Django 博客园练习--已完成 部署一般用uwsgi或者gunicorn
项目流程:
1. 产品需求
一. 基于用户认证组件和Ajax实现登陆(图片验证码)
二. 基于forms组件和Ajax实现用户注册功能
一和二的数据库表可以放入到用户信息表中
三.系统首页设计
四.设计个人站点
四的个人网站设计了字段为 title(个人网站的名字),site_name(个人网站URL后面的字段,比如 http:xxx/alex),theme(个人网站主题的CSS样式), 然后和用户信息表做一对一关联
五.个人文章详情页
六.文章点赞功能
七.实现评论功能
--------文章的评论
--------对评论的评论
八. 后台管理页面(富文本编辑框)
2. 设计表结构
2.1 用户信息表
使用session功能,利用django自带的auth功能,但是自带的auth表字段很少
原生的auth_user表中只有id,password等一些基础的字段.无法满足具体业务的认证需求.
所以我们可以自定义一张表,来写入需要用到的字段,因为原生的User表是继承了AbstractUser 类.
所以我们也可以继承并扩展这个表
使用的时候要注意setting.py中要添加 AUTH_USER_MODEL = "app02.UserInfo" app02是应用名,UserInfo是自定义类名.
否则容易出现报错

from django.contrib.auth.models import User,AbstractUser
'''
这里AbstractUser 父类就已经有了username password等一些列的字段了,
其他的只是我们扩展的字段而已
'''
class UserInfo(AbstractUser):
nid = models.AutoField(primary_key=True)
telphone = models.CharField(max_length=11, null=True, unique=True)
avatar = models.FileField(upload_to="avatars/", default="avatars/default.png")
create_time = models.DateTimeField(verbose_name="创建时间", auto_now_add=True)
blog = models.OneToOneField(to="Blog", to_field="nid", null=True,on_delete=models.CASCADE)
def __str__(self):
return self.username
2.2 个人主页表
个人主页表放入了主页的标题,站点名,和网站样式
class Blog(models.Model):
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name="个人博客标题", max_length=64)
sitename = models.CharField(verbose_name="站点名称", max_length=64)
theme = models.CharField(verbose_name="个人博客主题央视", max_length=32)
def __str__(self):
return self.title
2.3 分类
用来定义文章的内容类别 ,比如python,java,mysql, 和个人主页文章表属于一对一关系,也就是一篇文章有一个分类
同时分类和用户信息表应该是属于一对多关系,一个用户下可以有多个分类
注意点:因为用户信息表和个人主页表是一对一关系,所以我们的分类表和他们任意一张表建立一对多关系,其他表都是可以通过跨表查询到的
class Category(models.Model):
'''个人文章分类表'''
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name="分类标题", max_length=64)
blog = models.ForeignKey(to="Blog", verbose_name="所属博客", to_field="nid",on_delete=models.CASCADE)
def __str__(self):
return self.title
2.4 标签
用来定义文章的关键字信息 和个人主页文章表属于一对多关系,也就是一篇文章有多个关键字,同时标签和用户信息表应该是属于一对多关系,一个用户下可以有多个标签
注意点:因为用户信息表和个人主页表是一对一关系,所以我们的标签表和他们任意一张表建立一对多关系,其他表都是可以通过跨表查询到的
class Tag(models.Model):
'''个人文章标签表'''
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name="标签名称", max_length=64)
blog = models.ForeignKey(to="Blog", verbose_name="所属博客", to_field="nid",on_delete=models.CASCADE)
def __str__(self):
return self.title
2.5 个人主页文章表
class Artical(models.Model):
'''个人文章分类表'''
nid = models.AutoField(primary_key=True)
title = models.CharField(verbose_name="文章标题", max_length=64)
desc = models.CharField(verbose_name="正文描述",max_length=32)
create_time = models.DateTimeField(verbose_name="文章创建时间", auto_now_add=True)
content = models.TextField() # 文章正文
comment_count = models.IntegerField(verbose_name="文章评论数", default=0)
up_count = models.IntegerField(verbose_name="点赞数", default=0)
down_count = models.IntegerField(verbose_name="踩他数", default=0)
# 文章和用户 一对多关系,字段放在多的这张表
user = models.ForeignKey(to="UserInfo", to_field="nid", verbose_name="作者", on_delete=models.CASCADE)
# 文章和分类,可以一对多,也可以多对多,这里设置成一对多
category = models.ForeignKey(to="Category", to_field="nid", verbose_name="文章分类", on_delete=models.CASCADE)
# 文章和标签,设置成多对多关系,不用through,就是系统自动创建关联表,用through就是自动创建第三张关联表
tag = models.ManyToManyField(
to="Tag",
through="Artical2Tag",
through_fields=("article", "tag")
)
def __str__(self):
return self.title
文章和标签tag多对多的第三张自定义关系表
class Artical2Tag(models.Model):
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(to="Artical", to_field="nid", on_delete=models.CASCADE, verbose_name="文章")
tag = models.ForeignKey(to="Tag", to_field="nid", on_delete=models.CASCADE, verbose_name="标签")
#通过一个内嵌类 "class Meta" 给你的 model 定义元数据
#这里unique_together 代表 article和tag 他们两者的且关系必须是唯一的
class Meta:
unique_together = [
("article", "tag")
]
def __str__(self):
ret = self.article.title + "---" +self.tag.title
return ret
2.6 点赞和踩他
class ArticleUpDown(models.Model):
#文章点赞 踩他表
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(to="Artical", to_field="nid", on_delete=models.CASCADE, verbose_name="文章",null=True)
#之所以需要user是因为对文章的点赞 一定是对某个作者的某篇文章进行点赞,而不是单独对某个文章点赞
user = models.ForeignKey(to="UserInfo", to_field="nid", verbose_name="作者", on_delete=models.CASCADE,null=True)
is_up = models.BooleanField(default=True)
class Meta:
unique_together = [
("article", "user")
]
2.7评论
class Comment(models.Model):
# 文章点赞 踩他表
nid = models.AutoField(primary_key=True)
article = models.ForeignKey(to="Artical", to_field="nid", on_delete=models.CASCADE, verbose_name="文章", null=True)
user = models.ForeignKey(to="UserInfo", to_field="nid", verbose_name="作者", on_delete=models.CASCADE,null=True)
creat_time = models.DateTimeField(verbose_name="评论创建日期",auto_now_add=True)
content=models.CharField(verbose_name="评论内容",max_length=255)
# 这个字段主要用于对评论的评论,to=self或者Comment 是一种自关联的写法
parent_comment = models.ForeignKey(to="self",null=True,on_delete=models.CASCADE)
'''
对评论的评论逻辑如下: 444和555是对111评论的评论
111
444
555
222
333
Comment 表
parent_comment 为null 表示只是对文章的评论,
而最后两条分别是对nid为1的评论和nid为4的评论的评论
nid article user create_time content parent_comment
1 1 1 2021-09-08 111 null
2 2 1 2021-09-09 222 null
3 1 1 2021-09-09 333 null
4 1 1 2021-09-10 444 1
5 1 1 2021-09-11 555 4
'''
3.对着每个功能进行开发
登陆页面
-
基于form组件渲染登陆页面和注册页面的标签元素
form组件字段用到的有
required=False 是否必填,error_messages={"required": "账号不能为空", "invalid": "账号格式有误"} 自定义错误信息提示widget=widgets.PasswordInput(attrs={"class": "form-control"}, )) 内置的widgt插件,设置标签属性等 -
注册和登陆页面的验证码实现
简单的文字验证码,用PIL模块,
先创建实例Image.new(),创建一块画布,
然后设置ImageFont.truetype字体样式
再创建画笔实例ImageDraw.Draw(),通过随机生成的大小写和数字进行填写,注意每个字符的间距
随机的字符串生成后,通过request.session,同步到session会话中,用于后期的验证码校验
创建BytesIO()实例,把生成的验证码写入进去,这样就不用在硬盘上生成图片调用了,加快代码的执行效率.
验证图片的刷新可以通过按钮刷新,也可以在图片的URL后添加?实现重复刷新
$("#verify_code").click(function () { $(this)[0].src += "?"; }); -
ajax功能实现用户账号密码POST校验.
不要忘记添加CSRF字段一起POST,ajax的字段提交常用到的就是url,type,data,和成功回调函数success
-
后台session进行账号密码校验
先通过Django自带的auth模块进行校验(auth.authenticate),校验成功后(auth.login)进行注册,返回一个request.user.
校验失败,则返回一个字典,通过ajax里的success进行渲染到前端网页,进行打印提示.
-
用户注册功能,也是用form组件进行字段渲染,同时对于用户上传自定义头像图片实现逻辑如下:
用户头像上传预览的方式1,通过label标签的for和input id一致产生的联动性实现的,点击了label也会出发input的聚焦事件,然后把#user_icon标签进行显示隐藏 html: <div> <label for="user_icon">用户头像 <img class="head_pic" src="/static/img/default.jpg"></img> </label> <input type="file" id="user_icon"> </div>方式2,通过子绝父相让头像图片(head2_img)和input框(head2_input)重叠,并且大小和长宽设置一样 然后input(head2_input)透明度设置为透明 <div class="user_head2_div" style="height: 60px"> <span>用户头像2</span> <img src="/static/img/default.jpg" class="head2_img"> <input type="file" id="head2_input"> </div> <div> <input type="button" class="btn btn-success" value="确认提交"> </div> -
用户头像预览
前端考虑到功能是上传图片后实现的图片预览,所以选用的是change事件,然后通过files获取用户选中的文件对象,
然后用js的 FileReader() 类读取文件内容,并返回 class.result()
修改img的src属性,设置src的值为class.result()文件读取结果的值.
用onload事件对图片进行加载显示.
$("#user_icon").change(function () {
//用change事件获取文件对象
var file_obj = $(this)[0].files[0];
//实例化一个FileRead类,用readAsDataURL读取图片内容
var head_icon = new FileReader();
head_icon.readAsDataURL(file_obj);
//用该标签的加载事件进行对图片的前端渲染
head_icon.onload = function () {
$(".head_pic").attr("src", head_icon.result)
};
})
-
ajax中利用js的form表单的进行数据提交
创建new.FormData()实例,然后用append方法添加键值.头像的值获取方法同上
利用FormData提交数据时候,AJAX的contentType和processData需要设置为false
注意csrftoken的键值提交
ajax数据POST方式1:
$.ajax({ type:"POST", //ajax提交form 情况下 contentType和processData 必须为false contentType:false, processData:false, dataType:"json", data:{ "user": $("#id_reg_account").val(), 'csrfmiddlewaretoken':$("input[name='csrfmiddlewaretoken']").val(), //#todo 怎么在ajax中发送csrf而不是在获取html数值后续研究下 "csrfmiddlewaretoken":$.cookie("csrftoken"), }, success:function (data) {} })ajax数据POST方式2:
我们也可以对data中的键值进行用js中的FormData()类进行统一添加,然后赋值给data
$(".submit").click(function () { var post_data = new FormData(); //js中使用FormData类进行ajax中的data数据提交 //创建new.FormData()实例,然后用append方法添加键值.头像的值获取方法同上 //append的key值要注意和html中的name相互对应 post_data.append("reg_account",$("#id_reg_account").val()); post_data.append("pwd",$("#id_pwd").val()); post_data.append("re_pwd",$("#id_re_pwd").val()); post_data.append("email",$("#id_email").val()); post_data.append("avatar",$("#user_icon")[0].files[0]); //利用FormData提交数据时候,AJAX的contentType和processData需要设置为false post_data.append("csrfmiddlewaretoken",$("input[name='csrfmiddlewaretoken']").val()); //注意csrftoken的键值提交 $.ajax({ type:"POST", //ajax提交form 情况下 contentType和processData 必须为false contentType:false, processData:false, dataType:"json", data:post_data, success:function (data) {} } )ajax数据POST方式3:
方式2还可以再优化,注意到添加的键值对除了'#avatar'是一个文件对象,其他都是可以通过遍历进行动态获取form表单中的键值对,利用form对象的serializeArray()方法,这个方法会把里面的键值对组成数组
var post_data = new FormData(); //js中使用FormData类进行ajax中的data数据提交 //创建new.FormData()实例,然后用append方法添加键值.头像的值获取方法同上 //append的key值要注意和html中的name相互对应 post_data.append("reg_account",$("#id_reg_account").val()); post_data.append("pwd",$("#id_pwd").val()); post_data.append("re_pwd",$("#id_re_pwd").val()); post_data.append("email",$("#id_email").val()); // 可以获取form表单的对象,用serializeArray()方法,把里面的key和value分别用name和value获取,遍历赋值,图片对象特殊无法用这种方法获取,需要下面手动append var request_data = $("#form").serializeArray(); $(request_data).each(function (index,data) { post_data.append(data.name,data.value) }); -
django的UserForm组件对于前端ajax提交的数据进行清理校验
form.is_valid()>>>form.cleaned_data和form.errors,对form.errors的错误信息进行对应的显示
def reg(request): """注册账号用户""" if request.is_ajax(): #也可以用request.menth=="POST",因为ajax也是一次局部post reg_info = reg_form(request.POST) response={"user":None,"message":None} if reg_info.is_valid(): #如果账号密码通过了局部钩子和全局钩子 response["user"]=reg_info.get("user") else: #未通过钩子校验 response["message"] = reg_info.errors return JsonResponse(response) new_regs = reg_form() return render(request, "reg.html", {"new_regs": new_regs}) -
前端对返回的错误字典进行前端提示
success:function (data) { //先清空span标签中的错误信息和边框颜色 $(".error_info").text(""); $(".form-control").css({"border":"1px solid black"}); if(data.user){ //获取到user说明POST数据校验成功 }else{ //否则单元格显示错误信息 //Django返回的key是{user:None,message:None} $.each(data.message,function (key,error_list) { //通过id_标签名的拼接,定位dom元素,然后在他的span标签中显示错误样式和错误信息 $("#id_"+key).next(".error_info").text(error_list[0]).css({"color":"red","font-weight":"bolder"}); $("#id_"+key).css({"border":"1px solid red"}) // $("#id_"+key).parent().addClass("has-error") }) } }先清空span标签中的错误提示和边框标红的效果.然后遍历错误的字典,遍历错误的键值,因为我UserForm组件渲染的标签id命名规则是id_+字段,所以我们也同样构造获取对象
$("#id_"+key).next(".error_info"),并利用next方法获取同级别元素中的class=error_info类名进行错误信息的赋值和边框的颜色变更.ajax中的success:function(data)中的data返回值如下,message是他的键,值是2个错误信息
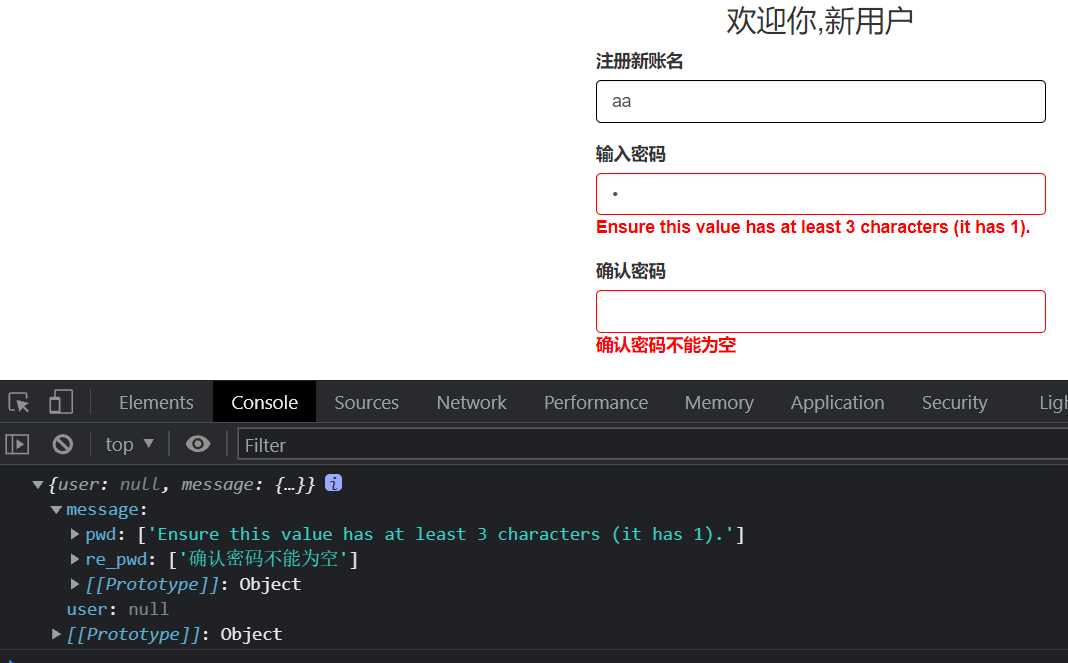
-
Django对于用户名,密码和二次密码进行局部钩子和全局钩子验证,通过验证后写入数据库
class reg_form(forms.Form): reg_account = forms.CharField( max_length=32, label="注册新账名", error_messages={"required": "账号不能为空", "invalid": "账号格式有误"}, widget=widgets.TextInput(attrs={"class": "form-control"}, )) pwd = forms.CharField(min_length=3,max_length=32, label="输入密码", error_messages={"required": "密码不能为空", "invalid": "密码请按大小加特殊字符"}, widget=widgets.PasswordInput(attrs={"class": "form-control"}, )) re_pwd = forms.CharField(min_length=3,max_length=32, label="确认密码", error_messages={"required": "确认密码不能为空", "invalid": "密码请按大小加特殊字符"}, widget=widgets.PasswordInput(attrs={"class": "form-control"}, )) email = forms.EmailField(max_length=32, required=False, label="邮箱", widget=widgets.EmailInput(attrs={"class": "form-control"}, )) def clean_reg_account(self): """局部钩子,函数命名规则clean_校验字段""" user = self.cleaned_data.get("reg_account") user_check = UserInfo.objects.filter(username = user) if not user_check: return user else: raise ValidationError("用户名已注册") def clean(self): # 全局钩子,对几个字段进行额外的校验 pwd = self.cleaned_data.get("pwd") re_pwd = self.cleaned_data.get("re_pwd") #密码和二次输入的密码不为空但是2次输入不一致 #全局钩子的错误key值是__all__开头的,因此需要在前端额外对这个字段进行过滤提取,显示在网页上 if pwd and re_pwd and not (pwd == re_pwd): raise ValidationError("2次密码输入不一致") # 密码和二次输入的密码不为空且相同 else: # 按照模块的写法,如果没问题返回cleaned_data return self.cleaned_data def reg(request): """注册账号用户""" if request.is_ajax(): #也可以用request.menth=="POST",因为ajax也是一次局部post reg_info = reg_form(request.POST) response={"user":None,"message":None} if reg_info.is_valid(): #通过了全局钩子和局部钩子 response["user"]=reg_info.cleaned_data.get("reg_account") user = reg_info.cleaned_data.get("reg_account") pwd = reg_info.cleaned_data.get("pwd") email = reg_info.cleaned_data.get("email") avatar = request.FILES.get("avatar") # 如果账号密码通过了局部钩子和全局钩子,就把注册信息写入到数据库中 # 要用create_user方法,会进行加密存储 UserInfo.objects.create_user(username=user,password=pwd,email=email,avatar=avatar) else: #未通过钩子校验,把错误字段放入message中 response["message"] = reg_info.errors return JsonResponse(response) new_regs = reg_form() return render(request, "reg.html", {"new_regs": new_regs})-
全局钩子的错误key值是__all__开头的,因此需要在前端额外对这个字段进行过滤提取,显示在网页上
success:function (data) { console.log(data); //先把错误信息显示的效果清除 $(".error_info").text(""); $(".form-control").css({"border":"1px solid black"}); if(data.user){ //获取到user说明注册成功,跳转到登陆页面 location.href="/cnblog/login/" }else{ // console.log(data); //否则单元格显示错误信息 //先清空span标签中的错误信息和边框颜色 //Django返回的key是{user:None,message:None} $.each(data.message,function (key,error_list) { //提取全局钩子的错误key值,过滤出来显示前端 if(key=="__all__"){ $("#id_re_pwd").next(".error_info").text(error_list[0]).css({"color":"red","font-weight":"bolder"}); }; $("#id_"+key).next(".error_info").text(error_list[0]).css({"color":"red","font-weight":"bolder"}); $("#id_"+key).css({"border":"1px solid red"}) // $("#id_"+key).parent().addClass("has-error") }) } }, -
avatar路径设置
我们在自定义ORM表的时候是这么定义avatar字段的,上传的路径为avatars 文件夹, 在当前项目的根路径下如果有avatars文件夹,则会把文件以`Blog\avatars\1.jpg`形式存储. 如果没有这个文件夹则会自动创建文件夹 ```python class UserInfo(AbstractUser): nid = models.AutoField(primary_key=True) telphone = models.CharField(max_length=11, null=True, unique=True) avatar = models.FileField(upload_to="avatars/", default="avatars/default.png") create_time = models.DateTimeField(verbose_name="创建时间", auto_now_add=True) blog = models.OneToOneField(to="Blog", to_field="nid", null=True,on_delete=models.CASCADE) #视图文件的代码 def reg(request): """注册账号用户""" if request.is_ajax(): reg_info = reg_form(request.POST) response={"user":None,"message":None} if reg_info.is_valid(): response["user"]=reg_info.cleaned_data.get("reg_account") user = reg_info.cleaned_data.get("reg_account") pwd = reg_info.cleaned_data.get("pwd") email = reg_info.cleaned_data.get("email") avatar = request.FILES.get("avatar") # 如果账号密码通过了局部钩子和全局钩子,就把注册信息写入到数据库中 if avatar: # 要用create_user方法,会进行加密存储 UserInfo.objects.create_user(username=user,password=pwd,email=email,avatar=avatar) else: #考虑到avatar不是必填项,用户如果没有上传头像,则Userinfo表不添加,不添加则会使用字段设置的defalut的内容 UserInfo.objects.create_user(username=user, password=pwd, email=email) else: response["message"] = reg_info.errors return JsonResponse(response) new_regs = reg_form() return render(request, "reg.html", {"new_regs": new_regs}) #视图文件的代码的部分优化内容 create_user 函数是可以传字典的,那么我们可以设置空字典,has_avatar={} 如果有avatar字段,则has_avatar={"avatar":avatar} avatar = request.FILES.get("avatar") has_avatar={} if avatar: has_avatar["avatar"]=avatar UserInfo.objects.create_user(username=user,password=pwd,email=email,**has_avatar) ```-
avatar自定义路径配置以及media配置解耦上传路径
Django有2中静态文件,一个是/static/需要给浏览器下载的 ,另一个是/media/由用户上传的.
和static一样,我们也需要把avatar上传的文件做下解耦,单独放到一个文件夹去,
我们可以去setting.py配置MEDIA_ROOT字段来实现这样的目的,通过下面设置,上传的文件路径就变成了cnblogs这个应用的upload_folder文件夹,完整的路径为
cnblogs\upload_folder\avatars\1.jpgMEDIA_ROOT = os.path.join(BASE_DIR,"cnblogs/upload_folder/") -
avatar自定义路径放到每个用户自己的username下
考虑每个用户上传的文件命名可能重名,最好还是将avatar文件放到用户名下的路径
在model中自定义一个函数,然后用upload_to去接受这个函数返回值
在这个自定义函数中也可以对上传的filename进行重命名,防止任意路径访问漏洞
def user_directory_path(instance,filename): print("instance",instance) print("filename",filename) return os.path.join(instance.username,"avatars",filename) class UserInfo(AbstractUser): # avatar = models.FileField(upload_to="avatars/", default="avatars/default.png") avatar = models.FileField(upload_to=user_directory_path, default="avatars/default.png") -
media配置访问url路由
上一步我们配置了上传的路径,但是里面的客户上传的文件内容或者图片要进行url访问呢?之前的static是django默认配置好了访问路由.那么media我们需要做如下配置
1.1 setting.py 设置
MEDIA_URL = "/media/"1.2 路由导入,在urls.py需要导入
from Blog import settings from django.views.static import serve1.3 设置路由, media是1.1随意命名的,这个设置好后media就代表了绝对路径
cnblogs/upload_folder/这么设置就表示但凡绝对路径是cnblogs/upload_folder/下的子文件夹,都开通了访问路由.
re_path("media/(?P<path>.*)/$",serve,{"document_root":settings.MEDIA_ROOT}) -
设置博客导航
基于bootstrap修改主页样式,用到了导航条,设置了文章类型:随笔 新闻 日记 右侧增加个人信息 如果登陆>>显示用户名字,用户头像,以及下拉菜单(注销,改头像,改密码) 如果未登陆>>显示注册,登陆按钮 -
博客body部分,分为左中右,分别列宽占比4-6-2
用超级账户登陆,先随机导入点数据.刚进去的管理员后台是这样的,看不到之前创建的数据库表
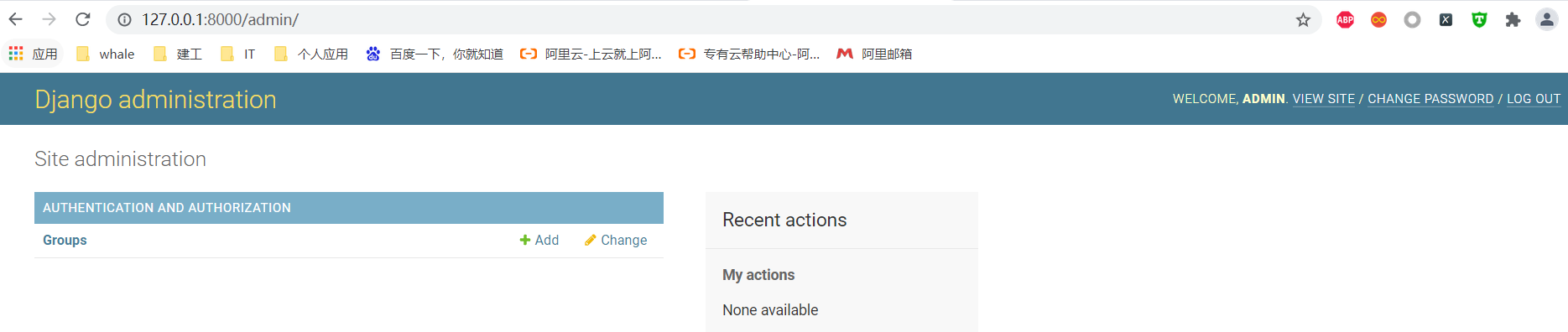
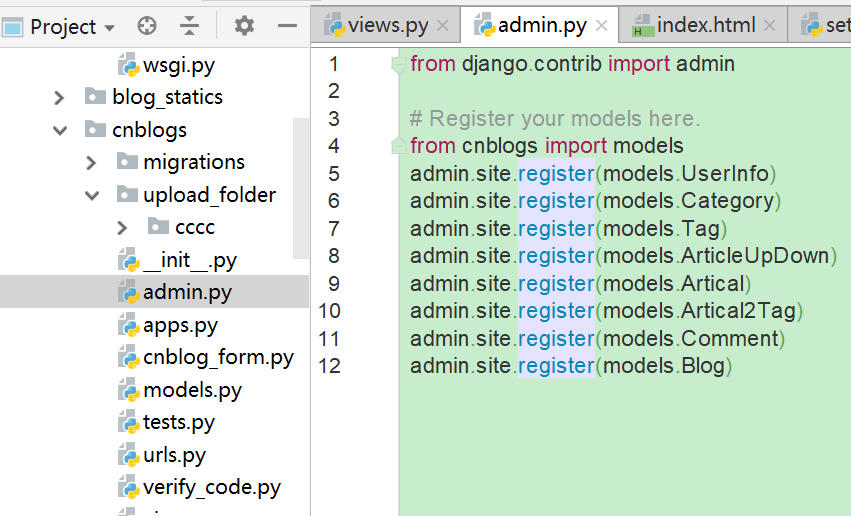
我们需要在应用名/admin.py把ORM的model表进行注册并导入进来,
from cnblogs import models admin.site.register(models.UserInfo) admin.site.register(models.Category) admin.site.register(models.Tag) admin.site.register(models.ArticleUpDown) admin.site.register(models.Artical) admin.site.register(models.Artical2Tag) admin.site.register(models.Comment) admin.site.register(models.Blog)
刷新admin页面就可以看到各个数据库表,接着进行后台数据的自定义添加. 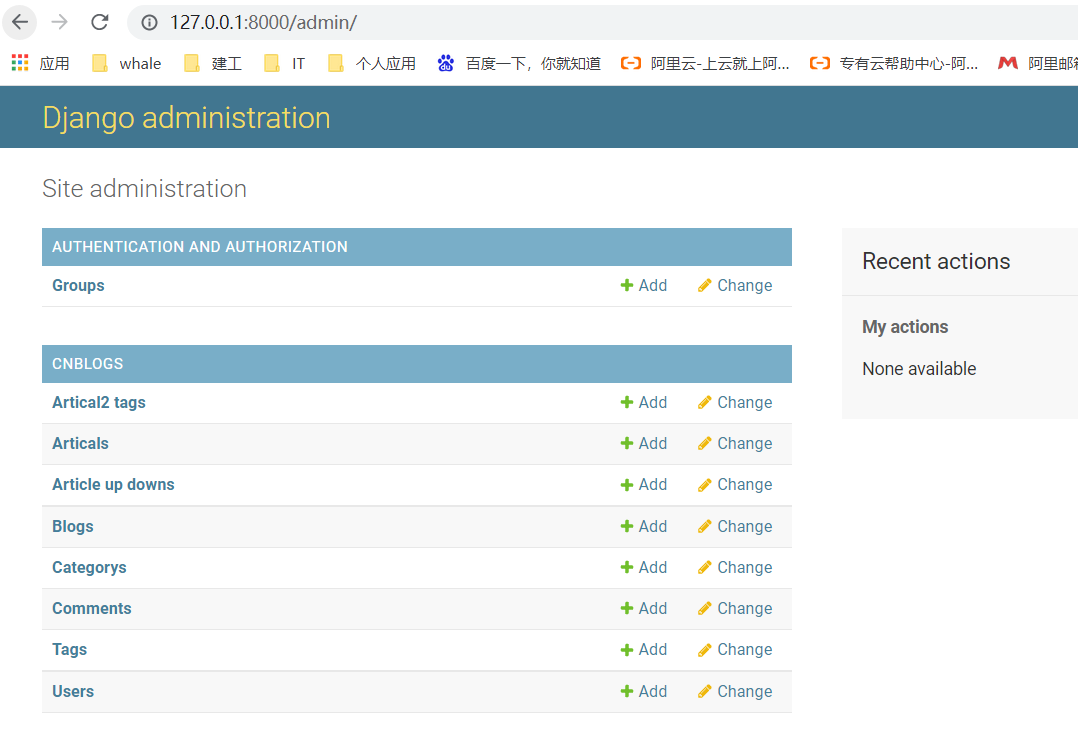 添加的时候最好从大到小的顺序添加 比如: 以User表开始,从用户>用户的Bolgs>Article>(Catagory)(Tag)(Artical2Tag)>Comment 还有注意表和表之间的关系,比如创建一个user,然后创建该用户的Bolgs信息.在数据库中,user和Bolgs是一对一的关系.所以创建完毕后在user里要去绑定这个关系,其他的表的关系也是如此 -
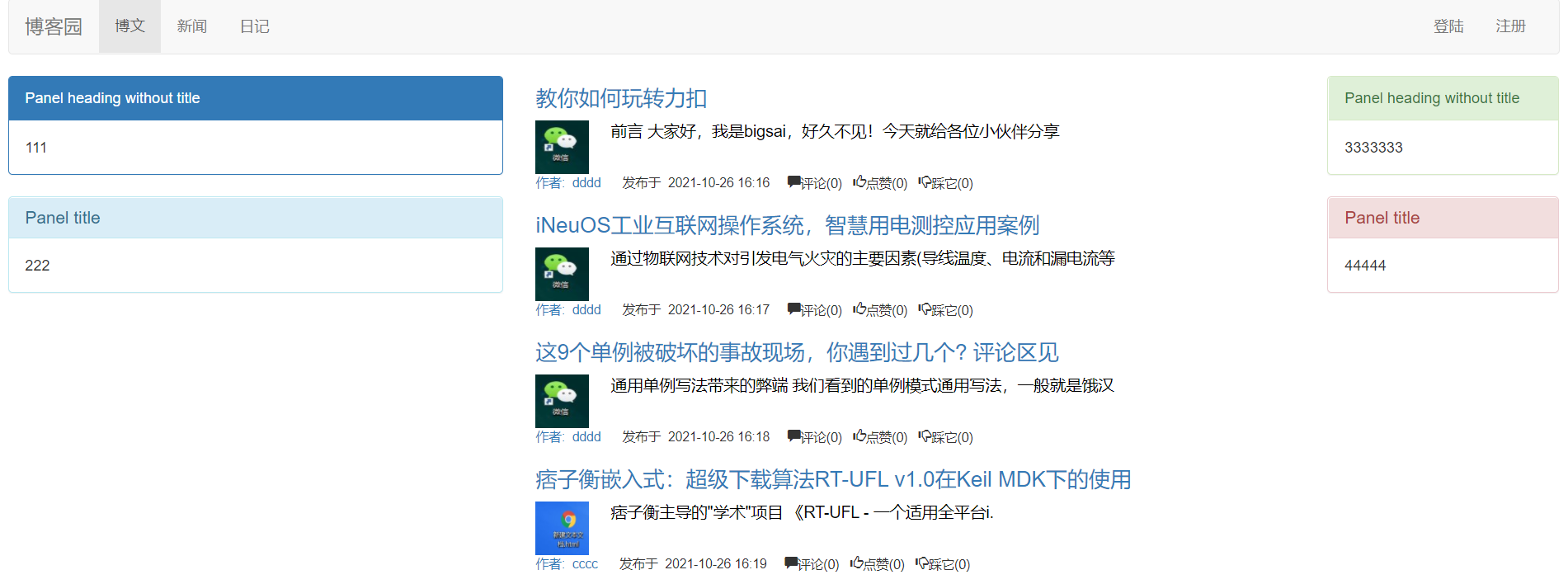
ORM获取数据库所有的文章,渲染主页中中间文章的内容
-
然后做个人主页,配置路由
re_path('^index/(?P<user_home_site>\w+)/$', user_home_site),可以先配置404错误网页,如果个人ID未找到显示404页注意:判断个人ID是否存在用exists比上面的查询效率高,
UserInfo.objects.filter(username=user).exists()但是如果考虑到user对象是用来查博客的个人站点,基本存在的可能性高于不存在,并且需要根据user对象对博文,分类进行渲染.所以实际还是用这个效率高
UserInfo.objects.filter(username=user).first() -
个人主页的数据渲染
做个人主页,大致框架分左右两边,左边 查询当前站点每个分类以及对应的文章数artical_num_each_categoryies = Category.objects.filter(blog=user_blog).values("pk").annotate( c=Count("artical__nid")).values("title", "c")查询当前站点每个标签以及对应的文章数
artical_num_each_tags = Artical.objects.filter(user=user_check).values("pk").annotate(c=Count("tag__nid")).values( "title", "tag__title", "c")查询当前站点每一个年月的名称以及对应的文章数
这里要实现的效果是 2012 6 月(10),根据年月来进行聚合.但是实际上我们存到数据库的时候是
2021-10-26 16:16:41.691016这种格式,因为精确到毫秒级别,所以每个时间都是不同的,无法聚合.在不对原有的数据库进行修改的前提下,要时间聚合思路有2个,
一个是根据mysql语句对时间进行格式化
数据库中可以用date_format对时间的显示做输出格式化. mysql> select * from date_time; +------+---------------------+----------+------------+ | id | dt | t | d | +------+---------------------+----------+------------+ | 1 | 2021-10-30 10:54:44 | 10:54:44 | 2021-10-30 | | 2 | 2021-10-30 10:54:49 | 10:54:49 | 2021-10-30 | +------+---------------------+----------+------------+ 2 rows in set (0.00 sec) mysql> select date_format(dt,"%Y-%m-%d") from date_time; +----------------------------+ | date_format(dt,"%Y-%m-%d") | +----------------------------+ | 2021-10-30 | | 2021-10-30 | +----------------------------+另一个就是通过orm传输SQL语法进行格式化,这里需要用extra方法
extra(select=None,where=None,params=None,tables=None,order_by=None,select_params=None)完整格式query_set对象.extra(select="key: 'sql语句' ")
Artical.objects.extra(select={"filter_ret":"date_format(create_time,'%%Y-%%m-%%d')"}).values("title","filter_ret") 有时候ORM查询语法无法表达复杂的查询语句,我们可以通过extra指定一个或者多个参数,例如select,where,tables,这些参数都不是必须,但是必须要有一个, 以select为例,我们在数据库的artical表中有个文章的create_time字段,我们利用extra进行时间过滤 ret=models.Artical.object.extra(select={"filter_ret":"create_time > '202-10-26' "})extra的详细案例

Django里关于时间的筛选有内置的Trunc方法 ,导包和实例如下:
from django.db.models.functions import TruncDate, TruncDay, TruncHour, TruncMinute, TruncSecond Experiment.objects.annotate( ... date=TruncDate('start_datetime'), ... day=TruncDay('start_datetime', tzinfo=melb), ... hour=TruncHour('start_datetime', tzinfo=melb), ... minute=TruncMinute('start_datetime'), ... second=TruncSecond('start_datetime'), ... ).values('date', 'day', 'hour', 'minute', 'second').get() {'date': datetime.date(2014, 6, 15), 'day': datetime.datetime(2014, 6, 16, 0, 0, tzinfo=<DstTzInfo 'Australia/Melbourne' AEST+10:00:00 STD>), 'hour': datetime.datetime(2014, 6, 16, 0, 0, tzinfo=<DstTzInfo 'Australia/Melbourne' AEST+10:00:00 STD>), 'minute': 'minute': datetime.datetime(2014, 6, 15, 14, 30, tzinfo=<UTC>), 'second': datetime.datetime(2014, 6, 15, 14, 30, 50, tzinfo=<UTC>)在实际应用中我们对于 2021-06-10 15:30:5657这种datetime时间格式分别用extra和自带的TruncDate进行格式化
# 第一种,extra格式化 artical_ret = user_articals.extra(select={"filter_ret":"create_time > '2021-10-26 16:20' "}) date_list=Artical.objects.filter(user=user_check).extra(select={"strift_date":"date_format(create_time,'%%Y-%%m')"}).values("strift_date").annotate(c=Count("nid")).values("strift_date","c")[0] print(date_list) #{'strift_date': '2021-10', 'c': 2} # 第二种,自带的TruncMonth方法 date_list2=Artical.objects.filter(user=user_check).annotate(month=TruncMonth("create_time")).values("month").annotate(c=Count("nid")).values("month","c").first() print(date_list2) #{'month': datetime.datetime(2021, 10, 1, 0, 0), 'c': 1} print(datetime.datetime.strftime(date_list2["month"],"%Y-%m")) #2021-10
-
-
-
实现文章左侧的分类,标签的跳转功能
我们在上面实现了数据库数据的前端渲染,现在要实现这些数据进行跳转,实现跳转后在对数据进行响应的过滤渲染,我们注意到在博客园上我们分别
点击分类 url 为 *.com/alex/category/140673.html 格式为root/username/category/xxx.html
点击标签 url 为 *.com/alex/tag/Git 格式为root/username/tag/标签名
点击随笔归档 url 为 *.com/alex/archive/2021/04.html 格式为root/username/archive/year/month.html
正常的思路我们可以为上面设置三个路由,加上三个视图.
category re_path("^index/(?P<username>\w+)/category/.*/$") tag re_path("^index/(?P<username>\w+)/tag/.*/$") archive re_path("^index/(?P<username>\w+)/archive/.*/$")但是他们也有共同点就是第二个参数不同其他都是相同的.我们可以做一个取巧的设计用一条路由实现三条路由
re_path("^index/(?P<username>\w+)/(?P<condition>category|tag|archive)/(?P<parames>.*)/$")路由设置好了,但是视图中因为传的参数不一样,考虑到有名分组传的就是字典类型,我们在视图中使用**kwargs
def homesite(request,**kwargs): return HttpResponse("%s"%kwargs) # http://127.0.0.1:8000/index/cccc/tag/python/ 传的参数就是{'username': 'cccc', 'condition': 'tag', 'parames': 'python'} # 也可以把username和condition行参写好,那么kwargs接受的就是剩下的参数 def homesite(request,username,condition**kwargs): return HttpResponse("%s"%kwargs) # http://127.0.0.1:8000/index/cccc/tag/python/ 传的参数就是{'parames': 'python'}我们再来分析下规律如下
主页的url是 http://127.0.0.1:8000/cnblog/index/ 用户的主页url是 http://127.0.0.1:8000/cnblog/index/cccc/ 用户的category页url是 http://127.0.0.1:8000/cnblog/index/cccc/category/1234.html/ 用户的tag页url是 http://127.0.0.1:8000/cnblog/index/cccc/tag/python/ 用户的archive页url是 http://127.0.0.1:8000/cnblog/index/cccc/archive/2021/04.html 如果路由是设置2条,一条是 re_path("^index/(?P<username>\w+)/",homesite) 另一条是re_path("^index/(?P<username>\w+)/(?P<condition>category|tag|archive)/(?P<parames>.*)/$",homesite) 而视图是 def homesite(request,username,condition**kwargs): 可以用kwargs或者condtion的传参是否为空判断url访问的路径是主页还是tag还是archive还是category if kwargs: 访问tag或archive或category else: 访问个人主页 #同时我们保持主页左侧内容不变,只刷新右边页面,如果是个人主页,右边显示所有的文章 #如果是tag还是archive还是category其中一个,则显示对应过滤的内容即可,这样就用了2个路由+2个视图实现了5个路由+5个视图的功能,精简了代码. #在模版方面用用1个homesite.html和1个index.html实现了5个html内容的渲染
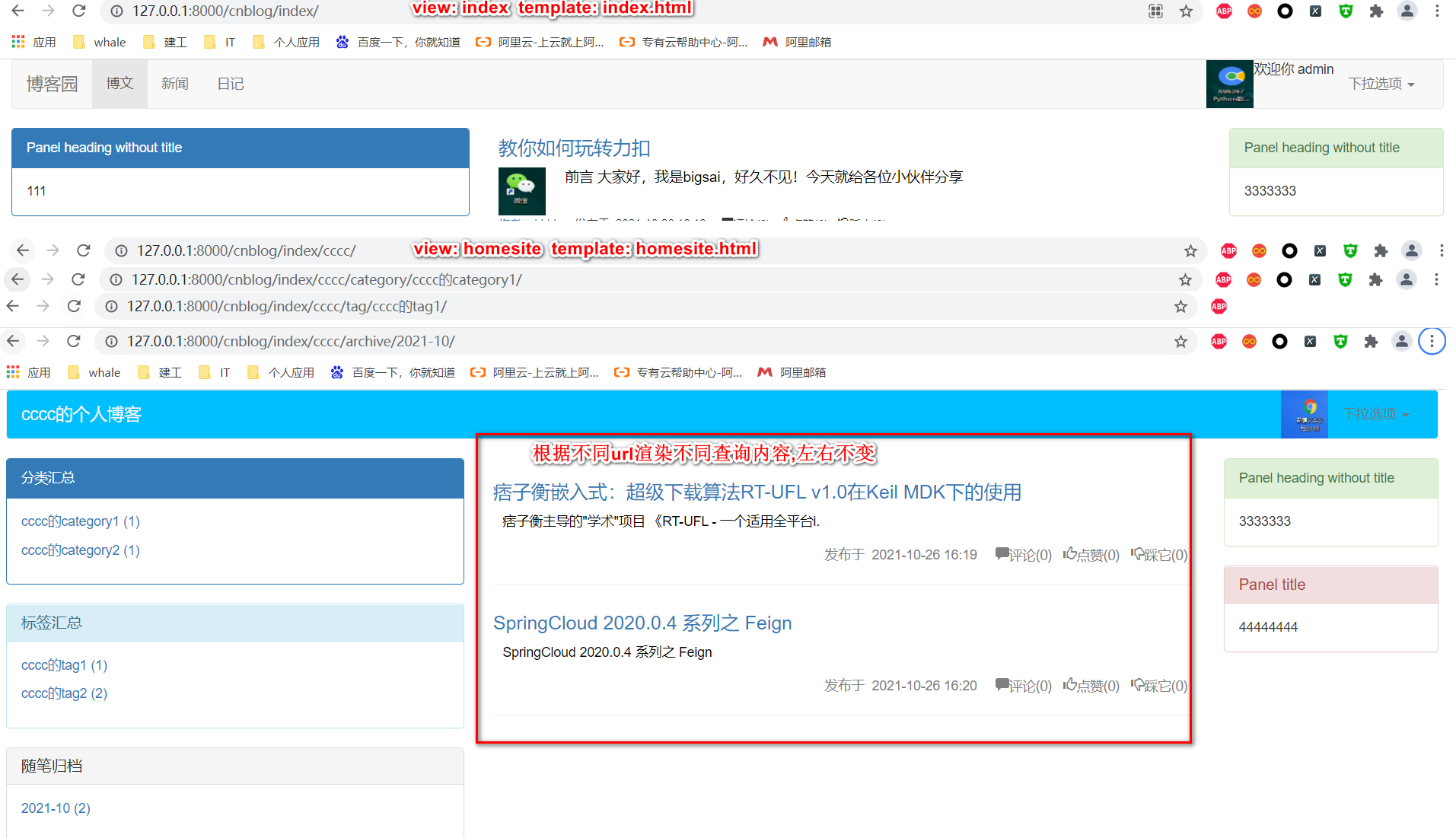
视图代码如下:
```python
def home_site(request, user,**kwargs):
"""个人主页"""
# user_check = UserInfo.objects.filter(username=user).first()
# 用exists比上面的查询效率高,属于优化范畴
user_check = UserInfo.objects.filter(username=user).first()
#无该用户返回404
if not user_check:
return render(request, "404.html")
if kwargs:
# 如果kwargs有值说明要过滤的是分类,标签或者随笔归档条件的文章
condition = kwargs.get("condition")
parames = kwargs.get("parames")
# 用user_articals这个变量,可以下面的个人主页模板共用一套,用同一个变量渲染内容
if condition =="category":
user_articals = Artical.objects.filter(user=user_check).filter(category__title=parames)
elif condition=="tag":
user_articals = Artical.objects.filter(user=user_check).filter(tag__title=parames)
elif condition=="archive":
year,month = parames.split("-")
user_articals = Artical.objects.filter(user=user_check).filter(create_time__year=year,create_time__month=month)
print(year,month)
#如果kwargs为空,表示访问的只是个人站点主页
else:
user_articals = user_check.artical_set.all()
# 用户当前站点下每个分类的名称以及对应的文章数
## 下面都是渲染home_site.html左侧导航栏的数据用的
# 用户博客
user_blog = user_check.blog
# 查询该用户所有相关文章,显示文章的title
artical_num_each_categoryies = Category.objects.filter(blog=user_blog).values("pk").annotate(
c=Count("artical__nid")).values("title", "c")
# 当前站点下每个tag的名称以及对应的文章数,由于一个文章有多个tag,b
artical_num_each_tags = Artical.objects.filter(user=user_check).values("pk").annotate(c=Count("tag__nid")).values(
"title", "tag__title", "c")
empty_tags = {}
for artical_num_each_tag in artical_num_each_tags:
if empty_tags.get(artical_num_each_tag["tag__title"]):
empty_tags[artical_num_each_tag["tag__title"]] += 1
else:
empty_tags[artical_num_each_tag["tag__title"]] = 1
# artical_ret = user_articals.extra(select={"filter_ret":"create_time > '2021-10-26 16:20' "})
date_list=Artical.objects.filter(user=user_check).extra(select={"strift_date":"date_format(create_time,'%%Y-%%m')"}).values("strift_date").annotate(c=Count("nid")).values("strift_date","c")
#输出结果{'strift_date': '2021-10', 'c': 2}
# date_list2=Artical.objects.filter(user=user_check).annotate(month=TruncMonth("create_time")).values("month").annotate(c=Count("nid")).values("month","c").first()
# print(date_list2) #{'month': datetime.datetime(2021, 10, 1, 0, 0), 'c': 1}
# print(datetime.datetime.strftime(date_list2["month"],"%Y-%m")) #2021-10
return render(request, "home_site.html", locals())
```
-
现在开始设置用户文章详情页面.规划详情页左还是继承个人主页的内容,还是改中间的渲染内容.至于右边的内容就不要了
这里有2种思路实现
-
使用模版的继承{% extends "base.html" %} {% block content %},这个在之前的内容有详细记载,不多阐述
-
使用inclusion_tag 进行对HTML需要渲染的模版内容进行解藕,inclusion_tag 其实也是自定义标签的一种
2.1 app项目中创建templatetags文件夹,然后自定义一个py文件
2.2 导包并且实例化一个对象
from django.template import Library register = Library()2.3 自定义函数 这个函数就是通过调用ORM获取动态展示的数据的
2.4 给这个自定义函数加语法糖
@register.inclusion_tag('这里填你要把数据传给哪个HTML模版')
@register.inclusion_tag("artical_detail.html") def artical_detail_fun(user_check,artical_id): artical_list = Artical.objects.filter(user=user_check,pk=artical_id).first() comments_list = Comment.objects.filter(article_id=artical_id) return {"artical_list": artical_list,"comments_list":comments_list} ``` 2.5 html模版使用模版语法进行数据渲染 2.6 在父模版中,加入自定义标签中的tag名字和函数名,如果函数需要传参,后面写参数 ```python #{% load '自定义的tag名' %} {% load mytags %} #{% 自定义tag文件中的函数名 参数1,参数2..... %} {% mytags_function user %} ``` 以下面的例子为例,我们把博客左边显示的标签,分类作为一个base.html,右边展示的文章详情页为artical_detail.html 自定义标签my_tags.py文件中自定义函数为artical_detail_fun ```python @register.inclusion_tag("artical_detail.html") def artical_detail_fun(user_check,artical_id): print("user_check",user_check,"artical_id",artical_id) artical_list = Artical.objects.filter(user=user_check,pk=artical_id).first() return {"artical_list": artical_list} ``` 详细的程序调用流程如下: ```python 1.路由为 re_path('index/(?P<user>\w+)/artical/(?P<artical_id>\d+)/$', artical_detail), 2.我们通过url http://127.0.0.1:8000/cnblog/index/dddd/artical/3/ user=dddd artical_id=3 3.然后调用视图函数artical_detail,把user和artical_id传入,artical_detail视图render给base.html 4.base.html中关于左侧的标签,分类,随笔归档渲染的数据来自于artical_detail视图,同时base.html中 关于文章详情页的内容做了自定义标签的导入,看下方的load 就是导入my_tags.py这个自定义函数文件 然后导入这个文件中的articai_detail_fun函数, 同时给articai_detail_fun函数传入usercheck和artical_id两个参数(看上面自定义标签的代码) articai_detail_fun函数也只是获取orm的数据,然后再传给设定的模版文件进行渲染 设定的渲染文件用语法糖指定@register.inclusion_tag("artical_detail.html") 5.artical_detail.html的数据渲染后传入base.html进行渲染,base.html渲染后就是一个文章详情页的整体页面展现 和之前extend/block语法相比,extend/block渲染解藕的模版时候,这个模版是html和渲染的数据同时写在一个html文件 sub_template(extend base,和block content)--->>>base.html(block content) 而inclusion_tag,是将这个解藕的模版再进行解藕,把这个模版再拆分成数据和HTML文件, base.html(load my_tags和artical_detail_fun函数和形参)-->>my_tags(形参传入,通过ORM产生数据)-->>artical_detail.html(模版进行数据渲染),然后再逆向把渲染好的artical_detail模版数据给base.html然后再渲染. ``` 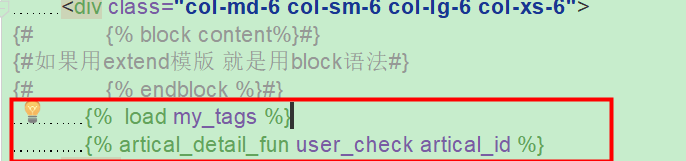中间部分显示个人的所有文章 文章显示要注意博客渲染的都是HTML格式的,需要打开safe过滤器,后期注意XSS攻击防护
-
-
博客个人详情页中,点赞和反对的样式设计,可以参考博客园的html和css代码,注意点:因为模版继承的关系,需要把css设置到base.html中去,如果css和html需要解藕,则在base.html中进行css导入
-
点赞和反对的事件绑定,基于ajax,注意,js也要在base.html中进行引入
nid is_up artical_id user_id我们对于点赞的数据库表字段如上,事件函数来看点赞和点反对ajax发送的内容都是,是否点赞,那篇文章,哪个用户.
对于这种需求,给他们设置一个公共的class,点赞 class为 class="diggit action",反对class为class="buryit action",
用action类绑定点击时间,然后用hasClass("diggit") 方法判断点击的是赞还是反对,赞对应true,反对对应false.

在视图中,需要考虑重复点赞的情况,因为一篇文章只允许该登陆用户点赞一次,可以根据user_id和artical_id作为判断标准,
视图中除了需要创建comment表的字段外,还要在Artical表中的 up_count 和down_count 进行自增,要用到F,
artical_obj.update(up_count=F("up_count") + 1)另外就是考虑这个点赞功能需不需要先登陆,考虑使用装饰器login_required
注意点: 1.导包 from django.contrib.auth.decorators import login_required 2.setting.py配置 LOGIN_URL = "/cnblog/login/",如果未登陆会自动跳转到这个登陆页面,并且带paramas ?next= 比如http://127.0.0.1:8000/cnblog/login/?next=/cnblog/backend/,利用这一点其实可以在登陆的视图中判断next参数是多少,一旦登陆成功,自动跳转到/cnblog/backend/这个url点赞和反对的视图代码
def up_down(request): res_mes = {"status": None, "message": None} if request.user.is_authenticated: if request.method == "POST": is_up = request.POST.get("is_up") is_up = json.loads(is_up) artical_id = request.POST.get("artical_id") user_id = request.user.pk # ArticleUpDown_obj 查找符合文章ID,Userid的对象, ArticleUpDown_obj = ArticleUpDown.objects.filter(article_id=artical_id, user_id=user_id) # 如果没有记录,表示登陆用户未对该文章进行点赞 if not ArticleUpDown_obj: artical_obj = Artical.objects.filter(pk=artical_id, user_id=user_id) if is_up: artical_obj.update(up_count=F("up_count") + 1) res_mes.update({"status": True, "message": "digg_count"}) else: artical_obj.update(down_count=F("down_count") + 1) res_mes.update({"status": True, "message": "bury_count"}) ArticleUpDown.objects.create(is_up=is_up, user_id=user_id, article_id=artical_id) # 登陆用户已对文章进行点赞 else: res_mes["message"] = "请不要重复点赞" else: res_mes["message"] = "请先登陆再进行操作" return JsonResponse(res_mes)点赞和反对的ajax代码
{# 点赞和点反对 #} $("#div_digg .action").click(function () { let is_up = $(this).hasClass("diggit"); $.ajax({ url: "/cnblog/is_ip/", type: "POST", data: { "is_up": is_up, "csrfmiddlewaretoken": $("[name='csrfmiddlewaretoken']").val(), "artical_id": {{ artical_list.pk }}, }, success: function (data) { if (data.status) { let up_down = $("#" + data.message).text(); up_down = parseInt(up_down) + 1; $("#" + data.message).text(up_down); console.log(data.status) } else { $("#digg_tips").text(data.message).css({"color": "red", "fontsize": 18}) } } }) }); -
评论功能
-
构建评论样式
-
ajax提交根评论
-
显示根评论
- render显示
- ajax显示
-
提交子评论
-
显示子评论
- render显示
- ajax显示
Comment表中设了parent_comment字段(简称pid)用来表示该条评论是否是子评论,是哪个根评论的子评论
提交根评论加入些细节,比如点击回复按钮就聚焦到输入框(注意,如果a标签href为#会进行跳到顶部,影响聚焦到评论框,使用javascript:void(0) 代替#)
另外聚焦评论框前先清空评论框内容,以及禁止提交空评论,还有点击提交后,通过ajax而不是render方式直接渲染插入效果.
评论的创建和在Artical表中评论总数自增1的数据库操作和发送邮件提醒评论成功三个功能,开启事务同进同退

评论视图代码(主要展示ajax)
from django.db import transaction from django.core.mail import send_mail from Blog import settings from threading import Thread def comment(request): response_dict = {"status": None, "ret": None} if request.user.is_authenticated: if request.method == "POST" and request.POST.get("comment"): comment = request.POST.get("comment") user_id = request.user.pk article_id = request.POST.get("article_id") pid = request.POST.get("pid") response_dict["status"] = True # transaction.atomic 是调用事务,把要一起执行的代码放里面缩进即可 with transaction.atomic(): comment_obj = Comment.objects.create(article_id=article_id, user_id=user_id, content=comment,parent_comment_id=pid) Artical.objects.filter(pk=article_id).update(comment_count=F("comment_count") + 1) # 这里为了减少延迟,额外开一个线程专门处理邮件发送 t1 = Thread(target=send_mail, args=("通知", "插入了%s" % comment, settings.EMAIL_HOST_USER, ["524072956@qq.com"]), kwargs={"html_message": "<h2>好好好</h2>"}) t1.start() # 注意 comment_obj.creat_time 只是一个datetime对象,要把对象进行字符串格式化,不能直接传对象 response_dict["create_time"] = comment_obj.creat_time.strftime("%Y-%m-%d %X") response_dict["user"] = request.user.username else: response_dict["ret"] = "no_login" print(response_dict) return JsonResponse(response_dict) ------------------------------------------------------------------- def comment_tree(request): """ 注意这里的ajax和Post方法不同,url:"/cnblog/comment_tree/", 将后面的?=参数利用request.GET.get("article_id") 进行获取 也不用csrf校验 """ nid = request.GET.get("article_id") # 通过values把返回值结果变成字典嵌套列表形式 # comment_list = list(Comment.objects.filter(article_id=nid).values("pk","user","content","parent_comment","creat_time")) # 这里解释下order_by的用途,默认查询结果就是order_by主键, # 这里手动在排序下是为了防止子评论的主键值在根评论的主键之前(一般不可能) # 但是为了代码的健壮性,排个序,不至于发生先渲染子评论再渲染根评论的情况 comment_list = list( Comment.objects.values("user__username").filter(article_id=nid).order_by("pk").values("pk", "user__username", "content","parent_comment", "creat_time")) # 为了安全 JsonResponse需要设置safe=false才能把Queryset序列化成字典回传,否则会报错 return JsonResponse(comment_list, safe=False) Django邮件发送的配置项目 # 发送stmp协议的邮件配置 EMAIL_BACKEND = 'django.core.mail.backends.smtp.EmailBackend' # 服务器名称 EMAIL_HOST = 'smtp.sina.com' # 服务端口 EMAIL_PORT = 25 # 发送的邮箱账号 EMAIL_HOST_USER = 'test@sina.com' # 在邮箱中设置的客户端授权密码 EMAIL_HOST_PASSWORD = 'cf**********5' # 收件人看到的发件人,不过尝试一下没用,不知道是不是理解有误,也有设置成 EMAIL_FROM = EMAIL_HOST_USER EMAIL_FROM = 'test@sina.com>'评论的ajax代码部分
//{#递交评论#} let pid = ""; let reply2user; let reply2comment; $(".submit").click(function (event) { let comment = $("#tbCommentBody").val(); if (comment) { if (pid) { comment = comment.slice(comment.indexOf("\n") + 1) } $.ajax( { url: "/cnblog/comment/", type: "POST", data: { "csrfmiddlewaretoken": $("[name='csrfmiddlewaretoken']").val(), "comment": comment, {#"user": "{{artical_list.user.pk}}",视图中直接用request.user#} "article_id": "{{ artical_list.pk }}", {#用来传根评论的ID,也可以用来区分根评论还是子评论.如果是根评论PID是为空#} "pid": pid }, success: function (data) { if (!data.status && data.ret === "no_login") { location.href = "/cnblog/login/" } else if (data.status) { //通过视图回调,用ajax进行根评论的刷新 let insert_li = ` <li class=list-group-item> <div> <span>${data.create_time}</span> <a href="">${data.user}</a> <a href="" class="comment-reply pull-right">回复</a> </div> <div class="comment-content"> <p>${comment}</p> </div> </li>`; let insert_pid_li = ` <li class=list-group-item> <div> <span>${ data.create_time }</span> <a href="#" class="user">${ data.user }</a> <a href="javascript:void(0)" class="comment-reply pull-right" username="${ data.user }" comment-pid="${ data.pid }">回复</a> </div> <div class="comment-content"> <div class="well"> <span>回复 ${ reply2user } : ${ reply2comment }</span> </div> <p>${comment }</p> </div> </li> `; if (pid) { $("ul.comment-list").append(insert_pid_li); } else { $("ul.comment-list").append(insert_li); } $("#tbCommentBody").val("") } } } ) } else { $("#tbCommentBody").attr("placeholder", "请不要发空消息") } }); //{# 评论点击回复后聚焦输入框#} $("a.comment-reply").click(function () { let atsomebody = "@" + $(this).attr("username") + "\n"; $("#tbCommentBody").val(""); $("#tbCommentBody").focus(); //点击按钮就聚焦到评论输入框,并且写入@aaaa字样 $("#tbCommentBody").val(atsomebody); pid = $(this).attr("comment-pid"); if (pid) { //获取该评论的用户 reply2user = $(this).attr("username"); //获取评论内容 reply2comment = $(this).parent().parent().children(".comment-content").children("p").text(); } }); //{#树形评论点击#} {#$("p.comment_tree").click(function () {#} $.ajax({ url: "/cnblog/comment_tree/", type: "get", data: { "article_id": "{{ artical_list.pk }}", }, success: function (data) { {#console.log(data);#} $.each(data, function (index, comment_obj) { let parent_comment = comment_obj.parent_comment; let content = comment_obj.content; let pk = comment_obj.pk; let user__username = comment_obj.user__username; let creat_time = comment_obj.creat_time; let insert_comment = ` <div class=list-group-item> <div class="comment_top"> <a href="">${index+1}楼</a> <span>${creat_time}</span> <a href="">${user__username}</a> <p comment_pid = "${pk}">${content}</p> </div> </div> `; if (!parent_comment) { //parent_comment 为空表示为根评论 $(".list-group.comment-list").append(insert_comment) } else { //树形子评论的插入 $("[comment_pid="+parent_comment+"]").append(insert_comment) } }) } })两种评论模式效果图对比

-
-
富文本功能实现,以kindeditor
- 富文本导入,我们实现的是js模块,所以按照Static路径,复制粘贴后,html导入
kindeditor-all.js,下面列举了常见设置,详细的设置可以去官网查询 http://kindeditor.net/docs/option.html
KindEditor.ready(function (K) { window.editor = K.create('#editor_id', { width: "800",//设置宽度 height: "400", resizeType: 0, //uploadJson是用来上传文件指定一个url的.然后我们在后台编辑视图函数处理 uploadJson: "/cnblog/upload_file/", //因为需要上传csrf的键值对,extraFileUploadParams用来编辑额外需要发送的键值对 extraFileUploadParams: { csrfmiddlewaretoken: $("[name='csrfmiddlewaretoken']").val(), }, filePostName: "file_upload", //自定义key值,体现在视图函数中的request.File //下面2个是用来回传富文本插件对象的,从对象中可以提取文本,html源码等信息,下面有具体例子 afterCreate: function () { this.sync(); }, afterBlur: function () { this.sync(); content_obj = this } }); });-
富文本上传图片,并在富文本编辑框预览
实现这个功能第一步是上传文件,ajax代码见上面,官网得知,返回字段如下:
这里有2点要注意,
一 .根据官网返回的是json字符串,所以视图需要json.dumps序列化下.
二.富文本用了iframe标签,在Django3.0中需要在setting.py配置X_FRAME_OPTIONS = 'SAMEORIGIN',
否则图片上传成功后无法预览.
POST参数 imgFile: 文件form名称, # 可以用filePostName参数进行自定义 dir: 上传类型,分别为image、flash、media、file 返回格式(JSON) #返回是json字符串, //成功时 { "error" : 0, "url" : "http://www.example.com/path/to/file.ext" } //失败时 { "error" : 1, "message" : "错误信息" } #视图函数 def upload_file(request): fname = request.FILES.get("file_upload") pth = os.path.join(settings.MEDIA_ROOT, "upload_file", fname.name) with open(pth, "wb")as f: try: for i in fname: f.write(i) except Exception: ret = {"error": 1, "message": "文件上传写入发生未知错误"} else: ret = {"error": 0, "url": "/cnblog/media/upload_file/%s" % fname.name} return HttpResponse(json.dumps(ret))-
富文本编辑器中的文本内容提取
富文本编辑后,内容需要存储到数据库.我们需要存储里面的HTML源码,作为正文内容,以便做展示渲染,同时需要对里面的纯文本内容提取,截取前100个字作为一个文章的简介信息。需要插入下面2个参数,返回的this.sync()就是富文本对象,可以用text和html分别提取里面的纯文本和HTML格式的内容
afterCreate: function () { this.sync(); }, afterBlur: function () { this.sync(); content_html = this.html() content_text = this.text() } //比如下面点击发送文本内容到后台的ajax案例 let content_obj;//在函数体外设置变量接收富文本的返回对象 KindEditor.ready(function (K) { window.editor = K.create('#editor_id', { width: "800", height: "400", resizeType: 0, //uploadJson是用来上传文件指定一个url的.然后我们在后台编辑视图函数处理 uploadJson: "/cnblog/upload_file/", //因为需要上传csrf的键值对,extraFileUploadParams用来编辑额外需要发送的键值对 extraFileUploadParams: { csrfmiddlewaretoken: $("[name='csrfmiddlewaretoken']").val(), }, filePostName: "file_upload", afterCreate: function () { this.sync(); }, afterBlur: function () { this.sync(); content_obj = this } }); }); $(".submit").click(function () { let userid = $(".pull-right>a:first").attr("uid"); let content = $("uid").val(); $.ajax({ // ContentType:"application/json", url: "/cnblog/artical_add/", type: "POST", data: { csrfmiddlewaretoken: $("input[name='csrfmiddlewaretoken']").val(), "content_text" : content_obj.text(),//调用富文本对象的text方法 "content_html" : content_obj.html(),//调用富文本对象的html方法 }, success: function (data) { console.log(data) } }) }) -
富文本提交内容的XSS过滤
from lxml.html.clean import clean_html print clean_html(html)
- 富文本导入,我们实现的是js模块,所以按照Static路径,复制粘贴后,html导入
本文作者:死了也要PY
本文链接:https://www.cnblogs.com/Young-shi/p/15391299.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步