Django ORM多表操作 正向反向查询语法 中介模型 反向生成models
ORM的注意事项
nid = models.AutoField(primary_key=True)ID字段是自动添加的,需要自定义变量名可以自己填写.- 对于外键字段,Django会在字段名上添加_id来创建数据库中的别名
- 外链字段Foreignkey有一个null=true的设置,它允许外链接受空值null,可以给赋空值None.
Foreignkey
-to:与那张表建立关联,这里可以填'self' 表示自关联,用于展示树状的层级结构
-to_field:对表中的某个字段
1 设置了关联后,对于基于对象的跨表反向查询的时候,直接使用替换的aa即可
-related_name:从关联模型反向访问到本模型的名称。它在外键或多对多关系中使用,作为访问对端对象集合的管理器名称
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.ForeignKey(Author, on_delete=models.CASCADE, related_name='books')
# 使用 related_name
author = Author.objects.get(id=1)
# 通过 related_name 从 Author 访问关联的 Book 集合
books_by_author = author.books.all() # 等价于 Book.objects.filter(author=author)
2 在查找关联模型时使用的过滤字段名称。这个通常用于查询时容易混淆或需要别名的情况。
-related_query_name:反向查询操作时,使用的连接前缀,用于替换表名
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.ForeignKey(Author, on_delete=models.CASCADE, related_query_name='written_book')
# 使用 related_query_name
# 查询所有写了书名为 "Django Basics" 的作者
authors = Author.objects.filter(written_book__title='Django Basics')
3 外键约束,开启外键约束数据的完整性由数据库进行控制,增加,删除会每次额外检查数据关联关系是否完整.如果删除可以提升性能.
-db_constraint
当你禁用了数据库约束,数据完整性则完全由应用层来保证。这需要确保应用逻辑能正确地处理和管理数据关系。
db_constraint默认是True,如果关闭后数据库没有外键约束,数据库无法强制这些字段的引用完整性。即使被引用的记录被删除,
引用的表中也不会出现数据库层面的错误。这可能导致数据不一致。
class CourseCategory(BaseModel):
name = models.CharField(max_length=255, unique=True, verbose_name="分类名称")
remark = models.TextField(default="", blank=True, null=True, verbose_name="分类描述")
direction = models.ForeignKey("CourseDirection", related_name="category_list", on_delete=models.DO_NOTHING, db_constraint=False, verbose_name="学习方向")
class Meta:
db_table = "fg_course_category"
verbose_name = "课程分类"
verbose_name_plural = verbose_name
def __str__(self):
return self.name
多表关系的操作概要
- 1对1的关系在两张表任意一张建立关联字段并且加Unique,比如
作者表 author
id name age
1 alex 18
2 blex 30
3 clex 25
作者个人信息表 authordetail
id addr gender tel author_id(Unique)
1 北京 男 123 1
2 南京 女 1234 2
3 上海 人妖 3311 3
create table authordetail(
id int primary key auto_increment,
addr varchar(20),
gender enum("male","female"),
tel int(11)
author_id int unique,
);
- 1对多的关系 需要在多个关系的表中建立关联字段
出版社 publish
id name book
1 北京出版社 18
2 南京出版社 30
3 天津出版社 25
create table publish(
id int primary key auto_increment,
name varchar(20)
);
书籍 book 在书籍和出版社对应关系中,一个出版社会出版多本书籍,因此把多个出版社id放在book表中创建一对多的关系,并且==要建立约束==,创建关系是为了查询,创建约束是为了防止产生脏数据
id bookname price publish_id
1 python 10 1
2 java 20 1
3 go 58 2
4 php 79 3
create table book(
id int primary key auto_increment,
bookname varchar(20),
price decimal(8,2),
publish_id int,
foreign key(publish_id) reference book(id),
);
- 多对多的关系 创建第三张关系表
书籍 book
id name price publish_id
1 python 18 1
2 java 30 1
3 go 25 2
create table book(
id int primary key auto_increment,
name varchar(32),
price decimal(5,2),
publish_id int,
foreign key (publish_id) reference publish(id),
);
作者表 author
id name age
1 alex 18
2 blex 30
3 clex 25
create table author(
id int primary key auto_increment,
name varchar(32),
age int,
);
做着书籍关系表 book2auther
id book_id author_id
1 1 1
2 1 2
3 2 1
4 3 2
create table book2auther(
id int primary key auto_increment,
book_id int,
author_id int,
foreign key (book_id) reference book(id),
foreign key (author_id) reference author(id),
);
create table publish(
id int primary key auto_increment,
name varchar(20)
);
那么上面的sql语句在ORM中是怎么创建的呢,下面拿着SQL语法 举例在ORM中的语法
1. 出版社和书本的一对多关系

on_delete有6个可选值,分别是:
CASCADE 删除级联,当父表的记录删除时,子表中与其相关联的记录也会删除。即:当一个老师被删除时,关联该老师的学生也会被删除。
PROTECT 子表记录所关联的父表记录被删除时,会报ProtectedError异常。即:当一个学生所关联的老师被删除时,会报ProtectedError异常。
SET_NULL 子表记录所关联的父表记录被删除时,将子表记录中的关联字段设为NULL,注意:需要允许数据表的该字段为NULL。
SET_DEFAULT 子表记录所关联的父表记录被删除时,将子表记录中的关联字段设为一个给定的默认值。
DO_NOTHING 子表记录所关联的父表记录被删除时,什么也不做。
SET() 设置为一个传递给SET()的值或者一个回调函数的返回值,该参数用得相对较少。
2. 作者和作者详情的一对一关系
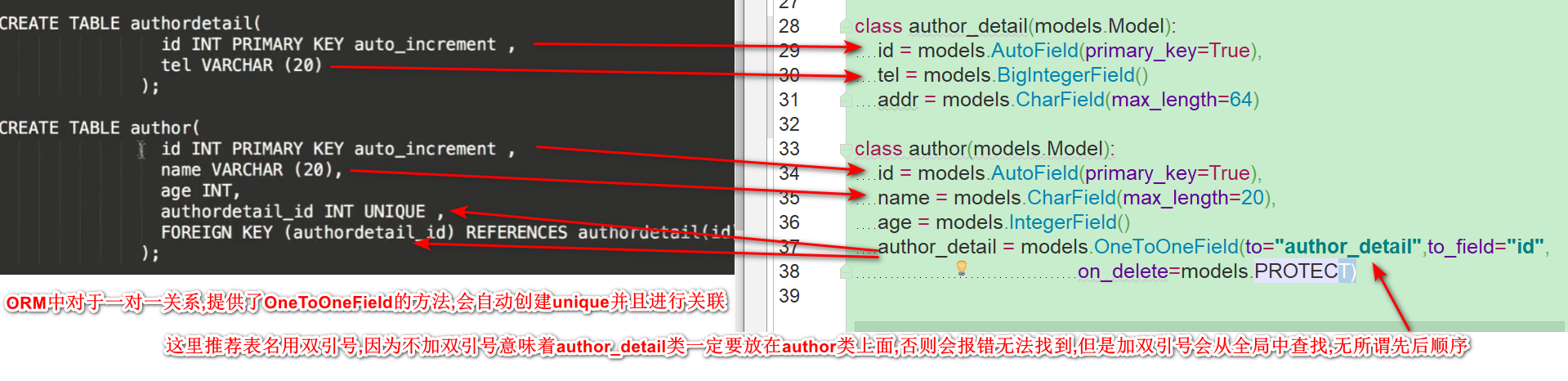
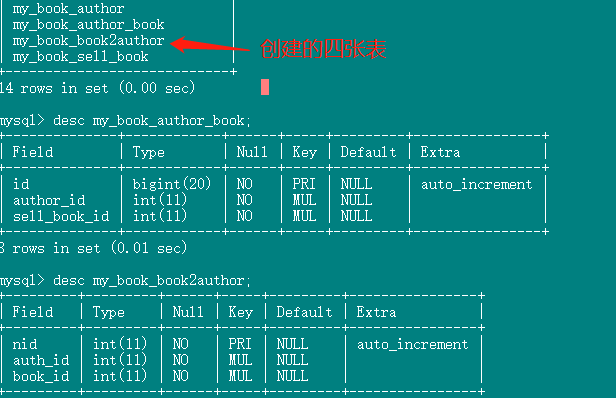
3. 书本和作者多对多的关系

我们可以看下手动创建的Book2Author 和ManyToMany创建的 book_author表,实现的效果是一样的.
orm一对多表之添加记录操作
class Publish(models.Model):
nid = models.AutoField(primary_key=True)
publish = models.CharField(max_length=32)
def __str__(self):
return self.publish
class book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=20)
price = models.DecimalField(max_digits=8, decimal_places=2)
pub_date = models.DateField()
publish = models.ForeignKey(to="Publish", to_field="nid",on_delete=models.CASCADE)
出版社和图书的对应关系为 一个出版社对应多本书,把对应关系写在book类中
出版社数据添加不多说,因为很简单,pub = models.Publish.objects.create(publish="南京出版社")
图书中的添加语法有2种,因为book中的publish在数据库中会自动进行字符串拼接为publish_id

- 第一种
book = models.book.objects.create(title="c++",price=18,pub_date = "2012-05-07",publish_id=2)publish_id直接写死 - 第二种如下,此时book.title是java,book.price是28,但是book.publish 其实就是pub这个对象了,他包含了出版社的信息,所以book.publish.publish就是出版社的名字(南京出版社)
pub = models.Publish.objects.filter(publish="南京出版社").first() #先对Publish表进行筛选出南京出版社的对象,再把这个对象放到publish的参数中去,等同于publish_id=南京的id
book = models.book.objects.create(title="java",price=28,pub_date = "2014-05-07",publish=pub)
orm多对多表之添加记录操作
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
publish = models.ForeignKey(to="Publish", to_field="pid", on_delete=models.CASCADE)
author = models.ManyToManyField(to="Author")
class Author(models.Model):
aid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
author_detail = models.OneToOneField(to="Author_detail", to_field="aid", on_delete=models.CASCADE)
多对多添加也是第一步也是先获取一个对象,比如作者和书籍的关系,因为author这个字段在Book表中进行多对多的表(app1_book_author)的添加,我们先获取author对象
alex = models.Author.objects.filter(name="alex").first() blex = models.Author.objects.get(name="blex")alex和blex就是作者的model对象- 先创建Book的id title price 以及一对多的Publish字段
bk = models.Book.objects.create(title="java",price=29,publish_id=2) #书名叫Java的对象 - 通过Book下的author字段添加多对多关系,通过add()方法添加,可以加对象,也可以直接加id号,也可以用列表形式,除了添加还有remove方法和all()方法可以删除和查询多对多关系
bk.author.add(alex,blex) #利用book类下的author字段,这个字段就是获取了manytomany的对象
bk.author.add(1,2)
bk.author.add(*[alex,blex])

orm多对多表之更改记录操作
比如还是作者和书籍的多对多关系,第一步还是先获取筛选对象 bk = models.Book.objects.create(title="java", price=28.23, publish=pub)
然后有2种方法
第一种方法
bk.author.clear() 先清除他们的关系
bk.author.add(3,4)在按照上面新增一个关系
第二种方法用set(list) set会在新增之前把原先关系删除,而且里面默认放的就是列表,也不用加*
bk.author.set([3,4])
orm一对多和多对多 基于对象跨表查询
正向和反向查询语法总结
数据库查询有2种,一种是子查询,一个子查询作为另一个查询语句的结果,第二种是join查询,把N张表通过关联组成一张大表,然后再提取里面的数据.
基于对象查询
正向
查询按字段
stu = Student.objects.get(name="李四")
stu.stu_detail.tel
反向
1. 按表名小写_set或者related_name字段
course = Course.objects.get(title="近代史")
course.student_set.all() 如果cousr模型的student设置了related_name=students 则查询语句为course.students.all()
2. 按表名或者related_name字段
stu_detail = StudentDetail.objects.get(tel="110")
print(stu_detail.student.name)
反向查询分情况决定是用表名小写_set或者表名小写. 先要了解_set 代表查询结果是一个queryset,
当两张表是一对一关联的话,查询结果必然是一个结果,不可能是一个queryset,所以这种情况是用表名小写反向查询.
当一对多的关联字段反向查询则用表名小写_set
基于join的跨表查询
正向
关联字段__字段
Student.objects.filter(age__gt=22).values("name","clas__name")
反向
表名_字段或者related_name字段__字段
查询年龄大于22的学生的姓名以及所在名称班级
Clas.objects.filter(student_list__age__gt=22).values("student_list__name","name")
查找手机号是110的学生的姓名和所在班级名称 stu是related_name字段
StudentDetail.objects.filter(tel="110").values("stu__name","stu__clas__name")
跨表查询对应的就是第一种子查询语句.跨表查询分 正向查询和反向查询.
正向查询
1.对象查找(跨表) 对象.关联字段.字段
要点:先拿到对象,再通过对象去查对应的外键字段,分两步
示例
book_obj = models.Book.objects.first() # 第一本书对象(第一步)
print(book_obj.publisher) # 得到这本书关联的出版社对象
print(book_obj.publisher.name) # 得到出版社对象的名称
2.字段查找(跨表) 关联字段__字段
示例
models.Book.objects.all().values("publisher__name")
#拿到所有数据对应的出版社的名字,神奇的下划线帮我们夸表查询
反向查询
1.对象查找 obj.表名_set 要点:先拿到外键关联多对一中的某个对象,由于外键字段设置在多的一方,所以这里还是借用Django提供的双下划线来查找
示例
publisher_obj = models.Publisher.objects.first() # 找到第一个出版社对象
books = publisher_obj.book_set.all() # 找到第一个出版社出版的所有书
titles = books.values_list("title") # 找到第一个出版社出版的所有书的书名
结论:如果想通过一的那一方去查找多的一方,由于外键字段不在一这一方,所以用__set来查找即可
2.字段查找 表名__字段 要点:直接利用双下滑线完成夸表操作
示例
titles = models.Publisher.objects.values("book__title")
正向查询按字段:关联字段在A表, 通过A查B, 反向查询按表名(表名小写_set):关联字段在A表, 通过B查A
#一对多 正向查询,查python书籍的出版社名字
bk = models.Book.objects.get(title="python")
print(bk.publish.name)
# 一对多 反向查询,查南京出版社出版的所有书籍
pub=models.Publish.objects.get(name="南京出版社")
print(pub.book_set.all()) #表名_set 返回的是个queryset对象集合
# 多对多 正向查询,查python书籍对应的所有作者名字
bk = models.Book.objects.get(title="python")
print([i.name for i in bk.author.all()])
# 多对多 反向查询,查blex作者对应的所有书籍名称
au = models.Author.objects.get(name="blex")
print([i.title for i in au.book_set.all()])
orm一对一 基于对象跨表查询
正向查询和一对多 多对多一样,但是反向查询有点不同,因为是一对一,不会有多个结果,
所以,结果也不会是queryset,语法也不用是小写表名_set,而是小写表名,例如 auth_detail.author.name
# 一对一
# 正向查询
au = models.Author.objects.filter(name="blex").first()
print(au.author_detail.add)
# 反向查询
auth_detail = models.Author_detail.objects.filter(add="鄞州区").first()
print(auth_detail.author.name)
orm 一对多和多对多查询 基于join查询
#跨表inner join查询 都是在orm语法中就是和values方法
bk = models.Author.objects.filter(name="alex").values("age")
bk2 = models.Author.objects.filter(name="alex").values_list("age", "author_detail")
print(bk)
print(bk2)
#基于双下划线的跨表查询 (join查询) 一对多.
#方式一 正常查询按表名,不过表名语法略有不同,是表名__字段,values里面 publish__name意思是Publish表中的name字段
bk3=models.Book.objects.filter(title="java").values("publish__name")
print(bk3)
#方式二 反向查询,通过出版社过滤book表中titile为python的对象,然后提取出版社的name字段
bk4 = models.Publish.objects.filter(book__title="python").values("name")
print(bk4)
# 基于双下划线的跨表查询(join查询) 多对多查询 查询java书籍的所有作者和alex写的书籍
#方式一 正向查询按字段
bk5 = models.Book.objects.filter(title="java").values("author__name")
print(bk5)
# 方式二 反向查询按表名__字段 通过作者查询书名
auth = models.Author.objects.filter(name="alex").values("book__title")
print(auth)
基于双下划线的跨表查询(join查询) 一对一查询的正向查询和反向查询语句和上述并无二样. 不做举例.
基础双下划线的连续跨表查询(join查询)
#连续跨表查询 ,查到城市以宁波开头的作者出版过的书籍和对应的出版社名字
#方式一 正向查询
#假如以book为起始对象,book关联了作者表和出版社表,但是并未直接关联作者详情的表.我们需要多表跨表查询获取对应的数据
#author__author_detail__city__startswith 就是join了author author_detail2张表,然后根据city为宁波开头的条件过滤出来获得bk对象
#"title","publish__name" bk对象有titile字段,可以直接获取,但是publish需要通过bk的publish_id去对应到Publish表查询,属于正向查询,按字段查询.
bk = models.Book.objects.filter(author__author_detail__city__startswith="宁波").values("title","publish__name")
print(bk) #QuerySet [{'title': 'java', 'publish__name': '南京出版社'}, {'title': 'python', 'publish__name': '北京出版社'}]>
#还是查到城市以宁波开头的作者出版过的书籍和对应的出版社名字,这次以author为基表进行反向查询
# author和author_detail有正向的连接的author_detail_id字段,所以filter直接筛选,获取到author对象
# 接下来通过author对象获取book名和出版社名,但是author对象和book是反向查询关系,通过book表的title和book表下publish字段关联的Publish的name字段获取到最终结果.
auth=models.Author.objects.filter(author_detail__city__startswith="宁波").values("book__title","book__publish__name")
print(auth)
基础双下划线的跨表查询(join查询) 查询datetime数据类型下的年月日
我们的ORM中字段如果是Date或者DateTime类型 比如 create_time = models.DateTimeField()
我们也可以用双下划线的模式对到这个create_time下的 年月日 时分秒字段做字段过滤 比如 xxx.object.filter(create_time__year=2021,create_time__month=06)
中介模型
ManyToManyField 表示小组和成员之间的多对多关系。但是,有时你可能想知道更多成员关系的细节,比如成员是何时加入小组的。 对于这些情况,Django 允许你指定一个中介模型来定义多对多关系。 你可以将其他字段放在中介模型里面。源模型的ManyToManyField 字段将使用through` 参数指向中介模型。对于上面的音乐小组的例子,代码如下:
from django.db import models
class Person(models.Model):
name = models.CharField(max_length=128)
def __str__(self): # __unicode__ on Python 2
return self.name
class Group(models.Model):
name = models.CharField(max_length=128)
members = models.ManyToManyField(Person, through='Membership')
def __str__(self): # __unicode__ on Python 2
return self.name
class Membership(models.Model):
person = models.ForeignKey(Person)
group = models.ForeignKey(Group)
date_joined = models.DateField()
invite_reason = models.CharField(max_length=64)
与普通的多对多字段不同,你不能使用add,create,set等赋值语句
>>> ringo = Person.objects.create(name="Ringo Starr")
>>> paul = Person.objects.create(name="Paul McCartney")
>>> beatles = Group.objects.create(name="The Beatles")
>>> m1 = Membership(person=ringo, group=beatles,
... date_joined=date(1962, 8, 16),
... invite_reason="Needed a new drummer.")
>>> m1.save()
>>> beatles.members.all()
[<Person: Ringo Starr>]
>>> ringo.group_set.all()
[<Group: The Beatles>]
>>> m2 = Membership.objects.create(person=paul, group=beatles,
... date_joined=date(1960, 8, 1),
... invite_reason="Wanted to form a band.")
>>> beatles.members.all()
[<Person: Ringo Starr>, <Person: Paul McCartney>]
无法使用add,create,set等示范
# THIS WILL NOT WORK
>>> beatles.members.add(john)
# NEITHER WILL THIS
>>> beatles.members.create(name="George Harrison")
# AND NEITHER WILL THIS
>>> beatles.members = [john, paul, ringo, george]
为什么不能这样做? 这是因为你不能只创建 Person和 Group之间的关联关系,你还要指定 Membership模型中所需要的所有信息;而简单的add、create 和赋值语句是做不到这一点的。所以它们不能在使用中介模型的多对多关系中使用。此时,唯一的办法就是创建中介模型的实例。
remove()方法被禁用也是出于同样的原因。但是clear() 方法却是可用的。它可以清空某个实例所有的多对多关系:
>>> # Beatles have broken up
>>> beatles.members.clear()
>>> # Note that this deletes the intermediate model instances
>>> Membership.objects.all()
[]
当使用中介模型(通过 through 指定)定义多对多关系时,需要自己处理中介模型实例的创建和保存。这通常涉及到创建多个 Membership 实例,并将它们一并保存到数据库。为了使这个过程的资源消耗最小化,可以使用 Django 的 bulk_create 功能,该功能允许一次性创建多个实例,从而减少数据库的交互次数。
使用 bulk_create 保存多对多关系
假设你有多个 person_id 和 group_id 的组合,以及相应的 date_joined 和 invite_reason 信息需要批量插入到 Membership 表中,以下是一个示例步骤:
from django.utils import timezone
from your_app.models import Person, Group, Membership
# 假设这些数据是你要插入的,没有指定存储位置
persons_data = [
{'person_id': 1, 'group_id': 1, 'date_joined': timezone.now().date(), 'invite_reason': 'Interested'},
{'person_id': 2, 'group_id': 1, 'date_joined': timezone.now().date(), 'invite_reason': 'Invited by friend'},
{'person_id': 3, 'group_id': 2, 'date_joined': timezone.now().date(), 'invite_reason': 'Networking'},
# 添加更多的数据条目
]
# 创建 Membership 对象的列表
memberships = [
Membership(person_id=data['person_id'],
group_id=data['group_id'],
date_joined=data['date_joined'],
invite_reason=data['invite_reason'])
for data in persons_data
]
# 批量插入 Membership 数据
Membership.objects.bulk_create(memberships)
"""
性能优势
减少数据库交互次数:bulk_create 将多个写操作结合成一个数据库事务,极大地减少了数据库通信和事务的开销。
效率提升:当你需要批量插入大量数据时,bulk_create 的性能明显高于逐条插入。
事务安全: Django 的 ORM 将 bulk_create 操作打包成单个事务,确保数据的一致性。
记得在使用时,bulk_create 会忽略任何 save 方法的调用和信号触发,如果这些特性在你的应用中很重要,需另外处理。考虑如何在项目的生命周期中平衡需要信号处理与高效数据操作的场景。
"""
反向生成models
Django较为适合原生开发,即通过该框架搭建一个全新的项目,通过在修改models.py来创建新的数据库表。但是往往有时候,我们需要利用到之前的已经设计好的数据库,数据库中提供了设计好的多种表单。那么这时如果我们再通过models.py再来设计就会浪费很多的时间。所幸Django为我们提供了inspecdb的方法。他的作用即使根据已经存在对的mysql数据库表来反向映射结构到models.py中.
我们在展示django ORM反向生成之前,我们先说一下怎么样正向生成代码。
正向生成,指的是先创建model.py文件,然后通过django内置的编译器,在数据库如mysql中创建出符合model.py的表。
反向生成,指的是先在数据库中create table,然后通过django内置的编译器,生成model代码。
python manage.py inspectdb > models文件名 [不写表名默认生成所有表]
本文作者:死了也要PY
本文链接:https://www.cnblogs.com/Young-shi/p/15143090.html
版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 2.5 中国大陆许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步