

平时工作就是做深度学习,但是深度学习没有落地就是比较虚,目前在移动端或嵌入式端应用的比较实际,也了解到目前主要有
caffe2,腾讯ncnn,tensorflow,因为工作用tensorflow比较多,所以也就从tensorflow上下手了。
下面内容主要参考&翻译:
https://www.tensorflow.org/mobile/?hl=zh-cn
https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/running_on_mobile_tensorflowlite.md
....等等,目前自己也是刚开始学移动端和嵌入式端部署,虽然这项技术感觉已经有点old了。
单独阅读英文文档没有翻译理解的透彻,如果有表述不对或者误人子弟的地方,还请拍砖,让我改正。
TensorFlow Lite和TensorFlow Mobile简介:
tensorflow旨在成为深度学习在移动端平台部署的良好解决方案。google公司目前主要有两套在移动端和嵌入式端部署解决方案,
分别是:TensorFlow for Mobile 和 TensorFlow Lite.我们这次主要学习tensorflow lite,然后再看tensorflow Mobile。
他们两个的主要不同点:
TensorFlow Lite是TensorFlow Mobile的演变,在大多数情况下,使用TensorFlow Lite开发的应用程序将具有更小的二进制
大小,更少的依赖性和更好的性能。TensorFlow Lite仅支持一组有限的运算符,因此默认情况下并非所有模型都可以使用它。 TensorFlow for Mobile具有更全面的支持功能
TensorFlow Lite在移动平台上提供更好的性能和更小的二进制文件存储大小,并且可以利用硬件进行加速(如果该平台支持)。此外,
它具有更少的依赖,因此可以在更简单,更受约束的设备方案上构建(build/编译)和托管。TensorFlow Lite还支持 Neural Networks API 的定位加速器。
TensorFlow Lite目前包含了一组有限的操作集合(operators set)。虽然TensorFlow for Mobile默认情况下仅支持一组约束操作,
但原则上:可以对其进行自定义以编译该内核,使得在TensorFlow中使用任意运算符。因此,TensorFlow Lite当前不支持的用例应继续使用TensorFlow for Mobile。
随着TensorFlow Lite的发展,它所支持的操作集合将不断增加,使得在移动端的部署更加地容易。
TensorFlow Lite简介:
TensorFlow Lite是TensorFlow针对移动和嵌入式设备的轻量级解决方案。它支持设备端机器学习推理,并具有的低延迟和较小的二进制文件尺寸。
TensorFlow Lite还支持Android Neural Networks API的硬件加速。TensorFlow Lite使用许多技术来实现低延迟,例如优化移动应用程序的内核,
预融合激活层,以及允许量化内核(更小和更快(定点数学/定点数计算)模型,浮点转整型)。
大多数TensorFlow Lite文档暂时都在GitHub上(https://github.com/tensorflow/tensorflow/tree/master/tensorflow/contrib/lite)。
TensorFlow Lite包含什么?
TensorFlow Lite支持一组核心运算符,包括量化和浮点运算,它们已针对移动平台进行了调整。它们结合了预融合激活和偏置,
以进一步提高性能和量化精度。此外,TensorFlow Lite还支持在模型中使用自定义操作。TensorFlow Lite基于FlatBuffers定义了一种新的模型文件格式。
FlatBuffers是一个开源,高效的跨平台序列化库。它类似于 protocol buffers(协议缓冲区),但主要区别在于FlatBuffers在访问数据之前通常与每个对象的内存分配相结合,
不需要对辅助表示(a secondary representation)进行解析/解包步骤。此外,FlatBuffers的代码占用空间比protocol buffers(协议缓冲区)小一个数量级。
TensorFlow Lite拥有一个新的移动优化解释器,其主要目标是保持应用程序的精简和快速。解释器使用静态图形排序和自定义(少量动态)内存分配器来确保最小的负载、初始化和执行延迟。
TensorFlow Lite提供了一个利用硬件加速的接口(如果在设备支持)。它通过Android Neural Networks API, 实现,可在Android 8.1(API级别27)及更高版本上使用。
为什么我们需要一个新的移动专用库?
机器学习正在改变计算范式,我们看到了移动和嵌入式设备上新用例的新趋势。在相机和语音交互模型的推动下,消费者的期望也趋向于与其设备进行自然的,类人的交互。
有几个因素引起了这个领域的兴趣:
× 硅层的创新为硬件加速提供了新的可能性,而Android Neural Networks API 等框架可以轻松利用这些功能。
×实时计算机视觉技术和口语理解的最新进展已引导了移动优化的基准模型的开源(例如,MobileNets,SqueezeNet)。
×广泛可用的智能应用为设备智能创造了新的可能性。
×能够提供“离线”用例,其中设备不需要连接到网络。
我们相信下一波机器学习应用程序将在移动和嵌入式设备上进行大量处理。
TensorFlow Lite亮点
TensorFlow Lite提供:
× 一组核心运算操作(operators),包括量化和浮动,其中许多已经针对移动平台进行了调整。
这些可用于创建和运行自定义模型。开发人员还可以编写自己的自定义运算符并在模型中使用它们。
× 一种新的基于FlatBuffers的模型文件格式。
× 具有基于设备的内核优化解释器,可在移动设备上更快地执行。
× TensorFlow转换器(TensorFlow converter)将TensorFlow训练的模型转换为TensorFlow Lite格式。
× 更小的尺寸:当所有支持的操作链接时,TensorFlow Lite小于300KB,当仅使用支持InceptionV3和Mobilenet所需的操作时,小于200KB。
×预先测试的模型:
以下所有模型均可保证“开箱即用/work”:
× Inception V3,一种用于检测图像中存在的主要对象的流行模型。
×MobileNets一系列移动优先计算机视觉模型,旨在有效地最大限度地提高准确性,同时注意到设备或嵌入式应用程序的受限资源。
它们是小型,低延迟,低功耗模型,参数化以满足各种用例的资源限制。它们可以用于分类,检测,嵌入(特征编码)和分割。
MobileNet模型比Inception V3更小但精度更低(稍低)。
×在智能回复上,一种端上模型,通过联系与上下文相关的消息,为新传入的文本消息提供一键式回复。该模型专为内存受限设备(如手表和手机)而构建,
并已成功应用于Smart Replies on Android Wear,在所有第一方和第三方应用。
另请参阅TensorFlow Lite支持的模型的完整列表TensorFlow Lite's supported models(https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/models.md),包括型号,性能编号和可下载的模型文件。
× MobileNet 模型的量化版本,其运行速度比CPU上的非量化(浮点)版本快。
× 新的Android演示应用程序,用于说明使用TensorFlow Lite和量化的MobileNet模型进行对象分类。
× Java和C ++ API支持
TensorFlow Lite架构:
下图显示了TensorFlow Lite的架构设计:
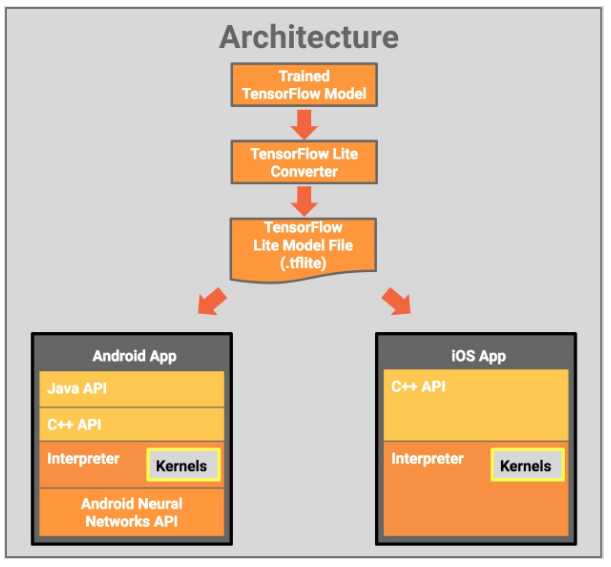
从磁盘上经过训练的TensorFlow模型开始,您将使用TensorFlow Lite转换器将该模型转换为TensorFlow Lite文件格式(.tflite)。然后,您可以在移动应用程序中使用该转换后的文件。
部署TensorFlow Lite模型文件使用:
Java API:围绕Android上的C ++ API的便利包装器。
C ++ API:加载TensorFlow Lite模型文件并调用Interpreter。 Android和iOS都提供相同的库。
解释器:使用一组内核执行模型。解释器支持选择性内核加载。没有内核它只有100KB,加载了所有内核300KB。这比TensorFlow Mobile要求的1.5M显着降低。
在部分Android设备上,Interpreter将使用Android Neural Networks API进行硬件加速,如果没有,则默认为CPU执行。
您还可以使用可由Interpreter使用的C ++ API实现自定义内核。
未来的工作
在未来的版本中,TensorFlow Lite将支持更多模型和内置运算符,包括定点和浮点模型的性能改进,工具的改进,以便更轻松地开发工作流程以及支持其他更小的设备等。
在我们继续开发的过程中,我们希望TensorFlow Lite能够大大简化针对小型设备模型的开发人员体验。
Next Steps
TensorFlow Lite GitHub存储库。包含其他文档,代码示例和演示应用程序。
