数据类型
概述
Java 是强类型语言.
每一种数据都定义了明确的数据类型, 在内存中分配了不同大小的内存空间 (字节) .
Java 中一共有 8 种基本类型 (primitive type) , 包括 4 种整型、2 种浮点型、1 种字符类型 (用于表示 Unicode 编码的代码单元) 和 1 种用于表示真值的 boolean 类型.
Java 的数据类型分为两大类: 基本数据类型和引用数据类型. 基本数据类型又分为四类八种.


基本数据类型的四类八种:
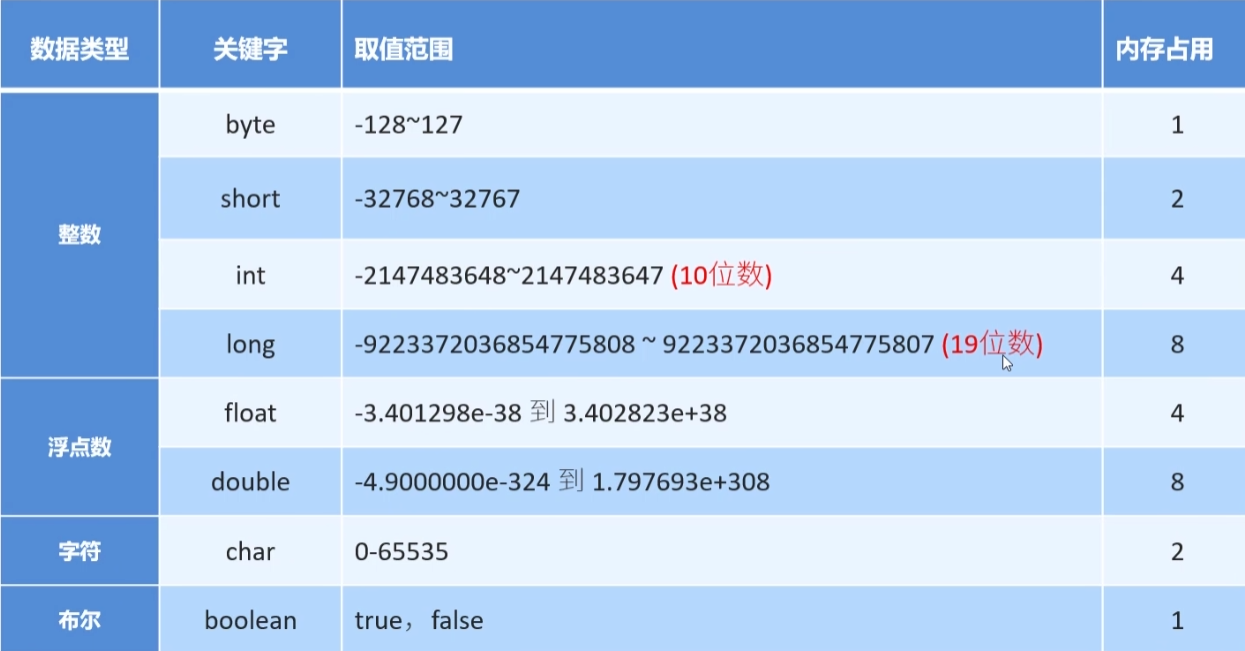
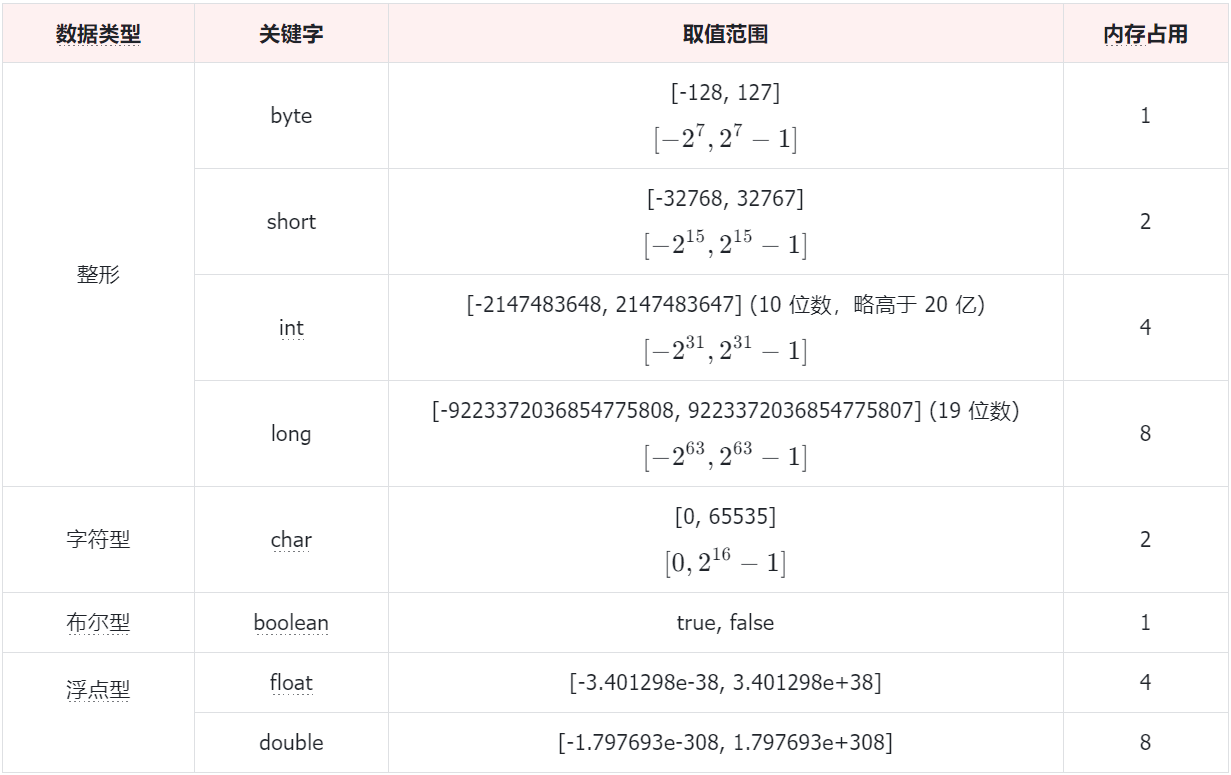
除了这四类八种基本数据类型, 其他类型都是引用数据类型.
整数类型中, int 类型最为常用, 但是如果 int 类型的范围不够, 则需要使用 long 类型. byte 和 short 两种类型主要用于特定的场合, 比如底层的文件处理或者存储空间有限时的大数组.
Java 的各个数据类型有固定的范围和字段长度, 不受具体的操作系统的影响, 以保证程序的可移植性.
Java 中没有无符号数, 即 Java 中的数都是有符号的.
整数和小数取值范围大小关系: double > float > long > int > short > byte.
可以把小空间赋给大空间.
C 和 C++ 程序会针对不同的处理器选择最高效的整型, 这样一来, 一个在 32 位处理器上运行得很好的 C 程序在 16 位系统上运行时可能会发生整数溢出.
可以在一行声明相同类型的多个变量, 但是不提倡这种写法, 分别声明每一个变量可以提高程序的可读性. 程序示例:
public class Test { public static void main(String[] args) { int a, b; // 可以在一行声明相同类型的多个变量 int a1; // 分别声明每一个变量可以提高程序的可读性 int a2; } }
声明一个变量之后, 必须用赋值语句显式地初始化变量. 千万不要使用未初始化的变量的值. 程序示例:
public class Test { public static void main(String[] args) { int a; System.out.println(a); // 报错: java: 可能尚未初始化变量 a } }
public class Test { public static void main(String[] args) { int a; // 声明 a = 10; // 初始化 System.out.println(a); // 10 } }
也可以将变量的声明和初始化放在同一行中. Java 中可以将声明放在代码中的任何地方. 在 Java 中, 变量的声明要尽可能靠近第一次使用这个变量的地方, 这是一种很好的编程风格.
在 Java 中, 并不区分变量的声明和定义. 程序示例:
public class Test { public static void main(String[] args) { int a = 10; // 声明和初始化放在同一行 System.out.println(a); // 10 } }
同时声明多个变量:
public class VariableDemo { public static void main(String[] args) { // 一条语句中定义多个变量 int a = 10, b = 20, c = 30; System.out.println(a); System.out.println(b); System.out.println(c); // 一条语句中定义多个变量, 只给部分变量初始化 int d, e = 100, f; // System.out.println(d); // 报错: Variable 'd' might not have been initialized System.out.println(e); // 100 // System.out.println(f); // 报错: Variable 'f' might not have been initialized } }
从 Java 10 开始, 对于局部变量, 如果可以从变量的初始值推断出它的类型, 就不再需要声明类型, 只需要使用关键字 var 而无须指定类型. 程序示例:
public class Test { public static void main(String[] args) { var a = 10; // 使用关键字 var 而无须指定类型 System.out.println(a); // 10 { var b = 100; // 使用关键字 var 而无须指定类型 System.out.println(b); // 100 } } }
C 和 C++ 区分变量的声明和定义. 例如:
int i = 10; // 是一个定义 extern int i; // 是一个声明
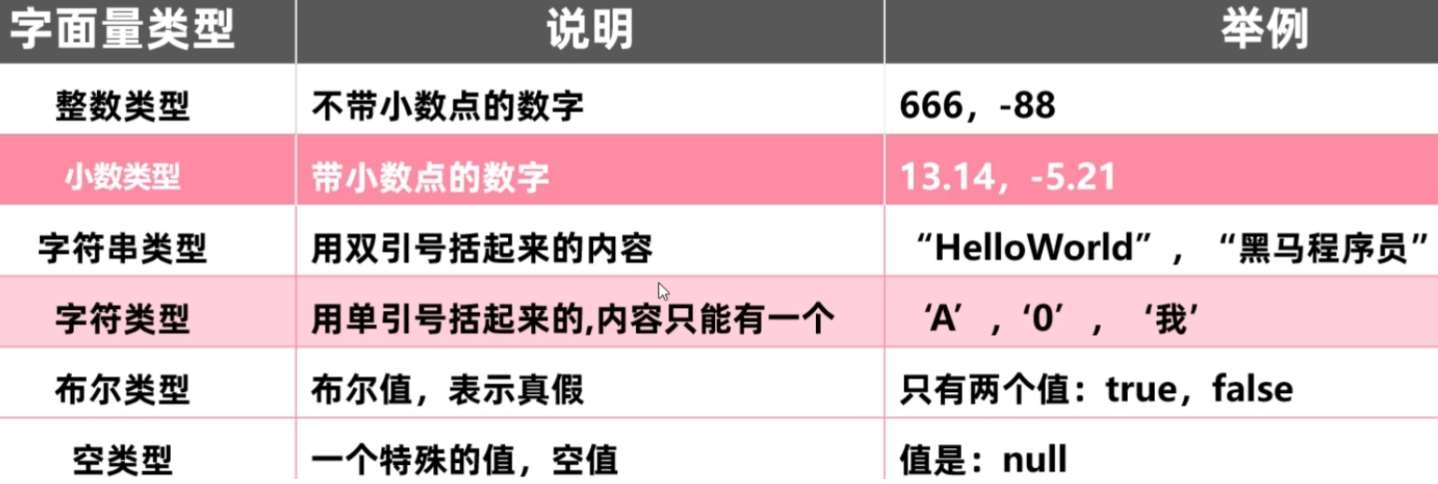
字面量
字符串类型的字面量必须用双引号包围, 双引号里面的内容有多少无所谓, 可以没有.
字符类型的字面量必须用单引号包围, 里面的内容有且只能有一个.
字面量按照类型分为下面的六种.
整型
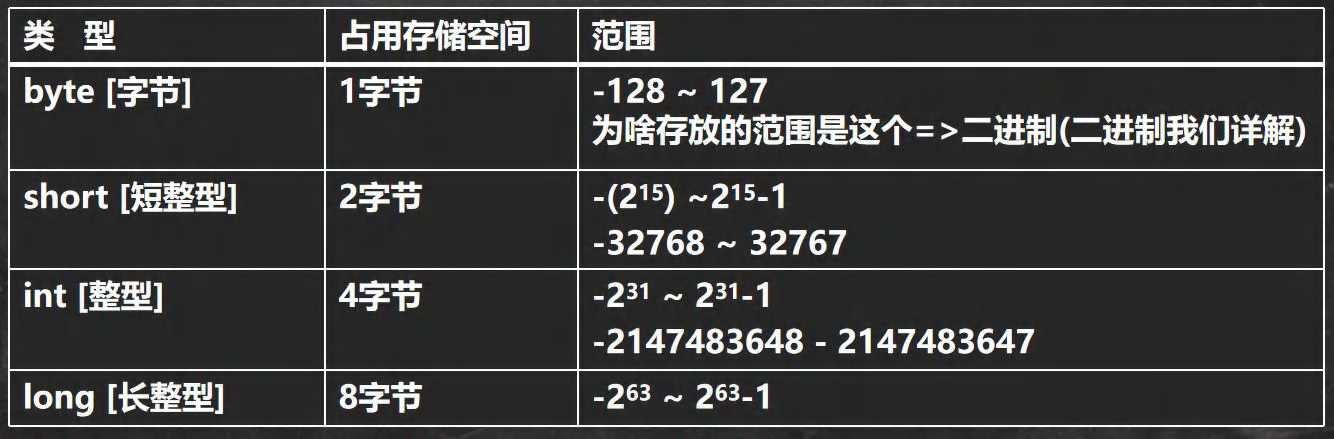
Java 的整型常量默认为 int 型.
bit: 计算机中的最小存储单位.
byte: 计算机中基本存储单元, 1 byte = 8 bit.
后缀
Java 的整型常量默认为 int 型, 如果超过了 int 的范围, 就需要在数据值的后面需要加一个 L 或 l 作为后缀, 表示是 long 类型的整数而不是默认的 int 类型.
程序示例:
public class Test { public static void main(String[] args) { long a = 10l; // 加后缀 l long b = 10L; // 加后缀 L // int c = 10L; // 报错: java: 不兼容的类型: 从 long 转换到 int 可能会有损失 System.out.println(a); // 10 System.out.println(b); // 10 // System.out.println(c); } }
程序示例:
public class ValueDemo3 { public static void main(String[] args) { long a = 999999999; // 正常输出 long b = 9999999999L; // 加了后缀 L 后才能正常输出 System.out.println(a); System.out.println(b); long c = 10L; // 就算一个整数在 int 范围内, 也可以通过后缀 L 让它变成 long 类型 System.out.println(c); } }
整型常量默认是 int 类型, 如果这个常量超过了 int 类型可以表示的范围, 那么就需要加上 L 后缀表示是 long 类型的常量, 否则报错.
整数的进制
不同进制的整数要加前缀.
-
十进制整数不加前缀;
-
二进制整数加前缀 0b 或 0B;
-
八进制整数加前缀 0;
-
十六进制整数加前缀 0x 或 0X.
程序示例:
public static void main(String[] args) { System.out.println(10); // 10 System.out.println(010); // 8 System.out.println(0b10); // 2 System.out.println(0x10); // 16 }
用 System.out.println 进行输出时, 都是默认以十进制的形式进行输出.
程序示例:
public class Test { public static void main(String[] args) { // System.out.println(0b123); // 报错: Integer number too large } }
浮点型

关于浮点数在机器中存放形式的简单说明: 浮点数 = 符号位 + 指数位 + 尾数位
尾数部分可能丢失, 造成精度损失 (小数都是近似值).
与整数类型类似, Java 浮点类型也有固定的范围和字段长度, 不受具体 OS 的影响.
float 是 4 个字节, double 是 8 个字节. float 是 6~7 位有效数字. double 是 15 位有效数字.
Java 的浮点型常量默认为 double 型.
后缀
Java 的浮点数字面量默认为 double 类型, 如果要将一个浮点型字面量视为 float 类型, 必须加后缀 f 或 F.
程序示例:
public static void main(String[] aStrings) { double a = 11.1; // float b = 11.1; // java: 不兼容的类型: 从 double 转换到 float 可能会有损失 float c = 11.1F; System.out.println(a); // 11.1 // System.out.println(b); System.out.println(c); // 11.1 }
定义 float 类型的变量时, 需要在数据值的后面加上一个 F 或 f 作为后缀.
在一个数值字面量后面加 d 或 D 可以将其视为 double 类型, 一般都不需要这么做, 但是不会报错, 如 3d 是 double 类型.
程序示例:
public static void main(String[] args) { double d1 = 3.3d; // 加后缀 d 将 float 类型数值变为 double 类型 double d2 = 3D; // 加后缀 D 将 int 类型数值变为 double 类型 System.out.println(d1); // 3.3 System.out.println(d2); // 3.0 }
浮点型常量不能赋值给整型, 程序示例:
public static void main(String[] args) { int a = 1.1; // 报错: java: 不兼容的类型: 从 double 转换到 int 可能会有损失 System.out.println(a); }
程序示例:
public class ValueDemo3 { public static void main(String[] args) { // float a = 10.53; // Type mismatch: cannot convert from double to float float a = 10.53F; // 正常输出 System.out.println(a); double b = 10.99F; // 10.989999771118164, 允许将 float 赋给 double System.out.println(b); } }
程序示例:
public class Test { public static void main(String[] args) { short a = 10; // 可以将处于 short 范围内的 int 类型的常量赋值给 short 类型的变量 System.out.println(a); int b = 10; // short c = b; // 不可以将处于 short 范围内的 int 类型的变量赋值给 short 类型的变量 // System.out.println(c); } }
字面量
浮点数字面量有三种写法:
-
十进制, 如 5.12, 512.0f, .512 (小数点不能省略, 必须有小数点, 0 可以省略, 即 0.512 = .512)
-
e 计数法, 如 5.12e2, 5.12E-2
-
p 计数法 , 这是用十六进制表示浮点型字面量, 用 p 表示指数, 尾数采用十六进制, 指数采用十进制, 指数的基数是 2 而不是 10.
十六进制中, 使用 p 表示指数而不是 e, 因为 e 是一个十六进制数.
通常情况下, 应该使用 double 型, 因为它比 float 型更精确.
double 表示这种数值的精度是 float 类型的两倍, 所以有人称之为双精度 double precision.
浮点数值不适用于无法接受舍入误差的金融计算. 例如:
public class Test { public static void main(String[] args) { System.out.println(2.0 - 1.1); // 0.8999999999999999 } }
这种舍入误差的主要原因是浮点数值采用二进制表示, 而在二进制系统中无法准确地表示分数 1/10. 这就好像十进制无法精确地表示分数 1/3 一样. 如果需要精确的数值计算, 不允许有舍入误差, 则应该使用 BigDecimal 类.
特殊的浮点值
所有的浮点数的计算都遵循 IEEE 754 规范.
有 3 个特殊的浮点数值表示溢出和出错情况:
-
正无穷大
-
负无穷大
-
NaN (不是一个数)
计算负数的平方根结果为 NaN.
表示这三个特殊值的常量:
public class Test { public static void main(String[] args) { System.out.println(Double.POSITIVE_INFINITY); // Infinity System.out.println(Double.NEGATIVE_INFINITY); // -Infinity System.out.println(Double.NaN); // NaN System.out.println(Float.POSITIVE_INFINITY); // Infinity System.out.println(Float.NEGATIVE_INFINITY); // -Infinity System.out.println(Float.NaN); // NaN System.out.println(Math.sqrt(-4)); // NaN } }
整数被 0 除将产生一个异常, 而浮点数被 0 除将会得到一个无穷大或 NaN 结果.
程序示例:
public class Test { public static void main(String[] args) { // System.out.println(10 / 0); // Exception in thread "main" java.lang.ArithmeticException: / by zero System.out.println(10.0 / 0); // Infinity System.out.println(-10.0 / 0); // -Infinity System.out.println(0.0 / 0); // NaN System.out.println(-0.0 / 0); // NaN System.out.println(0.0 / 0.0); // NaN System.out.println(0 / 0.0); // NaN } }
不能如下检测一个特定结果是否等于 Double.NaN:
if (x == Double.NaN) // is never true
所有 NaN 的值都认为是不相同的.
可以使用 Double.isNaN 方法来判断:
if (Double.isNaN(x)) // check whether x is "not a number"
这是适用于 x 是 double 类型的, 如果 x 是 float 类型, 则使用 Float.isNaN().
boolean
boolean 类型的字面量, 只有 true 和 false 两个值.
Java 中, integer 与 boolean 两种类型并不相容, 不可以用 0 或非 0 的整数代替 false 和 true.
例如, 下面的代码是错误的, 不能用整数作为测试条件:
int x = 1; while(x) {}
只能用 boolean 值作为测试条件.
例如, 下面的代码是可行的:
boolean isOK = true; while(isOK) {} // 或者 int x = 1; while(x == 1) {}
打印 boolean 字面量:
public class ValueDemo1 { public static void main(String[] args) { // 打印布尔型字面量 System.out.println(true); System.out.println(false); } }
执行结果:
true false
程序示例:
public class Test { public static void main(String[] args) { // boolean a = 10; // 不可以将处于 boolean 范围内的 int 类型的常量赋值给 boolean 类型的变量, boolean 值只有 true 和 false // System.out.println(a); } }
char
单个字符用 char, 多个字符用 String.
char 类型原本用于表示单个字符. 不过, 现在情况已经有所变化. 如今, 有些 Unicode 字符可以用一个 char 值描述, 另外一些 Unicode 字符则需要两个 char 值.
在 Java 中, char 的本质是一个整数, 在输出时, 输出的是 Unicode 码对应的字符. 可以直接给 char 赋一个整数, 然后输出时, 会输出对应的 Unicode 字符. char 类型是可以进行运算的, 相当于一个整数, 因为它有对应的 Unicode 码.
char 类型的字面量值要用单引号括起来. 例如: 'A' 是编码值为 65 的字符常量. 它与 "A" 不同, "A" 是包含一个字符的字符串. char 类型的值可以表示为十六进制值, 其范围从 \u0000 ~\uFFFFF. 例如 \u2122 表示商标符号 (
字符在计算机中的存储: 根据码表, 找到这个字符的编码, 再将编码转为二进制, 在计算机中存储这个二进制. 读取字符时, 要由二进制根据编码转换为字符.
编码转换的网址: https://tool.chinaz.com/Tools/Unicode.aspx
程序示例:
public class Test { public static void main(String[] args) { char ch1 = 'a'; char ch2 = 97; System.out.println(ch1); // a System.out.println(ch2); // a System.out.println(ch1 + 100); // 字符型参与运算, 输出 197 } }
字面量
字符型字面量要用单引号括起来, 内容有且只能有一个, 即内容不能为空. 字符串类型的字面量用双引号括起来, 内容可以为空. 比如: ""
转义字符
转义字符是字符型常量.
\t: 制表符, 在打印的时候, 将前面的字符串的长度补齐到 8, 或者 8 的倍数, 最少补 1 个空格, 最多补 8 个空格.
\n: 换行符.
\r: 回车.
\\: 一个 \.
\\\\: 两个 \, 即 \\.
\": 一个 ".
\': 一个 '.
程序示例:
public class Test { public static void main(String[] args) { System.out.println("************************"); System.out.println("abc" + '\t' + "def"); // System.out.println("abc" + "\t" + "def"); // \t 也可以用双引号括起来 System.out.println("12345678" + "\t" + "abc"); // 输出: 12345678 abc, 因为最少要补 1 个空格, 最多补 8 个空格 } }
执行结果:
************************ abc def 12345678 abc
程序示例:
public class ChangeChar { public static void main(String[] args) { // \t: 制表位 System.out.println("天津\t上海\t北京"); // \n: 换行符 System.out.println("天津\n上海\n北京"); // \\: 一个 \ System.out.println("Hello\\ok"); System.out.println("C:\\Windows\\apppatch"); // \ 会把后面那个字母当成是一个转义符的一个组合, // 如果组合起来之后是一个合法的转义符, 就正常编译, 否则报错: 非法转义符 // 反正就一定会当成是一个转义符, 然后去判断是否是合法的转义符 // 输出两个 \\: System.out.println("C:\\\\Windows\\\\apppatch"); // \": 一个" System.out.println("他说:\"你好. \""); // 输出: 他说:"你好. " // \': 一个' // \r: 一个回车 System.out.println("好的可以\r你好"); // 输出: 你好可以 System.out.println("好的可以\r\n你好"); } }
执行结果:
天津 上海 北京 天津 上海 北京 Hello\ok C:\Windows\apppatch C:\\Windows\\apppatch 他说:"你好. " 你好 好的可以 你好
可以在加引号的字符字面量或字符串中使用这些转义序列.
例如, '\u2122' 或 "Hello\n". 转义序列 \u 还可以在加引号字符常量或字符串之外使用 (而其他所有转义序列不可以). 例如:
public static void main(String\u005B\u005D args)
就是完全合法的, \u005B 和 \u005D 分别是 [ 和 ] 的编码.
Unicode 转义序列会在解析代码之前处理.
例如, "\u0022+\u0022" 当中, \u0022 会在解析之前转换为 ", 这会得到 ""+"", 也就是一个空串.
更隐秘地, 一定要当心注释中的 \u. 以下注释:
// \u000A is a newline
会产生一个语法错误, 因为读程序时 \u000A 会替换为一个换行符.
下面这个注释:
// look inside c:\users
也会产生一个语法错误, 因为 \u 后面并没有跟着 4 位十六进制数.
下面这个注释:
// look inside c:\\users
则不会报错.
字符编码
1、ASCII 码表
用一个字节表示, 一共 128 个字符. 扩展的 ASCII 码表一共 256 个字符.
2、Unicode 码表
Unicode 编码表的编码大小固定, 使用两个字节来表示字符, 字母和汉字统一都是占用两个字节, 这样浪费空间. Unicode 的好处是使用一种编码, 将世界上所有的符号都纳入其中. 每一个符号都给予一个独一无二的编码, 使用 Unicode 没有乱码的问题.
Unicode 的缺点: 一个英文字母和一个汉字都占用 2 个字节, 这对于存储空间来说是浪费的.
2 的 16 次方是 65536, 所以最多可以表示 65536 个字符.
编码 0-127 的字符与 ASCII 的编码一样. 比如 'a' 在 ASCII 码是 0x61, 在 Unicode 码是 0x0061, 都对应 97. 因此 Unicode 码兼容 ASCII 码.
3、UTF-8 码表
UTF-8 是 Unicode 是一种改进, 是在互联网上广泛使用的码表. UTF-8 是一种变长的编码方式, 可以使用 1-6 个字节表示一个符号, 根据不同的符号而变化字节长度, 字母使用 1 个字节, 汉字使用 3 个字节.
4、GBK 码表
可以表示汉字, 而且范围广, 字母使用 1 个字节, 汉字 2 个字节.
5、GB2312 码表
可以表示汉字, GB2312 可以表示的汉字个数少于 GBK.
6、Big5 码表
可以表示繁体中文, 多用于台湾、香港.
空类型
是一个特殊值, 表示什么都没有的状态. 字面量只有 null 一个.
public class ValueDemo { public static void main(String[] args) { // System.out.println(null); // 报错 System.out.println("null"); // 打印 null, null 不可以作为字面量直接打印 } }
自动类型转换
自动类型转换是把精度小的类型自动转换为精度大的数据类型.
自动类型转换也叫隐式转换或自动类型提升.
总的原则: 当 Java 程序在进行赋值或者算术运算时, 精度小的类型自动转换为精度大的数据类型, 这个就是自动类型转换.
数据类型按精度 (容量) 大小排序为:
char
byte

图中有 6 个实线箭头, 表示无信息丢失的转换; 另外有 3 个虚线箭头, 表示可能有精度损失的转换. 例如, 123456789 是一个大整数, 它包含的位数多于 float 类型所能表示的位数. 将这个整数转换为 float 类型时, 数量级是正确的, 但是会损失一些精度.
程序示例:
public class ConvertDemo { public static void main(String[] args) { int n = 123456789; float f = n; System.out.println(f); // 1.23456792E8 } }
其他细化的规则:
-
有多种类型的数据混合运算时, 系统首先自动将所有数据转换成容量最大的那种数据类型, 然后再进行计算.
-
当把精度 (容量) 大的数据类型赋值给精度 (容量) 小的数据类型时, 就会报错, 反之就会进行自动类型转换.
-
(byte, short) 和 char 之间不会相互自动转换.
-
byte, short, char 它们三者可以计算, 在计算时首先转换为 int 类型.
-
boolean 不参与自动转换.
当用一个二元运算符连接两个值时, 先要将两个操作数转换为同一种类型, 然后再进行计算. 如果两个操作数中有一个是 double 类型, 另一个操作数就会转换为 double 类型; 否则, 如果其中一个操作数是 float 类型, 另一个操作数将会转换为 float类型; 否则, 如果其中一个操作数是 long 类型, 另一个操作数将会转换为 long 类型; 否则, 两个操作数都将被转换为 int 类型.
程序示例:
int n1 = 10; // 有多种类型的数据混合运算时, 系统首先自动将所有数据转换成容量最大的那种数据类型, 然后再进行计算. // float f1 = n1 + 1.1; // Type mismatch: cannot convert from double to float float f1 = n1 + 1.1F; System.out.println(f1); // 11.1
程序示例:
// 当把精度 (容量) 大的数据类型赋值给精度 (容量) 小的数据类型时, 就会报错, 反之就会进行自动类型转换. // int a = 1.1; // Type mismatch: cannot convert from double to int // System.out.println(a); // 把一个常数 (必须是整数类型) 赋值给 byte 时, 先看这个常数是否在 byte 范围内 (-128~127) // 如果在范围内, 则可以赋值 byte b1 = 10; System.out.println(b1); // 10 // byte b3 = 1.1; // System.out.println(b3); // Type mismatch: cannot convert from double to byte // 把一个变量赋值给 byte 时, 要求变量必须也是 byte 类型 // int a1 = 10; // byte b2 = a1; // Type mismatch: cannot convert from int to byte // System.out.println(b2);
程序示例:
// byte, short, char 他们三者可以计算, 在计算时首先转换为 int 类型. byte b6 = 10; char c1 = 2; // byte b7 = b6 + c1; // Type mismatch: cannot convert from int to byte // System.out.println(b7); int n2 = b6 + c1; System.out.println(n2); // 12
程序示例:
// byte, short, char 他们三者可以计算, 在计算时首先转换为 int 类型. byte b8 = 10; byte b9 = 10; byte b10 = b8 + b9; // Type mismatch: cannot convert from int to byte
隐式类型转换就是在补码前面加零:
public class test4 { public static void main(String[] args) { byte a = 10; // 0000 1010 int b = a; // 0000 0000 0000 0000 0000 0000 0000 1010 System.out.println(b); } }
整型字面量在范围内时可以降级赋值, 用后缀 L 或 l 指定的常量除外. 但是用变量赋值时即便值在范围内也不可以降级赋值. 浮点型不论是字面量还是变量都不允许降级赋值. 总结起来一句话, int 类型的字面量在 short, byte 和 char 的范围内时, 可以降级赋值, 其余情况均不允许降级赋值.
程序示例:
public static void main(String[] args) { short a = 100; // 没问题, 是字面量降级赋值, int → short, 在范围内 System.out.println(a); }
程序示例:
public static void main(String[] args) { int a = 100L; // 报错: java: 不兼容的类型: 从 long 转换到 int 可能会有损失 System.out.println(a); }
程序示例:
public static void main(String[] args) { float a = 100; // 没问题, 可以将 int 赋值给 float, 同样, 也可以将 int 赋值给 double System.out.println(a); // 100.0 }
程序示例:
public static void main(String[] args) { float a = 100.; // 加了一点, 变成了 double 类型, 报错: java: 不兼容的类型: 从 double 转换到 float 可能会有损失 System.out.println(a); // 100.0 }
程序示例:
public class Test { public static void main(String[] args) { byte b1 = 10; // 可行, 在范围内的 int 类型常量可以赋值 byte b2 = 10L; // 报错 int a = 10; byte b3 = a; // 报错, 在范围内的 int 类型变量不可以赋值 short s1 = 10; // 可行, 在范围内的 int 类型常量可以赋值 short s2 = 10L; // 报错 int b = 10; short s3 = a; // 报错, 在范围内的 int 类型变量不可以赋值 char c1 = 10; // 可行, 在范围内的 int 类型常量可以赋值 char c2 = 10L; // 报错 int c = 10; char c3 = a; // 报错, 在范围内的 int 类型变量不可以赋值 } }
强制类型转换
强制类型转换是自动类型转换的逆过程, 是将精度大的类型转换为精度小的数据类型.
使用强制类型转换时要加上强制转换符 (), 但可能造成精度降低或溢出, 因此要格外要注意.
程序示例:
public class Test { public static void main(String[] args) { int i1 = (int) 1.9; System.out.println(i1); // 1, 非四舍五入, 直接丢弃小数点后的内容, 精度损失 byte b1 = (byte) 2000; System.out.println(b1); // -48, 数据溢出 int n1 = 2000; byte b2 = (byte) n1; System.out.println(b2); // -48, 数据溢出 double d1 = 121.42; double d2 = 121.52; System.out.println((int) d1); // 121 System.out.println((int) d2); // 121 } }
当需要精度高的数据类型转换为精度低的数据类型时, 就要用到强制类型转换.
强制类型转换只针对最近的操作数有效, 可以使用小括号修改优先级.
byte, char 和 short 可以接收处于范围内的 int 类型的整数, 但是不能接收 int 类型的变量, 如果需要, 则需要进行强制类型转换.
程序示例:
// 强制类型转换只针对最近的操作数有效, 可以使用小括号修改优先级. public class ForceConvertDetail { public static void main(String[] args) { // int x = (int) 10 * 3.5 + 6 * 1.5; // Type mismatch: cannot convert from double to int // System.out.println(x); int y = (int) (10 * 3.5 + 6 * 1.5); // 44 System.out.println(y); } }
程序示例:
public class ForceConvertDetail { public static void main(String[] args) { byte b1 = 1, b2 = 2; byte b3 = b1 + b2; // 报错: java: 不兼容的类型: 从 int 转换到 byte 可能会有损失 byte b3 = (byte) (b1 + b2); // 正确 } }
程序示例:
public class Test { public static void main(String[] args) { int a = 97; char c = (char) a; char b = 97; System.out.println(c); // a System.out.println(b); // a, 加不加强制类型转换都是一样的, 因为 97 在 0-65535 之间, 可以接收 char d = a; // 报错, 用变量赋值需要强转 } }
强制类型转换就是删除补码前面多出来的位:
public class Test { public static void main(String[] args) { int a = 300; // 0000 0000 0000 0000 0000 0001 0010 1100 byte b = (byte) a; // 0010 1100 System.out.println(b); // 44 } }
public class Test { public static void main(String[] args) { int a = 200; // 0000 0000 0000 0000 0000 0000 1100 1000 byte b = (byte) a; // 1100 1000 System.out.println(b); // -56 } }
不要在 boolean 类型与任何数值类型之间进行强制类型转换, 这样可以防止发生一些常见的错误, 只有极少数的情况下需要将一个 boolean 值转换为一个数, 此时可以使用条件表达式 b ? 1 : 0
基本数据类型和 String 类型的转换
在程序开发中, 经常需要将基本数据类型转成 String 类型, 或者将 String 类型转成基本数据类型.
基本类型转字符串: 基本类型 + ""
程序示例:
public class StringToBasic { public static void main(String[] args) { int n1 = 100; float f1 = 1.1F; double d1 = 4.5; boolean b1 = true; String s1 = n1 + ""; String s2 = f1 + ""; String s3 = d1 + ""; String s4 = b1 + ""; System.out.println(s1); System.out.println(s2); System.out.println(s3); System.out.println(s4); } }
运行结果:
100 1.1 4.5 true
String 类型转基本数据类型语法: 通过基本类型的包装类调用 parseXX 方法即可. XX 对应着一个类型.
Java 里, 每一个基本数据类型都对应一个包装类.
程序示例:
public class StringToBasic { public static void main(String[] args) { String s5 = "123"; int num1 = Integer.parseInt(s5); double num2 = Double.parseDouble(s5); float num3 = Float.parseFloat(s5); long num4 = Long.parseLong(s5); byte num5 = Byte.parseByte(s5); boolean b = Boolean.parseBoolean("true"); short num6 = Short.parseShort(s5); System.out.println(num1); System.out.println(num2); System.out.println(num3); System.out.println(num4); System.out.println(num5); System.out.println(num6); System.out.println(b); } }
运行结果:
123 123.0 123.0 123 123 123 true
程序示例:
// 得到字符串中的一个字符 public class StringToBasic { public static void main(String[] args) { String s5 = "cheng"; System.out.println(s5.charAt(0)); // 输出: c } }
在将 String 类型转成基本数据类型时, 要确保 String 类型能够转成有效的数据, 比如可以把 "123" 转成一个整数, 但是不能把 "hello" 转成一个整数. 如果格式不正确, 就会抛出异常, 程序就会终止. 这个异常在编译时不会发现, 在执行时会体现出来.
数字字面量加下划线
可以为数字字面量加下划线, 这样可以提高可读性, 编译器会去除这些下划线. 以多少个数字为一组进行分割是随意的.
程序示例:
public class Underscore { public static void main(String[] args) { long a = 1_000_000_000_000_000L; int b = 0B1111_0000_1111_0000; System.out.println(a); // 1000000000000000 System.out.println(b); // 61680 } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术