SHELL 编程
shell 编程
常用查询
shell版本查看和切换
查看shell有哪些 cat /etc/shells 里面的shell路径直接输入 就能切换不同的shell
查看当前的shell环境变量 cat $SHELL
shell执行的4种模式
bash file和 sh file是子shell
file 和source file 是本shell模式
容易混淆的语法点
1. $( ) 与 `` $( )与`` 都是用来作命令替换的。 先完成引号里的命令行,然后将其结果替换出来,再重组成新的命令行
$( )的弊端是,并不是所有的类unix系统都支持这种方式,但反引号是肯定支持的
2. ${ } 作用是获取变量的结果。一般情况下,$var与${var}是没有区别的,但是用${ }会比较精确的界定变量名称的范围
3. $(( )) 作用是进行整数运算。 在 $(( )) 中的变量名称,可于其前面加 $ 符号来替换,也可以不用,
还可以将其他进制转成十进制数显示出来。用法如下:echo $((N#xx))
echo $((2#110))
6 2进制
echo $((16#2a))
42 16进制
echo $((8#11))
9 8进制
4. $[] 和第三点一样 也是用来整数计算, $[]和$(())效果是等同的,建议用第三的写法,方便记忆
变量赋值
-
变量赋值的几种方式
- 变量=数值
- 引用其他命令结果进行赋值 ip=`ps -ef|grep "mysql"`
- 交互式变量赋值 read -t设置超时时间 -s不显示输入信息(密码) -p 设置提示信息 #这里-t建议放最前面,放后面可能不生效
- 脚本位置参数传参 $1 $2 $3
-
shell编程默认赋值都是字符串,所以单引号 双引号 或者直接字符串都一样
""弱引用 弱化空格的作为分隔符的意义
''强引用 弱化一切特殊符号的意义
``和$()优先执行 $()的弊端是,并不是所有的类unix系统都支持这种方式,但``是肯定支持的
在多层次的复合替换中,` ` 须要额外的转译\` 处理,而 $( ) 则比较直观对于大部分字符串来说,以下三种是等价的 比如"test"和$"test"和$'test' [root@django_env2 ~]# echo "test";echo $"test";echo $'test' test test test 但是对于一些特殊的分隔符"\n"和$"\n"是一样的,就是\n的字符串 而$'\n'则代表的是换行符 -------------------------------------------------------- [code]command1 `command2 `command3` `[/code] 原本的意图是要在 command2 `command3` 先将 command3 提换出来给 command 2 处理, 然后再将结果传给 command1 `command2 …` 来处理。 然而,真正的结果在命令行中却是分成了 `command2 ` 与 “ 两段。 正确的输入应该如下: [code]command1 `command2 \`command3\` `[/code] 要不然,换成 $( ) 就没问题了: [code]command1 $(command2 $(command3))[/code]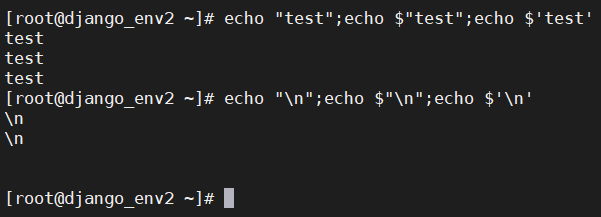
[root@127 download]# name=test [root@127 download]# name1="test1" [root@127 download]# name2='test2' [root@127 download]# echo $name1 test1 [root@127 download]# echo $name2 test2 [root@127 download]# echo $name test [root@127 download]# -
单引号变量,不识别特殊语法,双引号变量,可以识别特殊语法,反引号中的命令结果会被保留下来
[root@127 download]# name=test [root@127 download]# name1="test1" [root@127 download]# name2='test2' # 双引号可以识别$变量名的用法,单引号不行 [root@127 download]# echo "$name1" test1 [root@127 download]# echo "$name" test [root@127 download]# echo "$name2" test2 [root@127 download]# echo '$name2' $name2 [root@127 download]# echo '$name1' $name1 [root@127 download]# echo '$name' $name # 反引号 [root@127 download]# test=`ls -ll` [root@127 download]# echo $test total 82644 drwxr-xr-x 17 501 501 4096 Mar 11 15:52 Python-3.6.12 -rw-r--r-- 1 root root 84623360 Aug 15 2020 Python-3.6.12.tar -
位置变量

$*和$@的区别,当$*和$@ 不被" "包围时,没什么区别,都是将接受的每个参数看成一份整体数据,彼此用空格间隔而已. 如果被" "包围,$* 还是把所有接受的数据当成一份数据, 而$@ 会把每份数据单独视为一份数据,彼此间是独立的 比如bash text.bash alex 180 "$@" 接受的参数是alex和180 而$* 接受的参数是"alex 180" #! /bin/bash echo '特殊变量$0 $1 $2的实践' echo '结果 : '$0 $1 $2 echo "##############################" echo '特殊变量$#的实践' echo '结果 : '$# echo "##############################" echo '特殊变量$*和$@的实践' echo '结果 : '$* echo "##############################" echo '结果 : '$@ 把下面保存为1.sh,运行结果如下 [root@django_env2 ~]# bash 1.sh alex 180 特殊变量$0 $1 $2的实践 结果 : 1.sh alex 180 ############################## 特殊变量$#的实践 结果 : 2 ############################## 特殊变量$*和$@的实践 结果 : alex 180 ############################## 结果 : alex 180 把下面保存为2.sh #! /bin/bash echo '打印\"\$*\"' for var in "$*" do echo "$var" done echo "#############" echo '打印\"\$@\"' for var in "$@" do echo "$var" done 运行结果如下 [root@django_env2 ~]# bash 2.sh alex 180 打印\"\$*\" alex 180 ############# 打印\"\$@\" alex 180 -
变量子串 截取,基础${#args} ${args} 截取${args:start:length} 删除${args#word} ${args%word} 替换$
用test=congratulation示例 ${变量} 返回变量值 ${#变量} 返回变量长度,字符长度 ${#1} 传入变量1的长度 ${#name} name变量的长度 计算字符串长度其他方法还有wc -l 比如cat 1.txt |wc -L #打印最长行数的字符串长度 还有expr length "$test"和awk的echo "$test" |awk '{print length($0)}' ${变量:start} 返回变量offset数值后的长度 echo ${test:2}>>ngratulation ${变量:start:length}提取offset之后的length限制的字符 echo ${test:2:3}>>ngr 无论是从后向前还是从前向后,匹配的字符串支持* ? 等通配符 而且匹配位置不支持字符串中间,必须是以XXX为开始或者XXX为结束才能匹配到 ${变量#word} 从变量开头删除最短匹配的word子串 比如a=abc123abc ${a#ab} >>c123abc ${变量##word} 从变量开头删除最长匹配的word 比如a=abc123abc ${a##a*c} >> 因为##匹配的是最长abc123abc ${变量%word} 从变量结尾删除最短匹配的word子串 ${变量%%word} 从变量结尾删除最长匹配的word ${变量/pattern/string} 用string代替第一个匹配的pattern ${变量//pattern/string} 用string代替所有的的pattern [root@localhost ~]# a="man man boy boy man" [root@localhost ~]# echo ${a/man/girl} girl man boy boy man [root@localhost ~]# echo ${a//man/girl} girl girl boy boy girl示例,来一个批量修改文件名的操作
touch test{1..5}.jpg >>> test1.jpg test2.jpg test3.jpg test4.jpg test5.jpg 先批量创建5个jpg文件 for i in `ls *.jpg` do mv $i `echo ${i/test/best}` done变量扩展用法 对于变量的值进行判断和处理
如果parameter变量为空,返回word字符串 ${parameter:-word} 如果parameter变量为空,则word代替变量并返回其值 这里如果parameter为空,则ret和parameter都为word的值 ret=${parameter:=word} 注意 ${name:-10} 和${name: -10} 是有区别的,前者表示如果name变量为空,则返回10,后者代表对name变量的字符串截取后十位 如果parameter变量为空,word当做stderr说粗话,否则输出变量值 ${parameter:?word} 如果parameter变量为空,什么都不做,如果不为空则返回word ${parameter:+word}示例,比如把这个对变量判断添加到find命令中,提高容错率
find ${dir_path:=/opt/mysql/} -name "*.tar" -type f -mtime +7表示状态的变量
$? 上一条命令/脚本返回值 0正常 非0失败 用来判断执行是否成功 $$ 当前运行脚本的pid,把pid记录到文件中用来kill $! 上一个运行脚本的pid $_ 上一个脚本或命令的最后一个参数 和esc+.一样 -
${}和$()区别示例,以及${}示例
$()
用于命令替换
将括号内命令的执行结果赋值给变量
${}
用于变量替换
一般情况下,$ var与$ {var}是没有区别的,但是用${ }会比较精确的界定变量名称的范围
可用于取数组元素的值
#这道题可以帮助我们好好的区分$ ()和$ {}
#! /bin/bash
read n
a[0]=1
a[1]=1
for ((i=2;i<=n;i++))
do
x=$(expr $i - 1)
y=$(expr $i - 2)
a[$i]=$(expr ${a[$x]} + ${a[$y]})
done
echo ${a[$n]}
${}常见的使用场景
以下的内容基本从Shell13问中提取.
1. 截断功能 原始数据 /dir1/dir2/dir3/my.file.txt
${file#*/}: 拿掉第一条/及其左边的字符串:dir1/dir2/dir3/my.file.txt
${file##*/}: 拿掉最后一条/及其左边的字符串:my.file.txt
${file#*.}: 拿掉第一个.及其左边的字符串:file.txt
${file##*.}: 拿掉最后一个.及其左边的字符串:txt
${file%/*}: 删掉最后一个/及其右边的字符串:/dir1/dir2/dir3
${file%%/*}: 删掉第一条/及其右边的字符串:(空值)
${file%.*}: 拿掉最后一个.及其右边的字符串:/dir1/dir2/dir3/my.file
${file%%.*}: 拿掉第一个.及其右边的字符串:/dir1/dir2/dir3/my
记忆的方法为:
[list]#是去掉左边, ##最后一个和他的左边
%是去掉右边, %%第一个和他的右边
2. 字符串提取
单一符号是最小匹配﹔两个符号是最大匹配。
${file:0:5}:提取最左边的 5 个字节:/dir1
${file:5:5}:提取第 5 个字节右边的连续 5 个字节:/dir2
3. 字符串替换
${file/dir/path}:将第一个 dir 提换为 path:/path1/dir2/dir3/my.file.txt
${file//dir/path}:将全部 dir 提换为 path:/path1/path2/path3/my.file.txt
4. 针对不同的变量状态赋值(没设定、空值、非空值):
${file-my.file.txt}: 若$file没有设定,则使用my.file.txt作返回值。(空值及非空值时不作处理)
${file:-my.file.txt}:若$file没有设定或为空值,则使用my.file.txt作返回值。(非空值时不作处理)
${file+my.file.txt}: 若$file设为空值或非空值,均使用my.file.txt作返回值。(没设定时不作处理)
${file:+my.file.txt}:若$file为非空值,则使用my.file.txt作返回值。(没设定及空值时不作处理)
${file=my.file.txt}: 若$file没设定,则使用my.file.txt作返回值,同时将$file 赋值为 my.file.txt。(空值及非空值时不作处理)
${file:=my.file.txt}:若$file没设定或为空值,则使用my.file.txt作返回值,同时将 $file 赋值为 my.file.txt。(非空值时不作处理)
${file?my.file.txt}: 若$file没设定,则将my.file.txt输出至 STDERR。(空值及非空值时不作处理)
${file:?my.file.txt}:若$file没设定或为空值,则将my.file.txt输出至STDERR。(非空值时不作处理)
注意:
":+"的情况是不包含空值的.
":-", ":="等只要有号就是包含空值(null).
5. 变量的长度
${#file}
6. 数组运算
A=(a b c def)
${A[@]} 或 ${A[*]} 可得到 a b c def (全部组数)
${A[0]} 可得到 a (第一个组数),${A[1]} 则为第二个组数...
${#A[@]} 或 ${#A[*]} 可得到 4 (全部组数数量)
${#A[0]} 可得到 1 (即第一个组数(a)的长度),${#A[3]} 可得到 3 (第四个组数(def)的长度)
环境变量设置
环境变量一般指用export内置命令导出的变量,用于定义shell的运行环境
- 用户个人配置文件 ~/.bash_profile, ~/.bashrc 远程登陆用户特有文件
- 全局配置文件/etc/profile /etc/bashrc,且系统建议最好创建在/etc/profile.d/而不是直接修改主文件,全局配置文件,影响所有登陆系统的用户
- set 和declare 输出所有变量,包括全局变量和局部变量
- env 只显示全局变量
- unset 变量名,删除变量或者函数
- export 显示和设置环境变量值
- readonly 设置变量只对当前shell生效.
readonly name=test
环境变量文件加载顺序
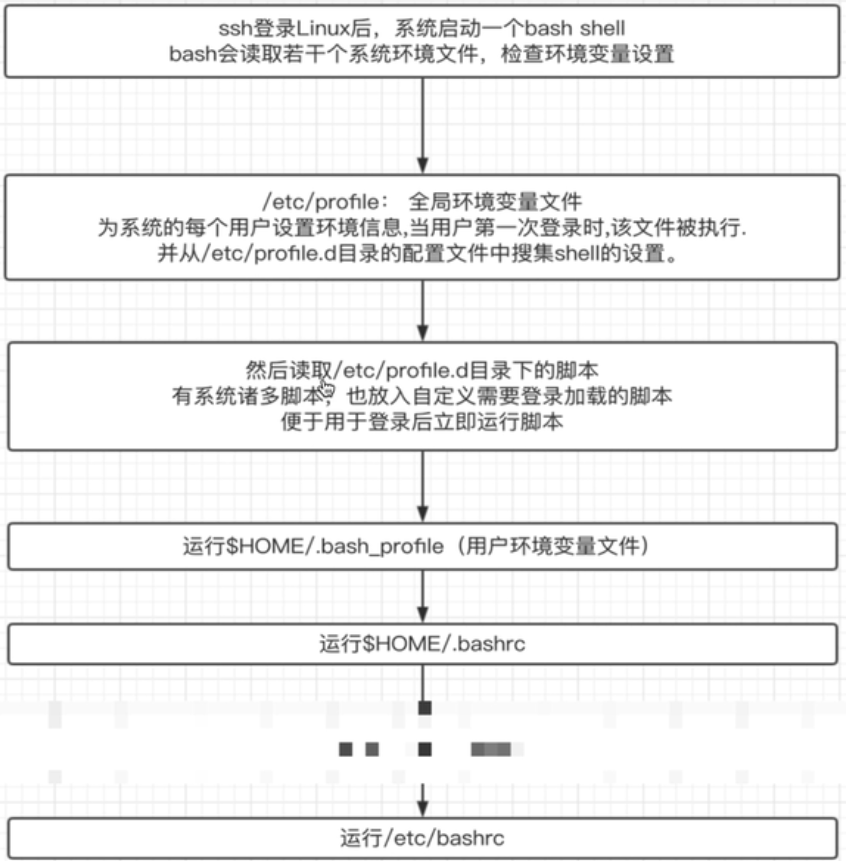
环境详细
模式区别
非交互式模式。在这种模式下,shell不与你进行交互,而是读取存放在文件中的命令,并且执行它们。当它读到文件的结尾,shell也就终止了
交互式模式就是shell等待你的输入,并且执行你提交的命令。这种模式被称作交互式是因为shell与用户进行交互。这种模式也是大多数用户非常熟悉的:登录、执行一些命令、签退。当你签退后,shell也终止了。
登入用户非交互模式
- 读取/etc/bashrc bashrc是在系统启动后,只要运行bash命令就触发一次。
- 读取 ~/.bashrc 当该用户登录时以及每次打开新的shell时,该文件被读取 会继承/etc/bashrc的部分变量
登入系统交互模式
- 读取/etc/profile profile是在用户登录后才会运行。
- 读取~/.bash_profile 用户的局部配置 只在用户登入时候执行一次,去其家目录读取/.bash_profile,如果这读取不了就读取/.bash_login,这个也读取不了才会读取 ~/.profile,这三个文档设定基本上是一样的,读取有优先关系
读取先后顺序
在 Bash shell 中,~/.bashrc 和 ~/.bash_profile(或 ~/.profile)的读取先后顺序取决于 Bash shell 是以登录方式还是非登录方式启动的。
登录 shell:
当您登录到系统时(例如通过 SSH 登录服务器或在 TTY 登录),Bash 会读取 /.bash_profile,/.bash_login 和 ~/.profile 文件(按照这个顺序),但只会执行找到的第一个文件。通常,在 ~/.bash_profile 中会有一行命令来读取 ~/.bashrc 文件,以便把一些基本的 shell 设置(别名、函数等)也应用于登录 shell。例如,您可能会在 ~/.bash_profile 中见到如下代码:
# 在 ~/.bash_profile 中
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
非登录 shell:
非登录 shell 通常是指您在已登录的图形用户界面中打开一个新的终端窗口或标签时启动的 shell。在这种情况下,Bash 会读取并执行 ~/.bashrc 文件。
在了解 ~/.bashrc 和 ~/.bash_profile 的区别后,以下是 Bash 启动时会读取的文件的一般顺序:
全局文件(对所有用户有效):
登录 shell:首先 /etc/profile 会被读取和执行。然后,Bash 会查找并执行 /etc/profile.d/*.sh 中的脚本。
非登录 shell:Bash 通常会读取 /etc/bash.bashrc(在一些系统上可能是 /etc/bashrc)。这个文件是系统级别的配置,用于所有用户的非登录 shell。
用户级别文件:
登录 shell:Bash 会读取 /.bash_profile,/.bash_login,/.profile(只读取找到的第一个文件)。通常,/.bash_profile 会包含命令来读取 ~/.bashrc。
非登录 shell:只读取 ~/.bashrc。
在大多数现代 Linux 发行版中,~/.profile 是最初由系统创建的,并且通常会被 ~/.bash_profile 或 ~/.bash_login(如果存在的话)所覆盖。所以,如果您创建了 ~/.bash_profile,那么 ~/.profile 将不会被登录 shell 读取,除非您在 ~/.bash_profile 中明确指定。这是为什么许多人会在他们的 ~/.bash_profile 中添加代码来源 ~/.bashrc 的原因。
总结一下,对于登录 shell,~/.bash_profile(或 ~/.profile)具有最高优先级,因为它是用户级别的配置,并且它还可以包含命令来读取 ~/.bashrc。对于非登录 shell,~/.bashrc 会被直接读取和执行。您可以根据个人需要决定在哪个文件中设置环境变量、别名和函数等。
变量传参
find 的-exec和 xargs 可以实现传参
使用 find 和 xargs 进行文件操作
1. find 的基本用法
find 命令用于搜索文件系统中的文件和目录。常见的选项和参数包括:
/path/to/search: 指定要搜索的目录。
-type f: 搜索普通文件(不搜索目录)。
-mtime +N: 搜索修改时间在 N 天前的文件。
-name "pattern": 根据文件名匹配模式进行搜索。
2. find 配合 -exec 使用
-exec 选项允许你对搜索到的每个文件执行指定的命令。基本命令格式如下:
find /path/to/search -type f -mtime +20 -name '*.log' -exec command {} \;
{}: 占位符,表示当前查找到的文件路径。
\;: 告诉 find 这是 -exec 命令的结束符, 多个exec需要多个 \;结束符
示例:
1 备份日志文件:
find /path/to/log/files -type f -mtime +20 -name '*.log' -exec cp {} {}.bak \;
2 删除包含 "Already downloaded" 字符串的行:
find /path/to/log/files -type f -mtime +20 -name '*.log' -exec sed -i '/Already downloaded/d' {} \;
3. 使用 xargs 传递参数
xargs 是一个构建和执行命令的工具,可以接收来自标准输入的参数,并将其作为命令行参数传递给指定的命令。
基本用法:
1 备份日志文件:
find /path/to/log/files -type f -mtime +20 -name '*.log' | xargs -I {} cp {} {}.bak
2 删除指定行:
find /path/to/log/files -type f -mtime +20 -name '*.log' | xargs -I {} sed -i '/Already downloaded/d' {}
4. 结合 find 和 xargs 进行多步骤操作
将 find 和 xargs 结合在一起,通过管道将 find 的输出传递给 xargs,然后处理每个文件。例如,备份文件后删除特定行:
find /path/to/log/files -type f -mtime +20 -name '*.log' | xargs -I {} sh -c 'cp "{}" "{}.bak" && sed -i "/Already downloaded/d" "{}"'
5. 处理特殊文件名: -print0 和 -0
如果文件名包含空格或其他特殊字符,使用 -print0 和 xargs -0 确保正确处理。
示例:
find /path/to/log/files -type f -mtime +20 -name '*.log' -print0 | xargs -0 -I {} sh -c 'cp "{}" "{}.bak" && sed -i "/Already downloaded/d" "{}"'
重点总结
使用 -exec 来对每个匹配的文件执行命令,需通过 \; 结束命令。
xargs 可以更高效地将 find 的输出作为输入参数传递给命令。
处理特殊文件名时,使用 -print0 和 -0 确保空间和特殊字符不会引起问题。
通过以上实践和理解,可以高效地查找并批量处理文件,提高工作效率。
重定向
基本知识点
-
0,1,2分别代表stdin,stdout,stderr
-
重定向覆盖输出符号
echo "> 就想python的w模式" > test.txt重定向追加输出符号
echo ">> 就想python的a模式" > test.txt< 重定向覆盖写入符号
cat < eof > 1.txt<< 重定向追加写入符号
<<一般和EOF一起搭配使用 EOF是END Of File的缩写,表示自定义终止符.既然自定义,那么EOF就不是固定的,可以随意设置别名
cat<<eof>1.txt > cat11 > cat222 > cat333 > eof
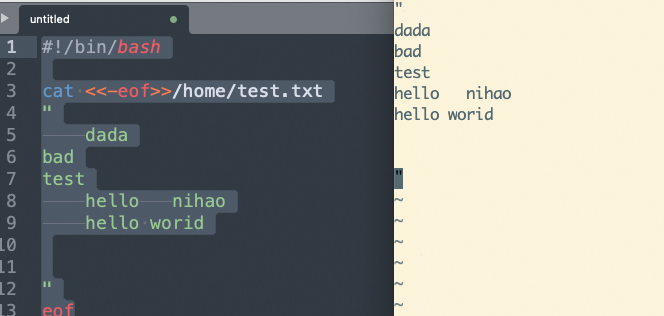
<<- 也是常用的一种写法,会忽略每行开始处的制表符(但仅限制表符,空格不会被忽略)
比如这段代码
#!/bin/bash
cat <<-eof>>/home/test.txt
"
dada
bad
test
hello nihao
hello worid
"
eof
相同功能也有其他场景的应用
# 这里文档可以与 ssh 命令一起使用,在远程主机上执行 echo 和 ls -l 命令。
ssh your_remote_host <<EOF
echo "登录到 $(hostname)"
ls -l
EOF
# 这会登录到 MySQL 数据库,选择特定的数据库,并执行查询。
mysql -u root -pYourPassword <<EOF
USE your_database;
SELECT * FROM your_table;
EOF
输出重定向
标准的输出重定向 命令 > 文件 完整的命令是 命令 1> 文件
标准错误输出重定向 错误命令 2> 文件
标准和错误的输出重定向 [错误]命令 > 文件 2>&1 也可以把2>&1 简写成&> [错误]命令 &> 文件
还可以标准和错误输出到不同文件 命令1 > 文件1 2>文件2 这里把正确命令保存到文件1,错误保存到文件2
bash一些基础的内置命令
- echo
-n 不换行输出
-e 解析字符串中的下面特殊字符
\n 换行
\r 回车
\t tab
\b 应使用字符之前或之间, 字符尾部跟\b 是没有效果的最前面使用 删除后面紧跟的字符,之间使用删除前一个字符
echo -e " \b哇\b哈哈"
哈哈
-
eval
把参数传给他,然后当命令执行 eval "cd /opt; ls -ll"
-
exec
不创建子进程,执行后续命令,且执行完毕后自动exit,下面就是执行date命令后退出了root账号
[root@django_env2 ~]# exec date 2022年 04月 06日 星期三 07:29:25 CST ────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────── Session stopped - Press <return> to exit tab - Press R to restart session - Press S to save terminal output to file
进程列表和子shell环境
shell的进程列表理念,要用到小括号() cd ~;ls;
检测是否在子shell环境中,输出BASH_SUBSHELL变量,如果是0,表示在当前shell环境,否则就是子shell运行的命令
一个小括号开启的是一个子shell命令(cd ~;ls;echo $BASH_SUBSHELL)
双引号=>弱化空格作为分隔符的作用 单引号=>强引用 弱化一切特殊符号的意义
假设我们使用子shell或反引用的方法将命令的输出保存到变量中,为了保留输出的空格和换
行符(\n),必须使用双引号。例如:
$ cat text.txt
1
2
3
$ out=$(cat text.txt)
$ echo $out
1 2 3 # 丢失了1、2、3中的\n
$ out="$(cat text.txt)"
$ echo $out
1
2
3
子shell嵌套运行
利用子shell,可以实现多进程的处理,提高程序并发执行效率.
比如运行(ls;echo $BASH_SUBSHELL;(cd /var;ls;echo $BASH_SUBSHELL))
运行结果
download nodejs860 ossutil python362 python_virtualenvwrapper redis-6.0.16 rh stunnel
1
account adm cache crash data db empty games gopher kerberos lib local lock log mail nis opt preserve run spool tmp www yp
2 # 代表第二个子shell
示例2
#!/bin/bash
ss &>/dev/null
if [[ `! ss &>/dev/null` ]]; then
echo "没有ss命令"
yum install -y ss &>/dev/null || (echo "ss命令无法安装";exit 1)
else
echo "有ss命令"
fi
算数运算符
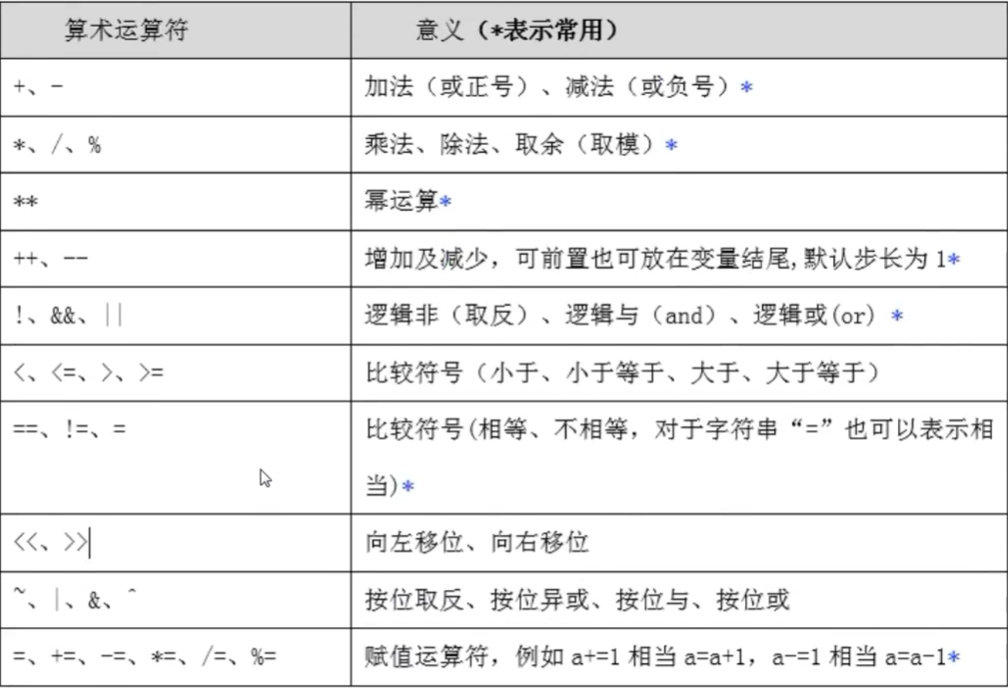
运算方式种类
-
用$(())进行计算,当计算用变量代入进去,括号里面的变量不用加$,但是这种方式不支持小数点计算
[root@django_env2 ~]# echo $((1+2)) 3 [root@django_env2 ~]# echo $((2*2)) 4 [root@django_env2 ~]# echo $((2/2)) 1 [root@django_env2 ~]# echo $((2**3)) 8 [root@django_env2 ~]# n=6;m=7 [root@django_env2 ~]# echo $((m*n)) 42 # 如果要把$写进去也是可以的 [root@django_env2 ~]# echo $(($m*$n)) 42 # 不支持小数计算 [root@django_env2 ~]# echo $(($m*$n*0.5)) -bash: 7*6*0.5: 语法错误: 无效的算术运算符 (错误符号是 ".5") -
let命令 更多可以用help let查看
[root@django_env2 ~]# n=6;m=7 [root@django_env2 ~]# let c=m*n [root@django_env2 ~]# echo $c 42 [root@django_env2 ~]# let c+=1 [root@django_env2 ~]# echo $c 43 -
expr命令 使用的时候表达式和符号之间要有空格 不支持幂次运算
[root@django_env2 ~]# expr 1+1 1+1 [root@django_env2 ~]# expr 1 + 1 2 [root@django_env2 ~]# expr 1 - 2 -1 [root@django_env2 ~]# expr 1 / 2 0 [root@django_env2 ~]# expr 1 * 2 expr: 语法错误 # *本来就是代表通配符,如果要用乘法要转义 [root@django_env2 ~]# expr 1 \* 2 2 -
bc 命令,需要用Yum 进行安装 支持小数计算,但是要是bc -L参数 bc是basic calculate的意思
正常输入bc 会进入交互式页面计算,如果不用交互式 就用 运算|bc [参数] bc运算中幂运算用^
[root@django_env2 ~]# echo 2*10|bc 20 [root@django_env2 ~]# echo 10/3|bc 3 [root@django_env2 ~]# echo 10/3|bc -l 3.33333333333333333333 [root@django_env2 ~]# echo 10%3|bc -l .00000000000000000001 [root@django_env2 ~]# echo 2^3|bc bc 关于计算浮点数的公式 echo "scale=3;6/4"|bc -
$[] 用的不多 不支持小数点运算
[root@django_env2 ~]# echo $[1+3] 4 [root@django_env2 ~]# echo $[2*3] 6 -
awk方法 awk 'BEGIN{print 计算1,计算2,计算3......}' 可以一次性输出多个计算结果
如果要用变量传数字计算需要用到-v参数
[root@django_env2 ~]# awk 'BEGIN{print 1+3,2*3,10/3}' 4 6 3.33333 [root@django_env2 ~]# awk -v n1=1 -v n2=2 'BEGIN{print n1+n2}' 3 # -v和n1变量也可以不带空格 [root@django_env2 ~]# awk -vn1=3 -vn2=4 'BEGIN{print n1*n2}' 12 # 变量传参 [root@django_env2 ~]# x=3 [root@django_env2 ~]# y=4 [root@django_env2 ~]# awk -vn1=$x -vn2=$y 'BEGIN{print n1*n2}' 12
几种运算方法比较
expr 能判断 参数是否为数字,如果不是数字会有报错信息 ,其他方法不会报错,然后可以用$? 进行判断上一次命令运行是否成功
[root@django_env2 ~]# echo $[a+1]
1
[root@django_env2 ~]# echo a+1|bc
1
[root@django_env2 ~]# echo $((a+1))
1
[root@django_env2 ~]# expr a + 2
expr: 非整数参数
bc 方法还可以用来进制转换 obase=进制;数字|bc
[root@django_env2 ~]# echo "obase=8;8"|bc
10
[root@django_env2 ~]# echo "obase=8;12"|bc
14
[root@django_env2 ~]# echo "obase=16;12"|bc
C
[root@django_env2 ~]# echo "obase=16;15"|bc
F
[root@django_env2 ~]# echo "obase=16;16"|bc
10
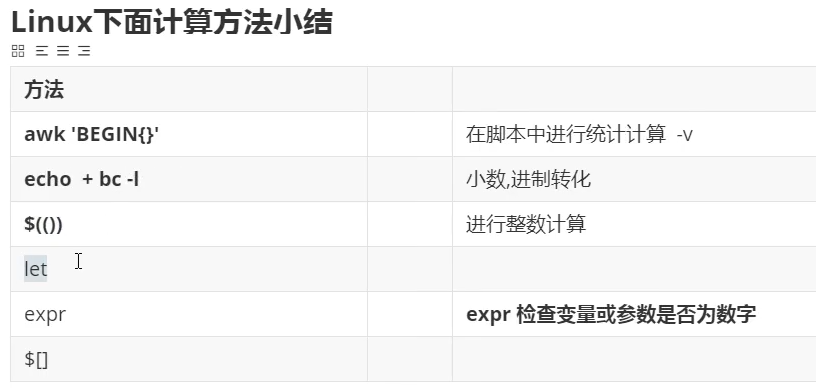
条件测试语句
条件测试语句类型
- 文件相关表达式
- 数字对比
- 字符串对比
- 逻辑:与或非
条件测试语句格式
更多可以参考man test或者man bash 搜索CONDITIONAL EXPRESSION
| test <条件> | test -f ./2.sh |
|---|---|
| [ <条件> ] | 一般用这种 注意左右留空格 [ -f ./2.sh ] |
| [[<条件>]] | 升级版 支持正则 |
| ((<条件>)) | 这种貌似有问题,试试路径加双引号 |
| [[ $str1 = $str2 ]]:当str1等于str2时,返回真。也就是说,str1和str2包 | |
| 含的文本是一模一样的。 |
条件参数
| 名称 | 含义 |
|---|---|
| -d | directory 目录是否存在 |
| -f | file 文件是否存在 |
| -e | exist 是否存在 |
| -r | read 文件是否存在并且是否有r权限 |
| -w | write 文件是否存在并且是否有w权限 |
| -x | execute 文件是否存在并且是否有x权限 |
| -s | size 文件是否存在并且是否为空 大于0成立 |
| -L | systemlink 文件是否存在并且是否为软连接 |
| -n | 判断变量是否有值 |
| f1 -nt f2 | file1 newer than file2 |
| f1 -ot f2 | file1 older than file2 |
| -z "STRING" | 字符串是否为空,空为真,不空为假 |
| -n "STRING" | 字符串是否不空,不空为真,空为假 |
| 注意 | 数字和数字比较必须用下面判断 |
| -eq | 判断两个数是否相等,相等为真 |
| -ne | 判断两个数是否相等,不等于为真 |
| -gt | 判断左边的数是否大于右边的,是则为真 |
| -ge | 判断左边的数是否大于等于右边的,是则为真 |
| -lt | 判断左边的数是否小于右边的,是则为真 |
| -le | 判断左边的数小于等于右边的,是则为真 |
条件判断示例语句
# 普通的判断,输入完后还要$? 看返回值, 可以用
[root@django_env2 ~]# [ -f ./2.sh ]
[root@django_env2 ~]# echo $?
0
# 可以和 && 和 || 一起用 直接输出结果
[root@django_env2 ~]# [ -f ./2.sh ] && echo "成功" || echo "失败"
成功
# 判断那个文件创建的时间早晚
[root@django_env2 ~]# [ ./1.sh -ot ./2.sh ] && echo "成功" || echo "失败"
成功
[root@django_env2 ~]# [ ./1.sh -nt ./2.sh ] && echo "成功" || echo "失败"
失败
常用的格式有如下搭配,可以替代if判断语句
-
满足条件,执行命令1
[ 条件 ] && 命令1
-
满足条件,执行多个命令
[ 条件 ] && {
命令1
命令2
}
-
如果条件不满足,再执行命令1
[ 条件 ] || 命令1
# 一个计算机的练习案例
#!/bin/bash
x=$1
y=$2
# 如果不是2个参数的话则提示,并返回1 ,1可以理解为自定义的错误代码
[ $# -eq 2 ] || {
echo "参数必须要有2个"
exit 1
}
expr $x + $y + 666 > /dev/null 2>&1 #把报错信息和正确计算结果不显示
[ $? -eq 0 ] || {
echo "$0 传参必须是数字"
exit 2
}
awk -vn1=$x -vn2=$y 'BEGIN{print n1+n2}'
# 判断当前用户是否是root的案例 用了判断uid和whoami的写法
#!/bin/bash
name=$UID
[ "$name" -eq 0 ]&& {
echo "yum install"
}
[ "$name" -eq 0 ]||{
echo "not root"
}
name=`whoami`
[ "$name" = "root" ] && echo "yum install" || echo "not root"
字符串 温馨提示变量必须要加双引号
注意点
- 字符串必须加引号,变量也要加
- 使用!=或者= 使用空格
- !=或者= 是用来比较字符串是否相同的

[root@django_env2 ~]# n1=old
[root@django_env2 ~]# n2=young
[root@django_env2 ~]# [ "$n1" = old ] && echo "是old" || echo "是young"
是old
[root@django_env2 ~]# [ "$n2" = old ] && echo "是old" || echo "是young"
是young
[root@django_env2 ~]# [ -n "$n3" ] && echo "不为空" || echo "为空"
为空
数组
数组语法
注意元素之间就是空格, 读取用${数组名称[index]} 起始索引为0
数组名称=(元素1 元素2 ...) 数组名称=([索引0]=元素1 [索引1]=元素2 ...)
arr=(1 2 3) arr=([0]=first [2]=second)
数组还可以把文件内容写入,比如arr=(`cat /etc/passwd`),每一行就是一个数组元素
数组增删改查
-
增 一次赋值一个 arr[0]=3
一次赋值多个 arr1=(1 2 3);arr2=(4 5 6)
-
查 declare -a 可以查看环境变量中的所有普通数组
也可以用${数组名称[@]} 或者 ${数组名称[*]} 查看所有数组的值
这里还可以结合变量的子串用法
${#数组名称[@]} 统计数组个数 ${!数组名称[@]} 获取数组元素的索引
${数组名称[@]:1} 切片,从下标1开始获取 ${数组名称[@]:1:2} 切片 从下标1开始向后截取2个元素
普通数组的常用循环调用方式
#!/bin/bash
for i in {1..4}
do
#这里用a++可以进行数组索引的自增,
#a++和++a都可以,区别和js一样 a++是先赋值再自增第一个是0,而后者是先自增再赋值,第一个索引是1
arr[a++]="数字$i"
done
# 一般都是遍历普通数组的索引,根据索引取出相应的数值
for i in ${!arr[*]}
do
echo "第$i个元素的值是${arr[$i]}"
done
关联型数组
普通数组默认索引是数字,但是用关联型数组可以自定义索引,也就是字典的key value概念
申明关系型数组方式和上面不同,用declare -A 数组名称进行申明
-
赋值 2种方式
-
arr[name]=alex
-
arr=([name]=alex [age]=18 [gender]=boy)
第二种的赋值会重新修改arr的变量,而不是只更改对应key的value值
也可以和上面一样和变量的子串功能一起使用
[root@django_env2 ~]# declare -A arr [root@django_env2 ~]# arr=([age]=19 [gender]=boy [name]=blex) [root@django_env2 ~]# echo ${arr[age]} age:19 [root@django_env2 ~]# echo ${#arr[@]} 3 [root@django_env2 ~]# echo ${!arr[@]} 0 1 2
-
-
用关系型数组用来进行统计数量
#!/bin/bash
#test.txt 写入3个aaa 1个bbb 1个ccc
declare -A test
for i in `cat test.txt`
do
let test[$i]++
done
循环体中的关键字
在for while循环体中会出现下面这些关键字,前面几个略,重点说下break和shift
: #同true
true
false
exit
continue
break
shift
break关键字
break有2种写法 一种就是break 跳出当前循环体, 另一种是后面加数字 break 2 就是跳出2层循环体
#!/bin/bash
for i in {1..9}
do
for j in {A..H}
do
echo "外循环是$i内循环是$j"
if [ $j = "D" ];then
break 2 # 2代表结束几层循环,2层就意味把外循环也跳出了,相当于exit
fi
done
done
shift关键字 用处不大,了解为主
shift会把传入的参数从右往左移动,每移动一次$1参数就丢弃,然后$2就变成了$1
下面这个脚本如果运行的方式是sh test.sh 1 2 3 4 5,会把5个数字依次向左移动,把$1传入后就丢弃,然后把$2移到$1的位置上.
最后的结果就是1+2+3+4+5 累加的值为15
#!/bin/bash
while [ $# -ne 0 ]
do
let num+=$1
shift
done
echo "累加的结果是$num"
for循环
语法 for 变量 in 序列1~100 示例: for number in {1..100}
do 放循环体语句 do echo number
done 结束for循环 done
还有一种就是条件循环
for((i=1;i<100;i++))
do
echo $i
done
在for循环中,默认的分隔符是空格和换行符,分隔符的变量是$IFS.如果用for循环批量读取文本内容,要先把默认的分隔符改成
old_ifs=$IFS
IFS=$'\n'
IFS=$old_ifs
注意上面$'\n'的写法,对于大部分字符串来说,以下三种是等价的 比如"test"和$"test"和$'test'
[root@django_env2 ~]# echo "test";echo $"test";echo $'test'
test
test
test
但是对于一些特殊的分隔符"\n"和$"\n"是一样的,就是\n的字符串 而$'\n'则代表的是换行符
下面是一段修改for循环的默认分隔符去把每行文本内容写入到普通数组的示例
#!/bin/bash
old_ifs=$IFS
IFS=$'\n'
for i in `cat /etc/passwd`
do
array[++b]=$i
done
for j in ${!array[*]}
do
echo "第$j个序列 数值是${array[$j]}"
done
IFS=$old_ifs
用for来遍历每行数据挺麻烦的,可以考虑用while或者bash内置的readarray或者mapfile命令来读取逐行数据,readarray和mapfile使用方法和参数都一样
下面是优化示例
#!/bin/bash
# 如果可用,使用readarray命令直接从文件读取到数组
if command -v readarray > /dev/null; then
readarray -t array < /etc/passwd
else
# 如果readarray不可用,使用while循环和read
b=0
while IFS= read -r line; do
array[b++]="$line"
done < /etc/passwd
fi
# 遍历数组并打印
for j in "${!array[@]}"; do
echo "第$j个序列 数值是${array[j]}"
done
for循环还有种很诡异的用法,可以遍历所有传入的参数,比如下面就写for i,然后sh test.sh 1 2 3 4 5
会依次把$1进行读取累加
#!/bin/bash
for i
do
let num+=$i
done
echo "累加的结果是$num"
if 判断
if后面要有空格,且[后面、]前面都要有空格,然后是分号,最后是then
里面有多个条件判断 -eq(equal) 相等 -ne(inequality) 不相等 -gt(greater than) 大于 -lt(less than) 小于 -ge(greater equal) 大于或等于 -le(less equal) 小于或等于
if里面的判断是不支持浮点数的
语法:
read -p "输入abcd" a
# 注意条件语句中 if then elif else 都是单独的命令,需要回车换行,也可以用封号在后面写成一行,注意下面三个条件不同的写法
if [ $a = "a" ]
then echo "选了a"
elif [ $a = "b" ]
then
echo "选了b"
elif [ $a = "c" ];then
echo "选了c"
else
echo "选了d"
fi
当一个if里有多条件判断的时候 用&&和|| 或者-a和-o 进行逻辑判断
-o = or , -a = and , 用-a -o 可以把多个逻辑判断写在一个 if [ 条件1 -a 条件2 ]
用&&和|| 则需要把多个逻辑判断分别单独写 if [ 条件1 ] && [ 条件2 ]
#!/bin/bash
read -p "输入时间" current_hour
#current_hour=date +%H
# 7点到11点 输出早上好
# 注意这一步讲默认的字符串进行整数类型转换
expr $current_hour + 0
if [ $current_hour -ge 7 -a $current_hour -le 11 ];then
echo "$USER 早上好啊"
# 12点到14点 输出中午好
elif [ $current_hour -ge 12 -a $current_hour -le 14 ];then
echo "$USER 中午好啊"
# 15点到18点 输出下午好
elif [ $current_hour -ge 15 ] && [ $current_hour -le 18 ];then
echo "$USER 下午好啊"
else
echo "$USER 晚上好啊"
fi
if 嵌套分支之 用命令运行结果进行判断
#判断用户是否存在
# 存在
# 提示用户已存在
# 不存在
# 1.创建用户
# 2.提示输入密码
# 密码小于7位 提示密码不符合要求
# 密码大于7位 创建用户
#!/bin/bash
read -p "输入账号" user_name
# 如果只是获取命令运行结果的真假,直接 if 命令;then 即可
if id $user_name;then
echo "$user_name 用户已存在"
else
echo "开始创建用户 $user_name"
read -p "输入密码" pwd
if [ ${#pwd} -gt 5 ];then
useradd $user_name
#这个是交互式下把密码变量输入进去进行更改密码,后面可以用expect进行更简单的操作
echo $pwd| passwd --stdin $user_name
#也可以把改密码后的提示内容丢弃不输出
#echo $pwd| passwd --stdin $user_name &> /dev/null
echo "$user_name 密码设置为 $pwd"
else
echo "密码应该大于5位"
fi
fi
if示例 之 丢弃屏幕输出返回结果
用&> /dev/null或者 >/dev/null 2>&1
#!/bin/bash
url=$1
ping -c2 -i0.2 -W0.5 $url >/dev/null 2>&1 # -c是ping的次数 -W是timeout -i是间隔时间
if [ $? -eq 0 ];then
echo "$url 正常"
else
echo "$url 不正常"
fi
模式匹配 case
case语法
case 变量 in
模式1)
命令序列1
;; # 每个case都是用);;进行分隔
模式2)
命令序列2
;;
*)
无匹配后命令序列
esac
案例展示
#!/bin/bash
#case 语法练习
read -p "输入账号" yesorno
case $yesorno in
y)
echo "输出y"
;;
yes)
echo "输出yes"
;;
n)
echo "输出n"
;;
no)
echo "输出no"
;;
*)
echo "啥也不是"
;;
esac
堡垒机示例
#!/bin/bash
#堡垒机 语法练习
web1=192.168.248.139
web2=192.168.248.140
cat<<eof
1.web1
2.web2
eof
read -p "输入序号,其他任意键退出" machine
case $machine in
1)
ssh root@$web1
;;
2)
ssh root@$web2
;;
*)
echo "退出了"
exit
;;
esac
while语句结构
语法格式 退出循环和python一样 也有exit break continue三个
while 条件测试
# while : 冒号代表为真
do
循环体
done
案例1
while :
do
let i++
echo $i
sleep 1
if [ $i -eq 8 ];then
break
fi
done
echo "循环完毕!!"
while还可以通过读取文件的形式进行循环,会每次输出一行,直到全部输出完毕结束死循环
#这种while用法一般不推荐,并且效果和for循环遍历一样,只是说明下有这种用法
#2种区别在于 while是把换行符当分隔符,而for是把空格和换行符都当分隔符
while read aaa for i in `cat /etc/passwd`
do do
echo $aaa echo $i
done < /etc/passwd done
#对于上面 done < /etc/passwd 可能不太好理解,是因为脚本执行其实都是一行执行,只不过我们编写时候为了看起来方便理解,会换行表述
#如果把上述的while语句看成一行 while read aaa;do echo $aaa;done < /etc/passwd 这个语句while ...done是一个整体,后面的< /etc/passwd是
#每次把一行的文本内容输入重定向到while中去,然后用aaa这个变量接收而已 当文件读取完毕后 while read aaa这段代码中read aaa其实就是false了.
while还可以遍历多行文本
#!/bin/bash
ret="
11 22 33
aa bb ccc
"
echo "$ret" |while read aaa; do
echo "${aaa}"
echo "-----"
done
expect
安装
yum install -y expect tcl tclx tcl-devel
tcl全称 tools command lanuage
示例1 解决ssh交互问题
注意 编写的脚本可以改后缀为.exp 来区分sh和exp,shell语言对后缀不敏感.
执行用./执行而不是用bash执行
还有#!/usr/bin/expect 必须要写在第一行
调用就用bash调用./aaa.exp 要赋予运行权限,这种调用模式是调用sh,然后sh根据第一行声明再调用expect进行解析执行
另一种就是直接指明expect路径运行脚本 /usr/bin/expect aaa.exp
#!/usr/bin/expect
spawn ssh root@192.168.1.2 #spaawn expect的内部命令,启动shell程序
expect {
粘贴交互时候的对话问题,截取部分代表性的即可 { send "yes\r"#输入交互时候你会输入的内容,回车用\r代替 }
} #expec期望哪些内容
interact #允许交互,如果不添加,会立即结束 spawn 后面运行的shell进程
exp_continue #对于那些不是会交互的内容 用这个,如果没交互则跳过执行下一条
#ssh 登陆主机 shell示例
#!/usr/bin/expect
spawn ssh root@192.168.248.140
expect {
"connecting (yes/no)" {send "yes\r";exp_continue}
"password" {send "root\r"};
}
interact
# 创建密钥并上传主机实现免密登录的示例
#!/usr/bin/expect
# 生成密钥 -t是密钥类型
spawn ssh-keygen -t rsa
expect {
"file in which to save the key" {send "\r";exp_continue}
"Enter passphrase (empty for no passphrase" {send "\r";exp_continue}
"Enter same passphrase again" {send "\r";exp_continue}
}
# 把密钥上传给主机
spawn ssh-copy-id 192.168.248.140
expect {
"Are you sure you want to continue connecting (yes/no)" {send "yes\r";exp_continue}
"'s password" {send "root\r";exp_continue}
}
# interact 上传就结束了,因此可以不需要保留这个交互界面
# 讲expect放入到bash脚本中调用示例
#!/bin/bash
>live_ip.txt
for i in {3..141}
do
{
ip=192.168.248.$i
ping -c1 -W1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo $ip >> live_ip.txt
#这里是上传密钥的expect的脚本
/usr/bin/expect <<-EOF #加载expect文件路径 可以改成随机定义的字符串比如aaa
spawn ssh-copy-id $ip
expect {
"Are you sure you want to continue connecting (yes/no)" {send "yes\r";exp_continue}
"'s password" {send "root\r"};
}
expect EOF # 表示问题回答完毕退出 expect 环境
EOF #这个EOF是为了对应上面的加载文件路径的-EOF 如果上面是aaa这里也是aaa
fi
} &
done
expect语法的2种调用方法
- 直接和bash语法写在一起用输入重定向调用 这种模式最后通常不需要加interact,加了交互保持模式对于切换成shell语言反而有问题
#!/bin/bash
>live_ip.txt
for i in {3..141}
do
{
ip=192.168.248.$i
ping -c1 -W1 $ip &> /dev/null
if [ $? -eq 0 ];then
echo $ip >> live_ip.txt
#这里是上传密钥的expect的脚本,用输入重定向把expect语法传入给/usr/bin/expect进行解析
/usr/bin/expect <<-aaa
spawn ssh-copy-id $ip
expect {
"Are you sure you want to continue connecting (yes/no)" {send "yes\r";exp_continue}
"'s password" {send "root\r"};
}
expect EOF
aaa
fi
} &
done
- 保存到文件中,在bash指定expcet路径调用(推荐用这种),这种最后通常要加interact用来保持交互状态
#!/bin/bash
for i in {3..7}
do
{
echo $i
} &
done
wait
/usr/bin/expect /root/load.exp
expect其他的命令参数
| 名称 | 含义 |
|---|---|
| set timeout n | 设置超时时间,表示该脚本代码需在n秒钟内完成,如果超过,则退出。如果设置为-1表示不会超时 |
| $argv | 可以使用[ lindex $argv n ]n为0表示第一个传参,为1表示第二个传参 |
| set | 定义变量 |
| exit | 退出expect脚本 |
示例,把expect单独放一个文件,然后通过shell位置传参,再传入到exp脚本中实现用户新增
#!/bin/bash
username=$1
echo $username
if ! id $username;then
echo "params is $username"
/usr/bin/expect add.exp $username
fi
# 下面是同路径下的add.exp脚本
#!/usr/bin/expect
set timeout 10
set username [ lindex $argv 0 ]
spawn echo "params is $username"
spawn useradd $username
interact
函数
定义函数的2种方式
- 函数名()
- function 函数名
函数的调用与传参
#!/bin/bash
test (){
expr $1 \* 10
expr $2 \* 10
}
function test2(){
expr $1 \* 10
expr $2 \* 10
}
test $1 $2
test2 $1 $2
#用数组进行传参示例
#!/bin/bash
array (){
st=1
# $*这里是获取数组里的所有内容,传参也是传的所有内容
for i in $*
do
echo $i
st=$[$st*$i]
done
echo $st
}
num=(3 4 5)
array ${num[*]}
函数的返回值
(1).使用return返回值:
使用return返回值,只能返回1-255的整数
函数使用return返回值,通常只是用来供其他地方调用获取状态,因此通常仅返回0或1;0表示成功,1表示失败
(2).使用echo返回值:
使用echo可以返回任何字符串结果
通常用于返回数据,比如一个字符串值或者列表值
#!/bin/bash
#阶乘函数
jiecheng (){
aa=1
for((i=1;i<=$1;i++))
do
aa=$(($aa*$i))
done
#用echo把返回值返回
echo $aa
}
ret=$(jiecheng $1)
echo "$1 de jie cheng shi $ret"
输出结果: 5 de jie cheng shi 120
linux的三剑客 sed awk grep和正则
正则
linux的正则可以被vim sed awk grep所使用到
在if中使用必须用双中括号,并用=~作为正则判断的标准写法,比如判断是否数字if [[ $num =~^[0-9]+$ ]]
正则元字符
^ $ . * [] 比较熟悉,略
[-] 匹配指定范围的一个字符,连续的范围 grep "[a-z]ove" 1.txt 就会匹配到love这种单词
[^] 匹配不在指定范围内的字符 grep "[^a-z]ove" 1.txt 就不会匹配到love这种单词
\ 单引号 双引号 \都可以转义
\< 词首定位符 和^区别一下,^是行首定位,所以以行为单位判断,词首是以每个单词的词首
\> 词尾定位符 和$区别一下,$是行尾定位,所以以行为单位判断,词尾是以每个单词的词首
() 就是分组,如果一个正则里多个(),后面用\1 \2代表分组里匹配到的内容 \1代表第一个()匹配到的内容
举个例子,比如对#abc123,我们要实现把#放到末尾 在vim中: s/\(#\)/\(.*\)/\2\1
\2代表(.*)匹配到的abc123
\1代表(#), 然后把两组的位置互换实现效果
^$ 代表空行
x\{m\} x\{m,\} x\{m,n\} 分别代表x字符出现m次 出现m次以上 出现m次到n次之间 \{ \}只是转义符
正则扩展元字符 有这些扩展元字符grep必须带-E参数 或者用egrep才能支持
+ 1-n个
? 0-1个
a|b
()
正则表达式匹配操作符
1. 基本匹配操作符:
= 或 ==: 完全匹配。检查字符串是否与正则表达式完全相同。
!= 或 <>: 不完全匹配。检查字符串是否与正则表达式不完全相同。
2. Shell 中的匹配操作符:
=~: 正则表达式匹配。检查字符串是否包含与正则表达式匹配的内容。
!~: 正则表达式不匹配。检查字符串是否不包含与正则表达式匹配的内容。
3. Perl 兼容的正则表达式 (PCRE) 中的匹配操作符:
=~: 正则表达式匹配。通常用于 Perl、PHP 和其他支持 PCRE 的语言中。
!~: 正则表达式不匹配。
4. 其他工具中的匹配操作符:
grep: 使用 -E 或 -P 选项启用正则表达式匹配,默认情况下使用基本正则表达式。
sed: 使用 -E 或 -r 选项启用扩展正则表达式,默认情况下使用基本正则表达式。
awk: 默认情况下支持扩展正则表达式。
sed
sed命令是按顺序逐行读取文件。然后,它执行为该行指定的所有操作,并在完成请求的修改之后的内容显示出来,也可以存放到文件中。完成了一行上的所有操作之后,它读取文件的下一行,然后重复该过程直到它完成该文件。返回值 不论对错,执行结果都是0 只有当命令有语法错误时候返回才是非0
命令语法
sed 选项 命令 文件(这种模式用的多)
常用的选项
-n, --quiet, --silent 默认sed会打印一遍文本的所有内容,-n可以取消自动打印模式空间 -n加命令/p 可以打印匹配规则的那条记录
-e 脚本, 这里的脚本理解为匹配命令 比如要匹配 py开头和PY开头的内容 sed -n -e "/py.*/p" -e "/PY.*/p" abc.txt
-r, --regexp-extended 在脚本中使用扩展正则表达式 正则可以让上面写法更简洁 sed -n -r "/py.*|PY.*/p" abc.txt
-f 脚本文件, --file=脚本文件 这里的文件指把匹配规则写到文件中,用-f指定这个规则文件进行匹配 不常用
-i[扩展名], --in-place[=扩展名] 直接修改文件(如果指定扩展名就备份文件)
sed常用的pattern用法
pattern用法:
1、 LineNumber 直接指定行号
sed -n "17p" file 打印第17行
2、StartLine,EndLine 指定起始行号和结束行号
sed -n ”10, 20p" file 打印从10-20行的内容
3、 StartLine,+N 指定起始行号,然后后面N行
sed -n ”10,+5p” file 打印从10行开始,后面加5行的内容
4、 /patternl/ 输出符合正则匹配规则的行数
sed -n ”/^root/p” file 打印以root开头的行
5、/patternl/,/pattern2/ 从pattern1规则开头,到pattern2规则结束,如果pattern2未匹配到则全部输出
sed -n ”/ftp/,/mail/p” file 输出第一个ftp开头的行,直到mail开头的行,如果没有匹配到mail开头则全部输出
6、LineNumber,/patternl/ 从指定行号开始到指定匹配规则结束
sed -n "4,/^hdfs/p” file
7、/patternl/,LineNumber 从指定匹配规则开始到指定行号结束
sed -n "/root/,10p" file
sed常用命令
这里的命令和上面的pattern一起搭配 比如sed /patternl/,/pattern2/d 就是把符合pattern1到pattern2的规则的内容删除
sed /patternl/,/pattern2/w file1 就是把符合pattern1到pattern2的规则的内容写入到file1文件
sed /patternl/,/pattern2/r file1 就是把file1文件内容写到符合pattern1和pattern2的规则的内容前
删除命令 d
后面指定文件的内容追加到匹配到的行后面 (支持正则) r
把匹配到的行内容另存到其他文件中 (支持正则) w
追加命令 a(之后)
插入命令 i(之前)
替换整行命令 c
获取下一行命令 n
反向选择 !
多重编辑 e
输出打印 p 通常和-n选项一起搭配使用 比如sed -n "2,+3p" 2.txt 输出第二行和下面三行内容
替换命令语法和其他不太一样
's/pattern/string/' 查找符合pattern的内容替换成string
's/pattern/string/g' 全局替换
's/pattern/string/2' 一行内只替换第二个符合pattern的字符串
's/pattern/string/gi' 全局替换+忽略大小写
&和\1 也是替换命令中的反向引用,说白了就是把符合匹配的内容用&或者\1作为一个变量去引用,而&或者\1就是被匹配到内容的本身
sed -i 's/ad..n/&A/' test.txt 这个写法可以把admin adxxn等内容后面加个A &A代表把admin替换成adminA
\1和& 虽然效果一样,不过对匹配到的内容要实现部分替换 要使用\1用法
\1用法使用时候前面匹配部分要用()括起来,并且()也要转义
sed -i 's/\(ad..n\)/\1A/' test.txt
如果要对匹配到的admin 只是把min替换AA
sed -i 's/\(ad\)\(..\)n/\1BB/' 2.txt 这里\1感觉想有名分组的序列号,如果\0还是会把所有匹配的内容后面添加BB
匹配前
-rwxrwxrwx 1 root root 144 Sep 16 2022 1.sh
-rw-r--r-- 1 admin root 6 Aug 26 2022 1.txt
drwxr-xr-x 3 root admin 4096 Oct 19 19:20 docker
匹配后
-rwxrwxrwx 1 root root 144 Sep 16 2022 1.sh
-rw-r--r-- 1 adAA root 6 Aug 26 2022 1.txt
drwxr-xr-x 3 root adAA 4096 Oct 19 19:20 docker
对变量内容替换
root@iZi7moesa6tik9Z:~/shixiaofeng# oldstr=root
root@iZi7moesa6tik9Z:~/shixiaofeng# echo $oldstr
root
root@iZi7moesa6tik9Z:~/shixiaofeng# newstr=ROOT
root@iZi7moesa6tik9Z:~/shixiaofeng# sed -i "s/$oldstr/$newstr/g" 2.txt 这里要注意不要用单引号 因为单引号会让$失去原有的作用.
root@iZi7moesa6tik9Z:~/shixiaofeng# cat 2.txt
total 21436
-rwxrwxrwx 1 ROOT ROOT 144 Sep 16 2022 1.sh
-rw-r--r-- 1 ROOT ROOT 6 Aug 26 2022 1.txt
sed范围
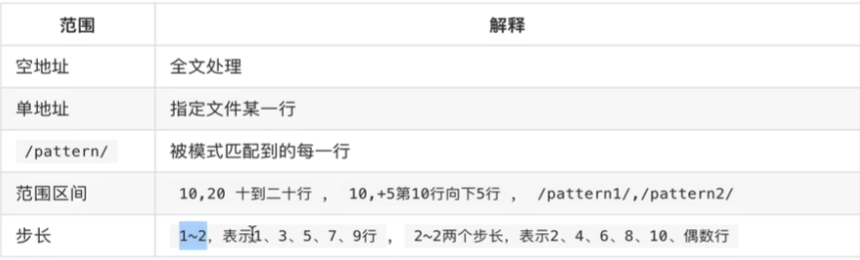
sed命令和正则的搭配使用示例
A. 删除命令 d
sed -r "3d" passwd 这里3d是数字+命令的模式,3代表行号,行号也可以用"1,3"或者"2,$"格式表示,$表示尾行 d代表删除 就是删除第三行
正规的写法还可以写成 sed -r "3{d}" passwd 这里{}里可以写多条命令用封号隔开,
如果有多条命令,代表的是对同一行进行多条命令的操作
B. 替换命令 s/替换前内容/替换后内容/
sed -r "s/^root/aaa/g"
sed -r "s/^[0-9][0-9]$/&.5/" 等同于 "s/(^[0-9][0-9]$)/\1.5/" 这个例子主要展示了\1和$的相同功能,就是充当了前面匹配到的分组内容的变量
sed -r "s#^root#aaa#" 这里的#等于\/ 考虑到替换的内容有可能是"/"本身用#代表了/,也可以用转义符号\/实现
C. 读文件命令 r filename
1.txt 有4行 分别是111 222 333 444,2.txt就一行hello
sed "r 2.txt" 1.txt
输出结果是,sed是逐行读取1.txt,然后每读1行后再读2.txt里的内容
111
hello
222
hello
333
hello
444
hello
sed "\$r 2.txt" 1.txt 语句效果等于 sed '$r 2.txt' 1.txt 区别是一个用了双引,弱引用,对元字符$要转义,强引用单引号则不用
$在这里是尾行的意思,也可以用数字表示行数
在vim也有类似的语法比如:$ r 2.txt
111
222
333
444
hello
sed "/222/r 2.txt" 1.txt
/222/r 2.txt 是对1.txt文本匹配到222这一行进行读取2.txt输出
输出结果
111
222
hello
333
444
D. 另存为文件命令 w filename
sed "w 5.txt" 1.txt 把1.txt文本逐行读取写到5.txt
sed "/222/w 5.txt" 1.txt 把1.txt文本逐行然后把匹配到的222另存到5.txt
E. 插入命令 追加命令 a(之后) 插入命令 i(之前)
sed "3atest" 1.txt 把test插入到 1.txt内容的第三行后
sed "3itest" 1.txt 把test插入到 1.txt内容的第三行后
如果要插入多行,比如插入3行内容为aaa bbb ccc,在aaa后输入转义符后按回车,把回车转移掉,输入其他内容按回车换行,在最后内容补上单引号 和文件的名称
sed '3iaaa\
> bbb
> ccc' 1.txt
用双引号也可以,就是对\要进行转义
sed "3iaaa\\
> bbb\\
> cccc" 1.txt
F. 替换整行命令 c 找到1.txt文本中的222内容,然后把这行内容整行替换成 "tihuan"
sed -ri "/222/c tihuan" 1.txt
和上面的写法差不多,还可以替换多行内容,比如下面就是把2至4行替换成aaa和bbb两行内容.注意2,4是范围替换,而不是在第2行和第4行替换
sed -ri '2,4c aaa\
bbb' 1.txt
G. 获取下一行命令 n 一般和其他命令一起搭配使用
sed '/bb/{n;d}' 1.txt 匹配到bb这一行,然后把它的下一行删除
H. 反向选择 !这里的!不是针对命令取反,而是针对条件范围取反
比如下面的!s/111/zzz/取反是针对前面的2,$范围进行取反,最终结果是除了2到尾行,其他行(第1行)把111替换成zzz
sed '2,$ !s/111/zzz/' 1.txt
I. 多重编辑 对于指定的一个范围多条命令一起执行就要用
这里主要有三种写法
写法1:
命令的完整写法是写在{}里的,
比如sed 's/111/222/' 1.txt 完整的写法是 sed '{s/111/222/}' 1.txt
比如sed '3d' 1.txt 完整的写法是 sed '3{d}' 1.txt
多条命令可以写在{}中,用;隔开
sed '1,${s/111/222/;s/fff/zzz/}' 1.txt 先把111换成222再把fff换成zzz
sed '{s/111/222/;s/fff/zzz/;n;d}' 1.txt 先把111换成222再把fff换成zzz然后把zzz下一行删除 但是会多删除其他内容,暂时没搞懂
sed '{/bbb/d;/fff/d}' 1.txt 找到bbb这一行删除,再找到fff这一行
写法2:
多个命令之间封号隔开
sed '2 d;s/888/999/' 1.txt
但是注意这种写法有些命令无法正常执行,比如sed '2c 22222;3c 33333' 1.txt
我们本意是想第二行都替换2222 第三行替换33333 但是实际执行会把第二行替换成22222;3c 33333
对封号用转义符号也没用,这个时候用第三种
写法3:
用-e参数
sed -e '2c 22222' -e '3c 33333' 1.txt
J. 追加变量 sed命令可以加入变量
[root@django_env2 ~]# name=boss
[root@django_env2 ~]# sed "2,3s/888/$name/" 1.txt
111
777
boss
ddd
bbb
eee
fff
ggg
这里要注意,"2,3s/888/$name/"如果改成了单引号,会有问题,因为单引号是强引用,会转义$name的变量意义,而变成字符串'$name'
[root@django_env2 ~]# sed '2,3 s/888/$name/' 1.txt
111
777
$name
ddd
bbb
eee
fff
ggg
具体应用案例
sed '/^$/d' 1.txt删除所有的空行sed 's/^#//g' 1.txt==sed -r 's/(^#)(.*)/\2/' 1.txt删除所有的#号sed -r '/maxsize=/s/2G/5G/' 1.txt把error_log "pipe:rollback logs/error_log interval=1d baknum=7 maxsize=2G"中的2G改成5G
/maxsize=/s/2G/5G/分成2部分看 /maxsize=/是第一部分,匹配到有这个参数的那一行,第二部分s/2G/5G/ 把该行的2G改成5Gsed -r '2,$s/^/#/' 1.txt==sed -r '3,$ s/(.*)/#\1/' 1.txt==sed -r '3,$ s/(.*)/#$/' 1.txt给2至尾行都在行首加个#
awk
awk主要是用来做数据进行做切片处理的,也是一门单独的编程语言,数据可以来源于文件,标准输入,或者其他命令的输出,支持自定义函数和正则
awk处理方式,逐行处理,对整行内容赋予$0的位置变量,然后默认按空格后者制表符分解,最多分解成100个位置,存储在$1-$99的位置变量中
options
commands 大致分为过去,现在和将来三大区域,三个区域分别用BEGIN{} {} END{}表示,注意全部是大写
awk基本语法:awk -F|-f|-v 'BEGIN{ } / / {comand1;comand2} END{ }' file
示例文章:https://blog.csdn.net/sunboylife/article/details/105946062
-F 定义列分隔符
-f 指定调用脚本
-v 定义变量
' '引用代码块,awk执行语句必须包含在内
BEGIN{ } 初始化代码块,在对每一行进行处理之前,初始化代码,主要是引用全局变量,设置FS分隔符
{ } 命令代码块,包含一条或多条命令
// 用来定义需要匹配的模式(字符串或者正则表达式),对满足匹配模式的行进行上条代码块的操作
END{ } 结尾代码块,在对每一行进行处理之后再执行的代码块,主要是进行最终计算或输出结尾摘要信息
内部常用变量
-
FS 输入字段的分隔符(默认是空格) awk 'BEGIN{FS=":"}{print $1,$2,$3}' /etc/passwd awk -f: '{print $1}' /etc/passwd
-
OFS 输出字段的分隔符(默认是空格) awk 'BEGIN{FS=":";OFS="###"}{print $1,$2,$3}' passwd.txt /etc/passwd
-
RS 标准输入的分隔符(默认是换行符)
-
ORS 输出记录的分隔符(默认是换行符) awk 'BEGIN{OF=":";ORS="@@@"}{print $1,$2,$3}' passwd.txt 看下面输出结果就懂,RS是修改输入的分隔符
root:x:0:0:root:/root:/bin/bash @@@@@@@bin:x:1:1:bin:/bin:/sbin/nologin @@@@@@@daemon:x:2:2:daemon:/sbin:/sbin/nologin @@@@@@@adm:x:3:4:adm:/var/adm:/sbin/nologin @@@@@@@lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin @@@@@@@sync:x:5:0:sync:/sbin:/bin/sync @@@@@@@shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown @@@@@@@halt:x:7:0:halt:/sbin:/sbin/halt @@@@@@@mail:x:8:12:mail:/var/spool/mail:/sbin/nologin -
NR 当前记录数 awk开始执行程序后所读取的数据行数 从头到尾自增序号
-
FNR 同NR相对于当前文件 awk每打开一个新文件 FNR便从0重新累计 awk '{print FNR,$0}' file1 file2
对不同的文件打印各自的行号,而NR不一样,是合并打印,具体看下面例子的行号FNR NR 1 文件aa第1行 1 文件aa第1行 2 文件aa第2行 2 文件aa第2行 3 文件aa第3行 3 文件aa第3行 1 文件bb第1行 4 文件bb第1行 2 文件bb第2行 5 文件bb第2行 3 文件bb第3行 6 文件bb第3行 -
NF 根据分隔符计算每行的列数
awk 'BEGIN{FS=":"}{print NF,$0}' /etc/passwd
而NF因为会包含行数,还可以在()中进行变量计算
awk 'BEGIN{FS=":"}{print $(NF-6)}' /etc/passwd
对于下面数据,拆分后有些是2列,有些是3列,如果要显示最后一列可以利用NF特性显示[root@iZi5c01rx5nrerayjtd4qxZ ~]# cat /etc/shells /bin/sh /bin/bash /usr/bin/sh /usr/bin/bash [root@iZi5c01rx5nrerayjtd4qxZ ~]# cat /etc/shells |awk -F/ '{print $NF}' sh bash sh bash
格式化输出 print函数
比如我们对date函数的日期进行分割处理
[root@django_env2 ~]# date | awk '{print $1 $2}'
2022年04月
[root@django_env2 ~]# date | awk '{print $1,$2,$3}'
2022年 04月 21日
[root@django_env2 ~]# date | awk '{print "年份是" $1,"月份是" $2,"日期是"$3}'
年份是2022年 月份是04月 日期是21日
[root@django_env2 ~]# date | awk '{print "年份是" $1,"月份是\t" $2,"日期是"$3}'
年份是2022年 月份是 04月 日期是21日
内置字符串处理函数
gsub ( r, s )在整个$0中用s替代r awk 'gsub(/6\./,78) {print $0}' data.f 将所有“6.”换成78,并输出
gsub ( r, s , t )在整个t中用s替代r
index ( s , t )返回s中字符串t的第一位置
length ( s )返回s长度 awk ‘{if($3==”3BC1997″) {print length($3)}}' data.f awk '{print length($1),$1}' ip.txt
match ( s , r )测试s是否包含匹配r的字符串,返回位置 awk ‘BEGIN{print match(“ABCD”,/B/)}' :“//”和“”””效果一样
match里还可以用正则
[root@iZi5c01rx5nrerayjtd4qxZ ~]# cat /etc/shells
/bin/sh
/bin/bash
/usr/bin/sh
/usr/bin/bash
[root@iZi5c01rx5nrerayjtd4qxZ ~]# cat /etc/shells|awk -F/ 'match($NF,/^ba/) {print $NF}'
bash
bash
[root@iZi5c01rx5nrerayjtd4qxZ ~]# cat /etc/shells|awk -F/ '!match($NF,/^ba/) {print $NF}'
sh
sh
split ( s , a , fs )在fs上将s分成序列a awk ‘BEGIN {print split(“123#234#654″, myarray, “#”)}'返回数组元素个数,123#234#654是字符串,以“#”为分隔符,将字符串放入数组。
sprint ( f m t , exp )返回经f m t格式化后的exp
sub ( r, s ,$0) $0中s替换第一次r出现的位置
substr ( s , p )返回字符串s中从p开始的后缀部分
substr ( s , p , n )返回字符串s中从p开始长度为n的后缀部分 awk 'BEGIN{print substr(“helloleeboy”,2,7)}' data.f 输出n遍ellole,n为data.f的行数
还可以利用substr和index对分隔符只进行一次分隔
echo "apple-orange-banana" | awk '{ part1=substr($0, 1, index($0, "-")-1); part2=substr($0, index($0, "-")+1); print part1, part2}'
自定义输出的字符串格式
在 awk 中,你可以使用 printf 函数来自定义输出格式。printf 函数允许你指定输出字符串中的格式化参数,这样你就可以控制输出的外观,比如数字的小数位数、对齐方式等。
假设我们有一个简单的文本文件 data.txt,其中包含一些数值:
$ cat data.txt
10
20.5
30.25
40.75
如果我们想要以两位小数的格式输出这些数值,并且在每个数值前面加上 "Value: ",我们可以这样做:
$ awk '{printf "Value: %.2f\n", $1}' data.txt
Value: 10.00
Value: 20.50
Value: 30.25
Value: 40.75
查看内存使用率
free -m | awk 'NR==2{printf "%.2f%%\n", ($3/$2)*100}'
1.74%
free -m
total used free shared buff/cache available
Mem: 15874 278 188 120 15407 15150
Swap: 0 0 0
模式(正则)和动作
在awk语句中引号中间的也可以是模式加动作函数组成
如果省略模式部分,动作将时刻保持执行状态,每一行都会有动作
模式可以是任何条件语句或者正则表达或者复合语句,有模式的话就是根据模式产生对应的动作
-
字符串比较
awk '/^root/' /etc/passwd输出正则语法root开头的内容
awk '$0~/^root/' /etc/passwd在正则中=~是作为正则匹配的语法,在awk中直接用~也是表示用正则的语法,搭配位置变量一起使用
$0 是指每行的所有内容,输出root开头的内容
awk '$0!~/^root/' /etc/passwd!就是取反,输出每行非root开头的内容
awk -F: '$1~/^root/' /etc/passwd这里和上面不同了,$1表示冒号分隔符中提取每行第一列的数据,如果是root开头则输出该行内容
输出结果为root:x:0:0:root:/root:/bin/bash -
数值和字符串比较
关系运算符
< >
<= >=
==和!= 可以数字和字符串判断,其他都是数值判断
示例
awk -F: '$1=="root"' /etc/passwd
awk -F: '$3<10' /etc/passwd算术运算
示例
+-*/%(模)^(幂)
awk -F: '$3+500>1000' /etc/passwd -
多条件
逻辑判断
&& || !
awk -F: ' $3 < 5 && $1~/^root/' /etc/passwd
awk -F: '$3 < 50 || $1 ~/^root/' /etc/passwd
范围模式
语法:awk '/从哪里/,/到哪里/' filename
awk '/daemon/,/7:0/' passwd.txt
awk编程
变量
- 自定义内部变量 -v参数
awk -F: -v name=root '$1==name' passwd.txt这里注意awk中变量不用带$,看后面这个$1==name - 外部变量
外部变量和上面自定义内部有个不同的地方,内部定义的变量是不用加$的,但是如果是外部的变量,因为是shell定义的,因此在调用的时候还是要加$- 双引号 当调用外部变量时,外部使用双引号,内部也使用双引号,但内部双引号需要转义,awk本身的位置变量$也要被转义
name="root";awk -F: "\$1==\"$name\"" passwd.txt - 单引号 对下面"'"$name"'"语法的理解要分2步骤,
第一步单引号调用为 '$1'$name'',外部用单引号,对$name也用单引号
第二步,单引号为强引用,用来否定特殊字符特殊含义,但是这里套了2层单引号,双重否定等于肯定,意味着'$name'的转义取消了, 因此在分别在前后加上双引号
即"'"$name"'" ,对单引号再进行转义,让awk语法进行识别,总结一句话使用单引号时候,内部要用双引转义==
示例:awk -F: '$1=="'"$name"'"' passwd.txt和awk -F: '$1 ~"'"$name"'"' passwd.txt
- 双引号 当调用外部变量时,外部使用双引号,内部也使用双引号,但内部双引号需要转义,awk本身的位置变量$也要被转义
条件和判断
-
if(条件测试){执行语句}
awk -F: '{if($3==0){print $1" 是管理员"}}' passwd.txt如果$3为0,则打印$1是管理员
cat /etc/mongod.conf.orig |awk '{if($0 !~ /^$/ && $0 !~ /^#/) {print $0}}'过滤配置文件的空行和#开头的注释行,把其他内容打印出来
awk '/inet/{if($2~/([0-9]{1,3}\.){3}[0-9]{1,3}/){print $2}}' ip.txtif中使用~进行正则匹配判断,这里是找出ip地址
awk ‘{if(/[Ss]ept/) print $0}' data.f模糊匹配 大小写匹配
awk ‘{if($2 ~/^.e/) print $0}' data.f:模糊匹配 第二字段中,第二个字符为e,输出
awk ‘{if($4 ~/(lps|fcx)/) print $0}' data.f:模糊匹配 第四个字段含有lps或fcx则输出
注意在awk中,~是一个匹配操作符,~/^root/是一个匹配模式,表示匹配以"root"开头的行 -
if(条件测试){条件成立执行语句}else{条件不成立执行语句}
awk -F: '{if($3==0){print $1" 是管理员"}else{print $1" 不是管理员"}}' passwd.txt如果$3为0,则打印$1是管理员,反之则打印$1不是管理员
awk -F: '{if($3==0){i++}else{a++}} END{print "管理员有"i"非管理员有"a}' /etc/passwd输出结果为管理员有1非管理员有20
这个例子的总体结构是 awk -F: '{if(){}else{}} END{}' /etc/passwd -
if(条件测试){条件成立执行语句} else if(条件测试){条件成立执行语句} else{条件不成立执行语句}
awk -F: '{if($3==0){i++} else if($3<=5 && $3 >0){b++} else{a++}} END{print "等于0有"i "个 1-5之间有"b"个 其他的有"a}' /etc/passwd
输出结果为 等于0有1个 1-5之间有5个 其他的有15
循环
- while循环 语法
while(条件){执行语句}}
示例
awk 'BEGIN{while (i<10){print i;i++}}'
awk -F: '{while (i<10){print $i;i++}}' passwd.txt 把第一行每列都打印出来,一共打印10列 - for循环 语法1for(条件){执行语句}
for(i=1;i<=5;i++){print i}和for(i in array){print i}后面这种遍历不是按顺序输出的 可以和sort -n搭配实现按顺序排列
awk -F: '{for(i=0;i<10;i++){print $0}}' passwd.txt
数组
- 普通数组
awk -F: '{array[i++]=$1}END{for(i=1;i<10;i++){print i,array[i]}}' passwd.txt
awk -F: '{array[i++]=$1}END{for(i in array){print i,array[i]}}' passwd.txt| sort -n
练习讲解
awk -F: '{array[$NF]++i} END{for (i in array){print i,array[i]}}' passwd.txt NF是按:分割后的列数总和,这里作为变量传入,假设NF=7把每第7列写入数组,如果key相同则进行自增,最后遍历数组输出每个key的个数统计
awk -F: '/^[root|lp]/' passwd.txt 找每行root或者lp开头的内容
awk '!seen[$0]++' input.txt input2.txt 对input和input2文本里所有行的数据去重
grep
grep的简介
grep 是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来,最常用。
egrep (extended grep) egrep是grep的扩展,支持更多的re正则表达式元字符,等同于grep -E。
使用正则的时候grep对某些元字符需要用\进行转义,而egrep不用
fgrep 它们把所有的字母都看作单词,也就是说,正则表达式中的元字符表示回其自身的字面意义,不再特殊,等同于grep -F,相对于grep和egrep的执行速度最快。
POSIX字符
为了在不同国家的字符编码中保持一至,POSIX(The Portable Operating System Interface)增加了特殊的字符类,如[:alnum:]是A-Za-z0-9的另一个写法。要把它们放到[]号内才能成为正则表达式,如[A- Za-z0-9]或[[:alnum:]]。在linux下的grep除fgrep外,都支持POSIX的字符类。
[:alnum:] 文字数字字符
[:alpha:] 文字字符
[:digit:] 数字字符
[:graph:] 非空字符(非空格、控制字符)
[:lower:] 小写字符
[:cntrl:] 控制字符
[:print:] 非空字符(包括空格)
[:punct:] 标点符号
[:space:] 所有空白字符(新行,空格,制表符)
[:upper:] 大写字符
[:xdigit:] 十六进制数字(0-9,a-f,A-F)
grep使用语法和常用参数
用法: grep [选项]... PATTERN [FILE]...
注意: [FILE]可以有多个,意味grep支持在多个文件位置进行匹配查找
grep -q 静默 不会出现匹配到的结果,根据$?判断匹配是否成功
grep -v 取反
grep -o 精确匹配 比如字符串中{"aid":45,"path":"attachment/Mon_1112/2_1_5728040df3ab346.jpg"}
grep -o -E 'aid":[1-9]*' tmp.txt 得到的结果是 aid":45,只匹配规则里的内容,和-E一起使用
grep -B2 显示前2行
grep -A3 显示后3行
grep -C2 显示上下2行
grep -R 查目录下面的文件 grep 123 -R abc #在abc这个文件夹里搜索能匹配得到123的文件
grep -I 只显示文件名
grep -n 输出内容带行号
代码示例
用来记录上一条命令是否执行成功并写入日志
function dolog() {
local command="$*"
eval "$command"
local status=$?
if [[ $status -eq 0 ]]; then
echo -e $(date +"%Y-%m-%d %H:%M:%S") 运行成功 执行命令 "$*" 2>&1 | tee -a /tmp/young/update.txt
else
echo -e $(date +"%Y-%m-%d %H:%M:%S") 运行失败 执行命令 "$*" 2>&1 | tee -a /tmp/young/update.txt
fi
dolog dnf reposync -n -a=noarch -a=x86_64 --delete --repoid=uos-1050a-AppStream-x86_64 -p /mnt/disk1/repo/1050u1a/x86_64/
}
字符串包含
string="Hello, World"
char="W"
if [[ $string == *"$char"* ]]; then
echo "字符串包含字符 '$char'"
else
echo "字符串不包含字符 '$char'"
fi
判断命令是否存在
请注意,which 命令可能不在所有系统上都存在,而 type 和 command 是 shell 内建命令,更通用
if hash python 2>/dev/null; then
if command -v python &>/dev/null; then
if which python &>/dev/null; then
echo "Python is installed."
else
echo "Python is not installed."
fi
写法2
which python &>/dev/null
if [[ $? -eq 0 ]]; then
echo "Python is installed."
else
echo "Python is not installed."
fi
写法3
if [[ $(which python &>/dev/null; echo $?) -eq 0 ]]; then
echo "Python command exists"
else
echo "Python command does not exist"
fi
