.py
│ ├── celery_config.py
│ ├── main.py
│ ├── signals.py
│ ├── yundun
│ │ ├── __init__.py
│ │ ├── tasks.py
│ └── yundun_api
└── CloudEye
├── __init__.py
├── settings.py
├── urls.py
├── views.py
├── templates
│ └── send_task.html
└── wsgi.py
配置 Celery 实例
在 main.py 中配置不同云区的 Celery 应用实例,并确保可以使用 Django 的环境设置。
main.py
import os
from celery import Celery
from django.conf import settings
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'CloudEye.settings')
def create_celery_app(name, broker_url, result_backend):
celery_app = Celery(name)
celery_app.conf.update(
broker_url=broker_url,
result_backend=result_backend,
task_default_queue='Celery',
)
celery_app.config_from_object('django.conf:settings', namespace='CELERY')
celery_app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
return celery_app
CLOUD1_BROKER = 'redis://1.1.1.1:6379/0'
CLOUD1_BACKEND = 'db+mysql://username:password@1.1.1.1/dbname'
CLOUD2_BROKER = 'redis://1.1.10.1:6379/0'
CLOUD2_BACKEND = 'db+mysql://username:password@1.1.10.1/dbname'
CLOUD3_BROKER = 'redis://1.1.20.1:6379/0'
CLOUD3_BACKEND = 'db+mysql://username:password@1.1.20.1/dbname'
app_cloud1 = create_celery_app('cloud1', CLOUD1_BROKER, CLOUD1_BACKEND)
app_cloud2 = create_celery_app('cloud2', CLOUD2_BROKER, CLOUD2_BACKEND)
app_cloud3 = create_celery_app('cloud3', CLOUD3_BROKER, CLOUD3_BACKEND)
app_dict = {
'cloud1': app_cloud1,
'cloud2': app_cloud2,
'cloud3': app_cloud3,
}
定义任务
在 MyCelery/yundun/tasks.py 中定义任务,确保任务在相应的云区 Celery 实例上执行。
tasks.py
from main import app_cloud1, app_cloud2, app_cloud3
@app_cloud1.task
def scanner():
return "云区1的巡检任务完成"
@app_cloud2.task
def scanner():
return "云区2的巡检任务完成"
@app_cloud3.task
def scanner():
return "云区3的巡检任务完成"
创建视图
在 CloudEye/views.py 中创建视图来处理前端请求,并根据用户选择下发任务。
views.py
from django.shortcuts import render
from django.http import JsonResponse
from main import app_dict
def send_task_view(request):
if request.method == 'POST':
cloud_zone = request.POST.get('cloud_zone')
app = app_dict.get(cloud_zone)
if app is None:
return JsonResponse({'error': 'Invalid cloud zone selected.'}, status=400)
result = app.send_task('yundun.tasks.scanner')
task_result = result.get()
return JsonResponse({'message': f'{cloud_zone}的scanner任务结果: {task_result}'})
return render(request, 'send_task.html')
创建模板
在 templates/send_task.html 中创建一个简单的表单,以供用户选择云区并发送任务请求。
send_task.html
<!DOCTYPE html>
<html>
<head>
<title>选择云区并发送任务</title>
</head>
<body>
<h1>选择云区并发送任务</h1>
<form method="POST" action="{% url 'send_task' %}">
{% csrf_token %}
<label for="cloud_zone">选择云区:</label>
<select name="cloud_zone" id="cloud_zone">
<option value="cloud1">云区1</option>
<option value="cloud2">云区2</option>
<option value="cloud3">云区3</option>
</select>
<button type="submit">发送任务</button>
</form>
</body>
</html>
配置 URL
在 CloudEye/urls.py 中配置视图的 URL 路由。
urls.py
from django.urls import path
from . import views
urlpatterns = [
path('send_task/', views.send_task_view, name='send_task')
]
运行 Celery Worker
在每个云区启动 Celery Worker,以确保任务能够正确执行。
启动命令
# 云区 1
celery -A main.app_cloud1 worker --loglevel=info
# 云区 2
celery -A main.app_cloud2 worker --loglevel=info
# 云区 3
celery -A main.app_cloud3 worker --loglevel=info
启动 Django 项目
确保 Django 项目正在运行,并访问 http://yourserver/send_task/,选择目标云区并发送任务请求。
通过上述配置,可以在 Django 项目中实现多云区的集中调度和任务下发,以及任务结果汇总。通过浏览器前端界面,可以动态选择目标云区进行任务操作。
此文档详细列出了配置步骤、代码示例以及各个部分的目的和功能,以帮助用户实现 Celery 的跨云区集中调度。
Celery 签名
使用 Signature 对象在 Celery 中确实带来了很多便利,包括自动参数传递、任务管理、错误处理等。Signature 对象不仅仅是为了方便获取前一个任务的返回值,实际上它提供了一系列强大的功能来简化和增强任务管理。以下是一些主要功能和用途:
使用 Celery Signature 对象的功能和用途
在 Celery 中,Signature 对象为复杂任务流管理提供了强有力的支持。下面列出了 Signature 对象的主要功能和用途,以及相关的代码示例,包括使用 Signature 类和 .s() 语法糖两种写法。
1. 自动参数传递
Signature 对象在链式任务(如 chain)中自动处理任务间的结果传递。
使用 .s() 语法糖
result = chain(
app.tasks['first_task'].s(arg1, arg2),
app.tasks['second_task'].s()
).apply_async()
使用 Signature 类
from celery import Signature
result = chain(
Signature('first_task', args=(arg1, arg2)),
Signature('second_task')
).apply_async()
2. 任务链(Chains)
通过 Signature 对象轻松构建任务链,确保任务按顺序执行。
使用 .s() 语法糖
from celery import chain
chain_result = chain(
app.tasks['task_a'].s(arg1),
app.tasks['task_b'].s(),
app.tasks['task_c'].s()
).apply_async()
使用 Signature 类
from celery import Signature
chain_result = chain(
Signature('task_a', args=(arg1,)),
Signature('task_b'),
Signature('task_c')
).apply_async()
3. 任务组(Groups)
Signature 对象允许任务以并行方式执行,并结合这些任务的结果。
使用 .s() 语法糖
from celery import group
group_result = group(
app.tasks['task_a'].s(arg1),
app.tasks['task_b'].s(arg2),
app.tasks['task_c'].s(arg3)
).apply_async()
使用 Signature 类
from celery import Signature, group
group_result = group(
Signature('task_a', args=(arg1,)),
Signature('task_b', args=(arg2,)),
Signature('task_c', args=(arg3,))
).apply_async()
4. 和弦(Chords)
Signature 对象可以用来创建和弦,执行一组任务后进行回调。
使用 .s() 语法糖
from celery import chord
chord_result = chord(
group(
app.tasks['task_a'].s(arg1),
app.tasks['task_b'].s(arg2),
app.tasks['task_c'].s(arg3)
)
)(app.tasks['final_task'].s())
使用 Signature 类
from celery import Signature, chord, group
chord_result = chord(
group(
Signature('task_a', args=(arg1,)),
Signature('task_b', args=(arg2,)),
Signature('task_c', args=(arg3,))
)
)(Signature('final_task'))
5. 灵活性和可组合性
灵活组合任务签名,动态配置任务执行。
使用 .s() 语法糖
sig = app.tasks['some_task'].s()
sig_with_data = sig.clone(args=(new_arg,))
使用 Signature 类
sig = Signature('some_task')
sig_with_data = sig.clone(args=(new_arg,))
6. 回调和错误处理
通过 Signature 对象设置回调和错误处理函数。
使用 .s() 语法糖
sig = app.tasks['some_task'].s(arg1, arg2).on_error(app.tasks['error_handler'].s())
sig.apply_async()
使用 Signature 类
sig = Signature('some_task', args=(arg1, arg2)).on_error(Signature('error_handler'))
sig.apply_async()
7. 序列化和反序列化
Signature 对象支持序列化和反序列化,适用于分布式任务队列。
使用 .s() 语法糖
sig = app.tasks['some_task'].s(arg1, arg2)
serialized_sig = sig.dumps()
deserialized_sig = Signature(serialized_sig)
deserialized_sig.apply_async()
使用 Signature 类
sig = Signature('some_task', args=(arg1, arg2))
serialized_sig = sig.dumps()
deserialized_sig = Signature(serialized_sig)
deserialized_sig.apply_async()
结论
Celery 中的 Signature 对象通过支持自动参数传递、任务链、任务组、和弦、灵活配置、回调和错误处理等功能,极大地方便了复杂任务流管理。通过 Signature 对象,使得不仅处理任务流更为便利,还提高了系统的可维护性和效率。
Celery 信号
Celery 提供了多种信号(Signals),允许开发者在任务的不同生命周期阶段插入自定义逻辑。这些信号可以帮助我们监控任务的执行情况、处理异常、记录日志等。
本文将详细介绍 Celery 中的信号及其使用方法,并通过代码示例展示信号中传输的参数。同时,我们还会介绍信号的方法(如 connect、disconnect 等)及其应用场景。
1. Celery 信号概述
Celery 信号是基于 Blinker 库实现的,Blinker 是一个简单的信号库,允许对象订阅和发送信号。Celery 提供了多种信号,涵盖了任务的生命周期各个阶段。
1.1 常用信号列表
以下是一些常用的 Celery 信号:
task_prerun: 任务执行前触发。task_postrun: 任务执行后触发。task_success: 任务成功完成后触发。task_failure: 任务失败后触发。task_retry: 任务重试时触发。task_revoked: 任务被取消时触发。task_unknown: 接收到未知任务时触发。task_rejected: 任务被拒绝时触发。before_task_publish: 任务发布前触发。after_task_publish: 任务发布后触发。
2. 信号的使用方法
要使用 Celery 信号,首先需要导入 celery.signals 模块,然后通过装饰器或直接连接信号处理器。
2.1 使用装饰器连接信号处理器
from celery import Celery
from celery.signals import task_prerun, task_postrun, task_success, task_failure
app = Celery('myapp', broker='pyamqp://guest@localhost//')
@task_prerun.connect
def task_prerun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, **extras):
print(f"Task {task_id} is about to run with args: {args}, kwargs: {kwargs}")
@task_postrun.connect
def task_postrun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, retval=None, state=None, **extras):
print(f"Task {task_id} has finished with state: {state} and return value: {retval}")
@task_success.connect
def task_success_handler(sender=None, result=None, **extras):
print(f"Task {sender.name} succeeded with result: {result}")
@task_failure.connect
def task_failure_handler(sender=None, task_id=None, exception=None, args=None, kwargs=None, traceback=None, einfo=None, **extras):
print(f"Task {task_id} failed with exception: {exception}")
2.2 直接连接信号处理器
from celery import Celery
from celery.signals import task_prerun, task_postrun
app = Celery('myapp', broker='pyamqp://guest@localhost//')
def task_prerun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, **extras):
print(f"Task {task_id} is about to run with args: {args}, kwargs: {kwargs}")
def task_postrun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, retval=None, state=None, **extras):
print(f"Task {task_id} has finished with state: {state} and return value: {retval}")
task_prerun.connect(task_prerun_handler)
task_postrun.connect(task_postrun_handler)
3. 信号参数详解
每个信号在触发时都会传递一些参数,这些参数可以帮助我们了解任务的当前状态。以下是常见信号的参数及其含义。
3.1 task_prerun 信号
sender: 发送信号的任务对象。task_id: 任务的唯一标识符。task: 任务实例。args: 任务的位置参数。kwargs: 任务的关键字参数。**extras: 其他额外参数。
@task_prerun.connect
def task_prerun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, **extras):
print(f"Task {task_id} is about to run with args: {args}, kwargs: {kwargs}")
3.2 task_postrun 信号
sender: 发送信号的任务对象。task_id: 任务的唯一标识符。task: 任务实例。args: 任务的位置参数。kwargs: 任务的关键字参数。retval: 任务的返回值。state: 任务的最终状态。**extras: 其他额外参数。
@task_postrun.connect
def task_postrun_handler(sender=None, task_id=None, task=None, args=None, kwargs=None, retval=None, state=None, **extras):
print(f"Task {task_id} has finished with state: {state} and return value: {retval}")
3.3 task_success 信号
sender: 发送信号的任务对象。result: 任务的返回结果。**extras: 其他额外参数。
@task_success.connect
def task_success_handler(sender=None, result=None, **extras):
print(f"Task {sender.name} succeeded with result: {result}")
3.4 task_failure 信号
sender: 发送信号的任务对象。task_id: 任务的唯一标识符。exception: 任务抛出的异常。args: 任务的位置参数。kwargs: 任务的关键字参数。traceback: 异常的 traceback 信息。einfo: 异常的详细信息。**extras: 其他额外参数。
from celery import Celery
from celery.signals import task_failure
import traceback as tb
@task_failure.connect
def task_failure_handler(sender=None, task_id=None, exception=None, args=None, kwargs=None, traceback=None, einfo=None, **extras):
# 输出错误的堆栈信息
formatted_traceback = ''.join(tb.format_exception(einfo.type, einfo.exception, einfo.tb))
print(f'任务命名: {sender.name} 任务ID: {task_id} 失败: {exception} 堆栈信息: {formatted_traceback}')
3.5 task_retry 信号
sender: 发送信号的任务对象。request: 任务的重试请求。reason: 重试的原因。**extras: 其他额外参数。
@task_retry.connect
def task_retry_handler(sender=None, request=None, reason=None, **extras):
print(f"Task {sender.name} is retrying due to: {reason}")
3.6 task_revoked 信号
sender: 发送信号的任务对象。request: 任务的请求对象。terminated: 任务是否被终止。signum: 终止信号的编号。expired: 任务是否已过期。**extras: 其他额外参数。
@task_revoked.connect
def task_revoked_handler(sender=None, request=None, terminated=None, signum=None, expired=None, **extras):
print(f"Task {sender.name} has been revoked")
3.7 task_unknown 信号
sender: 发送信号的任务对象。name: 任务的名称。id: 任务的唯一标识符。message: 未知任务的消息。**extras: 其他额外参数。
@task_unknown.connect
def task_unknown_handler(sender=None, name=None, id=None, message=None, **extras):
print(f"Unknown task received: {name} with id: {id}")
3.8 task_rejected 信号
sender: 发送信号的任务对象。message: 被拒绝任务的消息。**extras: 其他额外参数。
@task_rejected.connect
def task_rejected_handler(sender=None, message=None, **extras):
print(f"Task {sender.name} was rejected: {message}")
3.9 before_task_publish 信号
sender: 发送信号的任务对象。body: 任务的消息体。exchange: 任务的消息交换器。routing_key: 任务的路由键。headers: 任务的头部信息。properties: 任务的消息属性。declare: 任务的声明列表。**extras: 其他额外参数。
@before_task_publish.connect
def before_task_publish_handler(sender=None, body=None, exchange=None, routing_key=None, headers=None, properties=None, declare=None, **extras):
print(f"Task {sender} is about to be published with body: {body}")
3.10 after_task_publish 信号
sender: 发送信号的任务对象。body: 任务的消息体。exchange: 任务的消息交换器。routing_key: 任务的路由键。headers: 任务的头部信息。properties: 任务的消息属性。declare: 任务的声明列表。**extras: 其他额外参数。
@after_task_publish.connect
def after_task_publish_handler(sender=None, body=None, exchange=None, routing_key=None, headers=None, properties=None, declare=None, **extras):
print(f"Task {sender} has been published with body: {body}")
4. 信号的方法
Celery 信号提供了以下方法,用于管理信号处理器:
4.1 connect 方法
connect 方法用于将信号处理器连接到信号。当信号触发时,连接的处理器会被调用。
应用场景:
- 在任务执行前或执行后添加日志记录。
- 在任务失败时发送通知。
- 在任务发布前修改任务参数。
from celery.signals import task_prerun
def task_prerun_handler(sender=None, task_id=None, **kwargs):
print(f"Task {task_id} is about to run")
# 连接信号处理器
task_prerun.connect(task_prerun_handler)
4.2 disconnect 方法
disconnect 方法用于断开信号处理器与信号的连接。
应用场景:
- 动态移除不再需要的信号处理器。
- 在测试环境中临时禁用某些信号处理器。
from celery.signals import task_prerun
def task_prerun_handler(sender=None, task_id=None, **kwargs):
print(f"Task {task_id} is about to run")
# 连接信号处理器
task_prerun.connect(task_prerun_handler)
# 断开信号处理器
task_prerun.disconnect(task_prerun_handler)
4.3 send 方法
send 方法用于手动触发信号。通常用于测试或自定义信号。
应用场景:
- 在单元测试中模拟信号触发。
- 自定义信号并手动触发。
from celery.signals import task_prerun
def task_prerun_handler(sender=None, task_id=None, **kwargs):
print(f"Task {task_id} is about to run")
# 连接信号处理器
task_prerun.connect(task_prerun_handler)
# 手动触发信号
task_prerun.send(sender="my_task", task_id="12345")
4.4 has_listeners 方法
has_listeners 方法用于检查信号是否有连接的处理器。
应用场景:
- 在触发信号前检查是否有处理器。
- 动态决定是否触发信号。
from celery.signals import task_prerun
def task_prerun_handler(sender=None, task_id=None, **kwargs):
print(f"Task {task_id} is about to run")
# 检查是否有处理器
if task_prerun.has_listeners():
print("Signal has listeners")
else:
print("Signal has no listeners")
5. 信号全局和局部使用
信号导入默认是全局导入,也可以实现局部导入,
Blogapp
├── Apps
│ └── RBAC
│ ├── __init__.py
│ ├── admin.py
│ ├── apps.py
│ ├── models.py
│ ├── tests.py
│ ├── urls.py
│ └── views.py
├── Blogapp
│ ├── __init__.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ └── wsgi.py
├── MyCelery
│ ├── __init__.py
│ ├── celery_config.py celery的broker和backend配置
│ ├── main.py celery的app设置
│ ├── signals.py celery的信号
│ ├── yundun
│ │ ├── __init__.py
│ │ └── tasks.py
│ └── yundun_api
│ ├── __init__.py
│ ├── api_config.py
│ └── api_demo.py
├── manage.py
└── requirement.txt
5.1 全局导入
因为信号的导入是全局的,无论是在main.py导入 或者在每个任务下的tasks.py中导入,都是可以全局使用的.
我们模拟下 假设singnals.py代码如下
from celery.signals import task_failure
import logging
api_error_logger = logging.getLogger('yundun_api_error')
@task_failure.connect
def handle_task_failure(sender, task_id, exception, args, kwargs, traceback, **kwds):
api_error_logger.error(f'Task {sender.name} {task_id} failed: {exception}')
MyCelery/main.py代码如下
import os
from MyCelery import signals
from celery import Celery
from celery.schedules import crontab
# 必须在实例化celery应用对象之前执行
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'Blogapp.settings')
# 实例化celery应用对象
app = Celery('CloudEye')
# 指定任务的队列名称
app.conf.task_default_queue = 'Celery'
# 也可以把配置写在django的项目配置中
app.config_from_object('MyCelery.celery_config', namespace='CELERY') # 设置django中配置信息以 "CELERY_"开头为celery的配置信息
# 自动根据配置查找django的所有子应用下的tasks任务文件
app.autodiscover_tasks(['MyCelery.yundun',])
app.conf.beat_schedule = {
'add-every-10-seconds': {
'task': 'MyCelery.yundun.tasks.send_sms',
'schedule': 10,
'args': ("12345",)
'kwargs': {'data': {'key1': 'value1', 'key2': 'value2'}}, # 传递字典参数
},
}
5.2 局部导入
但是如果我想让信号根据不同的任务在同一个信号中做不同的事情的话也可以巧妙的用下面2种方法实现
- 信号中通过判断task.name进行判断
from celery import Celery, signals
from celery.signals import task_prerun, task_postrun, task_failure
import logging
app = Celery('example')
app.conf.broker_url = 'redis://localhost:6379/0'
logger = logging.getLogger('task_specific')
@signals.task_prerun.connect
def task_prerun_handler(sender, task_id, task, args, kwargs, **options):
if task.name == 'example.task_a':
logger.info(f"Task {task.name} is about to run.")
@signals.task_postrun.connect
def task_postrun_handler(sender, task_id, task, args, kwargs, retval, state, **options):
if task.name == 'example.task_a':
logger.info(f"Task {task.name} has been executed.")
@signals.task_failure.connect
def task_failure_handler(sender, task_id, args, kwargs, einfo, **options):
if sender.name == 'example.task_a':
logger.error(f"Task {sender.name} [{task_id}] failed.\nException: {einfo.exception}")
@app.task(name='example.task_a')
def task_a():
raise ValueError("This is an error in task_a")
@app.task(name='example.task_b')
def task_b():
raise ValueError("This is an error in task_b")
- 自定义任务类
通过自定义任务类,可以在任务的生命周期内(如初始化、执行前、执行后等)动态连接和断开信号,使信号处理函数在任务执行期间特定生效。可以将信号处理逻辑封装到特定任务类中,并让需要该行为的任务继承这个自定义任务类。
from celery import Celery, Task
import logging
app = Celery('example')
app.conf.broker_url = 'redis://localhost:6379/0'
logger = logging.getLogger('task_specific')
class TaskWithFailureHandler(Task):
def on_failure(self, exc, task_id, args, kwargs, einfo):
# 在任务失败时执行的代码
logger.error(f"Task {self.name} [{task_id}] failed.\nException: {exc}")
@app.task(base=TaskWithFailureHandler, name='example.task_custom_a')
def task_custom_a():
raise ValueError("This is an error in task_custom_a")
# 一个普通任务,不会使用自定义任务类的失败处理
@app.task(name='example.task_b')
def task_b():
raise ValueError("This is an error in task_b")
本文作者:死了也要PY
本文链接:https://www.cnblogs.com/Young-shi/p/17491868.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步