
软工作业2:论文查重(Python)
github:个人GitHub
| 软件工程 | 计科21级2班 |
|---|---|
| 作业要求 | 个人项目-实现论文查重 |
| 作业目标 | 学习创建和使用博客;自我介绍;学习Markdown语法;学习Github及Git的使用方法 |
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 150 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 480 | 480 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 20 |
| Design | 具体设计 | 20 | 5 |
| Coding | 具体编码 | 120 | 80 |
| Code Review | 代码复审 | 20 | 5 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 30 | 10 |
| Test Repor | 测试报告 | 20 | 10 |
| Size Measurement | 计算工作量 | 10 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 20 |
| 合计 | 1080 | 1045 |
二、计算模块接口的设计与实现过程
所用接口
simhash.Simhash
SimHash算法主要的工作就是将文本进行降维,生成一个SimHash值,通过对不同文本的SimHash值进而比较海明距离,从而判断两个文本的相似度。SimHash算法的优点是可以对海量的数据进行高效的处理。
使用方法:
from simhash import Simhash
#text1、text2为两篇论文
aa_simhash = Simhash(text1)
bb_simhash = Simhash(text2)
max_hashbit = max(len(bin(aa_simhash.value)), (len(bin(bb_simhash.value))))
#汉明距离
distince = aa_simhash.distance(bb_simhash)
#相似度
similar = 1 - distince / max_hashbit
re.compile
compile函数用于编译正则表达式,生成一个Pattern对象。它单独使用就没有任何意义,可以与re.sub一起使用对文本数据中的异常字符进行清除。
功能实现过程
-
通过命令行获取文件路径
-
读取文件,将论文存储为字符串并进行清洗
-
抽取文本中的关键词及其权重。对关键词取传统hash,并与权重叠加,算出文本的fingerprint值。
-
计算出两个文本之间fingerprint值的海明距离。
-
计算1减去海明距离除以两个文本的文本的fingerprint值中的较大值,作为两个文本的相似度。
-
将相似度输出到存储文件中。
项目中的方法
read_file(files):读取文本文件
filter_html(html):清除文本文件中的html
simhash_similarity(text1, text2):计算两篇文章的相似度
main_fun(file1,fil2,file3):程序运行的主函数
三、计算模块接口部分的性能分析
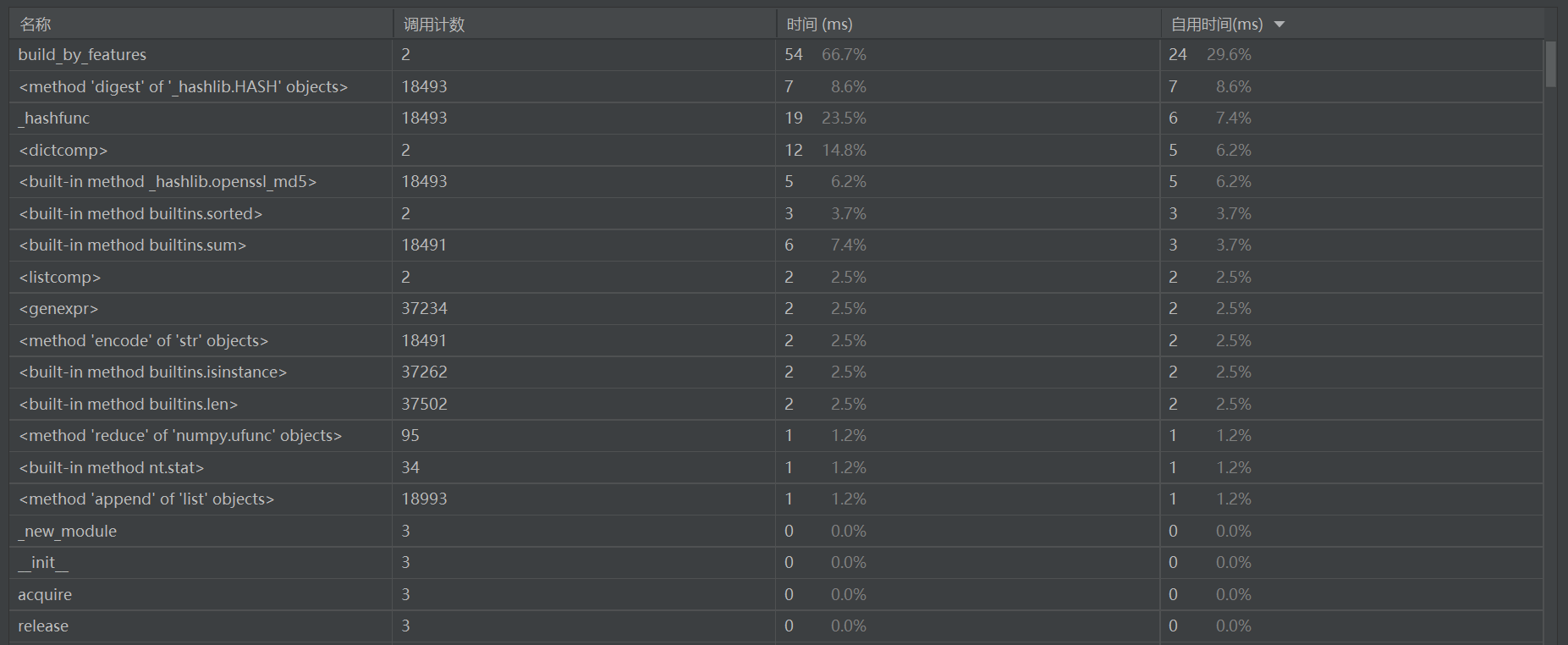
程序中各部分的运行时间和调用次数统计如下:
程序中调用次数最多的是计算长度的len()函数,耗费时间最多的是Simhash类中的build_by_features()函数。
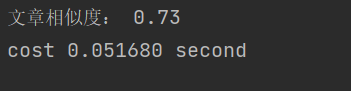
程序的运行时间约为0.0516秒
因为simhash算法部分的实现主要由库函数完成,所以提升性能的方向为文本处理模块。提升的思路是减少文本处理时的中间存储,将清除html的模块改进后,新的代码为:
def filter_html(html):
dd = re.compile(r'<[^>]+>', re.S).sub('', html).strip()
return dd
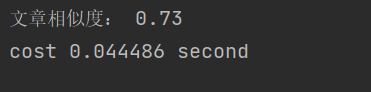
改进后的运行时间为0.0444秒,有提升。
四、计算模块部分单元测试
模块1:方法filter_html(html)
测试代码:
import re
def filter_html(html):
dd = re.compile(r'<[^>]+>', re.S).sub('', html).strip()
return dd
file_1 = r"D:\微信数据\测试文本\orig.txt"
file_2 = r"D:\微信数据\测试文本\orig_0.8_dis_15.txt"
files = [file_1,file_2]
for file in files:
with open(file, "r", encoding='UTF-8') as paper:
print(filter_html(paper.read()))
file_1中没有需要清除的字符,输出仍是原文:
原文

经过处理

file_2中存在需要清除的html,处理结果如下:
原文

经过处理
html已被去除,模块运行正确。
覆盖率100%
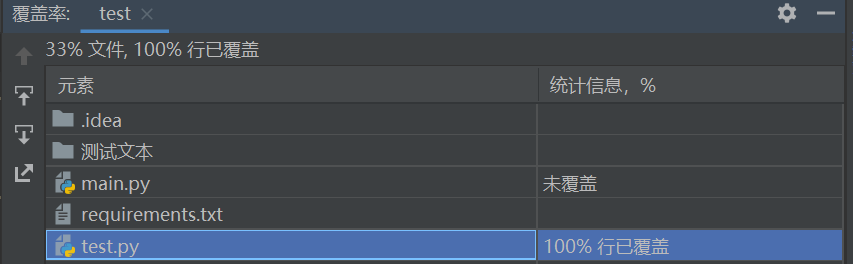
模块2:方法simhash_similarity(text1, text2)
测试代码:
from simhash import Simhash
def simhash_similarity(text1, text2):
"""
:param tex1: 文本1
:param text2: 文本2
:return: 返回两篇文章的相似度
"""
aa_simhash = Simhash(text1)
bb_simhash = Simhash(text2)
max_hashbit = max(len(bin(aa_simhash.value)), (len(bin(bb_simhash.value))))
# 汉明距离
distince = aa_simhash.distance(bb_simhash)
similar = 1 - distince / max_hashbit
return similar
text1="simhash算法的主要思想是降维,将高维的特征向量映射成一个低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。"
text2="simhash算法的主要思想是降维,将高维的特征向量映射成一个低维的特征向量,通过两个向量的Hamming Distance来确定文章是否重复或者高度近似。"
text3 = "simhash算法的主要思想是降维,将高维的特征向量映射成一个低维的特"
text4 = "frsimhatsh算法t的主4要思想是g降5维"
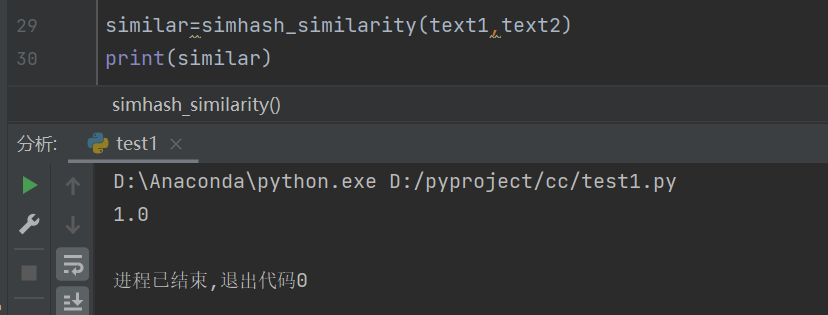
similar=simhash_similarity(text1,text2)
print(similar)
将text1分别与text2,text3,text4进行相似度度量,结果如下:
text1与text2
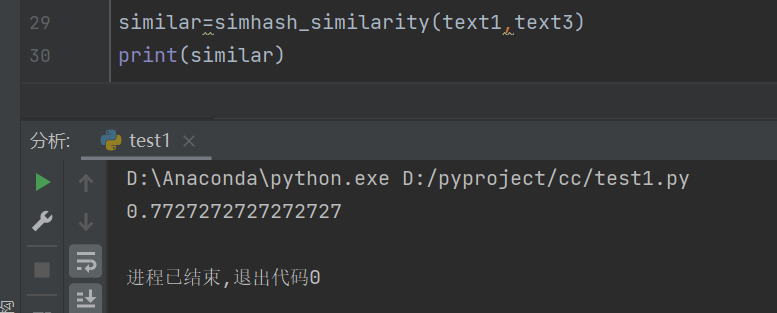
text1与text3
text1与text4
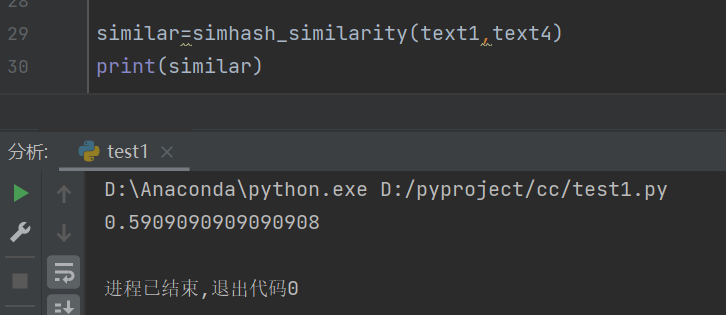
从text2到text4,与text1的相似度呈下降趋势,表明模块功能正常。
覆盖率
五、计算模块部分异常处理说明
命令行输入参数个数错误
if len(sys.argv) != 4:
print('命令行参数个数错误!')
exit()
检验文件是否存在
if not os.path.exists(file1) :
print("论文原文文件不存在!")
exit()
赋值没有使用close()关闭文件导致发生错误
with open(file, "r", encoding='UTF-8') as paper:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号