Django ORM操作之增删改查和数据库迁移的报错处理和FQ查询
关于模块导入后方法不提示的解决办法
在导入moudles的类后,可能出现objects等方法不会提示
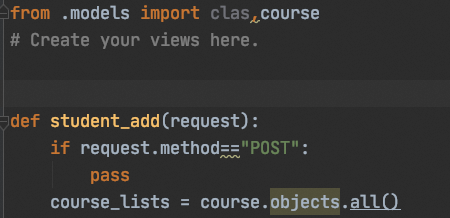
在moudles对应的类中添加 objects = models.Manager()

单表新增
新增方法3个,一个是book.save(),一个是book.object.create(),还有一个是book.objects.bulk_create
前2个方法都有返回值,返回的是你添加的内容,可以调用里面你添加的属性
from my_app.models import Book # 先导包 导入book类
def orm_add(request):
#对book表添加方式1 pub_date这个是日期格式必须是 年-月-日
new_obj = Book(title="go书",price=100,pub_date="2021-1-3",publish="人民出版社")
# validate_unique() 用来判断新增的值是否已经存在,如果存在则会抛出异常
new_obj.validate_unique()
print(new_obj)
print(new_obj.title)
new_obj.save() # save会对数据库表进行对记录的增加操作
#对book表添加方式2 create()方法 直接调用save保存,create是有返回值的
new_obj = Book.objects.create(title="java", price=300, pub_date="2021-4-3", publish="南京出版社")
#object.create()会返回一个对象,这个对象就是插入数据的数据,里面有插入时候的title price pubdate publish的属性
print(new_obj)
print(new_obj.title)
return HttpResponse("实例已添加")
第三个方法bulk_create是批量增加,比如现在添加100个数据,一个个新增的效率肯定低于100个一次性批量新增.把新增对象丢到列表中
注意点,正常使用会报错Duplicate entry '199' for key 'PRIMARY' 不知道解决办法,只能用try,数据可以正常插入
bk_list=[]
for i in range(1,100):
bk = models.test.objects.create(name="python-%i"%(i),price=i,)
bk_list.append(bk)
try:
models.test.objects.bulk_create(bk_list)
except Exception:
pass
单表自定义新增
如下面例子为例,avatar_img 字段是保存图片后自动存入的一个路径,这个路径只是一个相对路径,
配置文件设置为MEDIA_ROOT = os.path.join(BASE_DIR,"Client_media")和MEDIA_URL='/media/'
如果avatar_img的上传存储路径为upload/admin/ESCAN.jpg 这里的admin是用户名,不是固定写死的
那么MEDIA_ROOT路径就是/项目根路径/Client_media/upload/admin/ESCAN.jpg
MEDIA_URL的路径/media/upload/admin/ESCAN.jpg, 前端访问的路径就是http://host:port/media/upload/admin/ESCAN.jpg
licence_path想存储的路径是根据avatar_img生成的路径生成 MEDIA_URL,然后可以用自带的request.build_absolute_uri(MEDIA_URL)方法可以生成http://host:port/media/upload/admin/ESCAN.jpg的格式.
所以我们需要改下save的方法实现avatar_img的值返回时候,同时处理成licence_path的格式,然后调用父类的save一起保存
# model.py
def user_directory_path(instance, filename):
return os.path.join("upload", instance.company.username,filename)
class Company_Auth(models.Model):
company = models.ForeignKey(to="Company", to_field="id", on_delete=models.CASCADE)
title = models.CharField(max_length=64, verbose_name="企业名称")
uniques_id = models.CharField(max_length=64, verbose_name="企业信用代码")
leader = models.CharField(max_length=10, verbose_name="企业法人名字")
licence_path = models.CharField(max_length=64, verbose_name="营业执照路径")
leader_identify = models.CharField(max_length=10, verbose_name="企业法人职务")
avatar_img = models.ImageField(upload_to=user_directory_path, default="default_upload/test.jpg", blank=True, null=True)
def save(self, *args, **kwargs):
# 在保存数据前获取路径
path = user_directory_path(self, self.avatar_img.name)
path = os.path.join(settings.MEDIA_URL,path)
self.licence_path=path
super().save(*args, **kwargs)
图片和文件新增相同文件名的处理方式
ImageField和FileField是会保存到本地的,但是会遇到重名的,这个时候需要我们手动在存储前进行校验.django里有内置类 default_storage 可以对重复文件自动进行判断并且用随机字符串进行重命名保存
在 Django 中,default_storage 是一个文件存储系统的代理对象,它提供了一组方法来管理和处理文件。它是 django.core.files.storage 模块中的一个实例,可以通过导入 default_storage 来使用。
导入from django.core.files.storage import default_storage
常用方法
-
save(name, content)
: 保存文件到存储系统中。name是文件的相对路径,content是文件内容的对象(通常是File` 对象或类似的文件流对象)。当使用
default_storage.save(name, content)方法保存文件时,如果存储系统中已经存在同名的文件,则默认情况下会自动为新文件生成一个唯一的文件名。默认的文件名冲突解决策略是在原文件名后面添加一个随机字符串或时间戳,以确保新的文件名是唯一的。
例如,如果存储系统中已经存在
path/to/file.txt这个文件,当你使用default_storage.save("path/to/file.txt", content)保存一个新的文件时,可能会生成一个新的文件名,如path/to/file_1.txt或path/to/file_20220101.txt。
底层是调用类中的get_available_name方法,该方法会调用exists方法对重复文件名做判断,再用get_alternative_name获取随机字符串重命名的文件名
这种自动处理冲突的机制确保了在相同路径下可以保存多个文件,并且它们具有唯一的文件名。
如果你不希望自动生成唯一的文件名,可以在保存文件之前先检查文件是否已经存在,并根据需要采取相应的处理方法。
示例:from django.core.files.base import ContentFile from django.core.files.storage import default_storage content = b"Hello, World!" file = ContentFile(content) file_path = default_storage.save("path/to/file.txt", file) -
open(name, mode='rb'): 打开存储系统中的文件。name是文件的相对路径,mode是打开文件时的模式(默认为二进制读取模式)。示例:
with default_storage.open("path/to/file.txt") as file: content = file.read() -
delete(name): 删除存储系统中的文件。name是文件的相对路径。示例:
default_storage.delete("path/to/file.txt") -
exists(name): 检查存储系统中是否存在指定的文件。name是文件的相对路径。示例:
if default_storage.exists("path/to/file.txt"): print("File exists") else: print("File does not exist") -
get_available_name: 调用exists方法判断是否存在重复文件名,如果是则用get_alternative_name对文件名后加随机命名字符串
示例:from django.core.files.storage import default_storage name = "path/to/file.txt" available_name = default_storage.get_available_name(name) -
size(name)
: 获取存储系统中文件的大小(以字节为单位)。name` 是文件的相对路径。
示例:file_size = default_storage.size("path/to/file.txt") -
url(name): 获取存储系统中文件的公共访问 URL。name是文件的相对路径。可以和save方法搭配使用,因为save方法会返回一个保存后的绝对路径
示例:file_url = default_storage.url("path/to/file.txt") -
listdir(path=''): 获取存储系统中指定路径下的文件列表。path是相对路径(默认为空,表示存储系统的根目录)。
示例:files = default_storage.listdir("path/to/directory")这将返回一个包含两个元素的元组,其中第一个元素是文件夹列表,第二个元素是文件列表。
-
path(name): 获取存储系统中文件的本地文件系统路径。这在处理本地文件系统存储时特别有用。name是文件的相对路径。
示例:file_path = default_storage.path("path/to/file.txt")
单表查询
查询中要注意返回的是一个queryset的对象类型很多查询方法都要看得出的结果类型是否是个queryset. queryset 是个序列对象,允许像列表一样操作遍历
返回结果默认是 Book object (1) 为了看得清楚,可以在book类下面设置__str__,让对象返回的时候默认打印对象的title属性
返回值就改为了 <QuerySet [<Book: python书>, <Book: php>, <Book: java>]>

values和values_list返回值的区别

单表模糊查询
(1)模糊查询之contains
说明:如果要包含%无需转义,直接写即可。
例:查询姓名包含'华'的学生。
Student.objects.filter(name__contains='华')
(2)模糊查询之startswith、endswith
例:查询姓名以'文'结尾的学生
Student.objects.filter(name__endswith='文')
以上运算符都区分大小写,在这些运算符前加上i表示不区分大小写,如iexact、icontains、istartswith、iendswith.
(3)模糊查询之isnull
例:查询个性签名不为空的学生。
# 修改Student模型description属性允许设置为null,然后数据迁移
description = models.TextField(default=None, null=True, verbose_name="个性签名")
# 添加测试数据
NSERT INTO student.db_student (name, age, sex, class, description, created_time, updated_time) VALUES ('刘德华', 17, 1, '407', null, '2020-11-20 10:00:00.000000', '2020-11-20 10:00:00.000000');
# 代码操作
tudent_list = Student.objects.filter(description__isnull=True)
(4)模糊查询之in,range
例:查询编号为1或3或5的学生
Student.objects.filter(id__in=[1, 3, 5])
例: 查询年龄在20和30之间的学生
Student.objects.filter(age__range=(20,30)))
(5)模糊查询之比较查询
- gt 大于 (greater then)
- gte 大于等于 (greater then equal)
- lt 小于 (less then)
- lte 小于等于 (less then equal)
例:查询编号大于3的学生
Student.objects.filter(id__gt=3)
(6)模糊查询之日期查询
year、month、day、week_day、hour、minute、second:对日期时间类型的属性进行运算。
例:查询2010年被添加到数据中的学生。
Student.objects.filter(born_date__year=1980)
例:查询2016年6月20日后添加的学生信息。
from django.utils import timezone as datetime
student_list = Student.objects.filter(created_time__gte=datetime.datetime(2016,6,20),created_time__lt=datetime.datetime(2016,6,21)).all()
print(student_list)
F查询和Q查询
(1) F查询
F查询就是数据库两个字段之间的比较
使用F对象,被定义在django.db.models中。
语法如下:
"""F对象:2个字段的值比较"""
# 获取从添加数据以后被改动过数据的学生
from django.db.models import F
# SQL: select * from db_student where created_time=updated_time;
student_list = Student.objects.exclude(created_time=F("updated_time"))
print(student_list)
另外F函数还能用来修改表头数据
ret = models.NaviBar.objects.filter(rooter=pk).values("title", "name", "is_menu", "rooter__title")
# <QuerySet [{'title': '权限管理', 'name': 'permission', 'is_menu': True, 'rooter__title': '后台管理'}, {'title': '用户信息', 'name': 'user-role', 'is_menu': True, 'rooter__title': '后台管理'}, {'title': '用户权限', 'name': 'role-per', 'is_menu': True, 'rooter__title': '后台管理'}]>
使用annotate(menu_title=F('rooter__title'))后可以对字段的key值进行自定义
ret = models.NaviBar.objects.filter(rooter=pk).annotate(menu_title=F('rooter__title')).values("title", "name", "is_menu",
# <QuerySet [{'title': '权限管理', 'name': 'permission', 'is_menu': True, 'menu_title': '后台管理'}, {'title': '用户信息', 'name': 'user-role', 'is_menu': True, 'menu_title': '后台管理'}, {'title': '用户权限', 'name': 'role-per', 'is_menu': True, 'menu_title': '后台管理'}]>
也可以直接用F函数进行自定义 推荐用这种
ret = models.NaviBar.objects.filter(rooter=pk).values('title', 'name', 'is_menu', menu_title=F('rooter__title'))
# <QuerySet [{'title': '权限管理', 'name': 'permission', 'is_menu': True, 'menu_title': '后台管理'}, {'title': '用户信息', 'name': 'user-role', 'is_menu': True, 'menu_title': '后台管理'}, {'title': '用户权限', 'name': 'role-per', 'is_menu': True, 'menu_title': '后台管理'}]>
(2) Q查询
多个过滤器逐个调用表示逻辑与关系,同sql语句中where部分的and关键字。
例:查询年龄大于20,并且编号小于30的学生。
Student.objects.filter(age__gt=20,id__lt=30)
或
Student.filter(age__gt=20).filter(id__lt=30)
如果需要实现逻辑或or的查询,需要使用Q()对象结合|运算符,Q对象被义在django.db.models中。
语法如下:
Q(属性名__运算符=值)
Q(属性名__运算符=值) | Q(属性名__运算符=值)
例:查询年龄小于19或者大于20的学生,使用Q对象如下。
from django.db.models import Q
student_list = Student.objects.filter( Q(age__lt=19) | Q(age__gt=20) ).all()
Q对象的与或非分别对应&|~
例:查询年龄大于20,或编号小于30的学生,只能使用Q对象实现
Student.objects.filter(Q(age__gt=20) | Q(pk__lt=30))
Q对象左边可以使用~操作符,表示非not。但是工作中,我们只会使用Q对象进行或者的操作,只有多种嵌套复杂的查询条件才会使用&和~进行与和非得操作。
例:查询编号不等于30的学生。
Student.objects.filter(~Q(pk=30))
同样的取反还可以用exclude
students = student.objects.exclude(name__contains='华')
代码示例
class Book(models.Model):
id = models.AutoField(primary_key=True)
title = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8, decimal_places=2)
'''
如果之前表模型已经数据库创建过,这个时候再额外增加字段的话需要给他赋一个默认值.
否则会报错 让你select fix,设置默认值后可以按照之前的makemigrations和migrate 进行数据库写入这几个新增字段
'''
comment=models.IntegerField(default=0)
read_num=models.IntegerField(default=0)
Book表加入2个字段后我们随便写点数据如下

#我们在查询过程中放入一个变量,默认是不支持变量的,这个时候需要引入一个F,相当于sql语句中的where
#在F中,这个字段就变成了一个变量的概念.不是一个死值
# pub1=models.Book.objects.filter(comment__gt=read_num) #错误示范
from django.db.models import F
# 查询Book中comment数大于read_num的记录
pub1=models.Book.objects.filter(comment__gt=F("read_num")) #把read_num传入到F()中去.
# print(pub1)
#Boook每个comment的值都加1
bk=models.Book.objects.update(comment = F("comment")+1)
#Q 这个参数是用来实现多个筛选条件搭配的
# 比如我们要找价格小于45,评论数大于8的书籍,但是下面这种默认写法只支持且的筛选,如果要用或的筛选需要用Q()把条件都写在Q()里
# 且用& 或用| 非用~Q
bk = models.Book.objects.filter(price__lt=45,comment__gt=8)
from django.db.models import Q
#~Q是代表非的意思
bk = models.Book.objects.filter(Q(price__lt=45) | Q(comment__gt=8))
bk = models.Book.objects.filter(Q(price__lt=45) | ~Q(comment__gt=8))
bk = models.Book.objects.filter((Q(price__lt=45) | ~Q(comment__gt=8) & Q(read_num__gt=10)))
#如果有Q语句和默认的语句,默认的语句一定要放前面.
bk = models.Book.objects.filter(price__lt=45 & (~Q(comment__gt=40)&Q(title="python")))
聚合查询和分组查询看
https://www.cnblogs.com/Young-shi/p/15174328.html
原生查询
执行原生SQL语句,也可以直接跳过模型,才通用原生pymysql.
一共有2种,分别是用orm的raw方法进行原生查询和from django.db import connections的connections查询
注意用原生查询要注意防注入问题
1,使用orm操作数据库增删改查:因为orm采用的是参数化形式执行sql语句.
2,如果万一要执行原生sql语句,建议不要拼接url,而是使用参数化的形式.
#如何使用原生sql
res=models.Author.objects.raw('select * from app01_author where nid>1')
for author in res:
print(author.name)
res = models.Author.objects.raw('select * from app01_book where nid>1')
for book in res:
print(book.price)
#经过上面的对比可以看出,执行原生的sql,跟对象的类型无关,查出什么字段,就可以直接使用该字段
#用connections查询
from django.db import connections
with connections['default'].cursor() as cursor:
cursor.execute("UPDATE TbEmp SET sal=sal+10 WHERE dno=30")
cursor.execute("SELECT ename, job FROM TbEmp WHERE dno=10")
row = cursor.fetchall()
#使用这个方法,[]中括号中参数使用哪个数据库,这里示例的是default库
#拿游标对象
#拿数据方法 fetchall()全部数据 fetchone()取一条数据 fetchmany(n) n是想取多少条数据
#原生查询防注入的示例
id = 11001
#这种字符串拼接的方式容易被sql注入
#sql = "select id name from student where id="+id
sql = "select id name from student where id= %s"
cursor = connection.cursor()
param = []
param.append(id)
try:
cursor.execute(sql,param)
result = cursor.fetchall()
for result1 in result:
// 代码块
pass
finally:
cursor.close()
单表删除
- 模型类对象.delete 它运行时立即删除对象而不返回任何值。例如
model_obj.delete() - 模型类.objects.filter().delete()你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
这种delete方法有返回值(2, {'my_app.Book': 2})代表删除个数,以及哪张表成功删除的个数,一般没什么用.
obj = Book.objects.filter(title="go").delete()
单表改
改的方法是update()和save()两种,但是推荐用update()
不推荐save()的原因是如果只需要更新数据库某个字段,那么save()会把主键下所有字段都更新一遍,执行效率很低
update方法不可以被model对象调用,只能被queryset对象调用,所以如果查询记录的queryset不只一条记录,那么会对所有的记录都进行更改
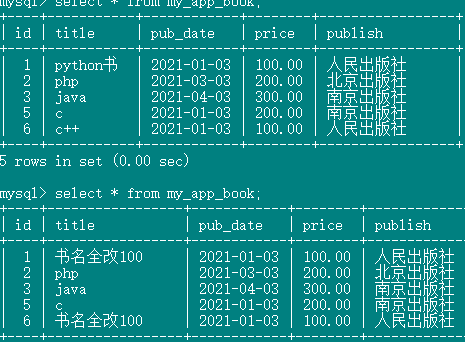
obj = Book.objects.filter(price=100).update(title="书名全改100")
返回的是一个整型数值,表示受影响的记录条数。
数据库迁移报错处理
表中没有相关字段
"Unknown column 'name' in 'django_content_type'"
python manage.py migrate出现如下问题

我们按照提示在对应的表中添加相应字段
alter table django_content_type add name varchar(10);
提示库中的表已存在
1050, "Table 'echart_show_category' already exists"
python manage.py migrate出现如下问题

使用py -3 manage.py migrate --fake-initial 跳过初始化这一步完成迁移

 浙公网安备 33010602011771号
浙公网安备 33010602011771号