Python-网络编程和多进程多线程开发
网络编程
osi7层模型
以通过访问网站发送请求数据为例,每一层会做如下的事情
-
应用层:规定数据的格式。
"GET /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.com\r\n\r\n" -
表示层:对应用层数据的编码、压缩(解压缩)、分块、加密(解密)等任务。
"GET /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.com\r\n\r\n你好".encode('utf-8') -
会话层:负责与目标建立、中断连接。
在发送数据之前,需要会先发送 “连接” 的请求,与远程建立连接后,再发送数据。当然,发送完毕之后,也涉及中断连接的操作。 -
传输层:建立端口到端口的通信,其实就确定双方的端口信息。
数据:"GET /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.com\r\n\r\n你好".encode('utf-8') 端口: - 目标:80 - 本地:6784 -
网络层:标记目标IP信息(IP协议层)
数据:"GET /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.com\r\n\r\n你好".encode('utf-8') 端口: - 目标:80 - 本地:6784 IP: - 目标IP:110.242.68.3(百度) - 本地IP:192.168.10.1 -
数据链路层:对数据进行分组并设置源和目标mac地址
数据:"POST /s?wd=你好 HTTP/1.1\r\nHost:www.baidu.com\r\n\r\n你好".encode('utf-8') 端口: - 目标:80 - 本地:6784 IP: - 目标IP:110.242.68.3(百度) - 本地IP:192.168.10.1 MAC: - 目标MAC:FF-FF-FF-FF-FF-FF - 本机MAC:11-9d-d8-1a-dd-cd -
物理层:将二进制数据在物理媒体上传输。
通过网线将二进制数据发送出去
每一层各司其职,最终保证数据呈现在到用户手中。
简单的可以理解为发快递:将数据外面套了7个箱子,最终用户收到箱子时需要打开7个箱子才能拿到数据。而在运输的过程中有些箱子是会被拆开并替换的.
在开发过程中其实只能体现:应用层、表示层、会话层、传输层,其他层的处理都是在网络设备中自动完成的。
import socket
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.connect(('110.242.68.3', 80)) # 向服务端发送了数据包
key = "你好"
# 应用层
content = "GET /s?wd={} http1.1\r\nHost:www.baidu.com\r\n\r\n".format(key)
# 表示层
content = content.encode("utf-8")
client.sendall(content)
result = client.recv(8196)
print(result.decode('utf-8'))
# 会话层 & 传输层
client.close()
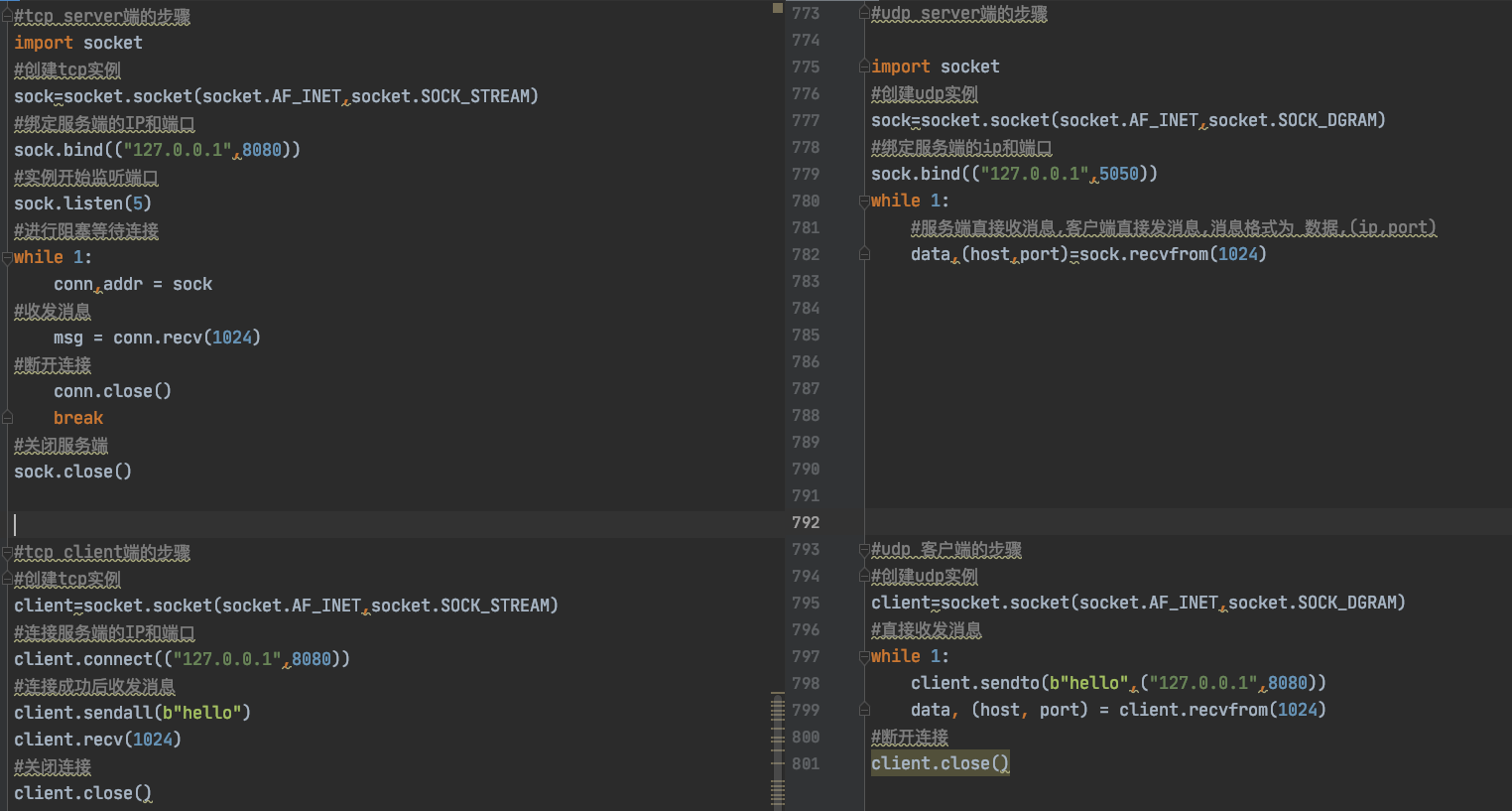
tcp和udp的代码区别
tcp的代码
#tcp server端的步骤
import socket
#创建tcp实例
sock=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#绑定服务端的IP和端口
sock.bind(("127.0.0.1",8080))
#实例开始监听端口
sock.listen(5)
#进行阻塞等待连接
while 1:
conn,addr = sock
#收发消息
msg = conn.recv(1024)
#断开连接
conn.close()
break
#关闭服务端
sock.close()
#tcp client端的步骤
#创建tcp实例
client=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#连接服务端的IP和端口
client.connect(("127.0.0.1",8080))
#连接成功后收发消息
client.sendall(b"hello")
client.recv(1024)
#关闭连接
client.close()
udp的代码
# ---------------------tcp和udp区别-----------------------
#udp server端的步骤
import socket
#创建udp实例
sock=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
#绑定服务端的ip和端口
sock.bind(("127.0.0.1",5050))
while 1:
#服务端直接收消息,客户端直接发消息,消息格式为 数据,(ip,port)
data,(host,port)=sock.recvfrom(1024)
#udp 客户端的步骤
#创建udp实例
client=socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
#直接收发消息
while 1:
client.sendto(b"hello",("127.0.0.1",8080))
data, (host, port) = client.recvfrom(1024)
#断开连接
client.close()
tcp和udp的区别
- 创建过程不同,tcp需要三次握手和4次挥手创建连接后收发消息,udp不用,直接发送
- tcp的socket模块使用send,sendall和recv收发消息,udp使用snedto和recvfrom收发消息
- tcp是创建连接后发消息,因此收发的只有消息.udp是直接像服务端收发消息,因此收发消息中要带上ip和port
两者代码的横向对比图如下:
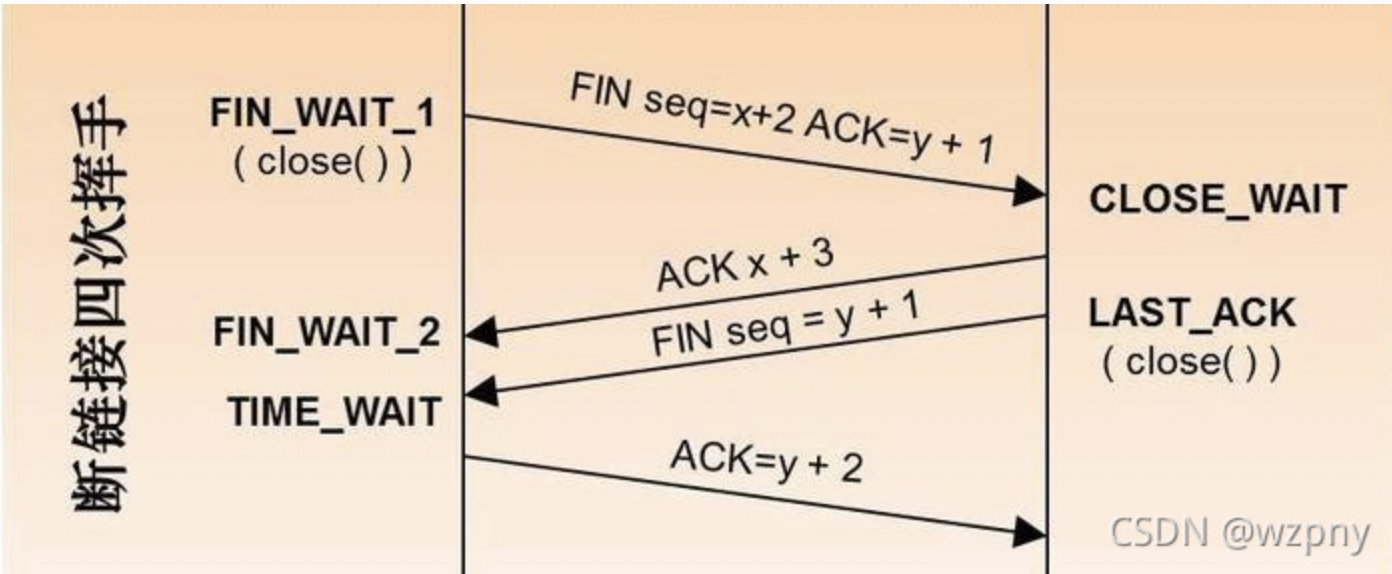
tcp的三次握手和四次挥手图解
三次握手
客户端 服务端
1. SYN-SENT --> <seq=100><CTL=SYN> --> SYN-RECEIVED
2. ESTABLISHED <-- <seq=300><ack=101><CTL=SYN,ACK> <-- SYN-RECEIVED
3. ESTABLISHED --> <seq=101><ack=301><CTL=ACK> --> ESTABLISHED

四次挥手
TCP A TCP B
1. FIN-WAIT-1 --> <seq=100><ack=300><CTL=FIN,ACK> --> CLOSE-WAIT
2. FIN-WAIT-2 <-- <seq=300><ack=101><CTL=ACK> <-- CLOSE-WAIT
3. TIME-WAIT <-- <seq=300><ack=101><CTL=FIN,ACK> <-- LAST-ACK
4. TIME-WAIT --> <seq=101><ack=301><CTL=ACK> --> CLOSED
TCP黏包现象
两台电脑在进行收发数据时,其实不是直接将数据传输给对方。
- 对于发送者,执行
sendall/send发送消息时,是将数据先发送至自己网卡的 写缓冲区 ,再由缓冲区将数据发送给到对方网卡的读缓冲区。 - 对于接受者,执行
recv接收消息时,是从自己网卡的读缓冲区获取数据。
所以,如果发送者连续快速的发送了2条信息,接收者在读取时会认为这是1条信息,即:2个数据包粘在了一起。例如:
# socket客户端(发送者)
import socket
client = socket.socket()
client.connect(('127.0.0.1', 8001))
client.sendall('alex正在吃'.encode('utf-8'))
client.sendall('翔'.encode('utf-8'))
client.close()
# socket服务端(接收者)
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8001))
sock.listen(5)
conn, addr = sock.accept()
client_data = conn.recv(1024)
print(client_data.decode('utf-8'))
conn.close()
sock.close()
如何解决粘包的问题
每次发送的消息时,都将消息划分为 头部(固定字节长度) 和 数据 两部分。例如:头部,用4个字节表示后面数据的长度。
- 发送数据,先发送数据的长度,再发送数据(或拼接起来再发送)。
- 接收数据,先读4个字节就可以知道自己这个数据包中的数据长度,再根据长度读取到数据。
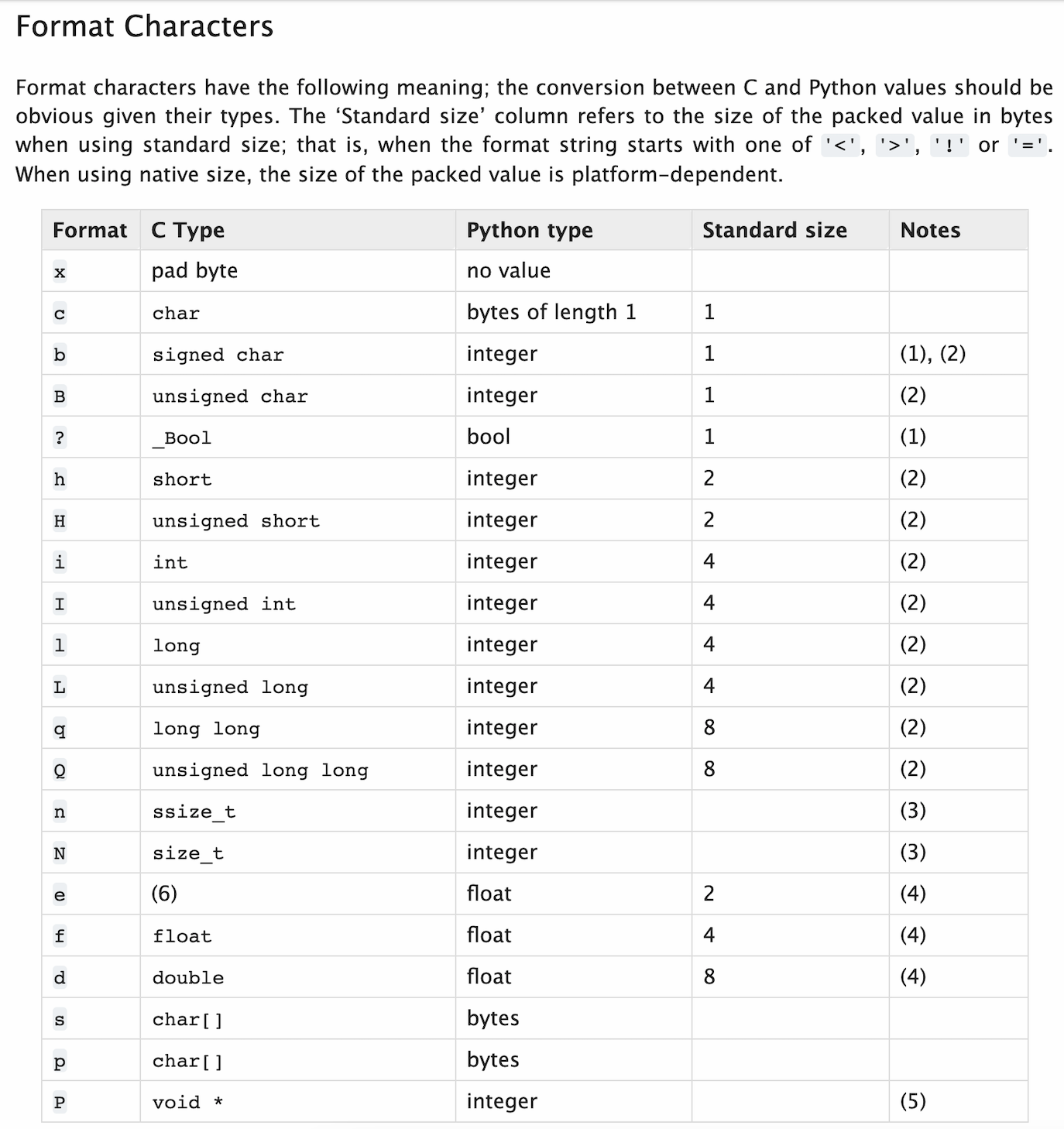
对于头部需要一个数字并固定为4个字节,这个功能可以借助python的struct包来实现:
import struct
# ########### 数值转换为固定4个字节,四个字节的范围 -2147483648 <= number <= 2147483647 ###########
v1 = struct.pack('i', 199)
print(v1) # b'\xc7\x00\x00\x00'
for item in v1:
print(item, bin(item))
# ########### 4个字节转换为数字 ###########
v2 = struct.unpack('i', v1) # v1= b'\xc7\x00\x00\x00'
print(v2) # (199,)
# -------------------服务端--------------------
import socket
import struct
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8001))
sock.listen(5)
conn, addr = sock.accept()
# 固定读取4字节
header1 = conn.recv(4)
data_length1 = struct.unpack('i', header1)[0] # 数据字节长度 21
has_recv_len = 0
data1 = b""
while True:
length = data_length1 - has_recv_len
if length > 1024:
lth = 1024
else:
lth = length
chunk = conn.recv(lth) # 可能一次收不完,自己可以计算长度再次使用recv收取,指导收完为止。 1024*8 = 8196
data1 += chunk
has_recv_len += len(chunk)
if has_recv_len == data_length1:
break
print(data1.decode('utf-8'))
# 固定读取4字节
header2 = conn.recv(4)
data_length2 = struct.unpack('i', header2)[0] # 数据字节长度
data2 = conn.recv(data_length2) # 长度
print(data2.decode('utf-8'))
conn.close()
sock.close()
# -------------------------客户端-------------------------
import socket
import struct
client = socket.socket()
client.connect(('127.0.0.1', 8001))
# 第一条数据
data1 = 'alex正在吃'.encode('utf-8')
header1 = struct.pack('i', len(data1))
client.sendall(header1)
client.sendall(data1)
# 第二条数据
data2 = '翔'.encode('utf-8')
header2 = struct.pack('i', len(data2))
client.sendall(header2)
client.sendall(data2)
client.close()
案例:消息 & 文件上传
- 服务端
import os
import json
import socket
import struct
def recv_data(conn, chunk_size=1024):
# 获取头部信息:数据长度
has_read_size = 0
bytes_list = []
while has_read_size < 4:
chunk = conn.recv(4 - has_read_size)
has_read_size += len(chunk)
bytes_list.append(chunk)
header = b"".join(bytes_list)
data_length = struct.unpack('i', header)[0]
# 获取数据
data_list = []
has_read_data_size = 0
while has_read_data_size < data_length:
size = chunk_size if (data_length - has_read_data_size) > chunk_size else data_length - has_read_data_size
chunk = conn.recv(size)
data_list.append(chunk)
has_read_data_size += len(chunk)
data = b"".join(data_list)
return data
def recv_file(conn, save_file_name, chunk_size=1024):
save_file_path = os.path.join('files', save_file_name)
# 获取头部信息:数据长度
has_read_size = 0
bytes_list = []
while has_read_size < 4:
chunk = conn.recv(4 - has_read_size)
bytes_list.append(chunk)
has_read_size += len(chunk)
header = b"".join(bytes_list)
data_length = struct.unpack('i', header)[0]
# 获取数据
file_object = open(save_file_path, mode='wb')
has_read_data_size = 0
while has_read_data_size < data_length:
size = chunk_size if (data_length - has_read_data_size) > chunk_size else data_length - has_read_data_size
chunk = conn.recv(size)
file_object.write(chunk)
file_object.flush()
has_read_data_size += len(chunk)
file_object.close()
def run():
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# IP可复用
sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock.bind(('127.0.0.1', 8001))
sock.listen(5)
while True:
conn, addr = sock.accept()
while True:
# 获取消息类型
message_type = recv_data(conn).decode('utf-8')
if message_type == 'close': # 四次挥手,空内容。
print("关闭连接")
break
# 文件:{'msg_type':'file', 'file_name':"xxxx.xx" }
# 消息:{'msg_type':'msg'}
message_type_info = json.loads(message_type)
if message_type_info['msg_type'] == 'msg':
data = recv_data(conn)
print("接收到消息:", data.decode('utf-8'))
else:
file_name = message_type_info['file_name']
print("接收到文件,要保存到:", file_name)
recv_file(conn, file_name)
conn.close()
sock.close()
if __name__ == '__main__':
run()
- 客户端
import os
import json
import socket
import struct
def send_data(conn, content):
data = content.encode('utf-8')
header = struct.pack('i', len(data))
conn.sendall(header)
conn.sendall(data)
def send_file(conn, file_path):
file_size = os.stat(file_path).st_size
header = struct.pack('i', file_size)
conn.sendall(header)
has_send_size = 0
file_object = open(file_path, mode='rb')
while has_send_size < file_size:
chunk = file_object.read(2048)
conn.sendall(chunk)
has_send_size += len(chunk)
file_object.close()
def run():
client = socket.socket()
client.connect(('127.0.0.1', 8001))
while True:
"""
请发送消息,格式为:
- 消息:msg|你好呀
- 文件:file|xxxx.png
"""
content = input(">>>") # msg or file
if content.upper() == 'Q':
send_data(client, "close")
break
input_text_list = content.split('|')
if len(input_text_list) != 2:
print("格式错误,请重新输入")
continue
message_type, info = input_text_list
# 发消息
if message_type == 'msg':
# 发消息类型
send_data(client, json.dumps({"msg_type": "msg"}))
# 发内容
send_data(client, info)
# 发文件
else:
file_name = info.rsplit(os.sep, maxsplit=1)[-1]
# 发消息类型
send_data(client, json.dumps({"msg_type": "file", 'file_name': file_name}))
# 发内容
send_file(client, info)
client.close()
if __name__ == '__main__':
run()
阻塞和非阻塞
默认情况下我们编写的网络编程的代码都是阻塞的(等待),阻塞主要体现在:
# ################### socket服务端(接收者)###################
import socket
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('127.0.0.1', 8001))
sock.listen(5)
# 阻塞
conn, addr = sock.accept()
# 阻塞
client_data = conn.recv(1024)
print(client_data.decode('utf-8'))
conn.close()
sock.close()
# ################### socket客户端(发送者) ###################
import socket
client = socket.socket()
# 阻塞
client.connect(('127.0.0.1', 8001))
client.sendall('alex正在吃翔'.encode('utf-8'))
client.close()
如果想要让代码变为非阻塞,需要这样写: sock.setblocking(False) 加上就变为了非阻塞
但是如果代码变成了非阻塞,程序运行时一旦遇到 accept、recv、connect 就会抛出 BlockingIOError 的异常。
这不是代码编写的有错误,而是原来的IO阻塞变为非阻塞之后,由于没有接收到相关的IO请求抛出的固定错误。
非阻塞的代码一般与IO多路复用结合,可以迸发出更大的作用。

IO多路复用
I/O多路复用指:通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作
IO多路复用 + 非阻塞,可以实现让TCP的服务端同时处理多个客户端的请求,例如:
# ################### socket服务端 ###################
import select
import socket
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.setblocking(False) # 加上就变为了非阻塞
server.bind(('127.0.0.1', 8001))
server.listen(5)
inputs = [server, ] # socket对象列表 -> [server, 第一个客户端连接conn ]
while True:
# 当 参数1 序列中的socket对象发生可读时(accetp和read),则获取发生变化的对象并添加到 r列表中。
# r = []
# r = [server,]
# r = [第一个客户端连接conn,]
# r = [server,]
# r = [第一个客户端连接conn,第二个客户端连接conn]
# r = [第二个客户端连接conn,]
r, w, e = select.select(inputs, [], [], 0.05)
for sock in r:
# server
if sock == server:
conn, addr = sock.accept() # 接收新连接。
print("有新连接")
# conn.sendall()
# conn.recv("xx")
inputs.append(conn)
else:
data = sock.recv(1024)
if data:
print("收到消息:", data)
else:
print("关闭连接")
inputs.remove(sock)
# 干点其他事 20s
"""
优点:
1. 干点那其他的事。
2. 让服务端支持多个客户端同时来连接。
"""
# ################### socket客户端 ###################
import socket
client = socket.socket()
# 阻塞
client.connect(('127.0.0.1', 8001))
while True:
content = input(">>>")
if content.upper() == 'Q':
break
client.sendall(content.encode('utf-8'))
client.close() # 与服务端断开连接(四次挥手),默认会想服务端发送空数据。
IO多路复用 + 非阻塞,可以实现让TCP的客户端同时发送多个请求,例如:去某个网站发送下载图片的请求。
import socket
import select
import uuid
import os
client_list = [] # socket对象列表
for i in range(5):
client = socket.socket()
client.setblocking(False)
try:
# 连接百度,虽然有异常BlockingIOError,但向还是正常发送连接的请求
client.connect(('47.98.134.86', 80))
except BlockingIOError as e:
pass
client_list.append(client)
recv_list = [] # 放已连接成功,且已经把下载图片的请求发过去的socket
while True:
# w = [第一个socket对象,]
# r = [socket对象,]
r, w, e = select.select(recv_list, client_list, [], 0.1)
for sock in w:
# 连接成功,发送数据
# 下载图片的请求
sock.sendall(b"GET /nginx-logo.png HTTP/1.1\r\nHost:47.98.134.86\r\n\r\n")
recv_list.append(sock)
client_list.remove(sock)
for sock in r:
# 数据发送成功后,接收的返回值(图片)并写入到本地文件中
data = sock.recv(8196)
content = data.split(b'\r\n\r\n')[-1]
random_file_name = "{}.png".format(str(uuid.uuid4()))
with open(os.path.join("images", random_file_name), mode='wb') as f:
f.write(content)
recv_list.remove(sock)
if not recv_list and not client_list:
break
"""
优点:
1. 可以伪造除并发的现象。
"""
IO多路复用概念补充
基于 IO多路复用 + 非阻塞的特性,无论编写socket的服务端和客户端都可以提升性能。其中
- IO多路复用,监测socket对象是否有变化(是否连接成功?是否有数据到来等)。
- 非阻塞,socket的connect、recv过程不再等待。
注意:IO多路复用只能用来监听 IO对象 是否发生变化,常见的有:文件是否可读写、电脑终端设备输入和输出、网络请求(常见)。 - 在Linux操作系统化中 IO多路复用 有三种模式,分别是:select,poll,epoll。(windows 只支持select模式)
select
select最早于1983年出现在4.2BSD中,它通过一个select()系统调用来监视多个文件描述符的数组,当select()返回后,该数组中就绪的文件描述符便会被内核修改标志位,使得进程可以获得这些文件描述符从而进行后续的读写操作。
select目前几乎在所有的平台上支持,其良好跨平台支持也是它的一个优点,事实上从现在看来,这也是它所剩不多的优点之一。
select的一个缺点在于单个进程能够监视的文件描述符的数量存在最大限制,在Linux上一般为1024,不过可以通过修改宏定义甚至重新编译内核的方式提升这一限制。
另外,select()所维护的存储大量文件描述符的数据结构,随着文件描述符数量的增大,其复制的开销也线性增长。同时,由于网络响应时间的延迟使得大量TCP连接处于非活跃状态,但调用select()会对所有socket进行一次线性扫描,所以这也浪费了一定的开销。
poll
poll在1986年诞生于System V Release 3,它和select在本质上没有多大差别,但是poll没有最大文件描述符数量的限制。
poll和select同样存在一个缺点就是,包含大量文件描述符的数组被整体复制于用户态和内核的地址空间之间,而不论这些文件描述符是否就绪,它的开销随着文件描述符数量的增加而线性增大。
另外,select()和poll()将就绪的文件描述符告诉进程后,如果进程没有对其进行IO操作,那么下次调用select()和poll()的时候将再次报告这些文件描述符,所以它们一般不会丢失就绪的消息,这种方式称为水平触发(Level Triggered)。
epoll
直到Linux2.6才出现了由内核直接支持的实现方法,那就是epoll,它几乎具备了之前所说的一切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法。
epoll可以同时支持水平触发和边缘触发(Edge Triggered,只告诉进程哪些文件描述符刚刚变为就绪状态,它只说一遍,如果我们没有采取行动,那么它将不会再次告知,这种方式称为边缘触发),理论上边缘触发的性能要更高一些,但是代码实现相当复杂。
epoll同样只告知那些就绪的文件描述符,而且当我们调用epoll_wait()获得就绪文件描述符时,返回的不是实际的描述符,而是一个代表就绪描述符数量的值,你只需要去epoll指定的一个数组中依次取得相应数量的文件描述符即可,这里也使用了内存映射(mmap)技术,这样便彻底省掉了这些文件描述符在系统调用时复制的开销。
另一个本质的改进在于epoll采用基于事件的就绪通知方式。在select/poll中,进程只有在调用一定的方法后,内核才对所有监视的文件描述符进行扫描,而epoll事先通过epoll_ctl()来注册一个文件描述符,一旦基于某个文件描述符就绪时,内核会采用类似callback的回调机制,迅速激活这个文件描述符,当进程调用epoll_wait()时便得到通知。
多进程和多线程
GIL, 全局解释器锁(Global Interpreter Lock),是CPython解释器特有一个玩意,让一个进程中同一个时刻只能有一个线程可以被CPU调用。
多进程的几种创建模式和区别
进程与进程之间则是相互隔离。
Python中通过多进程可以利用CPU的多核优势,计算密集型操作适用于多进程。
关于在Python中基于multiprocessiong模块操作的进程:
Depending on the platform, multiprocessing supports three ways to start a process. These start methods are
- fork,【“拷贝”几乎所有资源】【支持文件对象/线程锁等传参】【unix】【任意位置开始】【快】
The parent process usesos.fork()to fork the Python interpreter. The child process, when it begins, is effectively identical to the parent process. All resources of the parent are inherited by the child process. Note that safely forking a multithreaded process is problematic.Available on Unix only. The default on Unix.- spawn,【run参数传必备资源】【不支持文件对象/线程锁等传参】【unix、win】【main代码块开始】【慢】
The parent process starts a fresh python interpreter process. The child process will only inherit those resources necessary to run the process object’srun()method. In particular, unnecessary file descriptors and handles from the parent process will not be inherited. Starting a process using this method is rather slow compared to using fork or forkserver.Available on Unix and Windows. The default on Windows and macOS.- forkserver,【run参数传必备资源】【不支持文件对象/线程锁等传参】【部分unix】【main代码块开始】
When the program starts and selects the forkserver start method, a server process is started. From then on, whenever a new process is needed, the parent process connects to the server and requests that it fork a new process. The fork server process is single threaded so it is safe for it to useos.fork(). No unnecessary resources are inherited.Available on Unix platforms which support passing file descriptors over Unix pipes.
multiprocessing.set_start_method("spawn")
上述文档总结要点如下:
- windows模式下不需要设置,因为windows下多进程只支持spawn模式.
- fork模式下基本上是子进程会拷贝主进程的所有资源,而其他2个需要通过传参形式,不支持文件句柄和线程锁传参,注意是线程锁不是进程锁,意味着进程锁可以传参进去
代码示例
import multiprocessing
import time
"""
def task():
print(name)
name.append(123)
if __name__ == '__main__':
multiprocessing.set_start_method("fork") # fork、spawn、forkserver
name = []
#在创建子进程前name=[],因此创建子进程后,fork模式会复制这个name变量,最终输出[]
p1 = multiprocessing.Process(target=task)
p1.start()
time.sleep(2)
print(name) # []
"""
# --------------------------------------------------------------
"""
def task():
print(name) # [123]
if __name__ == '__main__':
multiprocessing.set_start_method("fork") # fork、spawn、forkserver
name = []
name.append(123)
在创建子进程前name=[123],因此创建子进程后,fork模式会复制这个name变量,最终输出[123]
p1 = multiprocessing.Process(target=task)
p1.start()
"""
# --------------------------------------------------------------
"""
def task():
print(name) # []
if __name__ == '__main__':
multiprocessing.set_start_method("fork") # fork、spawn、forkserver
name = []
#在创建子进程前name=[],因此创建子进程后,fork模式会复制这个name变量,最终输出[]
p1 = multiprocessing.Process(target=task)
p1.start()
#此时主进程的name为[123]而子进程的name依旧是创建之前复制的值[]
name.append(123)
"""
代码示例2
import multiprocessing
def task():
# 2子进程是fork模式复制,因此name=[] 文件写入的数据是 "武沛齐\nalex\n"
print(name)
file_object.write("alex\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("武沛齐\n")
# 1创建子进程前name=[] file_obj在内存中有武沛齐\n
p1 = multiprocessing.Process(target=task)
p1.start()
# 3此时主进程结束,结束前会把前面在内存的"武沛齐\n"也写入到硬盘文件中
#3 最终输出结果是"武沛齐\nalex\n武沛齐\n"
代码示例3
import multiprocessing
def task():
print(name)
# 2. 子进程会再写入一个"alex\n"
file_object.write("alex\n")
file_object.flush()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
file_object = open('x1.txt', mode='a+', encoding='utf-8')
file_object.write("武沛齐\n")
file_object.flush()
# 1. 子进程创建之前主进程会写入"武沛齐\n"
p1 = multiprocessing.Process(target=task)
p1.start()
# 3. 最终输出结果是"武沛齐\nalex\n"
代码示例4
import multiprocessing
import threading
import time
def func():
print("来了")
# 4 此时10个子线程都卡在这里
with lock:
# 6 主线程释放锁以后子线程开始各自申请锁进行输出
print(666)
time.sleep(1)
def task():
# 3 此时子进程的锁是申请走的状态,申请的对象是子进程中的主线程
for i in range(10):
t = threading.Thread(target=func)
t.start()
time.sleep(2)
# 5 等子进程的主线程运行到这里,释放锁
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("fork")
name = []
lock = threading.RLock()
lock.acquire()
# 1.fork模式可以拷贝线程锁,此时主进程的线程锁是已申请状态
p1 = multiprocessing.Process(target=task)
# 2.创建子进程,复制了线程锁,也复制了锁的申请状态
p1.start()
多进程之间的数据共享和交换
进程彼此之间是相互隔离的.因此如果需要多进程之间共享交换数据,python提供的官方方法有如下4种
- Value 和 Array方法 不太常用
先看下Value和Array的数据类型,这个是通过底层C语言实现的数据交换,因此数据类型定义完毕后无法更改
Array其实就是数组,他有2个限制, 1.定义完类型就不能更改 2.定义完数组的长度也无法更改,不能增删,只能改,改的值也必须是符合数据类型定义的值
'c': ctypes.c_char, 'u': ctypes.c_wchar, char代表非中文的字符 wchar代表可以有中文的字符
'b': ctypes.c_byte, 'B': ctypes.c_ubyte, byte是256个整数 byte是代表可以有符号 代表 -127~128之间 而ubyte是0~255 (其u表示无符号)
'h': ctypes.c_short, 'H': ctypes.c_ushort, short和int long double区别是正整数的范围大小区别
'i': ctypes.c_int, 'I': ctypes.c_uint,
'l': ctypes.c_long, 'L': ctypes.c_ulong,
'f': ctypes.c_float, 'd': ctypes.c_double
代码示例
# --------------------------Value----------------------------------
from multiprocessing import Process, Value, Array
def func(n, m1, m2):
n.value = 888
m1.value = 'a'.encode('utf-8')
m2.value = "武"
if __name__ == '__main__':
num = Value('i', 666)
v1 = Value('c')
v2 = Value('u')
p = Process(target=func, args=(num, v1, v2))
p.start()
p.join()
print(num.value) # 888
print(v1.value) # a
print(v2.value) # 武
# --------------------------Array----------------------------------
from multiprocessing import Process, Value, Array
def f(data_array):
data_array[0] = 666
if __name__ == '__main__':
# 这里定义i类型,因此数组的元素必须全部是整形,且元素个数不能增删
arr = Array('i', [11, 22, 33, 44]) # 数组:元素类型必须是int; 只能是这么几个数据。
p = Process(target=f, args=(arr,))
p.start()
p.join()
print(arr[:])
- Manager方法 比较常用
Manager可以定义列表和字典的数据类型
from multiprocessing import Process, Manager
def f(d, l):
d[1] = '1'
d['2'] = 2
d[0.25] = None
l.append(666)
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
l = manager.list()
p = Process(target=f, args=(d, l))
p.start()
p.join()
print(d)
print(l)
# -----------------------------------------------
import multiprocessing
from multiprocessing import Process, Manager
import os
import time
def test(idx, common_dict):
print("进程<%s>开始运行" %multiprocessing.current_process().name)
for i in range(idx+1):
pid = os.getpid()
ppid = os.getpgid(pid)
common_dict[ppid] = i
common_dict[multiprocessing.current_process().name] = i
time.sleep(0.5)
print("%s运行结束,字段数值是%s"%(multiprocessing.current_process().name,common_dict))
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
with Manager() as manager:
d = manager.dict()
p1 = Process(target=test, args=(10, d,))
p2 = Process(target=test, args=(12, d,))
p3 = Process(target=test, args=(13, d,))
p4 = Process(target=test, args=(14, d,))
p1.name="多进程1"
p2.name="多进程2"
p3.name="多进程3"
p4.name="多进程4"
[i.start() for i in [p1, p2, p3, p4]]
[i.join() for i in [p1, p2, p3, p4]]
print(d)
- 队列 比较常用
import multiprocessing
def task(q):
for i in range(10):
q.put(i)
if __name__ == '__main__':
queue = multiprocessing.Queue()
p = multiprocessing.Process(target=task, args=(queue,))
p.start()
p.join()
print("主进程")
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
print(queue.get())
- 管道, 队列是A>B数据先单向发送,先进先出,而管道是两端数据相互发送和网络的socket服务端和客户端类似
import time
import multiprocessing
def task(conn):
time.sleep(1)
conn.send([111, 22, 33, 44])
data = conn.recv() # 阻塞
print("子进程接收:", data)
time.sleep(2)
if __name__ == '__main__':
parent_conn, child_conn = multiprocessing.Pipe()
p = multiprocessing.Process(target=task, args=(child_conn,))
p.start()
info = parent_conn.recv() # 阻塞
print("主进程接收:", info)
parent_conn.send(666)
- python官方以外还提供其他数据共享的机制 例如:MySQL、redis等。
多进程和多线程的调用,阻塞,守护主进(线)程,以及主(线)程的名字设置
- 两者都是用start方法进行启动,并且join方法进行阻塞,等待当前进(线)程的任务执行完毕后再向下继续执行
# ----------------------------------------多进程----------------------------------
import time
from multiprocessing import Process
def task(arg):
time.sleep(2)
print("执行中...")
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
p = Process(target=task, args=('xxx',))
p.start()
p.join()
print("继续执行...")
# ----------------------------------------多线程----------------------------------
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += 1
def _sub(count):
global number
for i in range(count):
number -= 1
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
t1.start()
t2.start()
t1.join() # t1线程执行完毕,才继续往后走
t2.join() # t2线程执行完毕,才继续往后走
print(number)
- 多进程和多线程都有守护进(线)程的方法 守护进(线)程守护的都是主进(线)程 默认设置都是false 不守护,也就意味着子进(线)程运行完毕后,主进(线)程才结束,反之则是
守护主进程p.daemon = 布尔值,守护进程(必须放在start之前) p.daemon =True,设置为守护进程,主进程执行完毕后,子进程也自动关闭。
守护主线程t.setDaemon(布尔值),守护线程(必须放在start之前) t.setDaemon(True),设置为守护线程,主线程执行完毕后,子线程也自动关闭。`
线程可以分为两种类型:守护线程和非守护线程。它们之间的主要区别在于:
是否会阻塞主线程的退出:如果一个线程被设置为守护线程,那么当主线程结束时,它会随着主线程一起结束,即使该线程正在执行某些操作也会被强制终止。而非守护线程则不会影响主线程的退出。
是否等待其他线程的结束:当所有非守护线程结束后,程序才会退出。但是,如果仍有守护线程在运行,则不会等待守护线程完成就会直接退出程序。
是否能获得资源锁:如果一个线程被设置为守护线程,那么它不能获得资源锁(如互斥锁、条件变量),因为它可能在主线程结束前被强制终止。而非守护线程则可以正常使用资源锁。
需要注意的是,在 Python 中,默认情况下,线程是非守护线程。如果您想将线程设置为守护线程,可以使用 setDaemon(True) 方法来实现。同时,在编写多线程程序时,请务必考虑程序的退出方式和资源管理问题,以保证程序的正确性和可靠性。
- 多主(线)程的名字设置和获取
进程名字设置multiprocessing.current_process().name p.name = "进程1号"
线程名字设置threading.current_thread().getName() t.setName("线程1号")
# ----------------------------------------多进程----------------------------------
import multiprocessing
from multiprocessing import current_process
import time
def task(idx):
print("子进程%s开始运行"%current_process().name)
time.sleep(2)
print("多进程任务开始,进程名字是%s,传入的参数是%s" % (current_process().name, idx))
if __name__ == '__main__':
print("主进程开始")
task_list = []
for i in range(5):
p = multiprocessing.Process(target=task,args=(i,))
p.name = "进程%s"%i
# p.daemon=True # 如果设置了守护进程,运行输出结果是 主进程开始 主进程结束
p.start()
task_list.append(p)
# [i.join() for i in task_list]
print("主进程结束")
输出结果:
主进程开始
主进程结束
子进程进程0开始运行
子进程进程1开始运行
子进程进程3开始运行
子进程进程2开始运行
子进程进程4开始运行
多进程任务开始, 进程名字是进程0, 传入的参数是0
多进程任务开始, 进程名字是进程1, 传入的参数是1
多进程任务开始, 进程名字是进程3, 传入的参数是3
多进程任务开始, 进程名字是进程2, 传入的参数是2
多进程任务开始, 进程名字是进程4, 传入的参数是4
# ----------------------------------------多进程----------------------------------
# ----------------------------------------多线程----------------------------------
import threading
from threading import Thread
import time
def task(idx):
print("子进程%s开始运行"%threading.currentThread().getName())
time.sleep(2)
print("多进程任务开始,进程名字是%s,传入的参数是%s" % (threading.currentThread().getName(), idx))
if __name__ == '__main__':
print("主线程开始")
task_list = []
for i in range(5):
t = Thread(target=task,args=(i,))
t.setName("线程%s"%i)
# p.daemon=True # 如果设置了守护进程,运行输出结果是 主进程开始 主进程结束
t.start()
task_list.append(t)
[i.join() for i in task_list]
print("主线程结束")
# ----------------------------------------多线程----------------------------------
自定义多进(线)程类
# ----------------------------------------多进程----------------------------------
import threading
class MyThread(threading.Thread):
def run(self):
print('执行此线程', self._args) # self._args就是args传入的参数,传元祖显示元祖
t = MyThread(args=(100,))
t.start() #一旦执行start方法,就会去执行子类的run方法
-----------------------------------------------------
import requests
import threading
class DouYinThread(threading.Thread):
def __init__(self):
super(MyThread, self).__init__() # 加入这句话,因为多线程实例化,需要调用__call__方法,或者自己在类中写一个
def run(self):
file_name, video_url = self._args
res = requests.get(video_url)
with open(file_name, mode='wb') as f:
f.write(res.content)
url_list = [
("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"),
("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"),
("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg")
]
for item in url_list:
t = DouYinThread(args=(item[0], item[1]))
t.start()
# ----------------------------------------多线程加入了线程池----------------------------------
import concurrent.futures
class MyThread:
def __init__(self, thread_id, name):
super(MyThread, self).__init__() # 加入这句话,因为多线程实例化,需要调用__call__方法,或者自己在类中写一个
self.thread_id = thread_id
self.name = name
def run(self):
print(f"开始线程:{self.name}")
# 执行线程操作
print(f"结束线程:{self.name}")
if __name__ == "__main__":
# 创建线程池
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 开启新线程
threads = [MyThread(i, f"Thread-{i}") for i in range(5)]
results = [executor.submit(thread.run) for thread in threads]
# 获取执行结果
for result in concurrent.futures.as_completed(results):
print(result.result())
print("退出主线程")
# ----------------------------------------多进程----------------------------------
# ----------------------------------------多线程----------------------------------
import multiprocessing
class MyProcess(multiprocessing.Process):
def run(self):
print('执行此进程', self._args)
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
p = MyProcess(args=('xxx',))
p.start()
print("继续执行...")
# ----------------------------------------多线程----------------------------------
多进(线)程的进(线)程池和锁和线程安全
一个进程中可以有多个线程,且线程共享所有进程中的资源。多个线程同时去操作一个"东西",可能会存在数据混乱的情况.
而多进程 虽然进程和进程之间数据是隔离的,但是也可以通过其他方法进行数据共享,也会造成数据混乱的情况.
因此需要锁来保证数据的安全
数据混乱的代码示例
多线程通常是因为操作全局变量导致,而多进程则是因为做了进程之间的数据共享导致
# ----------------------------------------多进程示例1----------------------------------
import time
from multiprocessing import Process, Value, Array
def func(n, ):
n.value = n.value + 1
if __name__ == '__main__':
num = Value('i', 0)
for i in range(20):
p = Process(target=func, args=(num,))
p.start()
time.sleep(3)
print(num.value)
# ----------------------------------------多进程示例2----------------------------------
import time
from multiprocessing import Process, Manager
def f(d, ):
d[1] += 1
if __name__ == '__main__':
with Manager() as manager:
d = manager.dict()
d[1] = 0
for i in range(20):
p = Process(target=f, args=(d,))
p.start()
time.sleep(3)
print(d)
# ----------------------------------------多进程示例3----------------------------------
import time
import multiprocessing
def task():
# 假设文件中保存的内容就是一个值:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
for i in range(20):
p = multiprocessing.Process(target=task)
p.start()
# ----------------------------------------多线程代码示例1----------------------------------
import threading
loop = 10000000
number = 0
def _add(count):
global number
for i in range(count):
number += 1
def _sub(count):
global number
for i in range(count):
number -= 1
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
t1.start()
t2.start()
t1.join() # t1线程执行完毕,才继续往后走
t2.join() # t2线程执行完毕,才继续往后走
print(number)
# ----------------------------------------多线程代码示例2----------------------------------
import threading
num = 0
def task():
global num
for i in range(1000000):
num += 1
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
锁
- 同步锁
threading.Lock() multiprocessing.Lock() - 递归锁
threading.RLock() multiprocessing.RLock()
RLock支持多次申请锁和多次释放;Lock不支持
# Lock不支持多次申请和释放,会卡主
import threading
import time
lock_object = threading.RLock()
def task():
print("开始")
lock_object.acquire()
lock_object.acquire()
print(123)
lock_object.release()
lock_object.release()
for i in range(3):
t = threading.Thread(target=task)
t.start()
# RLock支持多次申请和释放
import threading
lock = threading.RLock()
# 程序员A开发了一个函数,函数可以被其他开发者调用,内部需要基于锁保证数据安全。
def func():
with lock:
pass
# 程序员B开发了一个函数,可以直接调用这个函数。
def run():
print("其他功能")
func() # 调用程序员A写的func函数,内部用到了锁。
print("其他功能")
# 程序员C开发了一个函数,自己需要加锁,同时也需要调用func函数。
def process():
with lock:
print("其他功能")
func() # ----------------> 此时就会出现多次锁的情况,只有RLock支持(Lock不支持)。
print("其他功能")
- 死锁 由于竞争资源或者由于彼此通信而造成的一种阻塞的现象。
# ----------------------因为多次上锁导致的死锁-------------------------
import threading
num = 0
lock_object = threading.Lock()
def task():
print("开始")
lock_object.acquire() # 第1个抵达的线程进入并上锁,其他线程就需要再此等待。
lock_object.acquire() # 第1个抵达的线程进入并上锁,其他线程就需要再此等待。
global num
for i in range(1000000):
num += 1
lock_object.release() # 线程出去,并解开锁,其他线程就可以进入并执行了
lock_object.release() # 线程出去,并解开锁,其他线程就可以进入并执行了
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
# ---------------------因为相互争夺对方的锁的掌控权导致的死锁---------------------------------
import threading
import time
lock_1 = threading.Lock()
lock_2 = threading.Lock()
def task1():
lock_1.acquire()
time.sleep(1)
lock_2.acquire()
print(11)
lock_2.release()
print(111)
lock_1.release()
print(1111)
def task2():
lock_2.acquire()
time.sleep(1)
lock_1.acquire()
print(22)
lock_1.release()
print(222)
lock_2.release()
print(2222)
t1 = threading.Thread(target=task1)
t1.start()
t2 = threading.Thread(target=task2)
t2.start()
- 多进(线)程加锁后的代码示例以及多进程spawn模式下,子进程需要阻塞等待子进程执行完毕,而fork模式不需要
# ----------------------------------------多进程spawn模式示例1----------------------------------
import time
import multiprocessing
import os
def task(lock):
print("开始")
lock.acquire()
# 假设文件中保存的内容就是一个值:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print(os.getpid(), "排队抢票了")
time.sleep(0.5)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
if __name__ == '__main__':
multiprocessing.set_start_method("spawn")
lock = multiprocessing.RLock()
process_list = []
for i in range(10):
# 这里多进程的spawn模式下,锁是可以被当成参数传进来的,而多线程不能当参数传入
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
process_list.append(p)
# spawn模式,需要子进程阻塞等待子进程执行完成后再往下走,而fork模式则不需要阻塞等待。
for item in process_list:
item.join()
# ----------------------------------------多进程fork模式示例2----------------------------------
import time
import multiprocessing
def task(lock):
print("开始")
lock.acquire()
# 假设文件中保存的内容就是一个值:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
lock.release()
# 这个示例主要展示unix下不同多进程的模式 使用的不同,fork模式不需要join阻塞
if __name__ == '__main__':
multiprocessing.set_start_method('fork')
lock = multiprocessing.RLock()
for i in range(10):
# 这里多进程的spawn模式下,锁是可以被当成参数传进来的,而多线程不能当参数传入
p = multiprocessing.Process(target=task, args=(lock,))
p.start()
# spawn模式,需要子进程阻塞等待子进程执行完成后再往下走,而fork模式则不需要阻塞等待。
# ----------------------------------------多线程示例1----------------------------------
import threading
lock_object = threading.RLock()
loop = 10000000
number = 0
def _add(count):
lock_object.acquire() # 加锁
global number
for i in range(count):
number += 1
lock_object.release() # 释放锁
def _sub(count):
lock_object.acquire() # 申请锁(等待)
global number
for i in range(count):
number -= 1
lock_object.release() # 释放锁
t1 = threading.Thread(target=_add, args=(loop,))
t2 = threading.Thread(target=_sub, args=(loop,))
t1.start()
t2.start()
t1.join() # t1线程执行完毕,才继续往后走
t2.join() # t2线程执行完毕,才继续往后走
print(number)
# ----------------------------------------多线程示例2----------------------------------
import threading
num = 0
lock_object = threading.RLock()
def task():
print("开始")
lock_object.acquire() # 第1个抵达的线程进入并上锁,其他线程就需要再此等待。
global num
for i in range(1000000):
num += 1
lock_object.release() # 线程出去,并解开锁,其他线程就可以进入并执行了
print(num)
for i in range(2):
t = threading.Thread(target=task)
t.start()
进(线)程池
线程不是开的越多越好,开的多了可能会导致系统的性能更低了,进程就更不行了,一般受限于CPU的核心个数
进程池: from concurrent.futures import ProcessPoolExecutor
线程池: from concurrent.futures import ThreadPoolExecutor
# --------------------进程池--------------------------------
import time
from concurrent.futures import ProcessPoolExecutor
import multiprocessing
def task(num):
print("执行", num)
time.sleep(2)
return num
def done(res):
print(multiprocessing.current_process())
time.sleep(1)
print(res.result())
time.sleep(1)
if __name__ == '__main__':
pool = ProcessPoolExecutor(4)
for i in range(50):
fur = pool.submit(task, i)
fur.add_done_callback(done) # done的调用由主进程处理(与线程池不同)
print(multiprocessing.current_process())
pool.shutdown(True)
# ----------------如果在进程池中要使用进程锁,则需要基于Manager中的Lock和RLock来实现。---------------------
import time
import multiprocessing
from concurrent.futures.process import ProcessPoolExecutor
def task(lock):
print("开始")
# lock.acquire()
# lock.relase()
with lock:
# 假设文件中保存的内容就是一个值:10
with open('f1.txt', mode='r', encoding='utf-8') as f:
current_num = int(f.read())
print("排队抢票了")
time.sleep(1)
current_num -= 1
with open('f1.txt', mode='w', encoding='utf-8') as f:
f.write(str(current_num))
if __name__ == '__main__':
pool = ProcessPoolExecutor()
# lock_object = multiprocessing.RLock() # 不能使用
manager = multiprocessing.Manager()
lock_object = manager.RLock() # Lock
for i in range(10):
pool.submit(task, lock_object)
# --------------------执行完线程池的任务继续执行别的--------------------------
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url):
print("开始执行任务", video_url)
time.sleep(5)
# 创建线程池,最多维护10个线程。
pool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(300)]
for url in url_list:
# 在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程,则等待。
pool.submit(task, url)
print("执行中...")
pool.shutdown(True) # 等待线程池中的任务执行完毕后,在继续执行
print('继续往下走')
# ----------------------------线程池任务执行完毕后执行其他任务-------------------------------------
import time
import random
from concurrent.futures import ThreadPoolExecutor, Future
def task(video_url):
print("开始执行任务", video_url)
time.sleep(2)
return random.randint(0, 10)
def done(response):
print("任务执行后的返回值", response.result())
# 创建线程池,最多维护10个线程。
pool = ThreadPoolExecutor(10)
url_list = ["www.xxxx-{}.com".format(i) for i in range(15)]
for url in url_list:
# 在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程,则等待。
future = pool.submit(task, url)
future.add_done_callback(done) # 是子主线程执行
# 可以做分工,例如:task专门下载,done专门将下载的数据写入本地文件。
# ---------------------------线程池的任务完成后统一获取后续任务的返回值--------------------------------------
import time
import random
from concurrent.futures import ThreadPoolExecutor,Future
def task(video_url):
print("开始执行任务", video_url)
time.sleep(2)
return random.randint(0, 10)
# 创建线程池,最多维护10个线程。
pool = ThreadPoolExecutor(10)
future_list = []
url_list = ["www.xxxx-{}.com".format(i) for i in range(15)]
for url in url_list:
# 在线程池中提交一个任务,线程池中如果有空闲线程,则分配一个线程去执行,执行完毕后再将线程交还给线程池;如果没有空闲线程,则等待。
future = pool.submit(task, url)
future_list.append(future)
pool.shutdown(True)
for fu in future_list:
print(fu.result())
多线程下的单例模式
遇到单例模式,每次实例化类的对象时,都是最开始创建的那个对象,不再重复创建对象。多线程下会因为单例模式而导致BUG.
- 先简单实现单例模式
class Singleton:
instance = None
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
# 返回空对象
if cls.instance:
return cls.instance
cls.instance = object.__new__(cls)
return cls.instance
obj1 = Singleton('alex')
obj2 = Singleton('SB')
print(obj1,obj2)
- 多线程执行单例模式,有BUG
import threading
import time
class Singleton:
instance = None
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
if cls.instance:
return cls.instance
time.sleep(0.1)
cls.instance = object.__new__(cls)
return cls.instance
def task():
obj = Singleton('x')
#这里输出的是实例的内存地址,正常来讲单例模式下是同一个内存地址,但是因为创建实例前,10个线程就各自开始创建了实例对象.结果没有实现单例模式
print(obj)
for i in range(10):
t = threading.Thread(target=task)
t.start()
- 多线程的单例模式bug解决
import threading
import time
class Singleton:
instance = None
lock = threading.RLock()
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
with cls.lock:
if cls.instance:
return cls.instance
time.sleep(0.1)
cls.instance = object.__new__(cls)
return cls.instance
def task():
obj = Singleton('x')
print(obj)
for i in range(10):
t = threading.Thread(target=task)
t.start()
- 单例模式下bug解决后优化
import threading
import time
class Singleton:
instance = None
lock = threading.RLock()
def __init__(self, name):
self.name = name
def __new__(cls, *args, **kwargs):
if cls.instance:
return cls.instance
with cls.lock:
if cls.instance:
return cls.instance
time.sleep(0.1)
cls.instance = object.__new__(cls)
return cls.instance
def task():
obj = Singleton('x')
print(obj)
for i in range(10):
t = threading.Thread(target=task)
t.start()
# 执行1000行代码
data = Singleton('asdfasdf')
print(data)
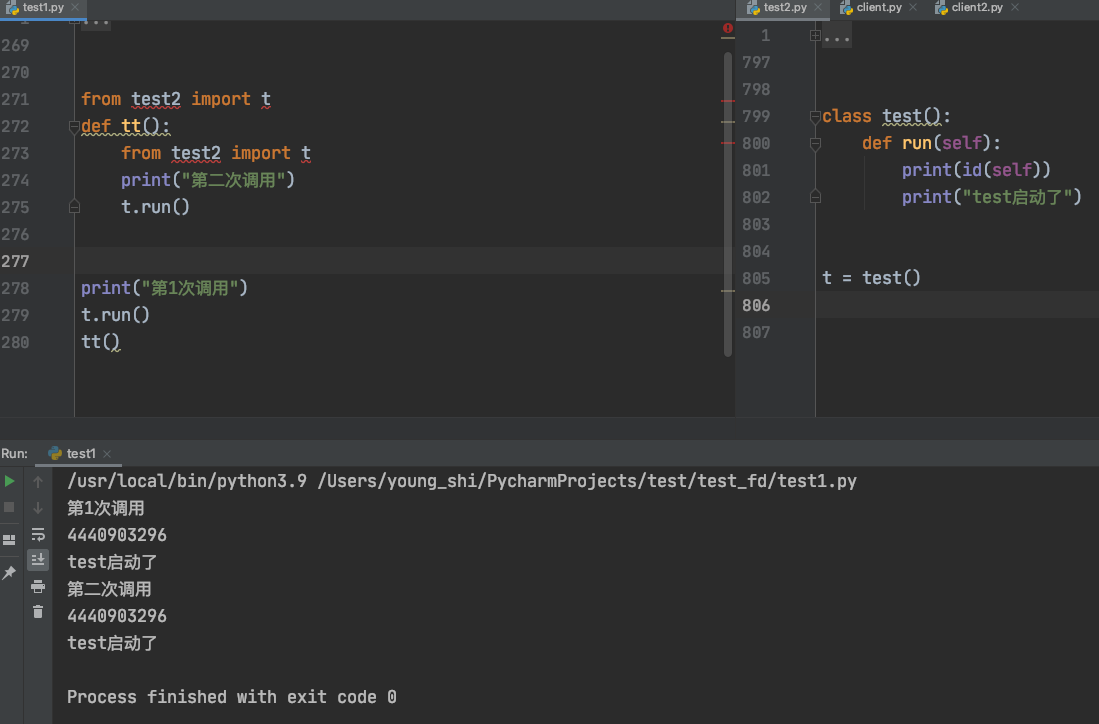
- 单例模式也可以通过导包的形式实现
通过导包形式,多次导入都不会重复生成实例,因为单例的对象已经在启动时候存在内存中了.
本文作者:死了也要PY
本文链接:https://www.cnblogs.com/Young-shi/p/17006003.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步