Linux学习笔记
Linux文件
Linux界面和常用快捷键
- 界面切换
文本到图形
ctrl+alt+f1 图形界面
init 5
图形到文本
ctrl+alt+F2-F6
init 3
2. 安装KDE桌面
yum -y groupinstallpvscan查看已经成功创建 "KDE Plasma Workspaces"
3. 常用快捷键
ctrl + a 移动到行首 等同于home ^
ctrl + e 移动到行尾 等同end $
ctrl + u 删除光标之前的字符
ctrl + k 删除光标之后的字符
ctrl + l 清屏 等同于clear
在命令模式下
##-----光标移动-----##
h # 光标向左移动一个字符
j # 光标向下移动一个字符
k # 光标向上移动一个字符
l # 光标向右移动一个字符
0 [Home] # 数字0;移动到这一行行首(常用)
$ [End] # 移动到这一行行尾(常用)
gg # 转到第一行(常用)
G # 转到最后一行(常用)
nG # n为数字;转到第n行
n<Enter> # n为数字;<Enter>表示<Enter>键;光标向下移动n行
H # 光标移动到这个屏幕的最上方那一行的第一个字符
M # 光标移动到这个屏幕的中央那一行的第一个字符
L # 光标移动到这个屏幕的最下方那一行的第一个字符
##-----光标词间移动-----##
w # 移动到下一个单词头部
b # 移动到前一个单词头部
e # 移动到下一个单词尾部
ge # 移动到前一个单词尾部
##-----复制-----##
yy # 复制光标所在的那一行(常用)
nyy # n为数字;复制光标所在的向下n行
y1G # 复制光标所在行到第一行的所有内容
yG # 复制光标所在行到最后一行的所有内容
y$ # 复制光标所在处,到该行的最后一个字符(常用)
y0 # 数字0;复制光标所在处,到该行的最前面一个字符(常用)
byw # 复制光标所在的一个单词
nyl # n为数字,复制光标向后的n个字符
##-----粘贴-----##
p # 将已复制的数据在光标下一行贴上(常用)
P # 大写;复制在上一行贴上
J # 将光标所在行与下一行的内容结合成同一行
##-----删除-----##
dd # 删除光标所在的那一整行(常用)
:2,5d,即可删除2到5行的文字。
ndd # 删除光标所在的向下n行
dG:删除光标所在行及其下方的所有文本。
d1G:删除光标所在行及其上方的所有文本。
d0:删除从光标位置到行首的所有文本。
d$ D # 删除光标所在处到该行最后字符(常用)
nd + ↑ # n为数字,删除光标所在行及其向上的n行
nd + ↓ # 删除光标所在行及其向下的n行(同ndd)
x # 删除光标处的字符
X # 删除光标的前一个字符
bdw # b 让光标回退到单词开头的位置;dw 从光标当前的位置开始删除,直到删到单词最后
daw # 直接删除光标所在的一个单词
##-----撤回/重复-----##
u # 复原前一个动作(常用)
Ctrl + r # 重做上一个动作(常用)
. # 重复前一个动作(常用)
时区和区域
确认当前的区域设置用locale命令查询,设置了 LANG 为 zh_CN.UTF-8 后,所有没有显式设置的 LC_* 类别会默认为 LANG 的值。
换句话说,如果您只设置了 LANG 而没有设置 LC_* 变量,那么所有的地区设置类别将采用 LANG 的值。
LANG:这是最重要的环境变量,它为所有的 LC_* 变量提供一个默认值。如果某个 LC_* 变量没有被设置,系统就会使用 LANG 变量的值。
LC_CTYPE:定义字符分类和字符串比较。这包括字符的类型,比如哪些字符是空白字符、哪些字符是字母等。
LC_NUMERIC:定义数字格式,比如小数点和千位分隔符的表示方式。
LC_TIME:定义日期和时间的格式,例如如何展示年、月、日、星期、小时、分钟和秒。
LC_COLLATE:定义字符串排序规则,它会影响到字符序列的比较和排序。
LC_MONETARY:定义货币格式,比如货币符号、货币值的格式和小数点表示。
LC_MESSAGES:定义用于提示信息、警告和错误消息的语言和区域设置。
LC_PAPER:定义纸张尺寸的默认大小,这在打印时可能会被应用。
LC_NAME:定义个人名称的书写格式,这包括名字和姓氏的顺序。
LC_ADDRESS:定义地址的格式,包括国家、城市、街道的书写顺序和格式。
LC_TELEPHONE:定义电话号码的格式。
LC_MEASUREMENT:定义度量单位系统,比如使用公制还是英制。
LC_IDENTIFICATION:提供有关 locale 的元数据,例如 locale 的版本、国家代码和语言代码等。
LC_ALL:这是一个特殊的环境变量,当它被设置时,它会覆盖所有其他的 LC_* 变量和 LANG 变量的值。它通常用于测试或者排除语言环境问题。
en_US.UTF-8,表示了具体的语言环境设置。在这个例子中,en_US 表示美式英语,.UTF-8 表示使用 UTF-8 字符编码。
在某些情况下,您可能需要针对不同的 LC_* 类别设置不同的值。例如,您可以将时间、货币和度量单位设置为与中文环境相匹配,而将字符类型设置为英文环境,以便更好地支持多语言编程或文本处理。这样做的命令可能如下所示:
export LC_TIME=zh_CN.UTF-8
export LC_MONETARY=zh_CN.UTF-8
export LC_MEASUREMENT=zh_CN.UTF-8
export LC_CTYPE=en_US.UTF-8
如果你希望将语言设置为中文,并使用24小时制,你可以只设置 LC_TIME 为 zh_CN.UTF-8 或其它中文区域设置:
export LC_TIME="zh_CN.UTF-8"
为了使这个设置永久生效,你可以将上面的命令添加到你的用户的 shell 配置文件中,比如 ~/.bashrc 或 ~/.bash_profile,或者全系统范围,比如 /etc/environment 或 /etc/profile。
设置时区
要设置为中国时区,你可以使用 timedatectl 命令:
sudo timedatectl set-timezone Asia/Shanghai
这个命令将时区设置为 Asia/Shanghai,它是中国大陆的标准时区。
在做出这些更改之后,你可以使用 date +"%Z%z" 命令来验证时间和格式是否正确 正常的东八区会输出 CST+0800
可能还需要重启 sysstat 服务以便新的设置生效:
systemctl restart sysstat
文件目录
常见的目录
boot 启动
etc 配置
home 普通用户家目录
root 超管
proc 进程目录
tmp 临时文件目录
var 日志邮件
bin 命令脚本文件
sbin 超管命令
mnt 挂在目录
media 媒体挂载
usr 应用程序
lib 库

文件管理命令 touch ls cp cat vim
vim
- 设置行号
:set number - 批量替换
2,9s/^/#/2到9行添加注释%s/^/#/全局添加注释 %是全局 s是替换 d是删除 - 取消高亮
:noh
cat和tac
cat -n 可以从上到下展示文本内容并加上行号
paste
用来合并多个文件
paste t1.txt t2.txt 合并2个文件的内容并打印
paste t1.txt t2.txt > t3.txt 合并2个文件的内容输出到t3
sort
sort t1.txt t2.txt 排序2个文件的内容
sort t1.txt t2.txt|uniq 取出两个文件的并集(重复行只保留一份)
sort t1.txt t2.txt|uniq -u 删除交集,留下其他的行
sort t1.txt t2.txt|uniq -d 取出两个文件的交集
tac 可以倒着展示文本内容
Linux用户
passwd和shadow文件
- shadow文件
shadow文件一共有9个字段 1) 用户名 2) 加密密码,如果为空,则对应用户没有口令,登录时不需要口令;*代表账号被锁定;!!代表这个密码过期或者没有密码。*和!!是伪用户,不允许登陆 $6$开头的,表明是用SHA-512加密的, $1$表明是用MD5力口空的 $2$是用Blowfish加密的 $5$患用SHA-256加密的。 3) 〃最后一次修改时间”表示的是从某个时亥起,至用户最后一次修改口令时的天数。不同的系统时间起算年不一样,大部分是以1970年1月1日开始计算 可以用命令推算出修改时间是多少 date -d "1970-01-01 15775 days" 4) 〃最小时间间隔〃指的是两次修改口令之间所需的最小天数。如果是 0,则密码可以随时修改 5) 〃最大时间间隔“指的是口令用寺有效的最大天数 6) "警告时间" 表示系统警告用户直到密码失效的天数 7) 〃密码过期后的宽限天数”表示的是用户没有登录活动但账号仍能保持有效的最大天数。10,则代表密码过期 10 天后失效;如果是 0,则代表密码过期后立即失效;如果是 -1,则代表密码永远不会失效 8) 〃失效时间"字段给出的是一个绝对的天数,如果使用了这个字段,那么就给出相应账号的生存期。期满后该号就不再是一合法的账号,也就不能再用来登录了。(硬限制O ) 9) 保留 - passwd文件
passwd一共7个字段,分别是用户名:密码占位符:uid:gid:描述:HOME路径:shell
uid 普通用户肯定是1000以后,系统自己创建的都是0-999
用户管理命令
1.root用户下,passwd 用户名 可以更改指定用户名的密码,非管理权限下 passwd更改自己的用户名密码.
2.echo 'mongodb:111111' | chpasswd -m
a. 首先将用户名密码一起写入一个临时文件.
cat chpass.txt
root:123456
zhaohang:123456
b. 使用如下命令对用户口令进行修改:
chpasswd -e < chpass.txt
修改用户名的几种方式
1. echo "123456" | passwd --stdin root 容易通过history造成密码泄露, 其它的一些发行版(如Debian/Suse)所提供的passwd并不支持--stdin这个参数
新增用户用useradd -s shell -g GID -u UID -d 目录 -c 描述
删除用户 userdel -r 用户名
更改用户passwd中的属性用usermod命令,比如-s参数更改shell,-d home_dir,-e expire_date 注意这里的-d 只是更改home,但是并不会创建用户的家目录
usermod还有添加组的用途usermod -aG 组名 要加入的组名 注意-G是覆盖,-aG才是追加
用户组管理
- 组信息文件
位置在/etc/group
组成内容 组名:组密码:组ID:组成员 - 命令
groupadd 增组 groupdel 删除组 - 将用户加入组或者从组里删除 一次只能添加(删除)一个
gpasswd -a user group
gpasswd -d user group
su 永久提权
用来本地账户之间的相互切换,
- 命令 su - root 代表切换root用户,并切换成root的环境变量
su root 代表切换root用户,但使用切换前的用户环境变量
sudo 临时提权
-
sudo原理,
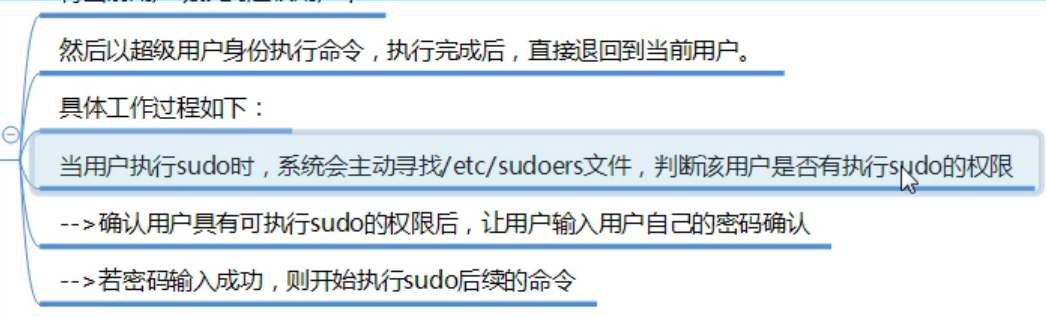
-
sudo命令,sudo就是编辑/etc/sudoers文件
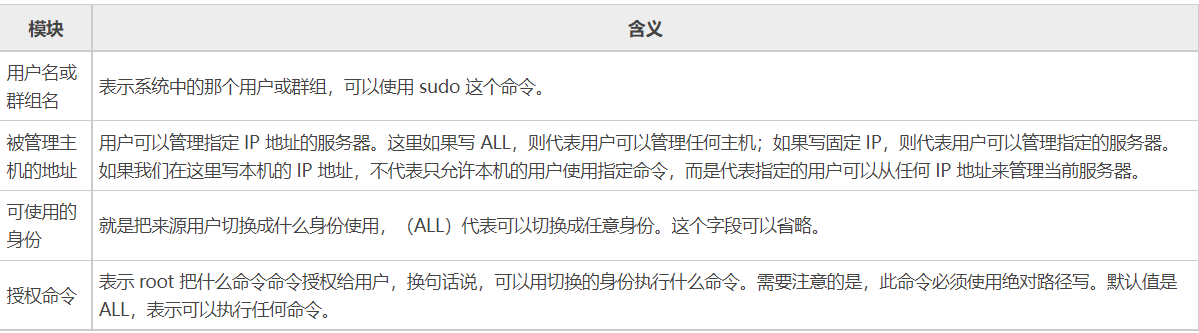
root ALL=(ALL) ALL
用户名 被管理主机的地址=(可使用的身份) 授权命令(绝对路径)
示例
多个授权命令,之间用逗号分隔。用户 lamp 可以使用 sudo -l 查看授权的命令列表:
授权用户 lamp 可以重启服务器,由 root 用户添加,可以在 /etc/sudoers 模板下添加如下语句:
[root@localhost ~]# visudo
lamp ALL=/sbin/shutdown -r now #授权命令要使用绝对路径
Linux权限
权限UGO
- UGO就是u用户,g组,o其他用户,a所有用户,对于rwx的权限设置,rwx分别是421 这里tmp目录有点特殊,他默认有个t权限
- 改权限命令语法: 用chmod 对象(ugoa)赋值符(+-=)权限类型(rwx) 文件目录
chmod ugo+r nginx_bak.conf #所有人皆可读取
chmod a+r nginx_bak.conf #所有人皆可读取
chmod 777 nginx_bak.conf #所有人可读,写,执行
- 改属主语法: 用chown 用户名.组名 文件目录
- 改属组语法: 用chgrp 组名 文件目录
权限ACL
UGO权限是针对一个用户,一个组的,而ACL权限是设置不同用户的,是对UGO一个权限补充功能
我们通过ll命令查看文件的UGO权限,默认都是-rw-r--r--. 注意这里最后是一个.
而通过ACL进行设置过的UGO权限最后一个是+,也就是-rw-r--r--+,这个时候就要用getfacl查看具体补充的权限
- 命令格式:setfacl 参数 用户或组:用户名:权限 文件对象
setfacl -m u:alice:rw /home/test.txt - ACL权限查看
getfacl /home/test.txt
# file: home/test.txt
# owner: root
# group: root
user::rw-
group::r--
other::r--
----------setfacl u:young:r /home/test.txt-------
# file: home/test.txt
# owner: root #属主 root
# group: root #属组 root
user::rw- #用户:属主:rw-
# 上述命令会在这里添加一个young属主读的权限
user:young:r-- #用户:young:r-
group::r-- #组:属组:r
mask::r-- #掩码:属组:r 属于用来临时做权限控制,应用场景比如设置了很多用户的不同权限,突然想统一只给写的权限, setfacl -m m::w home/test.txt, 这样一来其他用户只能写入,无法读取和执行了,上述这个young用户本来是有r权限的,被mask以设置就无法读取了
other::r-- #其他人:其他人:r
- 删除ACL权限
setfacl -x 用户或组:用户名:权限 文件删除一条ACL权限 比如setfacl -x u:young:r /home/1.txt
setfacl -b 文件删除除了属主外其他所有的ACL权限 比如setfacl -b /home/1.txt
特别权限suid
suid是一种临时提权,针对文件和程序时,可以临时获取属主的权限. 可以使用chmod u+s file_path进行实现,该文件程序的权限会从rw-r--r--变成rws-r--r--,
要取消suid 也是用chmod u-s file_path进行取消属主权限,一般不会使用.默认情况下系统的/bin/passwd 就是允许临时提权的,这是因为根据UGO权限规则,/bin/passwd属主是root 如果其他账号无法看到并运行该文件,但是为了给账号提供自我更改密码的功能,做了临时提权,使得普通用户也可以看见并运行该文件,进行密码的修改
特别属性chattr
特殊属性可以用lsattr 文件进行查看,下面列举了几个常见的
i:如果对文件设置 i 属性,那么不允许对文件进行删除、改名,也不能添加和修改数据;如果对目录设置 i 属性,那么只能修改目录下文件中的数据,但不允许建立和删除文件;
a:如果对文件设置 a 属性,那么只能在文件中増加数据,但是不能删除和修改数据;如果对目录设置 a 属性,那么只允许在目录中建立和修改文件,但是不允许删除文件;
u:设置此属性的文件或目录,在删除时,其内容会被保存,以保证后期能够恢复,常用来防止意外删除文件或目录。
s:和 u 相反,删除文件或目录时,会被彻底删除(直接从硬盘上删除,然后用 0 填充所占用的区域),不可恢复。
chattr +a /var/log/messages #让某个文件只能往里面追加数据,但不能删除
chattr -a /var/log/messages #让某个文件删除特殊属性a
掩码umask
umask代表要减去的权限,可以输入umask查看默认的值是0022,
可以临时更改umask值 比如umask 0000这样默认创建出来的文件夹就都是777的权限了,注意的是只是文件的权限默认都是666,哪怕umask设置的是000.这是安全机制,防止恶意执行损坏linux.
Linux进程
进程状态和进程查看
进程常见的6种状态
R(RUNNING) 可运行状态。如果一个进程处于该状态,那么说明它立刻就要或正在CPU上运行。不过运行的时机是不确定的,这有进程调度器来决定
S(TASK_INTERRUPTIBLE) 可中断的睡眠状态。当进程正在等待某个事件(比如网络连接或者信号量)到来时,会进入此状态
D (TASK_UNINTERRUPTIBLE) 不可中断的睡眠状态。此种状态与可中断的睡眠状态的唯一区别就是它不可被打断。处于此状态的进程通常是在等待一个特殊的事件,比如等待同步的I/O操作完成。
T (TASK_STOPPED.) 暂停状态或者跟踪状态。 向进程发送SIGSTOP信号
Z (TASK_DEAD-EXIT_ZOMBIE) 僵尸状态,处于此状态的进程即将结束运行,该进程占用的绝大多数资源也都已经被回收,不过还有一些信息未删除,
X (TASK_DEAD-EXIT_DEAD) 退出状态
查看进程状态有ps,top命令
ps命令常用的有ps -ef用来看pid和ppid,还有ps -aux --sort -%mem,ps -axo pid,%cpu|head -5 o参数可以自定义显示的列名
top命令内容注释
top - 22:03:11 up 33 min, 1 user, load average: 0.00, 0.01, 0.05
运行时间 当前登录用户数 分别在 1分钟 5分钟 15分钟的cpu负载
Tasks: 125 total, 1 running, 124 sleeping, 0 stopped, 0 zombie
总进程数 运行核数 睡眠数 停止数 僵死数
%Cpu(s): 0.0 us, 0.0 sy, 0.0 ni,100.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
cpu使用占比 用户使用占比 系统使用占比 ni是优先级 id是idle空闲 hi是硬件 si是软件 st是虚拟机
KiB Mem : 4154376 total, 3820008 free, 136184 used, 198184 buff/cache
总的物理内存4G 3.8G空闲 使用了136MB 缓存硬盘内容198MB
KiB Swap: 2097148 total, 2097148 free, 0 used. 3769540 avail Mem
交换分区2G 空闲2G 使用0 下次可用空间 3.7G
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
优先级 虚拟内存 物理内存 共享内存 进程状态
9801 root 20 0 162116 2236 1548 R 0.3 0.1 0:01.91 top
1 root 20 0 193552 6552 4140 S 0.0 0.2 0:02.14 systemd
top命令还有些内部指令 
top常用的还有-d -p参数 -d是刷新时间 -p指查看进程号 top -d 5 -p 10,20 每5秒刷新一次pid为10和20的进程信息
进程查看进程启动日期lstart和运行的时间etime
lstart STARTED time the command started. See also bsdstart, start, start_time, and stime.
etime ELAPSED elapsed time since the process was started, in the form [[DD-]hh:]mm:ss.
进程结束命令kill
kill -l可以查看所有的支持的信号
一般来说,1 9 15用的比较多,1是重新加载配置运行,15是让进程正常退出,9是强制杀死

进程优先级
优先级分2种,
- nice是用户自定义优先级,级别是从-20到19,
可以用命令ps -axo pid,command,nice --sort=-nice查看
设置程序优先级别
- 以什么级别启动程序 用nice -n 19 process_name &启动
- 给已启动的进程重新设置优先级 renice -n 19 pid
- 另一种是PR,无法自定义,优先级别是-99到39
进程优先级是PR+NICE,因此可以设置NICE去调整进程的优先级别,TOP命令可以看到有2列,一列PR一列NICE
后台任务
进程可以前后台切换
- 想在后台运行 加& 返回值 [1] 9801
[1]代表这是第几个后台运行程序 9801是pid, - 查看后台进程使用jobs查看
- 后台进程切到前台来用fg 后台进程号,
fg 1把后台第一个运行程序切换到前台 - 前台切到后台,需要先停止运行,使用
ctrl+z进行暂停,然后bg 1把第1个程序切换到后台 - 终止后台程序使用
kill %1终止第1个后台程序,这里的%是为了和kill pid区分开来
proc目录
存放了进程的文件以及系统的一些信息
守护进程
服务(service) 本质就是进程,但是是运行在后台的,通常都会监听某个端口,等待其它程序的请求,比如(mysql , sshd 防火墙等),因此我们又称为守护进程。
service 服务名[start | stop | restart | reload | status],在CentOS7.0后不再使用service ,而是systemctl
有3种方式查看系统运行服务:
- 使用setup -> system service系统服务就可以图形化看到
- /etc/init.d/服务名称
- chkconfig
--add:增加所指定的系统服务,让chkconfig指令得以管理它,并同时在系统启动的叙述文件内增加相关数据;
--del:删除所指定的系统服务,不再由chkconfig指令管理,并同时在系统启动的叙述文件内删除相关数据;
--level<等级代号>:指定读系统服务要在哪一个执行等级中开启或关毕。
-------------------------------------------------------------
chkconfig --add httpd #增加httpd服务。
chkconfig --del httpd #删除httpd服务。
chkconfig --level httpd 2345 on #设置httpd在运行级别为2、3、4、5的情况下都是on(开启)的状态。
chkconfig --list #列出系统所有的服务启动情况。
chkconfig --list mysqld #列出mysqld服务设置情况。
[root@bogon Desktop]# chkconfig --list mysqld
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
[root@bogon Desktop]# chkconfig --list |grep mysql
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
指定某个服务在某个级别的开关情况
chkconfig --level 35 mysqld on #设定mysqld在等级3和5为开机运行服务,
//--level 35表示操作只在等级3和5执行,on表示启动,off表示关闭。
chkconfig mysqld on #设定mysqld在各等级为on,“各等级”包括2、3、4、5等级。
服务运行级别
查看或者修改默认级别:vi /etc/inittab。Linux系统有7种运行级别(runlevel):常用的是级别3和5。
• 运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
• 运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
• 运行级别2:多用户状态(没有NFS),不支持网络
• 运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式
• 运行级别4:系统未使用,保留
• 运行级别5:X11控制台,登陆后进入图形GUI模式
•运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
比如关机可以使用指令init 0,重启可以替换reboot为 init 6 。
cpu
/proc/cpuinfo
内存
/proc/meminfo
内核
/proc/cmdline
FD和管道
FD
fd 全写就是file descriptors,文件句柄,进程使用文件描述符来管理打开的文件
比如我们使用vim编辑一个文件,就会在进程中产生一个句柄,进程号查出来是9829,我们就可以在/proc/9829/fd下发现有0,1,2三个系统产生的文件夹.
这里就代表0:stdin,1:stdout,2:stderr.这里的3是自己VIM打开的编辑页面.从图中可以看到stdin 重定向输入到 /dev/pts/0
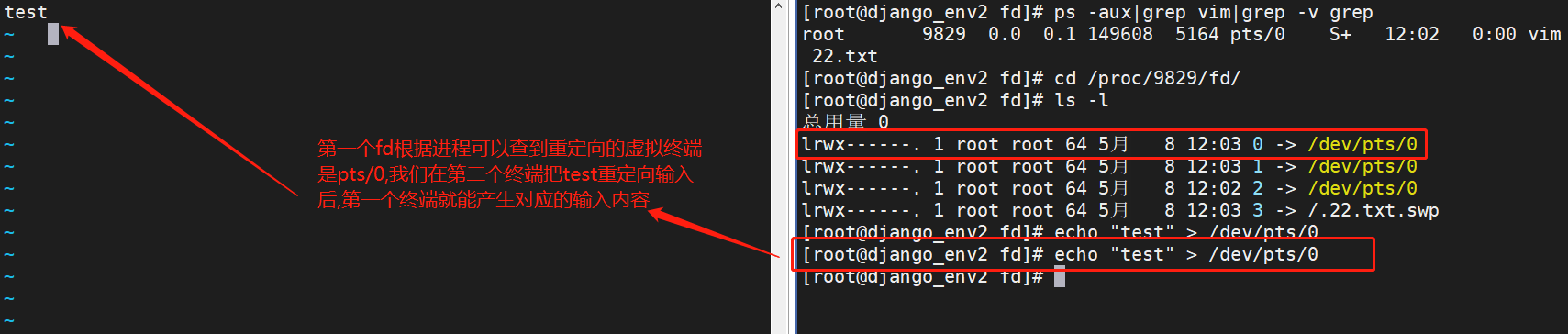
重定向
- 正确的输出重定向
1>等价> 覆盖
1>>等价>> 追加 - 错误输出重定向
2> 没有简写 覆盖
2>> 没有简写 追加 - 输入重定向
cat < /etc/passwd
管道
管道是多个程序之间的组合工具,组合原理是把一个程序的标准输出作为另一个程序的标准输入
- 管道有双通的管道 比如
|,使用方法略 - 管道还有三通的,使用tee命令,大致流程如下
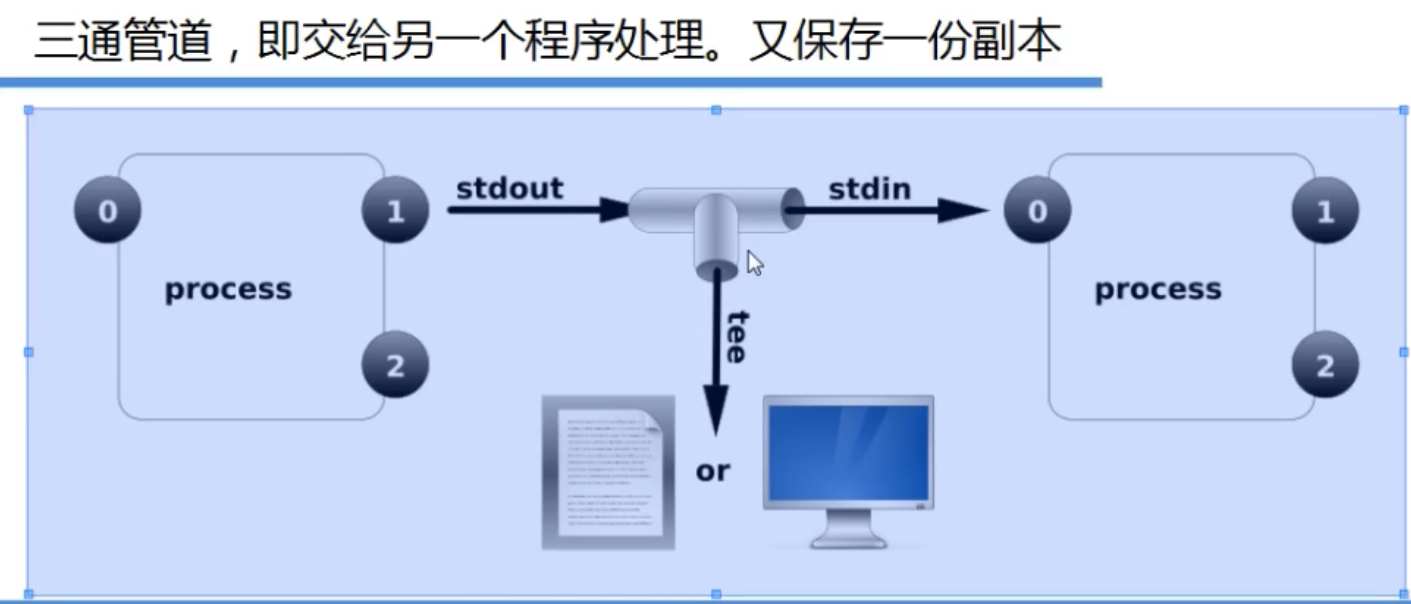
cat /etc/passwd|tail -3|tee 2.txt|grep vim这里的tee命令会把cat /etc/passwd|tail -3的结果保存到2.txt,同时再传给grep命令 - 用xargs传递参数
比如文本写入 aa bb两行数据cat 1.txt|xargs mkdir命令会把1.txt的aa bb 读取出来并传给mkdir命令,就会创建aa和bb两个文件夹在/aaa/bbb目录下查看文件夹大小在0G-9G之间 find ./aaa/bbb -type d |xargs du -sh |grep -e "[0-9]G" 在/aaa/bbb目录下查找距离现在30天的文件 并且删除 find ./aaa/bbb -type -f -mtime +30|xargs rm -f
磁盘
新磁盘添加分区挂载示例
磁盘添加
虚拟机添加步骤略,我们一共添加了2块2G硬盘
新物理磁盘使用三步骤 1.分区(MBR或者GPT) 2.格式化 3.挂载mount
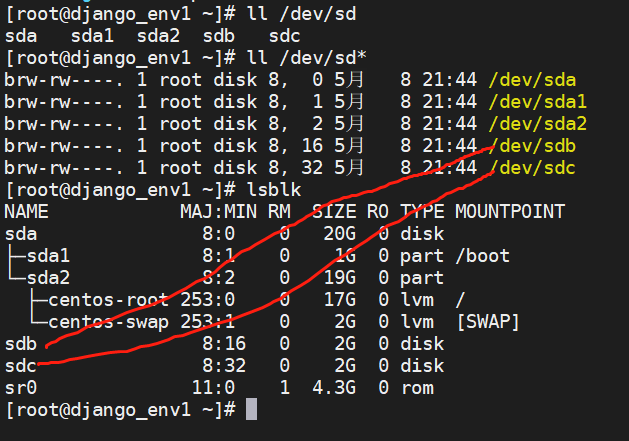
磁盘的文件类型是b block ,可以在ll /dev/sd* 可以看到,其中sda1 sda2是算一个硬盘(sda)不同分区,sda也是默认的c盘概念
也可以用lsblk命令查看
每列信息分别是
名称 设备类型 序号 是否可移动设备 大小 是否只读 磁盘或分区 挂载点
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sr0 11:0 1 4.3G 0 rom
磁盘分区
- 启动分区工具
在 Linux 中有专门的分区命令 fdisk 和 parted。其中 fdisk 命令较为常用,但不支持大于 2TB 的分区;如果需要支持大于 2TB 的分区,则需要使用 parted 命令,当然 parted 命令也能分配较小的分区
fdisk /dev/sdb fdisk 后面指定分区的盘符,输入m查看帮助,这里用n创建分区
| 命令 | 说 明 |
|---|---|
| a | 设置可引导标记 |
| b | 编辑 bsd 磁盘标签 |
| c | 设置 DOS 操作系统兼容标记 |
| d | 删除一个分区 |
| l | 显示已知的文件系统类型。82 为 Linux swap 分区,83 为 Linux 分区 |
| m | 显示帮助菜单 |
| n | 新建分区 |
| 0 | 建立空白 DOS 分区表 |
| P | 显示分区列表 |
| q | 不保存退出 |
| s | 新建空白 SUN 磁盘标签 |
| t | 改变一个分区的系统 ID |
| u | 改变显示记录单位 |
| V | 验证分区表 |
| w | 保存退出 |
| X | 附加功能(仅专家) |
-
选择主分区或者扩展分区,分区一共分为 主分区,扩展分区,逻辑分区. 这里选p
MBR分区模式要求硬盘上主分区数量最多是4个。主分区可以用来安装操作系统,其中只有一个主分区还可以被设置为活动分区。如果硬盘上的4个主分区都安装了操作系统,那么活动分区的设置决定了是从哪个分区的系统启动。被设置为活动分区的主分区具有启动引导程序(例如,NTLDR)用来从硬盘加载操作系统。
扩展分区是主分区剩下的区域就是扩展分区,在扩展分区里再分逻辑分区,按照windows举例,c盘就是主分区,那么剩下的空间区域就是扩展分区,扩展分区里又会分为D E F等多个逻辑分区
-
选择分区号和起始扇区(2048以前的空间用来保存扇区表)
-
设置分区的大小,这里设置+1G
-
输入w保存分区退出
磁盘格式化
格式化就是创建文件系统,这里使用mkfs.ext4 /dev/sdb1 注意后面要填分区sdb1,而不是填整个新硬盘盘符sdb
mkfs是make file system缩写,ext4是扩展程序第4代版本的意思,centos7主要用这个,centos8用xfs,确认回车产生如下信息
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
65536 inodes, 262144 blocks
13107 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=268435456
8 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (8192 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
磁盘挂载
创建挂载点,一个分区一个挂载点
- mkdir /mnt/disk1
- mount -t ext4 /dev/sdb1 /mnt/disk1
挂载完毕后进行查看挂载信息
-
方法1 df-hT
文件系统 类型 容量 已用 可用 已用% 挂载点 /dev/mapper/centos-root xfs 17G 3.3G 14G 20% / devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm tmpfs tmpfs 2.0G 12M 2.0G 1% /run tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup /dev/sda1 xfs 1014M 146M 869M 15% /boot tmpfs tmpfs 406M 0 406M 0% /run/user/0 /dev/sdb1 ext4 976M 2.6M 907M 1% /mnt/disk1 #这里就是挂载的磁盘信息 -
方法2 mount
这个命令会出现一大堆数据,看最后一行
/dev/sdb1 on /mnt/disk1 type ext4 (rw,relatime,seclabel,data=ordered)
MBR分区类型和扩展分区里进行逻辑分区和挂载
MBR最多只能有4个主分区,是因为MBR会划分一个64字节的空间作为文件分区表。然后一个分区的分区表会占用16个字节。所以只能有4个分区表。
如果要再往外延伸,需要创建扩展分区,在扩展分区里再进行逻辑分区。
下面示例是把扩展分区中再进行逻辑分区的示例,分区完出现无法获取分区完的盘符信息,需要用partprobe对sdb的分区列表重新获取后可以解决报错问题.
[root@django_env1 ~]# fdisk /dev/sdb <<<<<<<<<<<<对sdb磁盘进行分区处理
命令(输入 m 获取帮助) p
磁盘 /dev/sdb:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x7fc5decf
设备 Boot Start End Blocks Id System <<<<<<<<<<<<可以看到目前sdb就挂载了2个盘
/dev/sdb1 2048 2099199 1048576 83 Linux
/dev/sdb2 2099200 2713599 307200 83 Linux
命令(输入 m 获取帮助):n
Partition type:
p primary (2 primary, 0 extended, 2 free) <<<<<<<<<2free是只主分区还可以创建2个
e extended
Select (default p): e 创建逻辑分区 <<<<<<<<<创建逻辑分区
分区号 (3,4,默认 3):3 分区号设置为3 <<<<<<<<<设置分区号
起始 扇区 (2713600-4194303,默认为 2713600):
将使用默认值 2713600
Last 扇区, +扇区 or +size{K,M,G} (2713600-4194303,默认为 4194303):
将使用默认值 4194303
分区 3 已设置为 Extended 类型,大小设为 723 MiB
命令(输入 m 获取帮助):p
磁盘 /dev/sdb:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x7fc5decf
设备 Boot Start End Blocks Id System <<<<<<<<<此时可以查看到sdb3这个新分的扩展区
/dev/sdb1 2048 2099199 1048576 83 Linux
/dev/sdb2 2099200 2713599 307200 83 Linux
/dev/sdb3 2713600 4194303 740352 5 Extended <<<<<<<<<83是分区的文件类型,5是扩展分区
命令(输入 m 获取帮助):n <<<<<<<<<有了扩展分区,在扩展分区里继续分逻辑区
Partition type:
p primary (2 primary, 1 extended, 1 free)
l logical (numbered from 5)
Select (default p): l 创建逻辑区 <<<<<<<<<按照提示逻辑区选l,分区号选5
添加逻辑分区 5
起始 扇区 (2715648-4194303,默认为 2715648):
将使用默认值 2715648
Last 扇区, +扇区 or +size{K,M,G} (2715648-4194303,默认为 4194303):+300M
分区 5 已设置为 Linux 类型,大小设为 300 MiB
命令(输入 m 获取帮助):w <<<<<<<<<保存并开始分区
The partition table has been altered!
Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: 设备或资源忙.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
正在同步磁盘。
[root@django_env1 ~]# fdisk /dev/sdb
欢迎使用 fdisk (util-linux 2.23.2)。
更改将停留在内存中,直到您决定将更改写入磁盘。
使用写入命令前请三思。
命令(输入 m 获取帮助):p
磁盘 /dev/sdb:2147 MB, 2147483648 字节,4194304 个扇区
Units = 扇区 of 1 * 512 = 512 bytes
扇区大小(逻辑/物理):512 字节 / 512 字节
I/O 大小(最小/最佳):512 字节 / 512 字节
磁盘标签类型:dos
磁盘标识符:0x7fc5decf
设备 Boot Start End Blocks Id System <<<<<<<<<可以看到扩展分区sdb3和sdb5逻辑分区
/dev/sdb1 2048 2099199 1048576 83 Linux
/dev/sdb2 2099200 2713599 307200 83 Linux
/dev/sdb3 2713600 4194303 740352 5 Extended
/dev/sdb5 2715648 3330047 307200 83 Linux
分区________
[root@django_env1 ~]# mkfs.ext4 /dev/sdb5 <<<<<<<<<注意这里对sdb分区完成后,格式化出现错误
mke2fs 1.42.9 (28-Dec-2013)
无法对 /dev/sdb5 进行 stat 调用 --- 没有那个文件或目录
The device apparently does not exist; did you specify it correctly?
[root@django_env1 ~]# partprobe /dev/sdb <<<<<<<<<用partprobe对sdb的分区列表重新获取后可以解决报错问题.
[root@django_env1 ~]# mkfs.ext4 /dev/sdb5 <<<<<<<<<再接着分区,显示分区成功
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=1024 (log=0)
分块大小=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
76912 inodes, 307200 blocks
15360 blocks (5.00%) reserved for the super user
第一个数据块=1
Maximum filesystem blocks=33947648
38 block groups
8192 blocks per group, 8192 fragments per group
2024 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (8192 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
永久挂载
磁盘默认不是永久挂载的,要写到配置文件(/etc/fstab)中才能开机实现挂载
配置文件最上面是系统的盘的信息,我们在下面追加配置信息 磁盘 挂载点 文件类型 默认选项 优先级 优先级
#系统的盘的信息
/dev/mapper/centos-root / xfs defaults 0 0
UUID=9a7131b7-71cf-4012-b5c4-XXXXXXXXXX /boot xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
#追加配置信息
/dev/sdb1 /mnt/disk1 ext4 defaults 0 0
/dev/sdb2 /mnt/disk2 ext4 defaults 0 0
配置完后mount -a,进行加载配置的盘符信息
卸载分区
挂载分区的步骤是分区-格式化-挂载(mount)
卸载分区的步骤是卸载(umount /dev/sdb1 /mnt/disk1),然后取消分区(fdisk中按d取消分区).
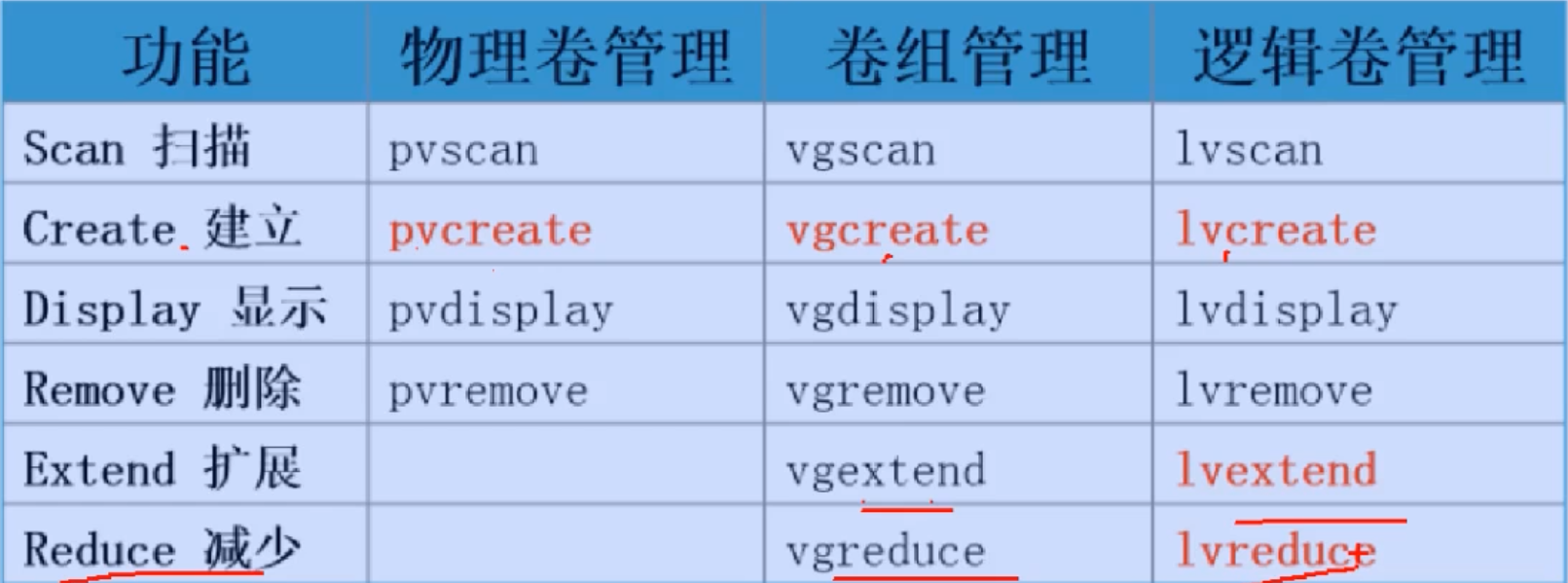
逻辑卷管理
逻辑卷(lvm logic volume manager),特点是可以随意扩张大小
PV:物理卷 (phsical volume) 一块硬盘或者多块硬盘
VG:卷组(Volume Group) 一堆磁盘的统称 比如D盘,E盘,自身没有意义,就是个代号 PV的集合
LV:逻辑卷(logical volume)一个逻辑分区,一个分区

- 创建LVM
1.1 准备新的,新的,新的物理磁盘,不要用已使用过的
1.2 pv 将物理磁盘转换成物理卷 pvcreate /dev/sdc
创建成功后可以用pvscan查看已经成功创建的物理卷
1.3 vg vgcreate vg1 /dev/sdc 这里是把/dev/sdc这块盘创建卷组命名为vg1
注意:1.2步骤可以省略,直接操作这一步,会自动执行pv的步骤
如果有多个卷组要创造 vg vgcreate vg1 /dev/sdc /dev/sdd /dev/sde
1.4 lv lvcreate -L 1G -n lv1 vg1 -L指定大小单位m,g -n卷名 vg1卷组名
1.5 创建文件系统并挂载
a. 分区 mkfs.exts /dev/卷名/卷组名 mkfs.exts /dev/vg1/lv1
b.挂载 mkdir /mnt/lv1 && mount /dev/vg1/lv1 /mnt/lv1
实际操作示例
初始的盘符信息如下
[root@django_env1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 2G 0 disk
├─sdb1 8:17 0 1G 0 part
├─sdb2 8:18 0 300M 0 part
├─sdb3 8:19 0 1K 0 part
└─sdb5 8:21 0 300M 0 part
sdc 8:32 0 2G 0 disk
sdd 8:48 0 1G 0 disk <<<<<这是我们这次的LVM创建对象
sr0 11:0 1 4.3G 0 rom
第一步 pv创建物理卷
[root@django_env1 ~]# pvcreate /dev/sdd
Physical volume "/dev/sdd" successfully created.
第二步 为该物理卷创建卷组名:myvg1
[root@django_env1 ~]# vgcreate myvg1 /dev/sdd
Volume group "myvg1" successfully created
这里可以用pvs或者pvscan查看当前的物理卷信息
[root@django_env1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdd myvg1 lvm2 a-- 1020.00m 1020.00m
第三步 在该物理卷上划分500M作为逻辑卷空间,该逻辑卷命名为mylv1
[root@django_env1 ~]# lvcreate -L 500M -n mylv1 myvg1
Logical volume "mylv1" created.
第四步 对该逻辑卷进行格式化,mkfs.ext4 /dev/逻辑卷组名/逻辑卷名
[root@django_env1 ~]# mkfs.ext4 /dev/myvg1/mylv1
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=1024 (log=0)
分块大小=1024 (log=0)
Stride=0 blocks, Stripe width=0 blocks
128016 inodes, 512000 blocks
25600 blocks (5.00%) reserved for the super user
第一个数据块=1
Maximum filesystem blocks=34078720
63 block groups
8192 blocks per group, 8192 fragments per group
2032 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729, 204801, 221185, 401409
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (8192 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
第五步 mnt创建文件夹,进行挂载
[root@django_env1 ~]# mkdir -p /mnt/myvg1_disk1
[root@django_env1 ~]# mount /dev/myvg1/mylv1 /mnt/myvg1_disk1
使用df或者lsblk查看挂载的逻辑卷
[root@django_env1 ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 17G 3.3G 14G 20% /
devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 2.0G 12M 2.0G 1% /run
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 146M 869M 15% /boot
tmpfs tmpfs 406M 0 406M 0% /run/user/0
/dev/mapper/myvg1-mylv1 ext4 477M 2.3M 445M 1% /mnt/myvg1_disk1 <<<<<<<<新挂的逻辑卷
[root@django_env1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 20G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 19G 0 part
├─centos-root 253:0 0 17G 0 lvm /
└─centos-swap 253:1 0 2G 0 lvm [SWAP]
sdb 8:16 0 2G 0 disk
├─sdb1 8:17 0 1G 0 part
├─sdb2 8:18 0 300M 0 part
├─sdb3 8:19 0 1K 0 part
└─sdb5 8:21 0 300M 0 part
sdc 8:32 0 2G 0 disk
sdd 8:48 0 1G 0 disk
└─myvg1-mylv1 253:2 0 500M 0 lvm /mnt/myvg1_disk1 <<<<<<<<新挂的逻辑卷
sr0 11:0 1 4.3G 0 rom
逻辑卷扩容
扩容前,我们先用一条命令模拟磁盘爆满 dd if=/dev/zero of=/mnt/myvg1_disk1/1.txt bs=1M count=1200
命令参数解释如下
if=/dev/zero 从/dev/zero读,/dev/zero 是一个特殊的文件,当你读它的时候,它会提供无限的空字符(NULL, ASCII NUL, 0x00)
of=/mnt/disk1/1.txt 写到/mnt/disk1/1.txt中区
bs=1M 一次读和写 1M
count=1200 持续读写1200次 一共写入1.2G内容
此时看mylv1这个逻辑区的空间 /dev/mapper/myvg1-mylv1 ext4 477M 473M 0 100% /mnt/myvg1_disk1
通过vgs命令看到该逻辑卷还有520M空间,我们进行扩容.
这一步必看.如果自身逻辑卷有空间,就自身扩容.如果自身用完了才考虑把其他盘加入到卷组里扩容
[root@django_env1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
myvg1 1 1 0 wz--n- 1020.00m 520.00m
接下来用lvextend对逻辑卷空间进行扩容 缩容用lvreduce
- lvextend -L +50M /dev/vg1/lv1 命令意思就是给/dev/vg1/lv1增加50M的空间
- lvextend 做完后,使用df -h 命令还是看不出容量有增加,此时需要刷新下
- resize2fs /dev/vg1/lv1 刷新后 使用df -h就可以看到磁盘空间容量刷新了
用命令扩容50M
[root@django_env1 ~]# lvextend -L +50M /dev/myvg1//mylv1
Rounding size to boundary between physical extents: 52.00 MiB.
Size of logical volume myvg1/mylv1 changed from 520.00 MiB (130 extents) to 572.00 MiB (143 extents).
Logical volume myvg1/mylv1 successfully resized.
此时看到容量只有496M
[root@django_env1 ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 17G 3.3G 14G 20% /
/dev/sda1 xfs 1014M 146M 869M 15% /boot
/dev/mapper/myvg1-mylv1 ext4 496M 473M 0 100% /mnt/myvg1_disk1
用resize2fs进行刷新
[root@django_env1 ~]# resize2fs /dev/myvg1/mylv1
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/myvg1/mylv1 is mounted on /mnt/myvg1_disk1; on-line resizing required
old_desc_blocks = 5, new_desc_blocks = 5
The filesystem on /dev/myvg1/mylv1 is now 585728 blocks long.
此时看到容量就有546M
[root@django_env1 ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 3.3G 14G 20% /
/dev/sda1 1014M 146M 869M 15% /boot
/dev/mapper/myvg1-mylv1 546M 473M 43M 92% /mnt/myvg1_disk1
卷组管理
逻辑卷如果本身物理空间足够,是可以用上述进行逻辑卷扩容的.但是如果该盘自身物理空间满了,就需要将新的空盘纳入到逻辑卷组中来,实现对原逻辑卷的扩容
- 创建PV,pvcreate /dev/sdd
- 扩展VG vgextend vg1 /dev/sdd
- 查看VG vgs 可以看到vg1这个卷组容量是否增加
- 接下来就如同上面一样,从自己的卷组中扩容 lvextend -L +100M /dev/myvg1/mylv1
- 刷新磁盘空间 resize2fs /dev/myvg1/mylv1
实际操作示例
首先先看vgs信息,逻辑卷组myvg1一共1020M 剩余448,使用了
[root@django_env1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
myvg1 1 1 0 wz--n- 1020.00m 448.00m
pvs显示物理卷只有2个
[root@django_env1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdd myvg1 lvm2 a-- 1020.00m 448.00m
这里创建新的物理卷sdc
[root@django_env1 ~]# pvcreate /dev/sdc
Physical volume "/dev/sdc" successfully created.
pvs显示了新的sdc物理卷
[root@django_env1 ~]# pvs
PV VG Fmt Attr PSize PFree
/dev/sda2 centos lvm2 a-- <19.00g 0
/dev/sdc myvg1 lvm2 a-- <2.00g <2.00g
/dev/sdd myvg1 lvm2 a-- 1020.00m 448.00m
第一步 vgextend 命令扩容逻辑卷组 myvg1
[root@django_env1 ~]# vgextend myvg1 /dev/sdc
Volume group "myvg1" successfully extended
vgs可以看到Vsize从开始的1020M增长到了2.99G
[root@django_env1 ~]# vgs
VG #PV #LV #SN Attr VSize VFree
centos 1 2 0 wz--n- <19.00g 0
myvg1 2 1 0 wz--n- 2.99g 2.43g
第二步 从逻辑卷组中拿空间扩容
[root@django_env1 ~]# lvextend -L +100M /dev/myvg1/mylv1
Size of logical volume myvg1/mylv1 changed from 572.00 MiB (143 extents) to 672.00 MiB (168 extents).
Logical volume myvg1/mylv1 successfully resized.
第三部 刷新磁盘空间
[root@django_env1 ~]# resize2fs /dev/myvg1/mylv1
resize2fs 1.42.9 (28-Dec-2013)
Filesystem at /dev/myvg1/mylv1 is mounted on /mnt/myvg1_disk1; on-line resizing required
old_desc_blocks = 5, new_desc_blocks = 6
The filesystem on /dev/myvg1/mylv1 is now 688128 blocks long.
查看mylv1空间从546M增长到了643M
[root@django_env1 ~]# df -hT
文件系统 类型 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root xfs 17G 3.3G 14G 20% /
devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 2.0G 12M 2.0G 1% /run
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 xfs 1014M 146M 869M 15% /boot
tmpfs tmpfs 406M 0 406M 0% /run/user/0
/dev/mapper/myvg1-mylv1 ext4 643M 473M 135M 78% /mnt/myvg1_disk1
lvm原理 以及lvm常用命令
常用命令
lvm原理
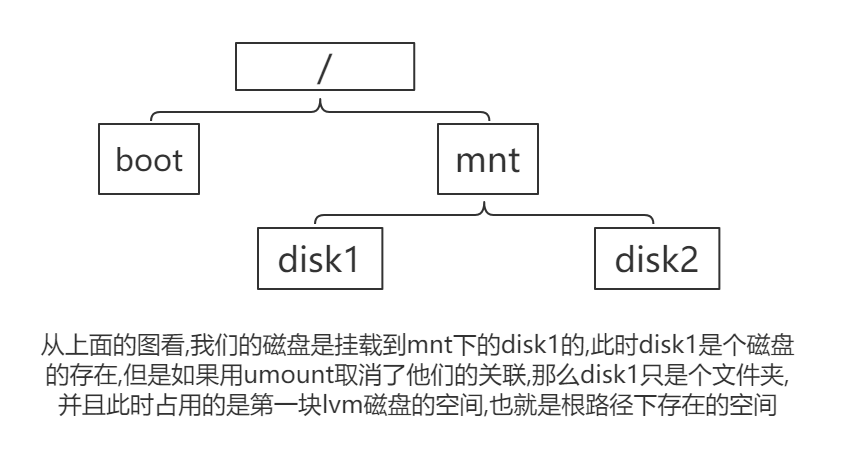
解除mnt磁盘的挂载
[root@django_env1 myvg1_disk1]# umount /dev/myvg1/mylv1 /mnt/myvg1_disk1
查看此时的文件使用量,看解除挂载后,文件写入到/mnt/myvg1_disk1占用的是哪个磁盘的空间
[root@django_env1 /]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 3.3G 14G 20% / <<<<<<<<<<<<<<注意这个第一块盘的空间
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 12M 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 1014M 146M 869M 15% /boot
tmpfs 406M 0 406M 0% /run/user/0
写入700M数据到/mnt/myvg1_disk1/2.txt
[root@django_env1 /]# dd if=/dev/zero of=/mnt/myvg1_disk1/2.txt bs=1M count=700
记录了700+0 的读入
记录了700+0 的写出
734003200字节(734 MB)已复制,3.47115 秒,211 MB/秒
[root@django_env1 /]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/centos-root 17G 4.0G 14G 24% / <<<<<<<<<<<<<<和上面比多了700MB的空间
devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs 2.0G 12M 2.0G 1% /run
tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/sda1 1014M 146M 869M 15% /boot
tmpfs 406M 0 406M 0% /run/user/0
[root@django_env1 /]# mount /dev/myvg1/mylv1 /mnt/myvg1_disk1
swap交换分区
交换分区的大小可以用free -m查看,可以看到此时交换分区是2047M
total used free shared buff/cache available
Mem: 4057 133 3008 11 915 3646
Swap: 2047 0 2047
新增交换分区的步骤
- 准备分区
1.1 准备/dev/sde磁盘,划分1G fdisk /dev/sde(和普通分区一样,选择主分区)
1.2 分区完毕后按t将类型设置82, 82是交换分区的代码(就是第一步完成后不要退出fdisk,直接按t输入82)
1.3 重新读取sde的分区表 partprobe /dev/sde
1.4 查看下分区是否完成 ll /dev/sde* - 格式化
2.1 mkswap /dev/sde1 - 挂载
3.1 swapon /dev/sde1
如果要取消交换分区
- 先swapoff /dev/sde1
- fdisk /dev/sde里取消分区即可
centos安装时候的自定义分区
centos安装时候有个自定义分区的功能
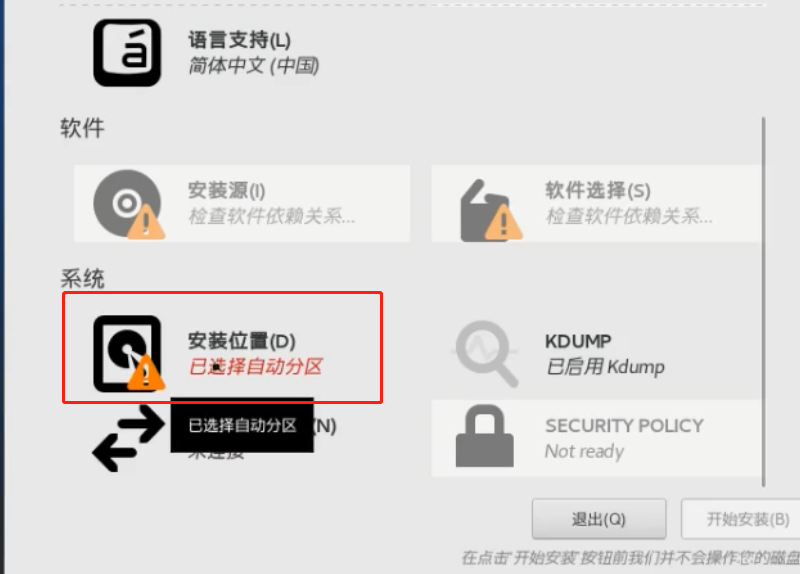
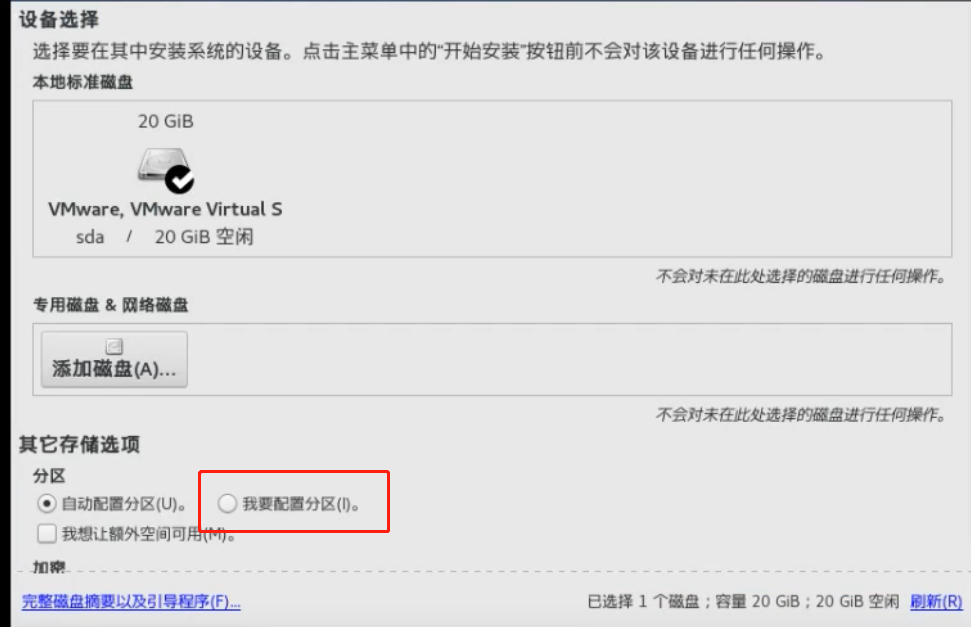
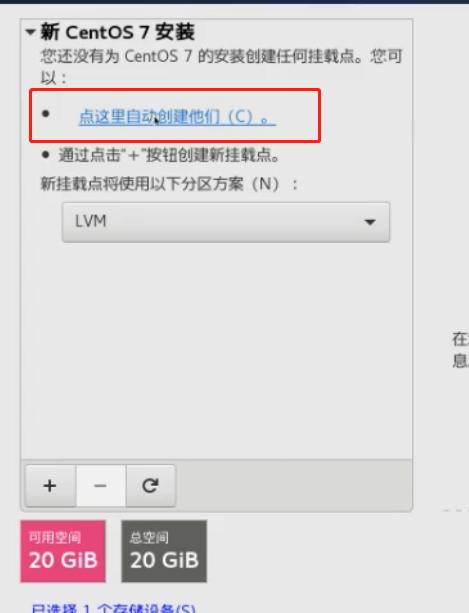
默认的都是一个根路径(/),一个swap分区,一个/boot引导分区
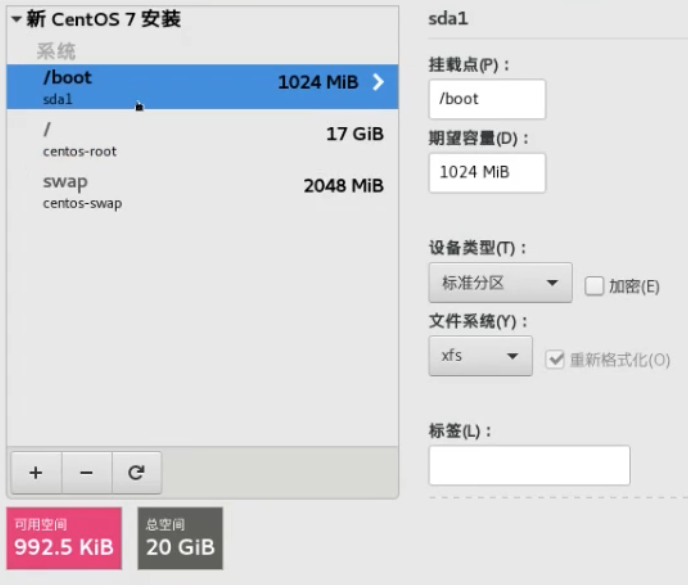
我们可以根据情况自定义分区,下面考虑到var下面挂载数据库,home下面有用户数据,因此独立划分了各自的分区
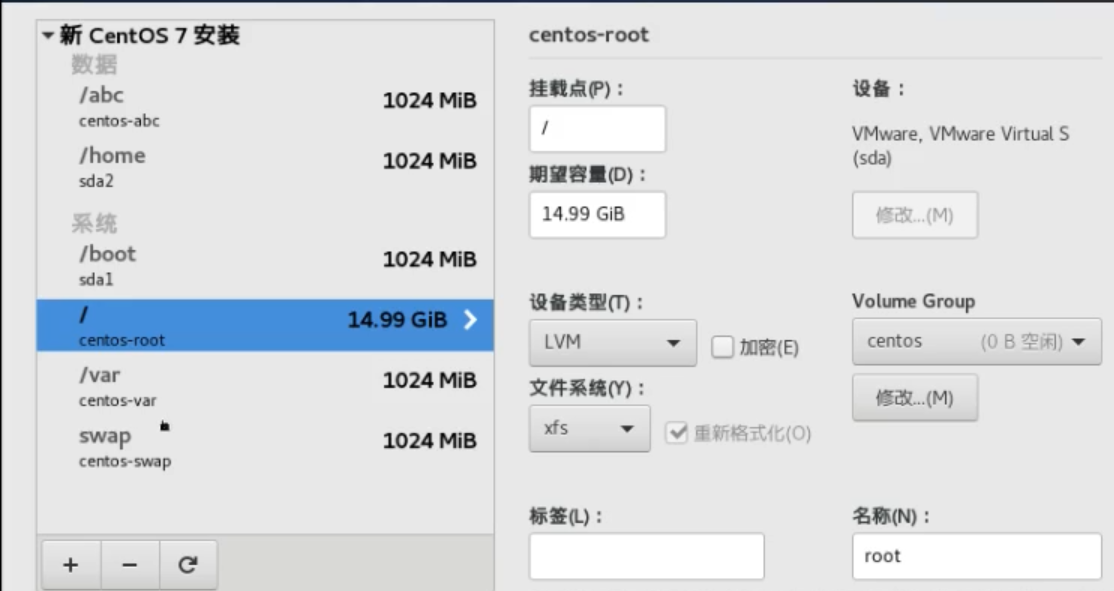
文件系统
文件系统简介
EXT4 是第四代扩展文件系统
XFS 是高性能的日志文件系统 支持的磁盘更大
他们都是索引文件系统
系统限制
EXT3 文件系统最大16T
EXT4 文件系统最大16T
XFS 文件系统最大100T
文件系统inode原理分析
inode是指index+node的意思,中文叫法是索引节点
inode 记录文件的属性(文件的元数据metadata)
文件的元数据 指的是文件的属性,大小,权限,属主,属组,连接数,块数量,块编号等
一个文件占用一个inode,同时记录此文件所在的block number
inode大小为128bytes
df -i 参数就可以看到剩余可用的索引节点 inode决定了文件系统中的文件数量
003.文件系统block原理分析
block
存储文件的实际数据
实际存储文件的内容,大文件占用多个block,block默认大小为4k
总结:block是根据文件内容决定的,inode是根据可使用的文件元数据来的.两者限制是相互独立的.
在磁盘写满的情况下,如果inode未消耗完,是可以继续创建文件的,只是无法写入内容.
如果在磁盘没满情况下,虽然文件数量消耗完,但是还是可以向文件内写入内容的
实验
/dev/mapper/myvg1-mylv1 已经提前消耗完了inode
[root@django_env1 ~]# df -i
文件系统 Inode 已用(I) 可用(I) 已用(I)% 挂载点
/dev/mapper/myvg1-mylv1 170688 170688 0 100% /mnt/myvg1_disk1
此时可以看到无法创建新文件
[root@django_env1 /]# touch /mnt/myvg1_disk1/test.txt
touch: 无法创建"/mnt/myvg1_disk1/test.txt": 设备上没有空间
但是可以向文件中继续写入数据
[root@django_env1 /]# echo "dwadwadawdawaaaaaaaaaaaaaaa a" > /mnt/myvg1_disk1/w1611
软连接示例
ln -s file_pth link_pth
硬链接文件
- 创建同分区硬链接成功,不同分区失败,必须在同一分区内创建
比如前面挂载的知识学到的,/根分区和/mnt/disk1 就是2个不同的分区, 可以用df -h查看挂载点是否在同一个 - 硬链接删除源文件,依然可以用
- 不允许将硬链接指向目录,只能指向文件
RAID类型和原理解析
- RAID0 条带集 2块盘以上 读写速度块 读写效率是盘数*100% ,但是不容错,把数据拆2份写入,但是其中一份有问题,另一份也读不出来
- RAID1 镜像集 2块盘以上 读写速度一般,用来备份容错,一块盘的数据会拷贝给另一份
- RAID5 功能可以实现高速读写和容错,实现起来至少要三个盘,带奇偶校验条带集。原理 ABC三块盘,把数据拆2分,写入A,B,在C写入校验的内容。因为校验是基于A,B两块盘的数据算法,因此C写入会比A B慢,因此下一次写入会把数据拆分写入A,C两块盘,然后B写入校验内容,再下一次是BC写入数据,A写入校验内容。 如果有一块盘数据有问题,可以换掉,通过其他2块盘的校验算法,可以恢复数据出来,实现容错
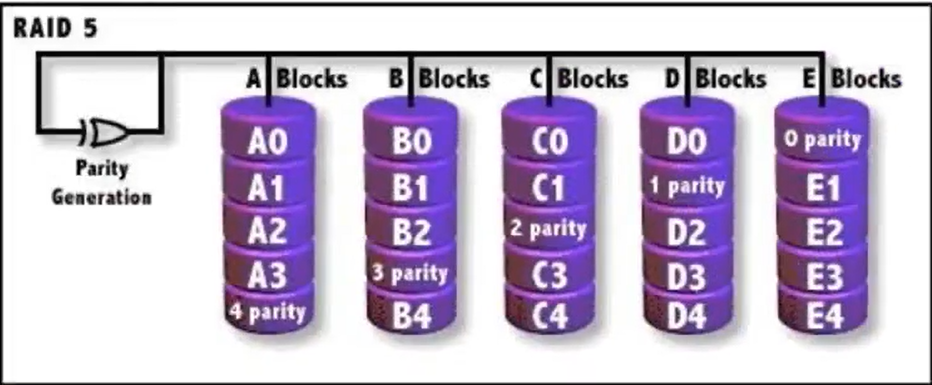
- RAID6 和5比多了一块逻辑校验盘,也就是AB写数据,CD校验内容,具有双重数据校验,因此运算负担较大,实现较复杂。通常RAID 6读写性能不如RAID 5
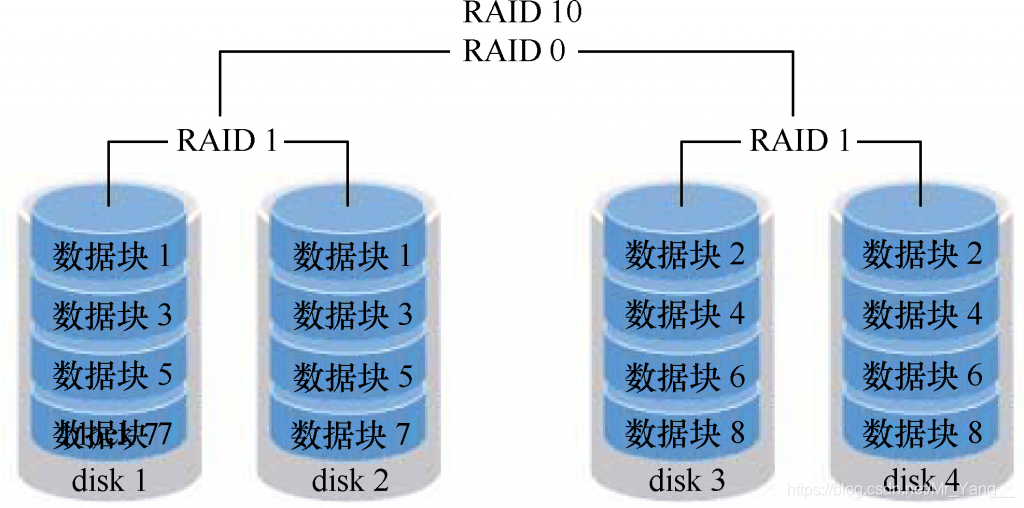
- RAID10 RAID50 是指 RAID1和RAID0的组合搭配,RAID50是指RAID0和RAID5的组合搭配
RAID 10 不是独创的一种RAID级别,它由RAID 1 和 RAID 0 两种阵列形式组合而成,RAID 10继承了RAID 0 的快速与高效,同时也继承了RAID 1 的数据安全,RAID 10 至少需要四块硬盘。RAID 1+0,先使用四块硬盘组合成两个独立的RAID 1 ,然后将两个RAID 1 组合成一个RAID 0。需要注意Raid 10 和 Raid01的区别,RAID01又称为RAID0+1,先进行条带存放(RAID0),再进行镜像(RAID1),而RAID10又称为RAID1+0,先进行镜像(RAID1),再进行条带存放(RAID0)。组成RAID 10 至少需要四块磁盘,是在实际应用中较为常见阵列形式。
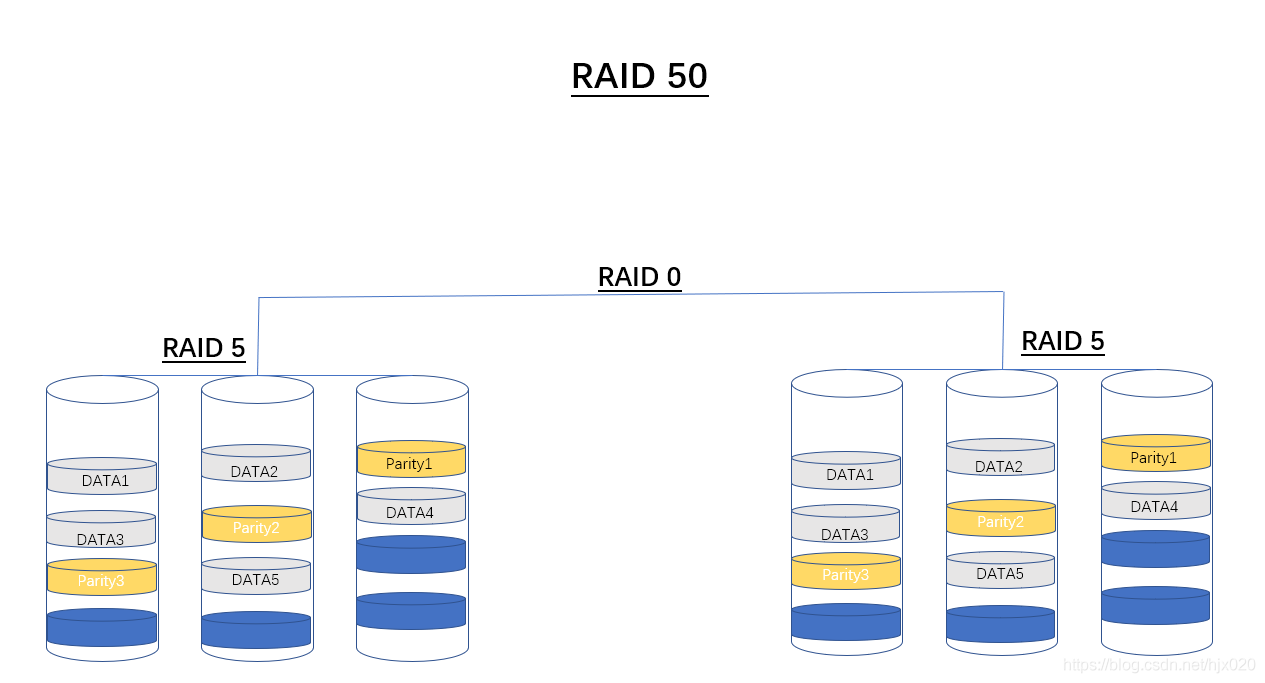
RAID50是RAID5与RAID0的结合。此配置在RAID5的子磁盘组的每个磁盘上进行包括奇偶信息在内的数据的剥离。每个RAID5子磁盘组要求至少三个硬盘。RAID50具备更高的容错能力,因为它允许某个组内有一个磁盘出现故障,而不会造成数据丢失。而且因为奇偶位分部于RAID5子磁盘组上,故重建速度有很大提高。它最适合需要高可靠性存储、高读取速度、高数据传输性能的应用。如大型数据库服务器、应用服务器、文件服务器等。
工作原理:如下图1-6所示,它由两组RAID 5磁盘组成(每组最少3个),每一组都使用了分布式奇偶位,而两组硬盘再组建成RAID 0,实现跨磁盘抽取数据,RAID 50最少需要6个磁盘。
同时RAID按照不同场景还分软RAID和硬RAID

软RAID实战
软RAID实现
- 准备4块盘或者3块盘 4块的话 2块写数据,1块写校验,另一块作为热备
- 创建RAID mdadm -C /dev/md0 -l5 -n3 -x1 /dev/sd{d,e,f,g}
命令拆分
RAID mdadm -C /dev/md0 -C创建RAID /dev/md0是自定义创建磁盘阵列的一个路径
-l5 l5代表level 5 也就是RAID5
-n3 n3代表 三块组成磁盘阵列的
-x1 x1 代表一个热备硬盘
/dev/sd{d,e,f,g} 写入组成硬盘阵列的4个硬盘分区
- 格式化
mkfs.ext4 /dev/md0 - 挂载
mkdir /mnt/raid5 && mount /dev/md0 /mnt/raid5 - 查看此次RAID5硬盘阵列的详细信息

下面是个模拟磁盘阵列损坏的实验,谨慎操作
弄2个终端,一个监控,一个进行移除操作
终端1 使用watch命令持续查看
watch -n 0.5 'mdadm -D /dev/md0 |tail'
终端2 使用-f参数将其中一块盘设定未故障状态 -r是移除该盘符
mdadm /dev/md0 -f /dev/sde -r /dev/sde
001.Linux系统配置及服务管理_第08章_文件查找简介
文件查找
which/whereis: 命令查找 速度最快,查找内容最少,从环境变量查找
locate: 文件查找,依赖数据库,新创建的文件找不到,要更新数据库才能找到
更新数据库 有2种 1.重启 2.updatedb命令
find: 文件查找,针对文件名
002.Linux系统配置及服务管理_第08章_文件查找find
find 常用参数示例
find /etc/ -name "hosts"
linux是区分大小写的,-i可以忽略大小写
find /etc/ -iname "hosts"
size 查询大小 -size n[cwbkMG] +5M是大于5M的意思
find /etc/ -size +5M
-maxdepth 查找最大目录层数 如 2,即只查找2层目录,下面查找的 一定是/etc/XXX/hosts的路径
find /etc/ -name "hosts" -maxdepth 2
-user -group 按照文件的属主和属组查询
find /etc/ -user jack
-type 按照文件类型查找 类型有f,b,d,p,l 分别对应文件,设备文件,目录,管道,链接文件
find /dev -type b -name "sd*"
-perm permission的意思 按照文件权限查找 下面是查找文件权限是714(rwx,x,r)的文件
find /etc/ -perm 714 精确匹配就是找权限为714的文件夹
find /etc/ -perm -714 3个权限位都必须至少匹配指定的714
find /etc/ -perm /714 松散匹配 3个权限位任意一个匹配指定的权限,不管其他位如何设置,417,741都会匹配上
find还可以跟后续处理,实现查找后的处理 形式很多,-print,-printf,-print0,-exec,-ok,-ls,-delete
-ok 和- exec的作用相同,只不过和会人交互而已,OK执行前会向你确认是不是要执行。 比如下面找到后会展示文件的详情
find /etc/ -perm 714 -ok -ls;
除了上述自带的参数,find还可以用-exec -ok去接其他linux命令。相应命令的形式为' 命令 - and' {} ;,注意{ }和\;之间的空格。
{} ; 是固定格式,用来对前面find的返回值进行传参的,下面的命令会把当前路径下权限为644的文件找出来并删除
find ./ -perm 644 -exec rm -f {} ;
003.Linux系统配置及服务管理_第08章_文件压缩原理
去重压缩法,把重复的数据设置变量代替.所以对日志压缩效果会很好
004.Linux系统配置及服务管理_第08章_文件解压缩和测试压缩
打包格式
tar 选项 生成压缩包路径 被压缩的源数据
解包
tar 选项 压缩包路径 选项 释放路径
普通解压和压缩用-cf -xf 这里的f参数必须在最后
tar -cf XXX.tar /etc
tar -xf XXX.tar
tar -xf XXX.tar -C /opt/newfolder
另外压缩模式也有几种常用的 -z gzip ; -j bzip ; -J xzip, 压缩效果xzip最强,耗时高,gzip性价比较高,比较常用
tar -czvf abg.tar.gz /etc

Linux安装
RPM
RPM (原Red Hat Package Manager) 也称二进制 无须编译,可以直接使用
linux 的安装包是rpm等同于windows的exe
一般正常RMP包是这样的
wget-1.14-15.el7.x86_64.rpm
zip-3.0-11.el7.x86_64.rpm
zip-3.0-11 是软件的包名和版本号
el7是发布版本代表支持红帽的第几代系统,RHEL(red hat enterprise linux) 红帽子企业版
x86_64 系统架构版本
RPM的管理工具主要是两个工具 YUM和RPM
RPM工具详解
RPM工具包
红帽系统特有的RPM工具,优点是不用配置,缺点是无法解决依赖关系,无法自行下载软件包
安装(i)
rpm -ih 包名 h参数是显示进度条的 包名要绝对路径
rpm -ivh /mnt/cdrom/Packages/wget-1.14-18.el17.x86_64.rpm
查询(q)
rpm -q 包名
卸载(e)
rpm -e 包名 注意卸载的时候包名不要带.rpm 因为.rpm是个包而不是一个已经被安装的程序
rpm -e wget 是wget不是wget-1.14-18.el17.x86_64.rpm
YUM指令

YUM本地仓库和阿里仓库
yum查看依赖 可以用provides命令 yum provides vim
从下面的结果可以看到vim的依赖是 vim-enhanced-7.4.629-7.el7.x86_64,如果yum安装不正常,可以自行安装vim-enhanced这个包,有时候带后面版本信息可能会安装不正常.
[root@django_env2 ~]# yum provides vim
已加载插件:fastestmirror
Repodata is over 2 weeks old. Install yum-cron? Or run: yum makecache fast
Determining fastest mirrors
* base: mirrors.aliyun.com
* extras: mirrors.aliyun.com
* updates: mirrors.aliyun.com
2:vim-enhanced-7.4.629-7.el7.x86_64 : A version of the VIM editor which includes recent enhancements
源 :base
匹配来源:
提供 :vim = 7.4.629-7.el7
2:vim-enhanced-7.4.629-8.el7_9.x86_64 : A version of the VIM editor which includes recent enhancements
源 :updates
匹配来源:
提供 :vim = 7.4.629-8.el7_9
yum和epel配置源
配置YUM仓库/YUM源
-
yum install wget
-
备份原生的yum源 mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.bak
-
下载阿里或者其他第三方yum源
-
更新yum缓存 yum makecache
-
查看第三方的yum提供包数量 yum repolist 从源名字可以判断是否更新成功
配置EPEL
EPEL(extra packages for Enterprise Linux)是企业版linux额外软件包
- 备份原生的epel源
mv /etc/yum.repos.d/epel.repo /etc/yum.repos.d/epel.repo.bak
2.下载第三方的到 /etc/yum.repos.d/
第二步可能和RHEL版本不同操作也不同,具体根据官网指示
为了加深印象YUM仓库是什么,我们设置一个本地源来做实验.
- 备份(略)
- 手动写一个配置文件test.repo格式如下
[test] #yum源文件名字 自定义
name=local_yum_name #yum源名字 自定义
baseurl=file:///mnt/cdrom baseurl是关键字,因为读取光盘内的包数据,都是在cdrom下的Packages文件夹中
///要这么看file:// /mnt/cdrom
gpgcheck=0 gpgcheck 类似于包的校验,0是关闭,1是开启
- 通过查看光驱文件ll /dev/cdrom 可以看到是链接文件指向sr0,说明实际路径是/dev/sr0
[root@django_env2 yum.repos.d]# ll /dev/cdrom
lrwxrwxrwx. 1 root root 3 5月 21 14:45 /dev/cdrom -> sr0
-
挂载光驱
mkdir /mnt/cdrom
mount /dev/cdrom /mnt/cdrom 或者 mount /dev/sr0 /mnt/cdrom 都可以 -
查看本地源是否可用
如果挂载成功ls /mnt/cdrom/Packages/|head -5是可以看到本地镜像文件中的包内容的
[root@django_env2 yum.repos.d]# ls /mnt/cdrom/Packages/|head -5
389-ds-base-1.3.8.4-15.el7.x86_64.rpm
389-ds-base-libs-1.3.8.4-15.el7.x86_64.rpm
abattis-cantarell-fonts-0.0.25-1.el7.noarch.rpm
abrt-2.1.11-52.el7.centos.x86_64.rpm
abrt-addon-ccpp-2.1.11-52.el7.centos.x86_64.rpm
也可以yum repolist看到本地yum仓库设置是否成功,下面的信息代表本地源仓库内有4021个包的内容
[root@django_env2 yum.repos.d]# yum repolist
已加载插件:fastestmirror
Loading mirror speeds from cached hostfile
源标识 源名称 状态
test local_yum_name 4,021
源码包安装
源码包安装
源码包里面是高级语言,必须要转换成二进制的计算机语言才能使用,需要GCC,C++编译安装,对比RPM包,可以自定义功能需要,而RPM包是别人已经设定好功能编译后的.
- 官网获取源码包 一般都是压缩文件
- 配置 ./configure --user=alex --group=alex --prefix=/opt/nginx/
- 编译安装 make&&make install
- 安装路径下bin文件中运行启动 可能涉及防火墙关闭
Linux计划任务
一次性调度执行 at
语法格式 at timespec
timespec 示例
now +5min 5分钟后
teatime tomorrow (teatime默认是16:00)
noon +4 days 4天后中午
5pm auguest 3 2029 2029年8.3号下午5点
4:00 2019-11-27 2019年11月27号下午4点
设置定时任务
[root@django_env2 tengine]# at now +1 min
at> useradd young1
at>
问题:
下面提示是因为at安装后未运行 systemctl start atd
Can't open /var/run/atd.pid to signal atd. No atd running?
周期性计划任务cron
cron的计划任务都是存放在/etc/crontab文件中
cron要使用必须要有crond服务,crond是计划任务执行的根本
没的话 需要安装 yum install -y crontabs
查看下systemctl status crond.service
ps -aux|grep crond
计划任务查看
系统级别的计划任务是cat /etc/crontab查看
用户级别的计划任务是crontab -l 查看 任务的文件路径在/var/spool/cron里
编辑创建计划 使用cron -e
cron的设置
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
定时设置主要是分时日月周,其中日和周是互斥的,要注意这点
语法格式 分 时 日 月 周 命令或者脚本 6个参数必须用空格间隔,*代表任意,脚本或者命令要写完整路径.
示例
0 * * * * /mysql_back.sh 每个整点运行 比如1点 2点 分钟为0的时候,一天运行24次
*/5 * * * * /mysql_back.sh */5 代表每5分钟 /代表每**
0 2 1,4,6 * * /mysql_back.sh 任意月的1 4 6号的2:00
0 2 5-9 * * /mysql_back.sh 任意月的5到9号的2:00
* * * * * /mysql_back.sh 每分钟执行
0 2 * * * /mysql_back.sh 每天2:00
0 2 2 6 5 /mysql_back.sh 周和日都写很少见,但是执行会都生效,也就是6月2号2:00会执行,然后6月的每周五2:00也执行
周期性计划任务systemd 服务
systemd 实际是通过定义一个timer单元来创建一个定时任务。它包含了两大内容,首先定义一个service单元,这个service单元定义了我们想定时执行的任务。然后再定义一个timer单元,通过timer单元定义定时规则去执行之前的service单元。
创建的服务单元和timer单元会放在/usr/lib/systemd/system路径下
- 创建定时脚本
首先我们创建一个脚本叫做 now_time.sh,脚本内容就是输出当时的时间:
cat <<EOF >/opt/now_time.sh
#!/bin/bash
echo "$(date)" >>/tmp/time_record.log
EOF
chmod 755 /opt/now_time.sh # 注意一定要更改权限,否则后面会由于没有执行权限而报错
- 创建 Service 单元
然后需要创建一个 Service单元 timerecord
cat <<EOF >/usr/lib/systemd/system/timerecord.service
[Unit]
Description=now time service
[Service]
ExecStart=/opt/now_time.sh
[Install]
WantedBy=multi-user.target
EOF
- 然后把 timerecord 作为系统服务。
systemctl start timerecord
- 创建 Timer 单元
在创建 Timer单元前,我们需要先了解下如何配置 Timer,
[Unit] # 定义元数据
[Timer] #定义定时器
OnActiveSec:定时器生效后,多少时间开始执行任务
OnBootSec:系统启动后,多少时间开始执行任务
OnStartupSec:Systemd 进程启动后,多少时间开始执行任务
OnUnitActiveSec:该单元上次执行后,等多少时间再次执行
OnUnitInactiveSec: 定时器上次关闭后多少时间,再次执行
OnCalendar:基于绝对时间,而不是相对时间执行,用于和 crond 类似的定时任务 ,以实际时间执行。
AccuracySec:如果因为各种原因,任务必须推迟执行,推迟的最大秒数,默认是60秒
Unit:真正要执行的任务,默认是同名的带有.service后缀的单元
Persistent:如果设置了该字段,即使定时器到时没有启动,也会自动执行相应的单元
WakeSystem:如果系统休眠,是否自动唤醒系统
示例:
在系统启动15分钟后启动,并在系统运行时,每周启动一次。
[Unit]
Description=Run foo weekly and on boot
[Timer]
OnBootSec=15min
OnUnitActiveSec=1w
[Install]
WantedBy=timers.target
每周执行一次(周一凌晨0点)。激活后,如果错过了上次启动时间,,它会立即触发服务,例如由于系统断电:
[Unit]
Description=Run foo weekly
[Timer]
OnCalendar=weekly
Persistent=true
[Install]
WantedBy=timers.target
每天周一下午3点10分运行
如果需要具体的时间,我们可以给OnCalendar 设定具体时间值,形如 Year-Month-Day Hour:Minute:Second
[Unit]
Description=Run timerecord on Monday 3:10
[Timer]
OnCalendar=Mon *-*-* 15:10:00
Unit=timerecord
[Install]
WantedBy=timers.target
每隔5秒执行一次
[Unit]
Description=Run timerecord every 5s
[Timer]
OnUnitActiveSec=5s # 可以设置为 5m,1h
Unit=timerecord
[Install]
WantedBy=timers.target
每个小时的每隔10分钟 进行备份服务
[Unit]
Description=backup
[Timer]
OnCalendar=*-*-* 0/1:0/10:00
Unit=backup
[Install]
WantedBy=multi-user.target
创建 Timer 单元 record:每隔1分钟执行一次
cat <<EOF > /usr/lib/systemd/system/timerecord.timer
[Unit]
Description=Run timerecord every 5s
[Timer]
OnUnitActiveSec=1m # 可以设置为 5m,1h
Unit=timerecord #指定 Service 服务名
[Install]
WantedBy=timers.target
EOF
启用定时任务
systemctl daemon-reload #重新加载配置
systemctl start timerecord.timer # 启动定时任务
常用命令查询参考
systemctl start timerecord.timer# 启动定时任务
systemctl stop timerecord.timer# 暂停定时任务
systemctl status timerecord.timer# 查看定时任务服务状态
systemctl restart timerecord.timer# 重启定时任务状态
systemctl list-timers --all # 查看定时任务列表
systemctl daemon-reload # 更改了配置文件后,需要重新加载
journalctl -u mytimer.timer # 查看 mytimer.timer 的日志
journalctl -u mytimer # 查看 mytimer.timer 和 mytimer.service 的日志
journalctl -f # 从结尾开始查看最新日志
journalctl -f -u timer.timer # 从结尾开始查看 mytimer.timer 的日志
Linux日志
rsyslogd 处理绝大部分日志记录
系统操作相关的信息,如登陆信息,程序启动关闭信息,错误信息
所有日志都在/var/log下

rsyslogd 默认是安装的.也可以自行安装yum install rsyslog
启动:systemctl start rsyslog.service
rsyslogd相关配置文件路径可以用rpm -qc rsyslog查询
- /etc/rsyslog.conf rsyslogd的主配文件
主配文件里有rules 有三部分组成 设备.级别 存放位置,设备只系统对某些类型的APP事件的定义,比如 authpriv是安全事件,mail是邮件事件
# The authpriv file has restricted access.
authpriv.* /var/log/secure
# Log all the mail messages in one place.
mail.* -/var/log/maillog
# Log cron stuff
cron.* /var/log/cron
# Everybody gets emergency messages
*.emerg :omusrmsg:*
常见的级别分类如图

- /etc/logrotate.d/syslog 和日志轮转相关
为了节约空间和整理方便 日志文件经常需要按照时间或者大小等维度分成多份
- 安装logrotate模块可以实现日志的自动轮转
yum install -y logrotate - 配置文件
- 主配置文件/etc/logrotate.conf 决定了每个日志文件如何轮转
- 子配置文件/etc/logrotate.d/* 自定义配置,方便管理
- 配置参数详解
weekly 轮转的周期,一周轮转 rotate 4 保留4分 create 轮转后创建新文件 dateext 使用日期作为后缀 date ext(extend) include /etc/logrotate.d 包含该目录下的子配置文件 /var/log/wtmp { 对某日志文件设置的轮转方法 monthly 上面可以理解为全局配置,这里是专属配置,如果冲突,优先使用专属配置 create 0664 root utmp 创建新文件 权限664 属主root属组utmp minsize 1M monthly和minisize同时符合才轮转 rotate 1 保留4分 } /var/log/btmp { missingok 丢失不提示 monthly create 0600 root utmp rotate 1 notifempty 空文件不轮转 maxsize 30k 达到30k就轮转,和monthly是或关系 # daily 每天轮转 #yearly 每年轮转 } - 轮转的时间轴操作记录在
/var/lib/logrotate/logrotate.status里,开机也会去里面检查时间和轮转规则,如果符合轮转,则会自动轮转操作日志
- /etc/sysconfig/rsyslog rsyslogd定义级别
其他应用程序的日志
比如我们修改一个SSH配置文件的日志产生记录路径,比如SSH的服务端配置文件在/etc/ssh/sshd_config
默认字段SyslogFacility AUTHPRIV 对应着 /etc/rsyslog.conf 的 authpriv.* /var/log/secure字段
我们重新设置SSH配置文件如下图的对应关系,注意sshd配置文件的SyslogFacility的设备名不能乱取,否则会重启失败影响SSH登陆,用LOCAL数字形式

然后重启rsyslog和SSHD的服务systemctl restart rsyslog.service sshd
用ssh登陆一下,就可以看到自定义的ssh日志在rsyslog的配置中生效了
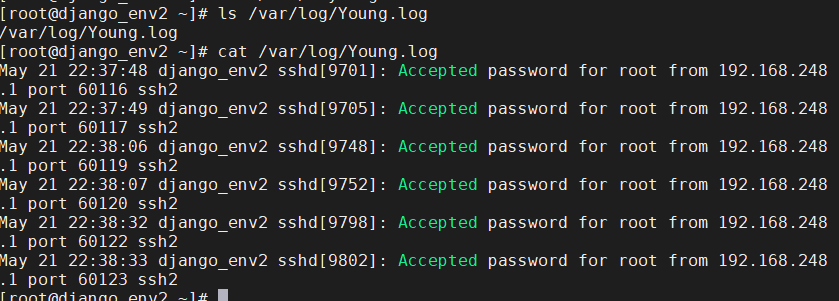
Linux网络
网络的2个服务
NetworkManager服务 网络管理程序
network服务 网络子管理程序 (平时主要配置这个,需要systemctl restart network 重启生效)
配置网络服务的ip 掩码 网关 DNS 主要有下面4个方法
- vim /etc/sysconfig/network-scripts/ifcfg-ens32
- 命令行nmcli (比较复杂,不太用)
- 简易图形 nmtui
- 图形界面 nm-connection-editor
对上面第一和第二的配置方法进行示例
配置前注意备份 /etc/sysconfig/network-scripts/ifcfg-ens32
查ip(ip add),网关(ip rou),DNS(cat /etc/resolv.conf)
- 对编辑ifcfg-ens32,只要了解相关参数即可
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=dhcp (手动none/static)
IPADDR=192.168.XXX.XXX (静态ip地址)
NETMASK=255.255.255.0 (子网掩码)
GATEWAY=192.168.1.1 (网关)
PREFIX=24 (网络位,和NETMASK互斥)
DNS1=192.168.1.2 (DNS)
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=95c6510d-b0d9-464d-8e75-d814c0a54e5d
DEVICE=ens33
ONBOOT=yes
IPV6_PRIVACY=no
- nmcli 命令如下
nmcli connection modify ens33 connection.autoconnect yes ipv4.method manual ipv4.address 192.168.127.122/24 ipv4.gateway 192.168.127.2 ipv4.dns 192.168.127.2
敲完需要nmcli conn up ens33进行生效
网络主机的改名方式
查看主机名 hostname
配置主机名 hostnamectl set-hostname name1(需要重新开启终端窗口) 或者 hostname name2(临时修改) 或者修改/etc/hostname的文件(需要重启生效)
初始化服务器
- 最小化安装,最小化安装网卡不会自动开启,设置自动开启
- 配置root密码
- 配置IP,自动获取或者静态,方法看上面
- 配置yum源
- 关闭防火墙 systemctl stop/disable firewalld
- 关闭selinux setenforce 0 或者vi /etc/sysconfig/seliunux 设置SELINUX=disable
- 安装常用程序 yum install -y lrzsz sysstat elinks wget net-tools bash-completion vim
- 制作镜像
OSI7层
应用层 应用程序
表示层 格式/压缩/加密
会话层 会话/全双工/半双工
传输层 分段/重组/端口号
网络层 ip地址/寻址/路由
数据链路层 mac地址/局域网
物理层 光电信号
单位换算
最小单位 bit=b 1/0
字节=byte=B=8bit
1kb=1024B
1MB=1024kb
1GB=1024MB
1TB=1024GB
防火墙iptables
nttable和iptables功能类似,但是语法会比iptables更简洁
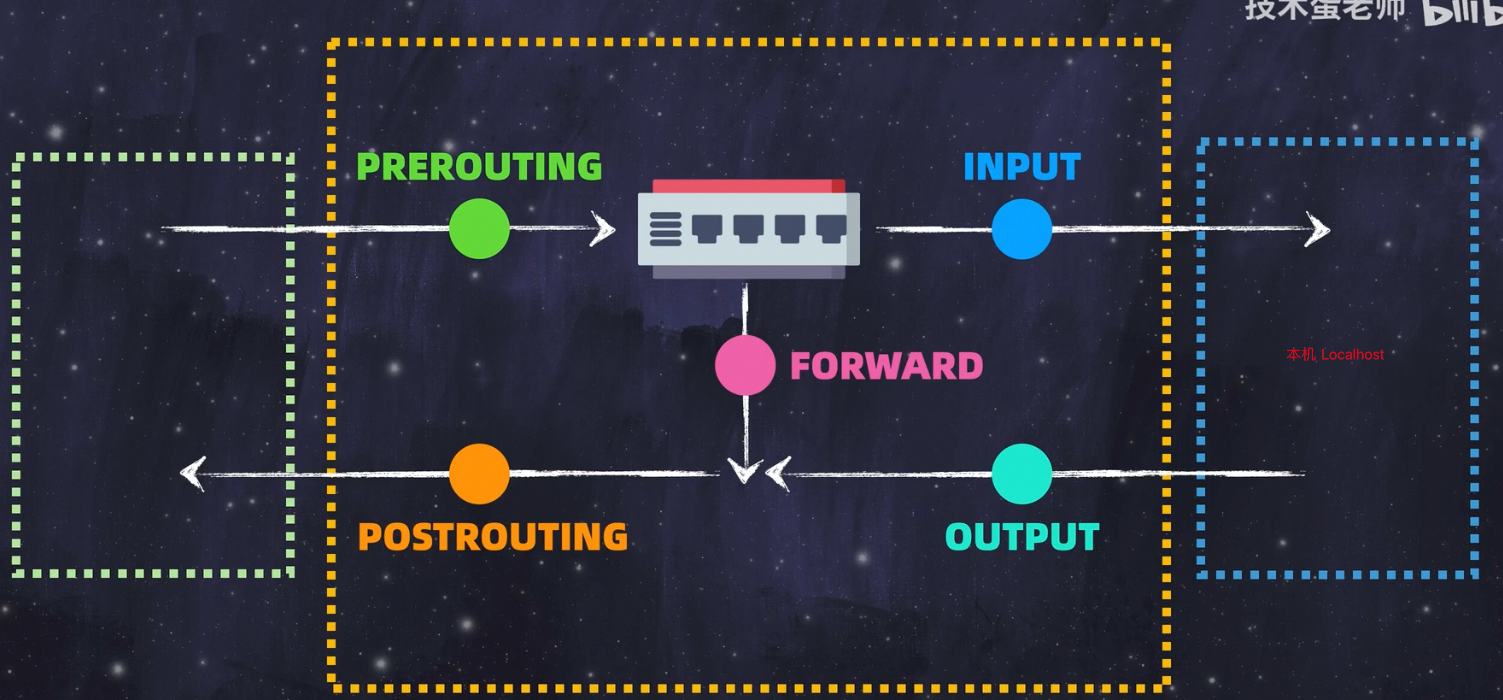
iptables 存在四表五链
安装 yum install -y iptables-services
根据网络链路存在5链
4表 即filter表、nat表、mangle表和raw表,分别用于实现包过滤,网络地址转换、包重构(修改)和数据跟踪处理。
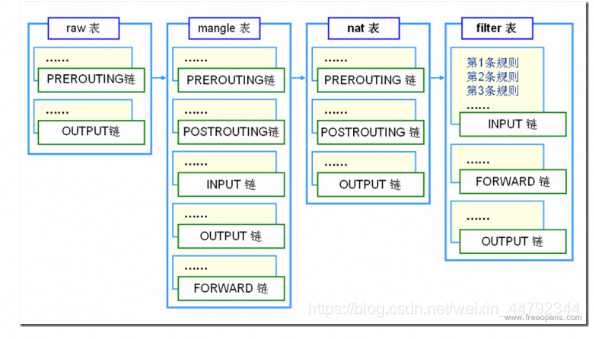
参考链接 https://blog.csdn.net/weixin_44792344/article/details/109674599
语法结构 -t默认是filter表
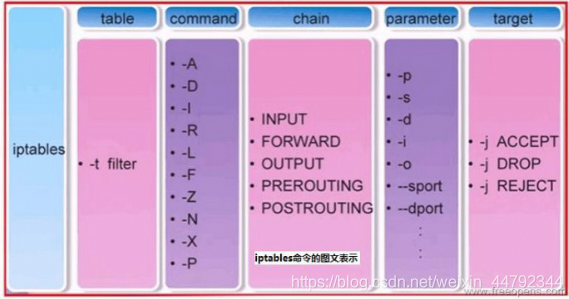
paremeter参数

command参数
-A 在指定链的末尾添加(append)一条新的规则
-D 删除(delete)指定链中的某一条规则,可以按规则序号和内容删除
-I 在指定链中插入(insert)一条新的规则,默认在第一行添加 如果要指定行添加 则在后面链名加索引好 -I INPUT 4 插入INPUT链第四个
-R 修改、替换(replace)指定链中的某一条规则,可以按规则序号和内容替换
-L 列出(list)指定链中所有的规则进行查看
-E 重命名用户定义的链,不改变链本身
-F 清空(flush)
-N 新建(new-chain)一条用户自己定义的规则链
-X 删除指定表中用户自定义的规则链(delete-chain)
-P 设置指定链的默认策略(policy)
-Z 将所有表的所有链的字节和数据包计数器清零
-n 使用数字形式(numeric)显示输出结果
-v 查看规则表详细信息(verbose)的信息
常用选项--------------------------------------------------
iptables -A INPUT # -A 追加规则
iptables -D INPUT 1(编号) # -D 删除规则
iptables -R INPUT 1 -s 192.168.12.0 -j DROP 取代现行规则,顺序不变(1是位置) # -R 修改规则
iptables -I INPUT 1 --dport 80 -j ACCEPT 插入一条规则,原本位置上的规则将会往后移动一个顺位 # -I 插入规则
iptables -L INPUT 列出规则链中的所有规则 # -L 查看规则
通用参数--------------------------------------------------
-t 指定表名 例:iptables -t filter -L
-p 协议 例:iptables -A INPUT -p tcp
-s 源地址 例:iptables -A INPUT -s 192.168.1.1
-d 目的地址 例:iptables -A INPUT -d 192.168.12.1
--sport 源端口 例:iptables -A INPUT -p tcp --sport 22
--dport 目的端口 例:iptables -A INPUT -p tcp --dport 22
-i 指定入口网卡 例:iptables -A INPUT -i eth0
-o 指定出口网卡 例:iptables -A FORWARD -o eth0
-j 指定要进行的处理动作
常用的ACTION:
DROP:丢弃
REJECT:明示拒绝
ACCEPT:接受
-m 引入扩展模块
state 模块用于跟踪数据包的状态
multiport 多端口 可以用于多个端口封禁 注意不同范围端口和多个端口的命令区别
iptables -A INPUT -m multiport -p tcp --dport 80,443 -j ACCEPT
iptables -A INPUT -m multiport -p tcp --dport 1:1024 -j ACCEPT
aec-range 源地址范围
dst-range 目标地址范围
语法格式
iptables -t 表名 <-A/I/D/R> 规则链名 [规则号] <-i/o 网卡名> -p 协议名 <-s 源IP/源子网> --sport 源端口 <-d 目标IP/目标子网> --dport 目标端口 -j 动作
查询
iptables -L INPUT INPUT是链表的名字,可以自定义 iptables -nL以数字形式是查看所有链表
全部清理
iptables -F
封禁
1、封IP段: 从123.0.0.1到123.255.255.254的命令
[root@node1 ~]# iptables -I INPUT -s 123.0.0.0/8 -j DROP
[root@node1 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP all -- 123.0.0.0/8 anywhere
2、封IP段: 从123.45.0.1到123.45.255.254的命令
[root@node1 ~]# iptables -I INPUT -s 123.45.0.0/16 -j DROP
[root@node1 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP all -- 123.45.0.0/16 anywhere
DROP all -- 123.0.0.0/8 anywhere
3、封IP段:从123.45.6.1到123.45.6.254的命令是
[root@node1 ~]# iptables -I INPUT -s 123.45.6.0/24 -j DROP
[root@node1 ~]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
DROP all -- 123.45.6.0/24 anywhere
DROP all -- 123.45.0.0/16 anywhere
DROP all -- 123.0.0.0/8 anywhere
4、禁PING
iptables -A INPUT -p icmp --icmp-type 8 -j DROP
基于iptables实现的零信任原理
实现的效果是需要先访问1122 再访问1123后才能访问的通 22端口,原理是基于tcp握手实现敲门顺序,
参考视频 https://www.bilibili.com/video/BV1nb421J7zp/
# 创建路由规则
iptables -N knockers
# 创建被访问主机端口1122的的握手顺序,rsource默认超时60秒,如果要自定义用--seconds 30
iptables -A INPUT -p tcp --dport 1122 -m state --state NEW -m recent --set --name knockers --rsource
iptables -A INPUT -p tcp --dport 1123 -m state --state NEW -m recent --set --name knockers --rsource
# 只有前2次敲门顺序对,--hitcount 才会为2,才能访问到22端口,如果前面加验证端口,--hitcount 也要同理增加次数
iptables -A INPUT -p tcp --dport 22 -m recent --update --seconds 30 --hitcount 2 --name knockers --rsource -j ACCEPT
# 对于hitcount为为1的请求直接丢弃
iptables -A INPUT -p tcp --dport 22 -m recent --rcheck --seconds 30 --hitcount 1 --name knockers --rsource -j DROP
iptables -A INPUT -p tcp --dport 22 -j DROP
Linux物理层
光纤
数据链路层
交换机
VLAN
TRUNK
考虑合并到13章网络里
001.Linux系统配置及服务管理_第15章_网络概述
002.Linux系统配置及服务管理_第15章_IP地址分类
003.Linux系统配置及服务管理_第15章_子网掩码的作用
004.Linux系统配置及服务管理_第15章_网络层封装
005.Linux系统配置及服务管理_第15章_路由器工作原理
006.Linux系统配置及服务管理_第15章_静态路由
Linux文件服务器
FTP
ftpserver 服务端
用到的是vsftpd的包 用Yum安装
FTP服务器的主目录是 /var/ftp/ 是ftp程序分享内容的本机目录
ftp客户端
Yum安装lftp
使用 lftp 服务器的ip地址 lftp -u user 192.168.1.2
ls 查看 get 下载文件比如get abc.txt mirror 下载目录 比如mirror pub
或者浏览器ftp://ip 进行认证下载
还可以用wget ftp://ip/abc.txt 进行下载
ftp的管理
- 配置文件备份 /etc/vsftpd/vsftpd.conf
- anonymous_enable=NO 禁止匿名登陆 账号登陆密码就是linux用户密码,下载路径是/home/user下的
- anon_upload_enable=NO 启动匿名用户上传文件的功能
- anon_mkdir_write_enable=NO 启动匿名用户创建目录能力
NFS
NFS server:Network file system yum install nfs-utils 主要用于linux之间系统共享,支持多节点挂载,以及并发写入
存储端用一台NAS和多台web端
- mkdir /webtest 创建webtest文件夹作为共享目录
- 配置NFS服务器,设置/etc/exports文件
设置内容为 /webtest 192.168.248.0/24(rw) # 192.168.248.0 根据NFS和其他主机的ip网段来写,意思是开放/webtest 目录给192.168.248.0/24这个网段的主机,权限是读写,如果只读设置为ro - 启动NFS服务器 systemctl start nfs-server && systemctl enable nfs-server
- 查看是否成功exportsfs -v 检查输出的目录
NFS 客户端 yum install -y nfs-utils httpd
这里以httpd测试服务做案例,三台web服务都安装
- systemctl start httpd #httpd的首页文件默认放/var/www/html/下
- showmount -e NFS的主机ip #可以看到这台主机ip的挂载共享目录
- 把每台web服务的主页目录和NFS服务主机的共享目录挂载 mount -t nfs 192.168.1.1(nfs共享主机):/webtest /var/www/html/
- 此时nfs服务端就会把/webtest的文件共享给其他主机, 可以ls /var/www/html/查看
- 解除挂载 umount /var/www/html/
SSH
ssh 对应的包是openssh-server
yum install -y openssh-server
开启服务 systemctl start sshd
免密登陆
- 生成密钥 ssh-keygen 密钥保存在/root/.ssh/id_rsa里
- 把密钥拷贝给其他需要免密登陆的主机 ssh-copy-id 其他主机ip
001.Linux系统配置及服务管理_第17章_网站服务器简介
002.Linux系统配置及服务管理_第17章_网站服务器测试
003.Linux系统配置及服务管理_第17章_apache虚拟主机
004.Linux系统配置及服务管理_第17章_discuz论坛系统上线
005.Linux系统配置及服务管理_第17章_discuz论坛系统后台管理
006.Linux系统配置及服务管理_第17章_wordpress个人博客系统
Linux 域名
Linux 脚本后台运行
正常脚本执行,终端关闭后,脚本也随之关闭
linux 通过nohup 可以后台挂起服务执行 比如下面这条将python的输出强制输出给终端,再保存到test.log文件
nohup python -u test.py >>test.log 2>&1 &
Linux 实用命令
批量运维命令 pssh
这是一个用于在多个主机上并行执行 ssh 的命令行实用程序。使用它,您可以从 shell 脚本向所有 ssh 进程发送输入。
pssh这个包主要功能就是提供了各种基于ssh和scp的命令行工具,包里包含了pssh、pscp、pnuke、prsync、pslurp,这五个工具
参考文章 https://www.dandelioncloud.cn/article/details/1603984149113421825
常用参数
-h:主机文件列表,内容格式”[user@]host[:port]“ 批量读取文件中的主机ip
-H:主机字符串,内容格式”[user@]host[:port]“。 pssh -H 192.168.0.128 ‘ls /‘
-A:手动输入密码模式
-o:输出的文件目录
安装yum install pssh
pslurp命令
批量将远程主机的文件批量复制到本地
文章:https://www.dandelioncloud.cn/article/details/1603984149113421825
命令语法:
pslurp [-vAr] [-h hosts_file] [-H [user@]host[:port]] [-l user] [-p par][-o outdir] [-e errdir] [-t timeout] [-O options] [-x args] [-X arg] [-L localdir] remote local(本地名)
Options:
--version show program's version number and exit
--help show this help message and exit
-h HOST_FILE, --hosts=HOST_FILE
hosts file (each line "[user@]host[:port]")
-H HOST_STRING, --host=HOST_STRING
additional host entries ("[user@]host[:port]")
-l USER, --user=USER username (OPTIONAL)
-p PAR, --par=PAR max number of parallel threads (OPTIONAL)
-o OUTDIR, --outdir=OUTDIR
output directory for stdout files (OPTIONAL)
-e ERRDIR, --errdir=ERRDIR
output directory for stderr files (OPTIONAL)
-t TIMEOUT, --timeout=TIMEOUT
timeout (secs) (0 = no timeout) per host (OPTIONAL)
-O OPTION, --option=OPTION
SSH option (OPTIONAL)
-v, --verbose turn on warning and diagnostic messages (OPTIONAL)
-A, --askpass Ask for a password (OPTIONAL)
-x ARGS, --extra-args=ARGS
Extra command-line arguments, with processing for
spaces, quotes, and backslashes
-X ARG, --extra-arg=ARG
Extra command-line argument
-r, --recursive recusively copy directories (OPTIONAL) 递归复制目录
-L LOCALDIR, --localdir=LOCALDIR 指定从远程主机下载到本机的存储的目录,local是下载到本地后的名称
output directory for remote file copies
Example: pslurp -h hosts.txt -L /tmp/outdir -l irb2
批量下载目标服务器的passwd文件至/data下,并更名为user
pslurp -A -H 192.168.1.6 -L /data /etc/passwd user
pscp.pssh命令
是将本地文件批量复制到远程主机
参考文章 https://blog.51cto.com/u_15057829/4523454
pscp-pssh选项
-v 显示复制过程
-r 递归复制目录
将本地的/data/host.log/192.168.1.6 文件复制到/data/
pscp.pssh -A -H 192.168.1.6 /data/host.log/192.168.1.6 /data/
将本地的/data/host.log/192.168.1.6 文件复制到 host.txt 文件里IP对应主机的data上
pscp.pssh -A -h host.txt /data/host.log/192.168.1.6 /data/
将本地多个文件批量复制到/data/
pscp.pssh -A -H 192.168.1.6 /data/host.log/192.168.1.6 /data/host.log/192.168.1.7 /data/
将本地目录批量复制到/data/目录
pscp.pssh -A -H 192.168.1.6 -r /data/host.log/ /data/
pnuke命令
pnuke命令的功能是能在多个主机上并行杀死进程的程序
文章 https://www.dandelioncloud.cn/article/details/1603984149113421825
pnuke [-vA] [-h hosts_file] [-H [user@]host[:port]] [-l user] [-p par] [-o outdir] [-e errdir] [-t timeout] [-O options] [-x args] [-X arg] pattern
pnuke -h iplist httpd 批量关闭httpd进程
rsync的使用心得
rsync用来同步文件
常用命令参数 -avzP -rvzP
-a表示进行归档操作;
-v(verbose)表示在stdout上打印出细节信息或进度。
-z 压缩数据传输效率更高
-r 同-a 但是区别是-a会将文件属性比如chmod权限 chattr等属性一起同步,-r只是单纯同步文件内容,效率更高
-P 显示同步的过程,可以用--progress替换。
-e 使用的信道协议 rsync -avzP -e 'ssh -p 22' 这里的-e 'ssh -p 22' 表示以ssh的方式通过22端口推送,如果不写默认22端口
主要记录下--include和--exclude参数的使用
- 首先两者搭配使用 先写include再写exclude
- 在 rsync 的 --include 选项中,/8/、/8 和 8/ 这三种写法确实有区别,它们代表着不同的匹配模式

- 比如这是要同步的目标目录,打星号的事我们要同步的目标,其余是要舍弃的对象
AppStream/x86_64/os/Packages/ *
AppStream/x86_64/os/repodata/ *
AppStream/x86_64/debug/Packages/
AppStream/x86_64/debug/repodata/
AppStream/aarch64/os/Packages/
AppStream/aarch64/os/repodata/
以下是我们的同步语法
rsync -rnvz --max-size='1G' --timeout=10 \
--include='/AppStream/' \
--exclude='/*' \
--include='/AppStream/x86_64/' \
--exclude='/AppStream/*/' \
--include='/AppStream/x86_64/*/' \
--exclude='/AppStream/x86_64/debug/*' \
rsync://源地址 目标地址
可以看到写法规律主要是参考3个原则写的,前2个规律可以避免搞混不同层级包含和过滤规则的冲突
1. 一个include对应一个exclude
2. 每对include和exclude的层级一致
3. 从根部路径往子路径蔓延
rsync的包含和排除
关于--include和--exclude参数的其他使用示例
https://www.jianshu.com/p/f30b3de32771
个人的经验总结如下:
--include和--exclude参数的执行顺序很关键,因为他是严格按照顺序执行,意味着两者有冲突会以后面一条的规则为准
另外路径的表达也要准确
示例1
根路径下有 AppStream ,OS,PLUS等文件夹,我们只同步AppStream文件夹
--exclude='/*/' \
--include='/AppStream/' \
上面的规则匹配不到任何数据,因为首先会排除所有的文件夹,包括AppStream,
哪怕第二条规则又加入了AppStream也不会有效果,因为第一条规则的优先级会高于第二条
所以需要调整下顺序,先包含,再排除,就可以实现
--include='/AppStream/' \
--exclude='/*/' \
示例2
需求 我们要过滤AppStream/x86_64/debug/,但是要其他两个文件夹
AppStream/x86_64/aaa/
AppStream/x86_64/os/
AppStream/x86_64/debug/
错误规则如下:
1 --include='/AppStream/' \
2 --exclude='/*/' \
3 --exclude='/AppStream/*/' \
4 --include='/AppStream/x86_64/' \
5 --exclude='/AppStream/x86_64/debug/**/' \
6 --include='/AppStream/x86_64/*/**' \
这条规则只能匹配到 AppStream/ 这个根路径无法获取下面/86_64的除了debug外的其他子文件夹
因为3 4规则冲突了和示例1一样先排除了AppStream的所有子文件夹,然后再包含,但是因为排除规则先执行 会优先与包含规则
修正规则 3 4 规则互换一下 然后 5 6排除了debug和debug的所有子文件夹,最后结果是同步AppStream/x86_64/os/Packages/和AppStream/x86_64/os/repodata/文件
1 --include='/AppStream/' \
2 --exclude='/*' \
3 --include='/AppStream/x86_64/' \
4 --exclude='/AppStream/*/' \
5 --exclude='/*/x86_64/debug/' \
6 --exclude='/*/x86_64/debug/**/' \
7 --include='/AppStream/x86_64/*/' \
我们可以把5 6规则继续优化成一条
--exclude='/AppStream/x86_64/debug/**/' \
或者
--exclude='/AppStream/x86_64/debug/' \
或者 这个就是直接过滤所有二层路径下的debug文件夹了
--exclude='/*/*/debug/' \
示例3
AppStream/x86_64/debug/Packages/
AppStream/x86_64/debug/repodata/
AppStream/loongarch64/debug/Packages/
AppStream/loongarch64/debug/repodata/
BaseOS/loongarch64/debug/Packages/
BaseOS/loongarch64/debug/repodata/
BaseOS/x86_64/debug/Packages/
BaseOS/x86_64/debug/repodata/
DDE/loongarch64/debug/Packages/
DDE/loongarch64/debug/repodata/
DDE/x86_64/debug/Packages/
DDE/x86_64/debug/repodata/
AppStream/x86_64/os/Packages/ **
AppStream/x86_64/os/repodata/ **
AppStream/loongarch64/os/Packages/
AppStream/loongarch64/os/repodata/
BaseOS/loongarch64/os/Packages/
BaseOS/loongarch64/os/repodata/
BaseOS/x86_64/os/Packages/ **
BaseOS/x86_64/os/repodata/ **
DDE/loongarch64/os/Packages/
DDE/loongarch64/os/repodata/
DDE/x86_64/os/Packages/ **
DDE/x86_64/os/repodata/ **
假设同步的根路径 子文件夹路径如上,我们要的就是x86_64/os路径内的Packages和repodata
我们可以一个个显示的设置指定的路径,
--include='/AppStream/' \
--include='/BaseOS/' \
--exclude='/*/' \
--include='/AppStream/x86_64/' \
--exclude='/AppStream/*/' \
--include='/BaseOS/x86_64/' \
--exclude='/BaseOS/*/' \
但是这样规则需要写很多,我们可以优化,思路如下
第一层过滤掉只要AppStream,BaseOS,DDE
--include='/AppStream/' \
--include='/BaseOS/' \
--include='/DDE/' \
--exclude='/*/' \
规则到了这里 只会剩下AppStream,BaseOS,DDE这三个文件夹了,那么我们只要第二层的x86_64,其他的都不要
--include='/*/x86_64/' \
--exclude='/*/*/' \
同理规则到了这里,只会剩下AppStream,BaseOS,DDE这三个的x86_64文件夹,其他架构的都已经排除掉了,
这层的逻辑会不一样,我们除了debug不要 其他都要,所以先写排除规则,再写include规则
--exclude='/*/*/debug/' \
--include='/*/x86_64/*/**' \
搭建yum源的步骤
普通Yum源
早期准备
开放防火墙80端口 或者关闭防火墙
增加防火墙端口
firewall-cmd --get-active-zones
firewall-cmd --zone=public --add-port=80/tcp --permanent
firewall-cmd --reload
- 配置外⽹yum源
- yum初始化 yum clean all && dnf makecache
- 搭建本地yum源的httpd服务,需要指定路径 yum -y install createrepo httpd
- 创建本地yum仓库路径 mkdir -p /var/www/html/html/packages/x86_64/ks10-adv-os和 /var/www/html/html/packages/x86_64/ks10-adv-updates
5 reposync 同步外网源仓库文件到本地 reposync -n --repoid=ks10-adv-os --repoid=ks10-adv-updates -p /var/www/html/packages/x86_64/
步骤五会生成的目录为/var/www/html/packages/x86_64/ks10-adv-os/Packages 和 /var/www/html/packages/x86_64/ks10-adv-updates/Packages - 创建本地索引文件 createrepo /var/www/html/packages/x86_64/ks10-adv-os/
步骤6会生成本地索引文件在/var/www/html/packages/x86_64/ks10-adv-os/repodata 和 /var/www/html/packages/x86_64/ks10-adv-updates/repodata - 开启httpd服务 systemctl start httpd
- 写一个shell脚本定期运行更新yum源
# 更新包
reposync -n --repoid=V8_AppStream --repoid=V8_AppStream-updates --repoid=V8_BaseOS --repoid=V8_BaseOS-updates --repoid=V8_PowerTools --repoid=V8_PowerTools-updates -p /mnt/data_disk1/www/html/packages/x86_64
# 对增量做meta更新
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_AppStream/
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_AppStream-updates/
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_BaseOS/
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_BaseOS-updates/
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_PowerTools/
createrepo --update /mnt/data_disk1/www/html/packages/x86_64/V8_PowerTools-updates/
- nginx和httpd配置
nginx
server {
listen 18080;
server_name localhost;
location / {
root /data/opt/myYum/yum/;
autoindex on;
autoindex_localtime on;
index index.html repomd.xml;
}
# 禁止访问相对路径/log文件
location /log {
deny all;
}
}
httpd
DocumentRoot "/mnt/data_disk1/www/html" 设置http服务的根路径
<Directory "/var/www/html/test"> 设置yum源的根路径
Options Indexes FollowSymLinks 开启目录遍历
AllowOverride None 禁止.htaccess 文件进行配置覆盖
Require all granted 允许所有用户访问
</Directory>
yum下载方式2 wget
有些场景用wget命令比较省力,可以保证1002a下的目录结构和上级源是一模一样
wget -c -N -m -np -nH --cut-dirs=1 -R "index.html*" http://ip/1002a/
这些参数的意义如下:
-c 保持已连接的会话
-N 代替-nc选项。-N选项允许wget更新本地文件的时间戳以匹配服务器上的文件。
-nc 不覆盖已经存在的文件
-m(或 --mirror):开启镜像下载模式,等价于 -r -N -l inf --no-remove-listing 的缩写,意味着递归下载、时间戳检查、无限深度遍历,且不清除FTP站点的列表。
-np(或 --no-parent):不遍历到父目录,防止爬升到父目录进行下载。
-nH(或 --no-host-directories):取消生成基于网站主机名的目录,即不在本地创建顶级域名目录。
--cut-dirs=1:跳过URL的目录层数。值为1时,http://ip/1002a/ 里的 1002a 计为一个层级被跳过,实际下载的内容直接保存在当前目录。你可能需要根据具体的URL调整这个值。
-R "index.html*":排除下载所有名为 index.html* 的文件。这是因为wget默认会下载每个目录下的索引文件,使用此选项可以排除它们。引号内可以根据需要排除更多文件或模式。
请注意,--cut-dirs 参数的值可能需要根据实际的URL路径深度调整。在此示例中,由于我们想要把 http://ip/1002a/ 下的内容下载到当前目录,并保持其下的结构,所以设置 --cut-dirs=1 来忽略掉第一个目录层级(即 1002a)。如目录结构更深,相应地调整这个参数值。
结构化yum源
转自https://www.cnblogs.com/yzbhfdz/p/15896202.html
自己生成结构化文件
注意点
1、repo2module 在modulemd-tools包中,需要先安装modulemd-tools
2、repo2module -s stable -d . modules.yaml这个命令有点问题,repo2module 没有-d参数,去掉。实际的应该是repo2module -s stable . modules.yaml
区别
和普通yum源多了一个用repo2module生成模块化yum源,然后将modifyrepo_c命令将模块化文件写入到repodata文件夹
注意modifyrepo_c 目标文件夹是repodata文件夹,而createrepo_c和repo2module是在包的目录
创建目录
mkdir -p /opt/ovirt/centos/8-stream/
cd /opt/ovirt/centos/8-stream/
mkdir -p AppStream/kickstart/
mkdir -p AppStream/os/
mkdir -p PowerTools/kickstart/
mkdir -p PowerTools/os/
下载AppStream
cd /opt/ovirt/centos/8-stream/AppStream/os/
wget https://mirrors.huaweicloud.com/centos/8-stream/AppStream/aarch64/os/Packages/
cat index.html | grep href | awk -F"\"" '{print $4}' | grep module_el8 | xargs -I {} wget https://mirrors.huaweicloud.com/centos/8-stream/AppStream/aarch64/os/Packages/{}
createrepo_c .
repo2module -s stable . modules.yaml
modifyrepo_c --mdtype=modules modules.yaml repodata/
下载PowerTools
cd /opt/ovirt/centos/8-stream/PowerTools/os/
wget https://mirrors.huaweicloud.com/centos/8-stream/PowerTools/aarch64/os/Packages/
cat index.html | grep href | awk -F"\"" '{print $4}' | grep module_el8 | xargs -I {} wget https://mirrors.huaweicloud.com/centos/8-stream/PowerTools/aarch64/os/Packages/{}
createrepo_c .
repo2module -s stable . modules.yaml
modifyrepo_c --mdtype=modules modules.yaml repodata/
创建CentOS-AppStream-PowerTools-local.repo
touch /etc/yum.repos.d/CentOS-AppStream-PowerTools-local.repo
编辑CentOS-AppStream-PowerTools-local.repo
[Centos8-AppStream-local1]
name=Centos8-AppStream-local1
baseurl=file:///opt/ovirt/centos/8-stream/AppStream/os/
enabled=1
gpgcheck=0
priority=2
[Centos8-PowerTool-local1]
name=Centos8-PowerTool-local1
baseurl=file:///opt/ovirt/centos/8-stream/PowerTools/os/
enabled=1
gpgcheck=0
priority=2
下载结构化文件
用dnf reposync或者reposync 用--download-metadata参数下载元数据
dnf reposync -n -a=x86_64 --delete --download-metadata --repoid=UniontechOS-1050a-AppStream-x86_64 -p /mnt/disk1/x86_64/1050a/
或者 --norepopath区别可以理解为自定义repodata文件夹的路径,建议还是和Packages文件放一起比较好
dnf reposync -n -a=x86_64 --delete --download-metadata --repoid=UniontechOS-1050a-AppStream-x86_64 -p /mnt/disk1/x86_64/1050a/UniontechOS-1050a-AppStream-x86_64 --norepopath
Yum下载已安装的包
下载命令考虑用 yum命令或者repotrack和yumdownloader
后2者需要提前下载 yum install yum-utils
yumdownloader:下载指定软件包及其依赖项,下载速度较快。但它无法自动下载依赖包的依赖项,需要手动处理。
repotrack:下载整个软件仓库的所有软件包及其依赖项,并自动处理软件包之间的依赖关系,节省了寻找依赖项的时间。但是下载速度较慢。
下载命令分别是
-
yumdownloader --resolve --destdir=<destination-folder> <package-name>
解释:
<package-name>替换为要下载的软件包的名称。
--resolve:此命令将下载指定软件包及其所有依赖项。
--destdir:指定下载目录。将替换为要保存软件包的目录。 -
repotrack --downloadonly --destdir=/home/localrepo/ <package-name> -
yum reinstall --downloadonly --downloaddir=/home/localrepo/ zstd.x86_64
可以导出安装的清单,然后用shell遍历下载
yum list installed | awk '{print $1}' > installed_packages.txt
while read package; do
yumdownloader --resolve --destdir=/path/to/localrepo "$package"
done < installed_packages.txt
最后可以尝试使用本地源来安装一个包以确保一切工作正常:
[localrepo]
name=Local Repository
baseurl=file:///path/to/localrepo
enabled=1
gpgcheck=0
yum --disablerepo="*" --enablerepo="localrepo" install somepackage
搭建docker源
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum makecache
yum -y install docker-ce
systemctl start docker
systemctl enable docker
